diff --git a/README.md b/README.md
index 3f0d59778..aa6f40ba1 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
# Sourcegraph Docs
-
+
Welcome to the Sourcegraph documentation! We're excited to have you contribute to our docs. We've recently rearchitectured our docs tech stack — powered by Next.js, TailwindCSS and deployed on Vercel. This guide will walk you through the process of contributing to our documentation using the new tech stack.
diff --git a/docs.config.js b/docs.config.js
index 1924e8202..7e57e782d 100644
--- a/docs.config.js
+++ b/docs.config.js
@@ -1,5 +1,5 @@
const config = {
- DOCS_LATEST_VERSION: '6.0'
+ DOCS_LATEST_VERSION: '6.1'
};
module.exports = config;
diff --git a/docs/cody/capabilities/chat.mdx b/docs/cody/capabilities/chat.mdx
index b0e3b6ab0..09864422c 100644
--- a/docs/cody/capabilities/chat.mdx
+++ b/docs/cody/capabilities/chat.mdx
@@ -66,7 +66,7 @@ Cody chat can run offline with Ollama. The offline mode does not require you to

-You can still switch to your Sourcegraph account whenever you want to use Claude, OpenAI, Gemini, Mixtral, etc.
+You can still switch to your Sourcegraph account whenever you want to use Claude, OpenAI, Gemini, etc.
## LLM selection
@@ -123,29 +123,6 @@ To use Cody's chat, you'll need the following:
The enhanced chat experience includes everything in the Free plan, plus the following:
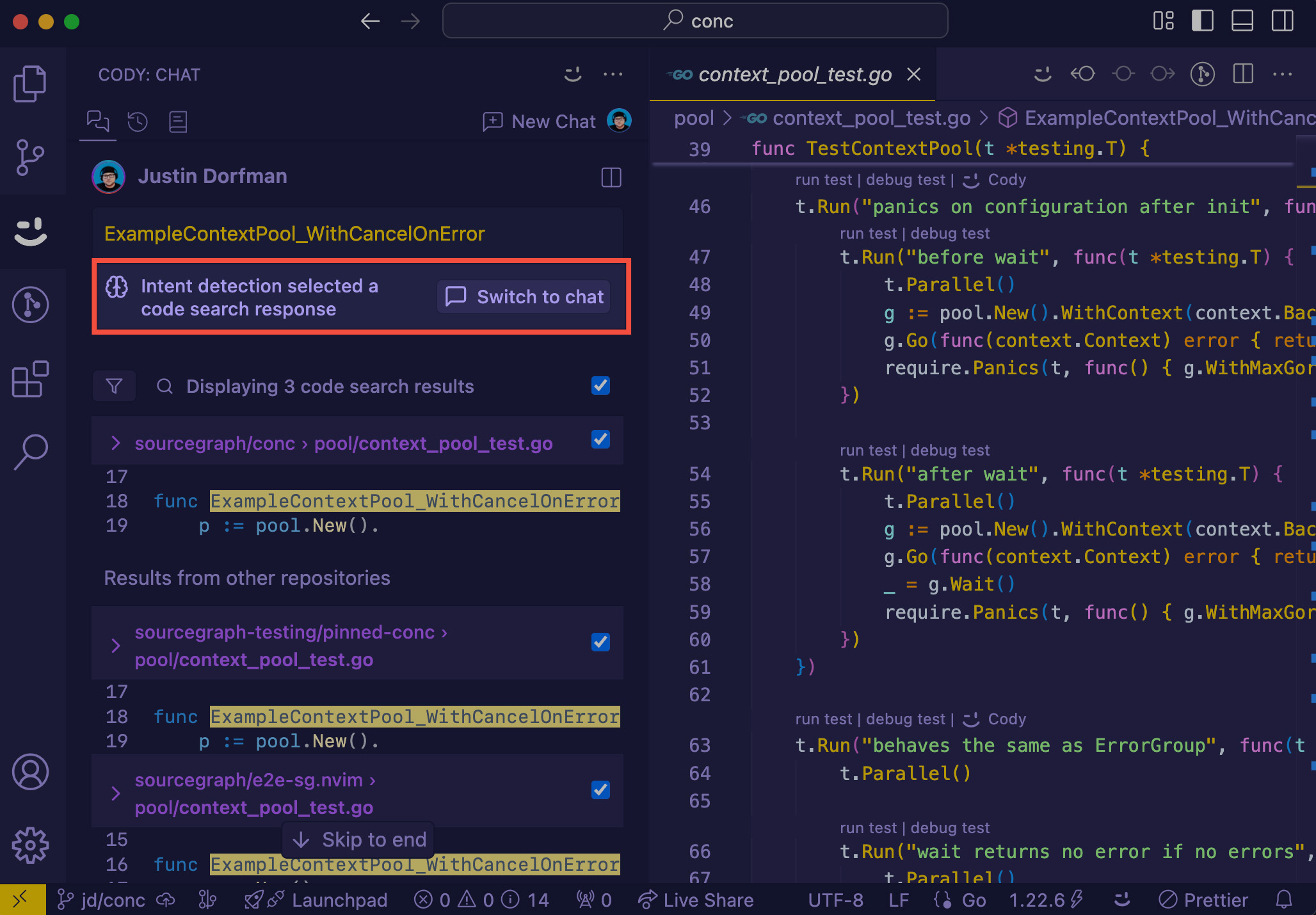
-## Intent detection
-
-Intent detection automatically analyzes user queries and determines whether to provide an AI chat or code search response. This functionality helps simplify developer workflows by providing the most appropriate type of response without requiring explicit mode switching.
