Significant performance degradation in Kafka JMX metrics on upgrade #7944
Replies: 7 comments 17 replies
-
|
|
Beta Was this translation helpful? Give feedback.
-
|
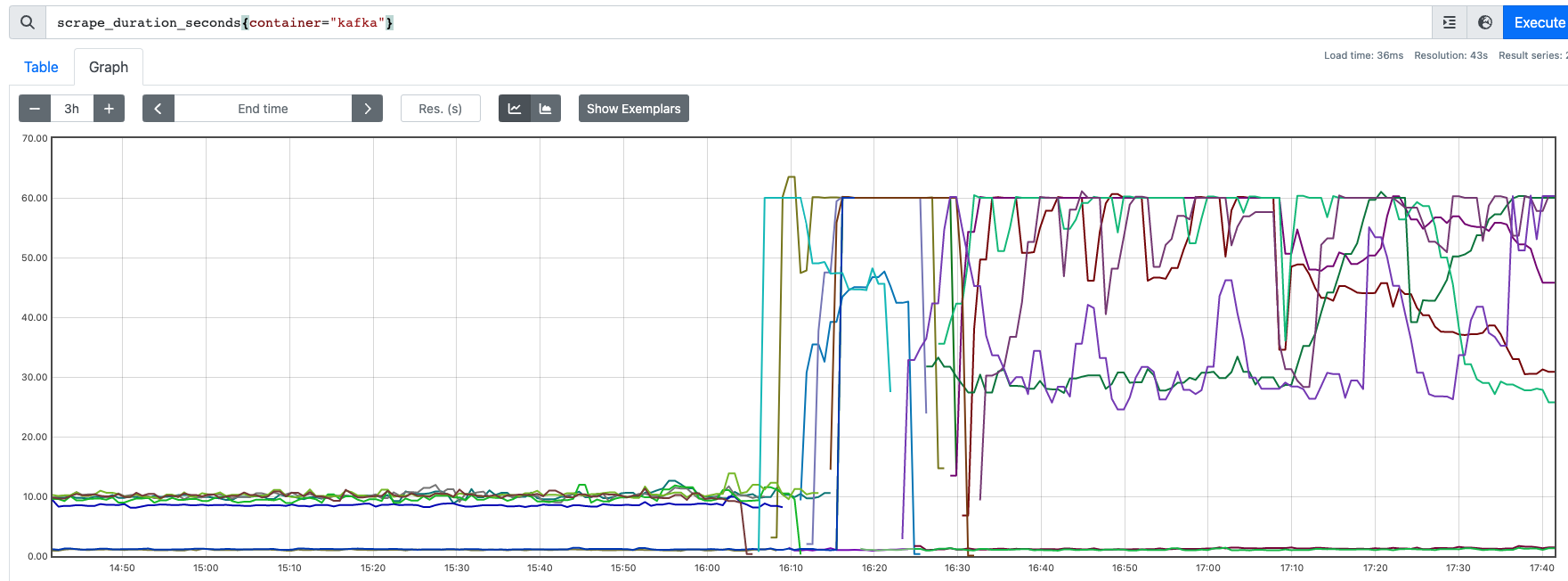
Maybe you can add some legend to the picture? Its not really clear what is what. There are some lines taking longer than before. But it is not clear what they belong to etc. |
Beta Was this translation helpful? Give feedback.
-
|
Apart from the obvious Kafka version change and change to its dependencies, there was an update to the JMX Prometheus Exporter. That could affect the performance. 0.32 uses the latest 0.17.2 version. I guess if you want, you can try to do a custom build of 0.32 with the older JMX Prometheus version to see if that might be related. I'm not aware of any other changes. |
Beta Was this translation helpful? Give feedback.
-
|
@scholzj apologies, you are right that a legend would have helped. Unfortunately I can't easily add that historically, though I could rerun the test if really needed. To clarify, these are the scrap time in seconds, with each line representing one Kafka broker. No other services e.g. Zookeeper are included. The low values on the left are the brokers when running 0.27.1-3.0.0. High values in the right are 0.32.0-3.3.1. Building with an older JMX Prometheus Exporter sounds like a good test. I will look into that today. Many thanks. |
Beta Was this translation helpful? Give feedback.
-
|
But what are all the different lines if it is one Kafka broker only? I assumed those might be different pods. |
Beta Was this translation helpful? Give feedback.
-
|
We have 8 brokers. It's one line per Kafka broker pod. |
Beta Was this translation helpful? Give feedback.
