This repository was archived by the owner on Jun 19, 2025. It is now read-only.
Deriving commanded ZMP from DCM feedback #14
wyqsnddd
started this conversation in
Stabilizer
Replies: 1 comment
-
|
That's right, basically in feedback control you assume that your state estimate is correct. Here the state is the DCM, so this assumption amounts to In practice, state estimation errors are reflected into feedback errors. That's one reason why we have for instance steady-state errors. We add the integral term to compensate them as proposed in Balance control based on Capture Point error compensation for biped walking on uneven terrain. |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
The equation above eq. (9) of the paper Stair Climbing Stabilization of the HRP-4 Humanoid Robot using Whole-body Admittance Control looks a bit confusing.
We need to assume that
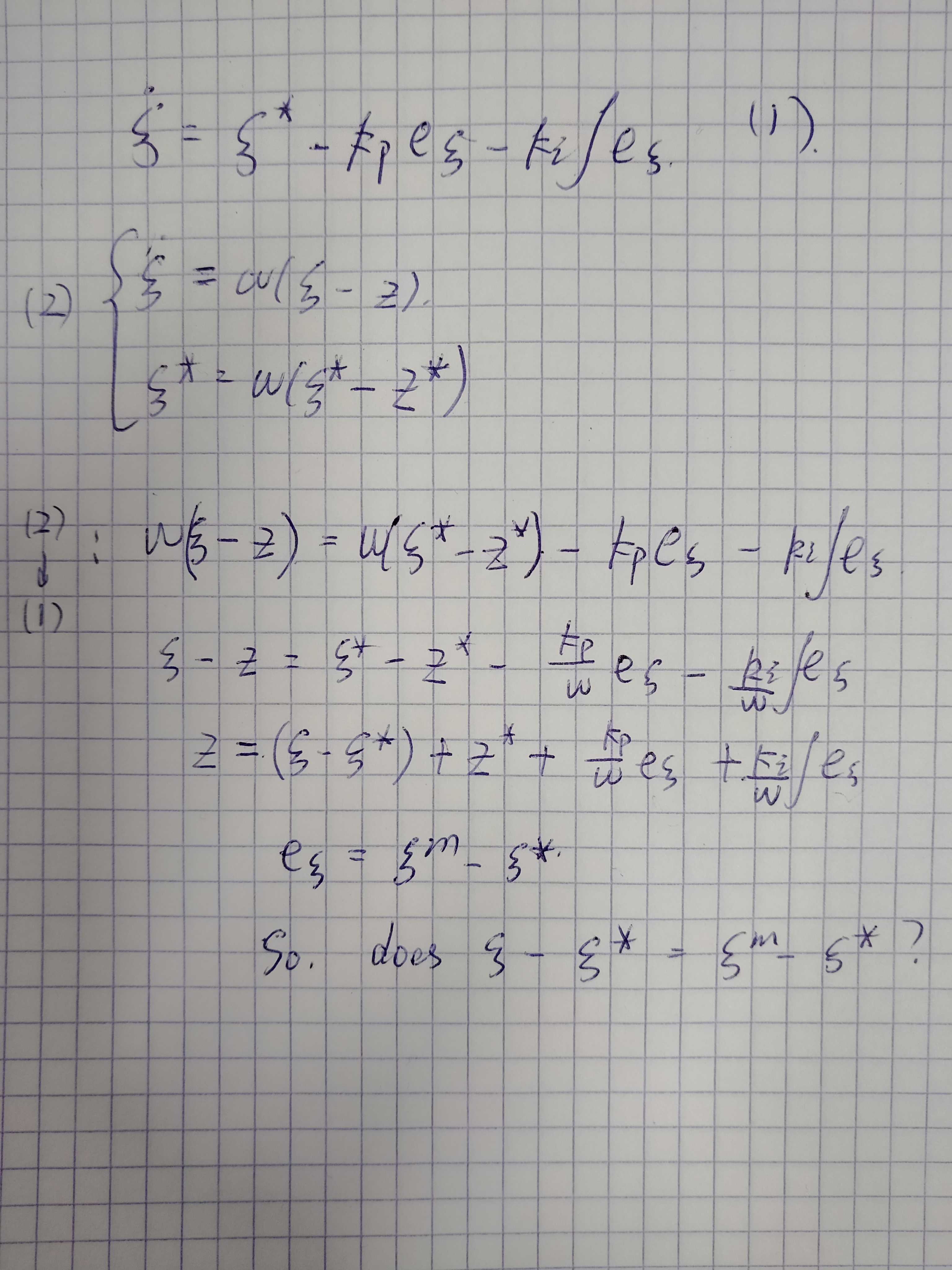
\xi - \xi^* = \xi^m - \xi^*to derive the equation, see details in the figure:Beta Was this translation helpful? Give feedback.
All reactions