-
-### How it works
-
-When a user submits a query in the chat panel, the intent detection component:
-
-- Analyzes the query content and structure
-- Determines the most appropriate response type (search or chat)
-- Returns results in the optimal format
-- Provides the ability to toggle between response types manually
-
-Let's look at an example of how this might work:
-
-#### Search-based response
-
-
-
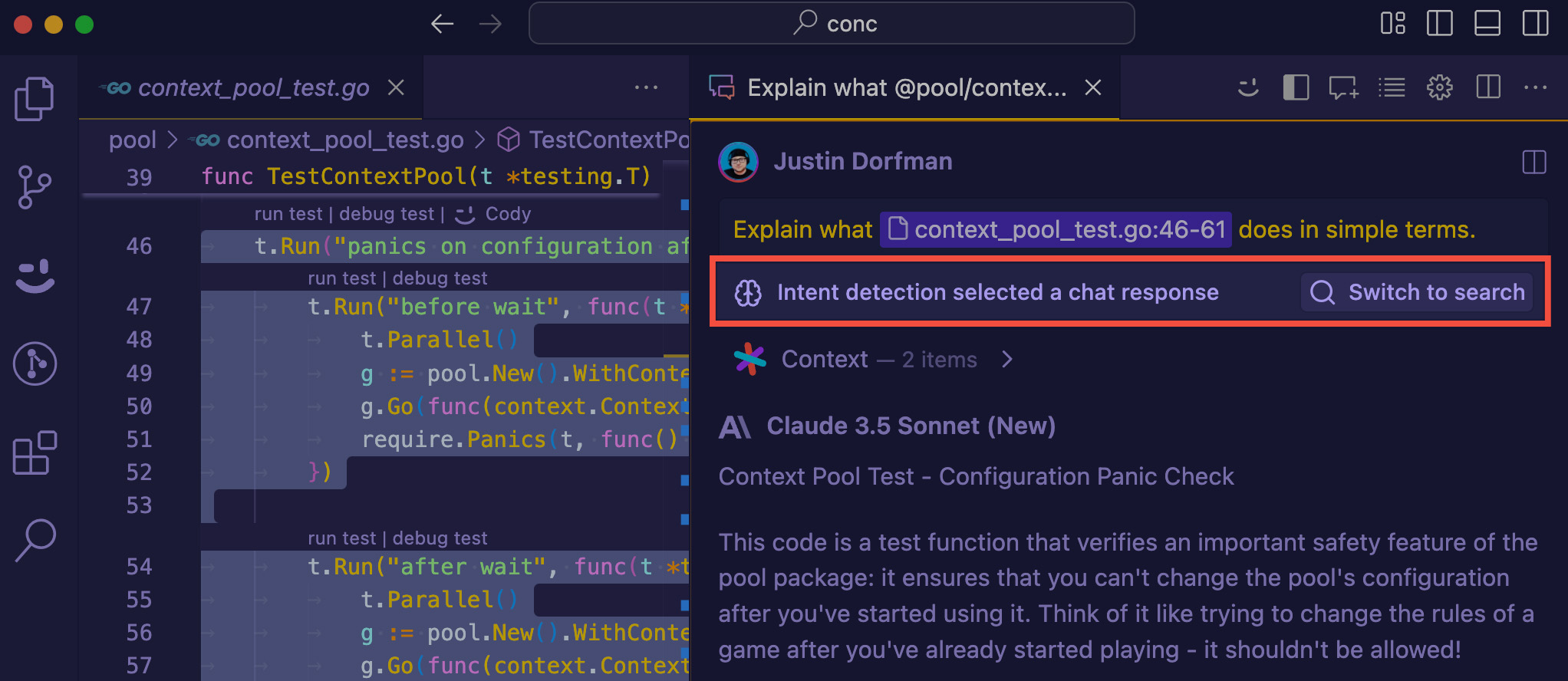
-#### Chat-based response
-
-
-
## Smart search integration
The smart search integration enhances Sourcegraph's chat experience by providing lightweight code search capabilities directly within the chat interface. This feature simplifies developer workflows by offering quick access to code search without leaving the chat environment.
@@ -181,15 +158,16 @@ Search results generated through smart search integration can be automatically u
The following is a general walkthrough of the chat experience:
1. The user enters a query in the chat interface
-2. The system analyzes the query through intent detection
-3. If it's a search query:
+2. By default a user gets a chat response for the query
+3. To get integrated search results, toggle to **Run as search** from the drop-down selector or alternatively use `Cmd+Opt+Enter` (macOS)
+4. For search:
- Displays ranked results with code snippets
- Shows personalized repository ordering
- Provides checkboxes to select context for follow-ups
-4. If it's a chat query:
+5. For chat:
- Delivers AI-powered responses
- Can incorporate previous search results as context
-5. Users can:
+6. Users can:
- Switch between search and chat modes
- Click on results to open files in their editor
- Ask follow-up questions using selected context
diff --git a/docs/cody/capabilities/supported-models.mdx b/docs/cody/capabilities/supported-models.mdx
index fb5439608..be4999d93 100644
--- a/docs/cody/capabilities/supported-models.mdx
+++ b/docs/cody/capabilities/supported-models.mdx
@@ -8,25 +8,20 @@ Cody supports a variety of cutting-edge large language models for use in chat an
| **Provider** | **Model** | **Free** | **Pro** | **Enterprise** | | | | |
| :------------ | :-------------------------------------------------------------------------------------------------------------------------------------------- | :----------- | :----------- | :------------- | --- | --- | --- | --- |
-| OpenAI | [gpt-3.5 turbo](https://platform.openai.com/docs/models/gpt-3-5-turbo) | ✅ | ✅ | ✅ | | | | |
-| OpenAI | [gpt-4](https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo#:~:text=to%20Apr%202023-,gpt%2D4,-Currently%20points%20to) | - | - | ✅ | | | | |
| OpenAI | [gpt-4 turbo](https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo#:~:text=TRAINING%20DATA-,gpt%2D4%2D0125%2Dpreview,-New%20GPT%2D4) | - | ✅ | ✅ | | | | |
-| OpenAI | [gpt-4o](https://platform.openai.com/docs/models/gpt-4o) | - | ✅ | ✅ | | | | |
-| Anthropic | [claude-3 Haiku](https://docs.anthropic.com/claude/docs/models-overview#model-comparison) | ✅ | ✅ | ✅ | | | | |
+| OpenAI | [gpt-4o](https://platform.openai.com/docs/models#gpt-4o) | - | ✅ | ✅ | | | | |
+| OpenAI | [gpt-4o-mini](https://platform.openai.com/docs/models#gpt-4o-mini) | ✅ | ✅ | ✅ | | | | |
+| OpenAI | [o3-mini-medium](https://openai.com/index/openai-o3-mini/) (experimental) | ✅ | ✅ | ✅ | | | | |
+| OpenAI | [o3-mini-high](https://openai.com/index/openai-o3-mini/) (experimental) | - | - | ✅ | | | | |
+| OpenAI | [o1](https://platform.openai.com/docs/models#o1) | - | ✅ | ✅ | | | | |
| Anthropic | [claude-3.5 Haiku](https://docs.anthropic.com/claude/docs/models-overview#model-comparison) | ✅ | ✅ | ✅ | | | | |
-| Anthropic | [claude-3 Sonnet](https://docs.anthropic.com/claude/docs/models-overview#model-comparison) | ✅ | ✅ | ✅ | | | | |
| Anthropic | [claude-3.5 Sonnet](https://docs.anthropic.com/claude/docs/models-overview#model-comparison) | ✅ | ✅ | ✅ | | | | |
-| Anthropic | [claude-3.5 Sonnet (New)](https://docs.anthropic.com/claude/docs/models-overview#model-comparison) | ✅ | ✅ | ✅ | | | | |
-| Anthropic | [claude-3 Opus](https://docs.anthropic.com/claude/docs/models-overview#model-comparison) | - | ✅ | ✅ | | | | |
