Taichi runs much slower on cpu backend than numba in non parallel mode when data amount is small #6057
Description
Question
I'm learning Taichi to accelerate my python code this days.
And I'm trying to test the performance of Taichi and Numba on tsunami simulating, which is an example in the book Modern Fortran, using my Intel mac book pro.
I rewrite the fortran code to Numba Version and Taichi Version. And for them, I tested both parallel and non parallel versions.
- When the data amount is small (float32 array with length of 10000), the non parallel versions run faster. But the code using Numba is much faster than the one using Taichi (both non parallel).
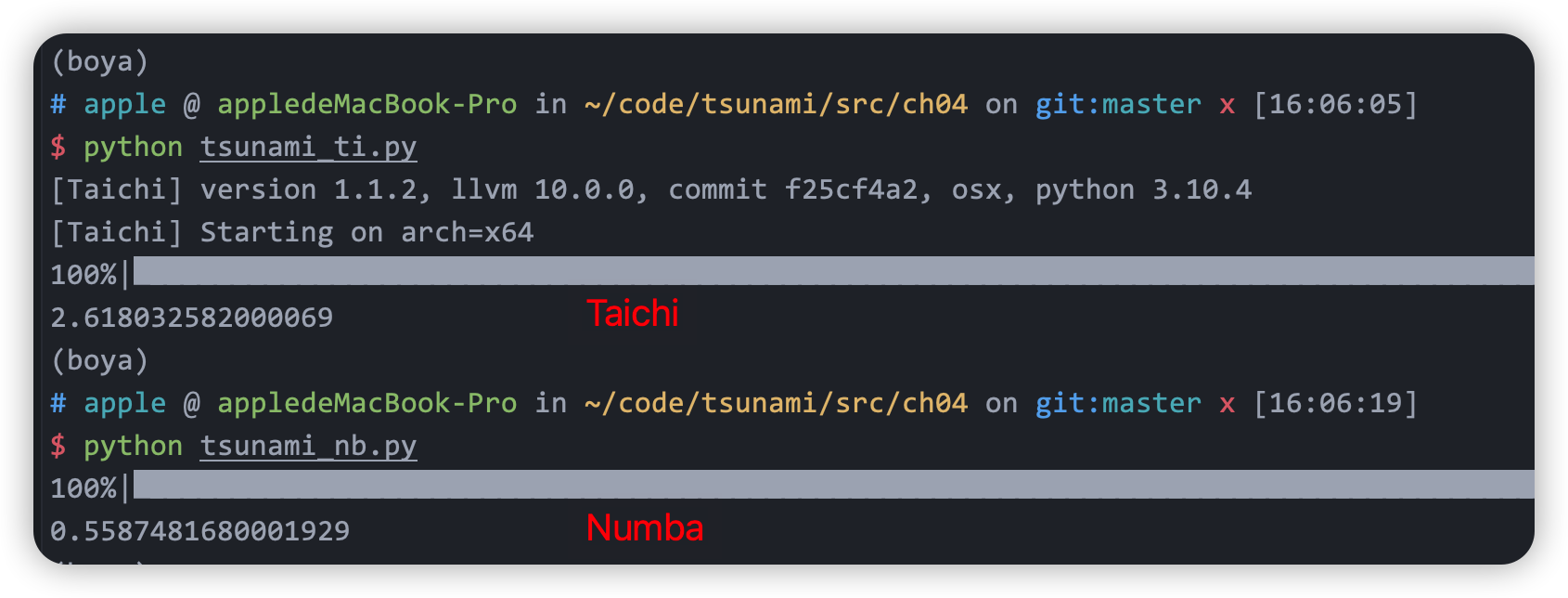
- I also test other situations, the results are shown in the following table
| Array Length - whether parallel | Taichi (s) | Numba (s) |
|---|---|---|
| 1000 - parallel | 7.904 | 42.473 |
| 1000 - non parallel | 2.618 | 0.559 |
| 10000 - parallel | 10.514 | 42.260 |
| 10000 - non parallel | 3.131 | 3.676 |
I can understand the performance of parallel version. But the low performance for Taichi of non parallel version confused me.