-
|
@scholzj thank you very much for your help last week. I didn't go back to an older version of the JMX Prometheus Exporter in the end, but the snippet of info that the metrics were coming from that exporter was very useful. I did some reading of the exporter docs and Github issues, and found many reports of people adding |
Beta Was this translation helpful? Give feedback.
-
|
Adding that config below for anyone who's interested. |
Beta Was this translation helpful? Give feedback.
-
|
Just noting that we experienced the same issue when upgrading from Strimzi 0.29.0 Kafka 3.0.1 to Strimzi 0.33.2 Kafka 3.3.2 (via Kafka 3.2.0). The difference is not as significant, but this is on a 3 broker cluster with almost no traffic on it. We also see liveness/readiness probe timeouts too. I'll also try |
Beta Was this translation helpful? Give feedback.
-
Assuming you mean timeouts of liveness / readiness probes in Kafka pods, that would suggest a lack of resources as the probes don't do really that much. |
Beta Was this translation helpful? Give feedback.
-
|
Confirm, same problem. Looks like strimzi team added new labels and this increased cardinality. |
Beta Was this translation helpful? Give feedback.
-
|
I think the performance of the JMX metrics was always kinda bad. It is possible that at some point we exposed more metrics. But I do not think we control the cardinality of the metrics as they are based of Kafka metrics. Also, keep in mind that this is configurable - so you are in control of what metrics are exposed and how they are labeled. |
Beta Was this translation helpful? Give feedback.
-
|
Well, I have to drop some labels you added in podMonitor resource: If you have a big enough kafka cluster metrics become a headacke. |
Beta Was this translation helpful? Give feedback.
-
|
We see the same performance problem after upgrading strimzi from I can confirm the jmx_exporter is the problem. I have build my own image where I downgrade the prometheus agent to 0.16.1 and it works with the same scrape time as before. My Dockerfile for the custom image: |
Beta Was this translation helpful? Give feedback.
-
|
Could you please test with latest version as well? |
Beta Was this translation helpful? Give feedback.
-
|
I will give it a try tomorrow |
Beta Was this translation helpful? Give feedback.
-
|
0.20.0 works well too. Its not significant faster but a little bit. From avg 20s to 17s per scrape. My cluster have 35000 replicas/partitions and 4 broker. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @flecno |
Beta Was this translation helpful? Give feedback.
-
|
With 0.16.1 is was around 20 seconds. You can see the deployment from 0.16 to 0.20 at 1:30pm |

Beta Was this translation helpful? Give feedback.
-
|
Hi @scholzj does it make sense to keep 2 versions of prometheus agents (old on - like a stable and new one and switch between them via feature flag) in single docker image? |
Beta Was this translation helpful? Give feedback.
-
|
Strimzi 0.38 will have JMX Exporter 0.20. But I do not think we have any plans to support multiple versions of it. It would be technically complicated, it would need to be tested somehow, etc. Also, doesn't the old JMX Exporter contain the SnakeYAML CVEs that would flag the container images in all scanners? |
Beta Was this translation helpful? Give feedback.
-
|
@vutkin I also tested with 0.18.0 which is bundled in Strimzi 0.37 and it looks good. No performance problem but the SnakeYAML CVE is fixed |
Beta Was this translation helpful? Give feedback.
-
|
BTW: @mimaison is looking into some other options how to replace the JMX Exporter completely with something that offers better performance. More details are here: strimzi/proposals#85 ... it is still work in progress, but I wanted to mention it. |
Beta Was this translation helpful? Give feedback.
-
|
Sure, I understand your concern. It seems like there might be a performance issue after upgrading your Kafka clusters. Have you checked if there are any specific configurations or settings that might have changed between the versions? Also, have you tried monitoring the system resources during these scrapes to see if there's any bottleneck causing the timeouts? |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Please use this to only for bug reports. For questions or when you need help, you can use the GitHub Discussions, our #strimzi Slack channel or out user mailing list.
Describe the bug
We have recently updated two of our cluster from operator
0.27.1to0.32.0, with a Kafka version upgrade from3.0.0to3.3.1.Following the update we have seen significant performance degradation in the scraping of JMX metrics. Previously scrapes would average around 10 seconds. Following the upgrade all scrapes are slower, with many timing out after 60 seconds.
To Reproduce
Steps to reproduce the behavior:
scrape_duration_secondsExpected behavior
I would expect to see little difference in performance between versions, and certainly not a degradation to the point where scrapes are timing out.
Environment (please complete the following information):
YAML files and logs
YAML Attached
output.yaml.zip
Beta Was this translation helpful? Give feedback.
All reactions