-| Mistral | [mixtral 8x7b](https://mistral.ai/technology/#models:~:text=of%20use%20cases.-,Mixtral%208x7B,-Currently%20the%20best) | ✅ | ✅ | - | | | | |
-| Mistral | [mixtral 8x22b](https://mistral.ai/technology/#models:~:text=of%20use%20cases.-,Mixtral%208x7B,-Currently%20the%20best) | ✅ | ✅ | - | | | | |
| Ollama | [variety](https://ollama.com/) | experimental | experimental | - | | | | |
-| Google Gemini | [1.5 Pro](https://deepmind.google/technologies/gemini/pro/) | ✅ | ✅ | ✅ (Beta) | | | | |
-| Google Gemini | [1.5 Flash](https://deepmind.google/technologies/gemini/flash/) | ✅ | ✅ | ✅ (Beta) | | | | |
-| Google Gemini | [2.0 Flash Experimental](https://deepmind.google/technologies/gemini/flash/) | ✅ | ✅ | ✅ | | | | |
-| | | | | | | | | |
+| Google Gemini | [1.5 Pro](https://deepmind.google/technologies/gemini/pro/) | ✅ | ✅ | ✅ (beta) | | | | |
+| Google Gemini | [2.0 Flash](https://deepmind.google/technologies/gemini/flash/) | ✅ | ✅ | ✅ | | | | |
+| Google Gemini | [2.0 Flash-Lite Preview](https://deepmind.google/technologies/gemini/flash/) (experimental) | ✅ | ✅ | ✅ | | | | |
-To use Claude 3 (Opus and Sonnets) models with Cody Enterprise, make sure you've upgraded your Sourcegraph instance to the latest version.
+To use Claude 3 Sonnet models with Cody Enterprise, make sure you've upgraded your Sourcegraph instance to the latest version.
## Autocomplete
@@ -37,7 +32,6 @@ Cody uses a set of models for autocomplete which are suited for the low latency
| Fireworks.ai | [DeepSeek-Coder-V2](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct) | ✅ | ✅ | ✅ | | | | |
| Fireworks.ai | [StarCoder](https://arxiv.org/abs/2305.06161) | - | - | ✅ | | | | |
| Anthropic | [claude Instant](https://docs.anthropic.com/claude/docs/models-overview#model-comparison) | - | - | ✅ | | | | |
-| Google Gemini (Beta) | [1.5 Flash](https://deepmind.google/technologies/gemini/flash/) | - | - | ✅ | | | | |
| Ollama (Experimental) | [variety](https://ollama.com/) | ✅ | ✅ | - | | | | |
| | | | | | | | | |
diff --git a/docs/cody/clients/feature-reference.mdx b/docs/cody/clients/feature-reference.mdx
index a98eccf63..2c06d487e 100644
--- a/docs/cody/clients/feature-reference.mdx
+++ b/docs/cody/clients/feature-reference.mdx
@@ -6,7 +6,7 @@
| **Feature** | **VS Code** | **JetBrains** | **Visual Studio** | **Eclipse** | **Web** | **CLI** |
| ---------------------------------------- | ----------- | ------------- | ----------------- | ----------- | -------------------- | ------- |
-| Chat | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Chat | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Chat history | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Clear chat history | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Edit sent messages | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
@@ -27,12 +27,13 @@
## Code Autocomplete
-| **Feature** | **VS Code** | **JetBrains** |
-| --------------------------------------------- | ----------- | ------------- |
-| Single and multi-line autocompletion | ✅ | ✅ |
-| Cycle through multiple completion suggestions | ✅ | ✅ |
-| Accept suggestions word-by-word | ✅ | ❌ |
-| Ollama support (experimental) | ✅ | ❌ |
+| **Feature** | **VS Code** | **JetBrains** | **Visual Studio** |
+| --------------------------------------------- | ----------- | ------------- | ----------------- |
+| Single and multi-line autocompletion | ✅ | ✅ | ✅ |
+| Cycle through multiple completion suggestions | ✅ | ✅ | ✅ |
+| Accept suggestions word-by-word | ✅ | ❌ | ❌ |
+| Ollama support (experimental) | ✅ | ❌ | ❌ |
+
Few exceptions that apply to Cody Pro and Cody Enterprise users:
diff --git a/docs/cody/clients/install-eclipse.mdx b/docs/cody/clients/install-eclipse.mdx
index 2494cb47a..8e55718b7 100644
--- a/docs/cody/clients/install-eclipse.mdx
+++ b/docs/cody/clients/install-eclipse.mdx
@@ -50,7 +50,7 @@ The chat input field has a default `@-mention` [context chips](#context-retrieva
## LLM selection
-Cody offers a variety of large language models (LLMs) to power your chat experience. Cody Free users can access the latest base models from Anthropic, OpenAI, Google, and Mixtral. At the same time, Cody Pro and Enterprise users can access more extended models.