Code
Numba
import numpy as np
import numba as nb
import time
from tqdm import tqdm
PARALLEL = True
class Tsunami:
def __init__(
self, grid_size: int,
time_step: float, # [s]
grid_spacing: float, # [m]
g: float, # [m/s^2]
i_center: int,
decay: float,
h_mean: float, # [m] mean water depth
):
assert grid_size > 0, "grid size must be > 0"
assert time_step > 0, "time step must be > 0"
assert grid_spacing > 0, "grid spacing must be > 0"
self.i_center = i_center - 1 # fortran 代码下标从1开始,数值对应需要 -1
self.decay = decay
self.grid_size = grid_size
self.g = g
self.grid_spacing = grid_spacing
self.time_step = time_step
self.h_mean = h_mean
def run(self, num_time_steps: int):
# 初始化所有需要的内存
keys = ('h', 'u')
fields = {key: np.zeros(self.grid_size, dtype=np.float32) for key in keys}
set_gaussian(fields['h'], self.decay, self.i_center)
t1 = time.perf_counter()
for _ in tqdm(range(num_time_steps)):
step(g=self.g, grid_spacing=self.grid_spacing, time_step=self.time_step, h_mean=self.h_mean, **fields)
t2 = time.perf_counter()
print(t2 - t1)
return fields["h"]
@nb.njit(nogil=True, cache=True, parallel=PARALLEL)
def step(h, u, g, grid_spacing, time_step, h_mean):
u[:] = u - (u * diff_centered(u) + g * diff_centered(h)) / grid_spacing * time_step
h[:] = h - diff_centered(u * (h_mean + h)) / grid_spacing * time_step
@nb.njit(nogil=True, cache=True, parallel=PARALLEL)
def diff_centered(x):
"""
:param x: ti.field(ti.float32) 1D
"""
dx = np.empty(shape=x.shape, dtype=x.dtype)
grid_size = x.shape[0]
dx[0] = x[1] - x[grid_size - 1]
dx[grid_size - 1] = x[0] - x[grid_size - 2]
dx[1:grid_size - 1] = x[2:] - x[: grid_size - 2]
return dx
@nb.njit(nogil=True, cache=True, parallel=PARALLEL)
def set_gaussian(x, decay, i_center):
x[:] = np.exp(-decay * (np.arange(x.shape[0]) - i_center) ** 2)
if __name__ == "__main__":
tsunami = Tsunami(
grid_size=1000,
time_step=0.02,
grid_spacing=1,
g=9.8,
i_center=25,
decay=0.02,
h_mean=10
)
tsunami.run(50000)Taichi
import time
import taichi as ti
from tqdm import tqdm
ti.init(ti.cpu)
PARALLEL = True
@ti.data_oriented
class Tsunami:
def __init__(
self, grid_size: int,
time_step: float, # [s]
grid_spacing: float, # [m]
g: float, # [m/s^2]
i_center: int,
decay: float,
h_mean: float, # [m] mean water depth
):
assert grid_size > 0, "grid size must be > 0"
assert time_step > 0, "time step must be > 0"
assert grid_spacing > 0, "grid spacing must be > 0"
self.i_center = i_center - 1 # fortran 代码下标从1开始,数值对应需要 -1
self.decay = decay
self.grid_size = grid_size
self.g = g
self.grid_spacing = grid_spacing
self.time_step = time_step
self.h_mean = h_mean
def run(self, num_time_steps: int):
# 初始化所有需要的内存
keys = ('h1', 'd_h1', 'h2', 'd_h2', 'u', 'd_u')
fields = {key: ti.field(ti.float32, self.grid_size) for key in keys}
set_gaussian(fields['h1'], self.decay, self.i_center)
set_zero(fields['u']) # 初始化
t1 = time.perf_counter()
for _ in tqdm(range(num_time_steps)):
self.step(**fields)
t2 = time.perf_counter()
print(t2 - t1)
return fields["h1"]
@ti.kernel
def step(
self, h1: ti.template(),
d_h1: ti.template(),
h2: ti.template(),
d_h2: ti.template(),
u: ti.template(),
d_u: ti.template()
):
diff_centered(h1, d_h1)
diff_centered(u, d_u)
ti.loop_config(serialize=not PARALLEL)
for i in range(self.grid_size):
u[i] -= (u[i] * d_u[i] + self.g * d_h1[i]) / self.grid_spacing * self.time_step
h2[i] = u[i] * (self.h_mean + h1[i])
diff_centered(h2, d_h2)
ti.loop_config(serialize=not PARALLEL)
for i in range(self.grid_size):
h1[i] -= d_h2[i] / self.grid_spacing * self.time_step
@ti.func
def diff_centered(x, dx):
"""
:param x: ti.field(ti.float32) 1D
:param dx: ti.field(ti.float32) 1D
"""
grid_size = x.shape[0]
dx[0] = x[1] - x[grid_size - 1]
dx[grid_size - 1] = x[0] - x[grid_size - 2]
ti.loop_config(serialize=not PARALLEL)
for i in range(1, grid_size - 1):
dx[i] = x[i + 1] - x[i - 1]
@ti.kernel
def set_zero(x: ti.template()):
ti.loop_config(serialize=not PARALLEL)
for i in range(x.shape[0]):
x[i] = 0
@ti.kernel
def set_gaussian(x: ti.template(), decay: ti.template(), i_center: ti.template()):
ti.loop_config(serialize=not PARALLEL)
for i in range(x.shape[0]):
x[i] = ti.exp(-decay * (i - i_center) ** 2)
if __name__ == "__main__":
tsunami = Tsunami(
grid_size=1000,
time_step=0.02,
grid_spacing=1,
g=9.8,
i_center=25,
decay=0.02,
h_mean=10
)
tsunami.run(50000)Metadata
Metadata
Assignees
Labels
Type
Projects
Status