+Cody offers a variety of large language models (LLMs) to power your chat experience. Cody Free users can access the latest base models from Anthropic, OpenAI, Google. At the same time, Cody Pro and Enterprise users can access more extended models.
Local models are also available through Ollama to Cody Free and Cody Pro users. To use a model in Cody chat, simply download it and run it in Ollama.
diff --git a/docs/cody/clients/install-visual-studio.mdx b/docs/cody/clients/install-visual-studio.mdx
index 821edd99f..2e48690ec 100644
--- a/docs/cody/clients/install-visual-studio.mdx
+++ b/docs/cody/clients/install-visual-studio.mdx
@@ -43,7 +43,7 @@ The chat input field has a default `@-mention` [context chips](#context-retrieva
## LLM selection
-Cody offers a variety of large language models (LLMs) to power your chat experience. Cody Free users can access the latest base models from Anthropic, OpenAI, Google, and Mixtral. At the same time, Cody Pro and Enterprise users can access more extended models.
+Cody offers a variety of large language models (LLMs) to power your chat experience. Cody Free users can access the latest base models from Anthropic, OpenAI, Google. At the same time, Cody Pro and Enterprise users can access more extended models.
Local models are also available through Ollama to Cody Free and Cody Pro users. To use a model in Cody chat, download it and run it in Ollama.
@@ -78,3 +78,13 @@ To help you get started, there are a few prompts that are available by default.
- Generate unit tests

+
+## Autocomplete
+
+Cody for Visual Studio supports single and multi-line autocompletions. The autocomplete feature is available for the extension `v0.2.0` and above. It's enabled by default, with settings to turn it off.
+
+
+
+Advanced features like [auto-edit](/cody/capabilities/auto-edit) are not yet supported. To disable the autocomplete feature, you can do it from your Cody settings section.
diff --git a/docs/cody/clients/install-vscode.mdx b/docs/cody/clients/install-vscode.mdx
index e959beba6..e5343503a 100644
--- a/docs/cody/clients/install-vscode.mdx
+++ b/docs/cody/clients/install-vscode.mdx
@@ -136,7 +136,7 @@ For Edit:
- On any file, select some code and a right-click
- Select Cody->Edit Code (optionally, you can do this with Opt+K/Alt+K)
-- Select the default model available (this is Claude 3 Opus)
+- Select the default model available
- See the selection of models and click the model you desire. This model will now be the default model going forward on any new edits
### Selecting Context with @-mentions
@@ -271,13 +271,13 @@ Claude 3.5 Sonnet is the default LLM model for inline edits and prompts. If you'
Users on Cody **Free** and **Pro** can choose from a list of [supported LLM models](/cody/capabilities/supported-models) for chat.
-
+
-Enterprise users get Claude 3 (Opus and Sonnet) as the default LLM models without extra cost. Moreover, Enterprise users can use Claude 3.5 models through Cody Gateway, Anthropic BYOK, Amazon Bedrock (limited availability), and GCP Vertex.
+Enterprise users get Claude 3.5 Sonnet as the default LLM models without extra cost. Moreover, Enterprise users can use Claude 3.5 models through Cody Gateway, Anthropic BYOK, Amazon Bedrock (limited availability), and GCP Vertex.
For enterprise users on Amazon Bedrock: 3.5 Sonnet is unavailable in `us-west-2` but available in `us-east-1`. Check the current model availability on AWS and your customer's instance location before switching. Provisioned throughput via AWS is not supported for 3.5 Sonnet.
-You also get additional capabilities like BYOLLM (Bring Your Own LLM), supporting Single-Tenant and Self Hosted setups for flexible coding environments. Your site administrator determines the LLM, and cannot be changed within the editor. However, Cody Enterprise users when using Cody Gateway have the ability to [configure custom models](/cody/core-concepts/cody-gateway#configuring-custom-models) Anthropic (like Claude 2.0 and Claude Instant), OpenAI (GPT 3.5 and GPT 4) and Google Gemini 1.5 models (Flash and Pro).
+You also get additional capabilities like BYOLLM (Bring Your Own LLM), supporting Single-Tenant and Self Hosted setups for flexible coding environments. Your site administrator determines the LLM, and cannot be changed within the editor. However, Cody Enterprise users when using Cody Gateway have the ability to [configure custom models](/cody/core-concepts/cody-gateway#configuring-custom-models) from Anthropic, OpenAI, and Google Gemini.
Read more about all the supported LLM models [here](/cody/capabilities/supported-models)
@@ -333,7 +333,7 @@ You can use Cody with or without an internet connection. The offline mode does n

-You still have the option to switch to your Sourcegraph account whenever you want to use Claude, OpenAI, Gemini, Mixtral, etc.
+You still have the option to switch to your Sourcegraph account whenever you want to use Claude, OpenAI, Gemini, etc.
## Experimental models
diff --git a/docs/cody/core-concepts/token-limits.mdx b/docs/cody/core-concepts/token-limits.mdx
index b83c1ba66..6491aef0a 100644
--- a/docs/cody/core-concepts/token-limits.mdx
+++ b/docs/cody/core-concepts/token-limits.mdx
@@ -2,7 +2,7 @@
Learn about Cody's token limits and how to manage them.
-For all models, Cody allows up to **4,000 tokens of output**, which is approximately **500-600** lines of code. For Claude 3 Sonnet or Opus models, Cody tracks two separate token limits:
+For all models, Cody allows up to **4,000 tokens of output**, which is approximately **500-600** lines of code. For Claude 3 Sonnet models, Cody tracks two separate token limits:
- The @-mention context is limited to **30,000 tokens** (~4,000 lines of code) and can be specified using the @-filename syntax. The user explicitly defines this context, which provides specific information to Cody.
- Conversation context is limited to **15,000 tokens**, including user questions, system responses, and automatically retrieved context items. Apart from user questions, Cody generates this context automatically.
@@ -13,61 +13,54 @@ Here's a detailed breakdown of the token limits by model:
-| **Model** | **Conversation Context** | **@-mention Context** | **Output** |
-| --------------------------- | ------------------------ | --------------------- | ---------- |
-| gpt-3.5-turbo | 7,000 | shared | 4,000 |
-| gpt-4-turbo | 7,000 | shared | 4,000 |
-| gpt 4o | 7,000 | shared | 4,000 |
-| claude-2.0 | 7,000 | shared | 4,000 |
-| claude-2.1 | 7,000 | shared | 4,000 |
-| claude-3 Haiku | 7,000 | shared | 4,000 |
-| claude-3.5 Haiku | 7,000 | shared | 4,000 |
-| **claude-3 Sonnet** | **15,000** | **30,000** | **4,000** |
-| **claude-3.5 Sonnet** | **15,000** | **30,000** | **4,000** |
-| **claude-3.5 Sonnet (New)** | **15,000** | **30,000** | **4,000** |
-| mixtral 8x7B | 7,000 | shared | 4,000 |
-| mixtral 8x22B | 7,000 | shared | 4,000 |
-| Google Gemini 1.5 Flash | 7,000 | shared | 4,000 |
-| Google Gemini 1.5 Pro | 7,000 | shared | 4,000 |
+| **Model** | **Conversation Context** | **@-mention Context** | **Output** |
+| ------------------------------------ | ------------------------ | --------------------- | ---------- |
+| gpt-4o-mini | 7,000 | shared | 4,000 |
+| gpt-o3-mini-medium | 7,000 | shared | 4,000 |
+| claude-3.5 Haiku | 7,000 | shared | 4,000 |
+| **claude-3.5 Sonnet (New)** | **15,000** | **30,000** | **4,000** |
+| Google Gemini 1.5 Pro | 7,000 | shared | 4,000 |
+| Google Gemini 2.0 Flash | 7,000 | shared | 4,000 |
+| Google Gemini 2.0 Flash-Lite Preview | 7,000 | shared | 4,000 |
-| **Model** | **Conversation Context** | **@-mention Context** | **Output** |
-| --------------------------- | ------------------------ | --------------------- | ---------- |
-| gpt-3.5-turbo | 7,000 | shared | 4,000 |
-| gpt-4 | 7,000 | shared | 4,000 |
-| gpt-4-turbo | 7,000 | shared | 4,000 |
-| claude instant | 7,000 | shared | 4,000 |
-| claude-2.0 | 7,000 | shared | 4,000 |
-| claude-2.1 | 7,000 | shared | 4,000 |
-| claude-3 Haiku | 7,000 | shared | 4,000 |
-| claude-3.5 Haiku | 7,000 | shared | 4,000 |
-| **claude-3 Sonnet** | **15,000** | **30,000** | **4,000** |
-| **claude-3.5 Sonnet** | **15,000** | **30,000** | **4,000** |
-| **claude-3.5 Sonnet (New)** | **15,000** | **30,000** | **4,000** |
-| **claude-3 Opus** | **15,000** | **30,000** | **4,000** |
-| **Google Gemini 1.5 Flash** | **15,000** | **30,000** | **4,000** |
-| **Google Gemini 1.5 Pro** | **15,000** | **30,000** | **4,000** |
-| mixtral 8x7b | 7,000 | shared | 4,000 |
+
+The Pro tier supports the token limits for the LLM models on Free tier, plus:
+
+| **Model** | **Conversation Context** | **@-mention Context** | **Output** |
+| ------------------------------------ | ------------------------ | --------------------- | ---------- |
+| gpt-4o-mini | 7,000 | shared | 4,000 |
+| gpt-o3-mini-medium | 7,000 | shared | 4,000 |
+| gpt-4-turbo | 7,000 | shared | 4,000 |
+| gpt-4o | 7,000 | shared | 4,000 |
+| o1 | 7,000 | shared | 4,000 |
+| claude-3.5 Haiku | 7,000 | shared | 4,000 |
+| **claude-3.5 Sonnet (New)** | **15,000** | **30,000** | **4,000** |
+| **Google Gemini 1.5 Pro** | **15,000** | **30,000** | **4,000** |
+| Google Gemini 2.0 Flash | 7,000 | shared | 4,000 |
+| Google Gemini 2.0 Flash-Lite Preview | 7,000 | shared | 4,000 |
+
-| **Model** | **Conversation Context** | **@-mention Context** | **Output** |
-| --------------------------- | ------------------------ | --------------------- | ---------- |
-| gpt-3.5-turbo | 7,000 | shared | 1,000 |
-| gpt-4 | 7,000 | shared | 1,000 |
-| gpt-4-turbo | 7,000 | shared | 1,000 |
-| claude instant | 7,000 | shared | 1,000 |
-| claude-2.0 | 7,000 | shared | 1,000 |
-| claude-2.1 | 7,000 | shared | 1,000 |
-| claude-3 Haiku | 7,000 | shared | 1,000 |
-| claude-3.5 Haiku | 7,000 | shared | 1,000 |
-| **claude-3 Sonnet** | **15,000** | **30,000** | **4,000** |
-| **claude-3.5 Sonnet** | **15,000** | **30,000** | **4,000** |
-| **claude-3.5 Sonnet (New)** | **15,000** | **30,000** | **4,000** |
-| **claude-3 Opus** | **15,000** | **30,000** | **4,000** |
-| mixtral 8x7b | 7,000 | shared | 1,000 |
+
+The Enterprise tier supports the token limits for the LLM models on Free and Pro tier, plus:
+
+| **Model** | **Conversation Context** | **@-mention Context** | **Output** |
+| ------------------------------------ | ------------------------ | --------------------- | ---------- |
+| gpt-4o-mini | 7,000 | shared | 1,000 |
+| gpt-o3-mini-medium | 7,000 | shared | 1,000 |
+| gpt-4-turbo | 7,000 | shared | 1,000 |
+| gpt-4o | 7,000 | shared | 1,000 |
+| o1 | 7,000 | shared | 1,000 |
+| o3-mini-high | 7,000 | shared | 1,000 |
+| claude-3.5 Haiku | 7,000 | shared | 1,000 |
+| **claude-3.5 Sonnet (New)** | **15,000** | **30,000** | **4,000** |
+| Google Gemini 2.0 Flash | 7,000 | shared | 1,000 |
+| Google Gemini 2.0 Flash-Lite Preview | 7,000 | shared | 1,000 |
+
@@ -89,26 +82,6 @@ When a model generates text or code, it does so token by token, predicting the m
The output limit helps to keep the generated text focused, concise, and manageable by preventing the model from going off-topic or generating excessively long responses. It also ensures that the output can be efficiently processed and displayed by downstream applications or user interfaces while managing computational resources.
-## Current foundation model limits
-
-Here is a table with the context window sizes and output limits for each of our [supported models](/cody/capabilities/supported-models).
-
-| **Model** | **Context Window** | **Output Limit** |
-| ---------------- | ------------------ | ---------------- |
-| gpt-3.5-turbo | 16,385 tokens | 4,096 tokens |
-| gpt-4 | 8,192 tokens | 4,096 tokens |
-| gpt-4-turbo | 128,000 tokens | 4,096 tokens |
-| claude instant | 100,000 tokens | 4,096 tokens |
-| claude-2.0 | 100,000 tokens | 4,096 tokens |
-| claude-2.1 | 200,000 tokens | 4,096 tokens |
-| claude-3 Haiku | 200,000 tokens | 4,096 tokens |
-| claude-3.5 Haiku | 200,000 tokens | 4,096 tokens |
-| claude-3 Sonnet | 200,000 tokens | 4,096 tokens |
-| claude-3 Opus | 200,000 tokens | 4,096 tokens |
-| mixtral 8x7b | 32,000 tokens | 4,096 tokens |
-
-These foundation model limits are the LLM models' inherent limits. For instance, Claude 3 models have a 200K context window compared to 8,192 for GPT-4.
-
## Tradeoffs: Size, Accuracy, Latency and Cost
So why does Cody not use each model's full available context window? We need to consider a few tradeoffs, namely, context size, retrieval accuracy, latency, and costs.
diff --git a/docs/cody/enterprise/completions-configuration.mdx b/docs/cody/enterprise/completions-configuration.mdx
index 1d0f7ea56..cdab972ab 100644
--- a/docs/cody/enterprise/completions-configuration.mdx
+++ b/docs/cody/enterprise/completions-configuration.mdx
@@ -8,7 +8,7 @@
## Using Sourcegraph Cody Gateway
-This is the recommended way to configure Cody Enterprise. It supports all the latest models from Anthropic, OpenAI, Mistral, and more without requiring a separate account or incurring separate charges. You can learn more about these in our [supported models](/cody/capabilities/supported-models) docs.
+This is the recommended way to configure Cody Enterprise. It supports all the latest models from Anthropic, OpenAI, and more without requiring a separate account or incurring separate charges. You can learn more about these in our [supported models](/cody/capabilities/supported-models) docs.
## Using your organization's account with a model provider
diff --git a/docs/cody/enterprise/model-config-examples.mdx b/docs/cody/enterprise/model-config-examples.mdx
index 3276aeda5..d6bf85a94 100644
--- a/docs/cody/enterprise/model-config-examples.mdx
+++ b/docs/cody/enterprise/model-config-examples.mdx
@@ -144,30 +144,6 @@ Below are configuration examples for setting up various LLM providers using BYOK
"maxOutputTokens": 4000
}
},
- {
- "modelRef": "anthropic::2023-06-01::claude-3-haiku",
- "displayName": "Claude 3 Haiku",
- "modelName": "claude-3-haiku-20240307",
- "capabilities": ["chat"],
- "category": "speed",
- "status": "stable",
- "contextWindow": {
- "maxInputTokens": 7000,
- "maxOutputTokens": 4000
- }
- },
- {
- "modelRef": "anthropic::2023-06-01::claude-3-haiku",
- "displayName": "Claude 3 Haiku",
- "modelName": "claude-3-haiku-20240307",
- "capabilities": ["edit", "chat"],
- "category": "speed",
- "status": "stable",
- "contextWindow": {
- "maxInputTokens": 7000,
- "maxOutputTokens": 4000
- }
- }
],
"defaultModels": {
"chat": "anthropic::2024-10-22::claude-3.5-sonnet",
diff --git a/docs/cody/enterprise/model-configuration.mdx b/docs/cody/enterprise/model-configuration.mdx
index 59f3c45b7..3a564f7d4 100644
--- a/docs/cody/enterprise/model-configuration.mdx
+++ b/docs/cody/enterprise/model-configuration.mdx
@@ -352,18 +352,6 @@ The response includes:
"maxOutputTokens": 4000
}
},
- {
- "modelRef": "anthropic::2023-06-01::claude-3-opus",
- "displayName": "Claude 3 Opus",
- "modelName": "claude-3-opus-20240229",
- "capabilities": ["chat"],
- "category": "other",
- "status": "stable",
- "contextWindow": {
- "maxInputTokens": 45000,
- "maxOutputTokens": 4000
- }
- },
{
"modelRef": "anthropic::2023-06-01::claude-3-haiku",
"displayName": "Claude 3 Haiku",
@@ -412,30 +400,6 @@ The response includes:
"maxOutputTokens": 4000
}
},
- {
- "modelRef": "google::v1::gemini-1.5-flash",
- "displayName": "Gemini 1.5 Flash",
- "modelName": "gemini-1.5-flash",
- "capabilities": ["chat"],
- "category": "speed",
- "status": "stable",
- "contextWindow": {
- "maxInputTokens": 45000,
- "maxOutputTokens": 4000
- }
- },
- {
- "modelRef": "mistral::v1::mixtral-8x7b-instruct",
- "displayName": "Mixtral 8x7B",
- "modelName": "accounts/fireworks/models/mixtral-8x7b-instruct",
- "capabilities": ["chat"],
- "category": "speed",
- "status": "stable",
- "contextWindow": {
- "maxInputTokens": 7000,
- "maxOutputTokens": 4000
- }
- },
{
"modelRef": "openai::2024-02-01::gpt-4o",
"displayName": "GPT-4o",
@@ -460,18 +424,6 @@ The response includes:
"maxOutputTokens": 4000
}
},
- {
- "modelRef": "openai::2024-02-01::cody-chat-preview-002",
- "displayName": "OpenAI o1-mini",
- "modelName": "cody-chat-preview-002",
- "capabilities": ["chat"],
- "category": "accuracy",
- "status": "waitlist",
- "contextWindow": {
- "maxInputTokens": 45000,
- "maxOutputTokens": 4000
- }
- }
],
"defaultModels": {
"chat": "anthropic::2024-10-22::claude-3-5-sonnet-latest",
diff --git a/docs/cody/faq.mdx b/docs/cody/faq.mdx
index ebf2215e2..689da159b 100644
--- a/docs/cody/faq.mdx
+++ b/docs/cody/faq.mdx
@@ -173,8 +173,6 @@ Once you are signed in make sure to re-enable protection.
#### Model Selection
-- **o1-preview**: Best for complex reasoning and planning
-- **o1-mini**: More reliable for straightforward tasks
- **Sonnet 3.5**: Better for tasks requiring longer outputs
#### Prompting Strategy
@@ -187,7 +185,6 @@ Once you are signed in make sure to re-enable protection.
#### Response Time
- Start with smaller contexts
-- Use o1-mini for faster responses
- Consider breaking complex tasks into stages
#### Quality
diff --git a/docs/cody/prompts-guide.mdx b/docs/cody/prompts-guide.mdx
index ab42c5434..bd6af1e8a 100644
--- a/docs/cody/prompts-guide.mdx
+++ b/docs/cody/prompts-guide.mdx
@@ -97,7 +97,7 @@ You can learn more about context [here](/cody/core-concepts/context).
## Selecting the right LLM
-Cody offers a variety of LLMs for both chat and in-line edits by all the leading LLM providers. Each LLM has its strengths and weaknesses, so it is important to select the right one for your use case. For example, Claude 3.5 Sonnet and GPT-4o are powerful for code generation and provide accurate results. However, Gemini 1.5 Flash is a decent choice for cost-effective searches. So, you can always optimize your choice of LLM based on your use case.
+Cody offers a variety of LLMs for both chat and in-line edits by all the leading LLM providers. Each LLM has its strengths and weaknesses, so it is important to select the right one for your use case. For example, Claude 3.5 Sonnet and GPT-4o are powerful for code generation and provide accurate results. However, Gemini 2.0 Flash is a decent choice for cost-effective searches. So, you can always optimize your choice of LLM based on your use case.
Learn more about all the supported LLMs [here](/cody/capabilities/supported-models).
diff --git a/docs/cody/quickstart.mdx b/docs/cody/quickstart.mdx
index d44ea8775..19d69e5fc 100644
--- a/docs/cody/quickstart.mdx
+++ b/docs/cody/quickstart.mdx
@@ -27,7 +27,7 @@ To help you automate your key tasks in your development workflow, you get **[Pro
The Cody chat interface offers a few more options and settings. [You can read more in these docs](/cody/capabilities/chat).
-
+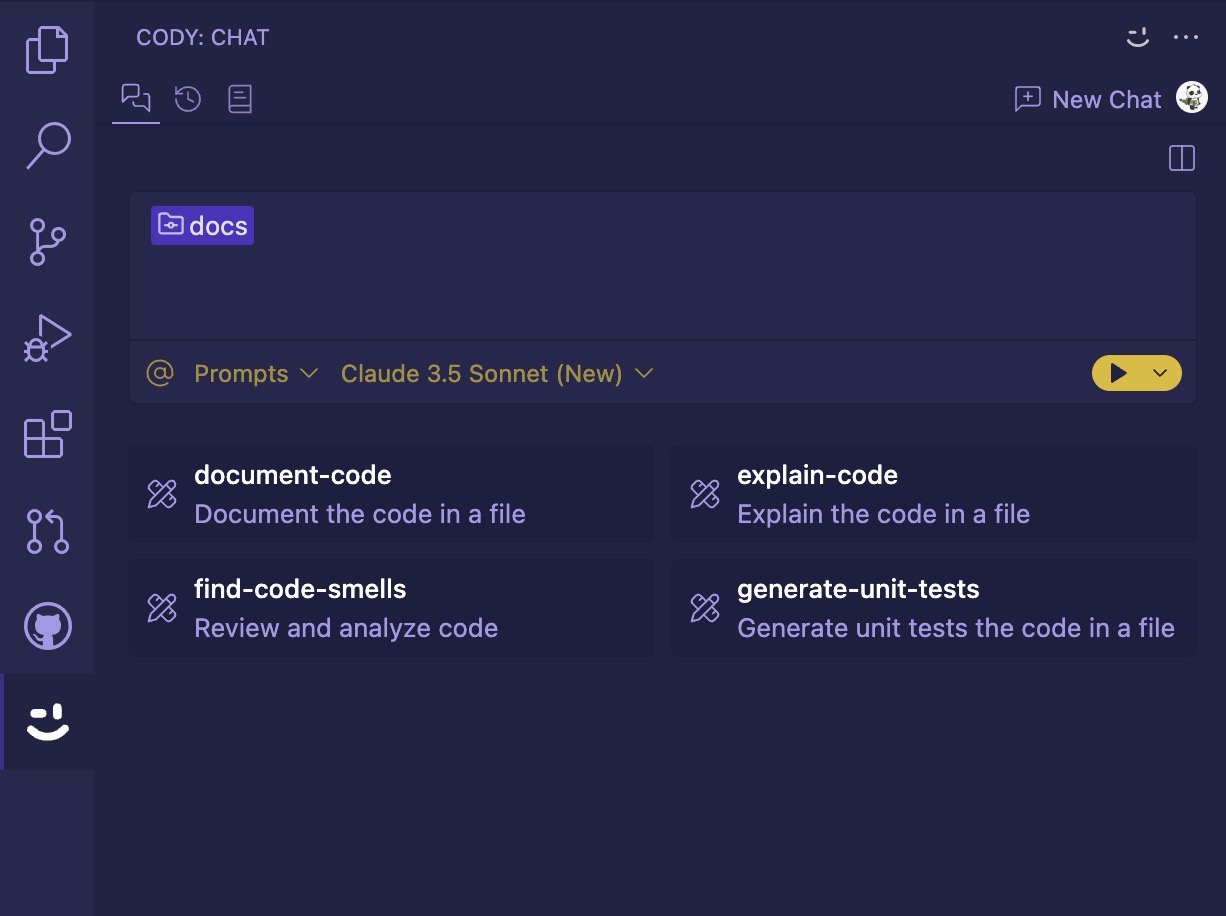
## Chat with Cody
diff --git a/docs/cody/troubleshooting.mdx b/docs/cody/troubleshooting.mdx
index 3614434b3..69a3ebcb8 100644
--- a/docs/cody/troubleshooting.mdx
+++ b/docs/cody/troubleshooting.mdx
@@ -273,7 +273,6 @@ Additionally, Eclipse's built-in Error Log can be used to view any uncaught exce
Symptoms:
- "Request Failed: Request to... failed with 500 Internal Server Error: context deadline exceeded"
-- Occurs with both o1-mini and o1-preview
- Happens even with relatively small inputs (~220 lines)
Solutions:
@@ -299,8 +298,6 @@ Symptoms:
Solutions:
-- For `o1-preview`: Copy the last line and ask to "continue from last line"
-- Switch to `o1-mini` for more reliable complete outputs
- Break down complex requests into smaller steps
- Consider using Sonnet 3.5 for tasks requiring longer outputs
diff --git a/docs/cody/usage-and-pricing.mdx b/docs/cody/usage-and-pricing.mdx
index 870411119..dbf4f18ed 100644
--- a/docs/cody/usage-and-pricing.mdx
+++ b/docs/cody/usage-and-pricing.mdx
@@ -37,20 +37,16 @@ Once your Pro subscription is confirmed, click **My subscription** to manage and
Cody Pro, designed for individuals or small teams at **$9 per user per month**, offers an enhanced coding experience beyond the free plan. It provides unlimited autocompletion suggestions plus unlimited chat and prompts. It also uses local repository context to enhance Cody's understanding and accuracy.
-Cody Pro uses DeepSeek-Coder-V2 by default for autocomplete. Pro accounts also default to the Claude 3.5 Sonnet (New) model for chat and prompts, but users can switch to other LLM model choices with unlimited usage, including:
-
-- Claude Instant 1.2
-- Claude 2
-- Claude 3
-- ChatGPT 3.5 Turbo
-- GPT-4o
-- ChatGPT 4 Turbo Preview
-- Mixtral
-- Google Gemini 1.5 Pro
-- Google Gemini 1.5 Flash
+Cody Pro uses DeepSeek-Coder-V2 by default for autocomplete. Pro accounts also default to the Claude 3.5 Sonnet (New) model for chat and prompts, but users can switch to other LLM model choices with unlimited usage. You can refer to the [supported LLM models](/cody/capabilities/supported-models) docs for more information.
Support for Cody Pro is available through our Support team via support@sourcegraph.com, ensuring prompt assistance and guidance.
+### Enterprise Starter
+
+Cody Pro users can also switch to the Enterprise Starter plan for **$19 per user per month**. This plan includes all the features of Cody Pro plus a multi-tenant Sourcegraph instance with core features like a fully managed version of Sourcegraph (AI + code search + intent detection with integrated search results, with privately indexed code) through a self-serve flow.
+
+Read more about the [Enterprise Starter plan](/pricing/enterprise-starter).
+
There will be high daily limits to catch bad actors and prevent abuse, but under most normal usage, Pro users won't experience these limits.
### Downgrading from Pro to Free
@@ -100,7 +96,7 @@ You can access your invoices via the [Cody Dashboard](https://sourcegraph.com/co
## Enterprise
-Cody Enterprise is designed for enterprises prioritizing security and administrative controls. We offer either seat-based or token based pricing models, depending on what makes most sense for your organization. You get Claude 3 (Opus and Sonnet 3.5) as the default LLM models without extra cost. You also get additional capabilities like BYOLLM (Bring Your Own LLM), supporting Single-Tenant and Self Hosted setups for flexible coding environments.
+Cody Enterprise is designed for enterprises prioritizing security and administrative controls. We offer either seat-based or token based pricing models, depending on what makes most sense for your organization. You get Claude Haiku 3.5 and Claude Sonnet 3.5 as the default LLM models without extra cost. You also get additional capabilities like BYOLLM (Bring Your Own LLM), supporting Single-Tenant and Self Hosted setups for flexible coding environments.
Security features include SAML/SSO for enhanced authentication and guardrails to enforce coding standards. Cody Enterprise supports advanced Code Graph context and multi-code host context for a deeper understanding of codebases, especially in complex projects. With 24/5 enhanced support, Cody Enterprise ensures timely assistance.
diff --git a/docs/legacy.mdx b/docs/legacy.mdx
index 11497bc5f..9f2be6f6c 100644
--- a/docs/legacy.mdx
+++ b/docs/legacy.mdx
@@ -2,6 +2,12 @@
This page displays the docs for legacy Sourcegraph versions less than 5.1
Learn about the Enterprise Starter plan tailored for individuals and teams wanting private code indexing and search to leverage the Sourcegraph platform better.