Build the index asynchronously after document are ingested rather than by consuming WAL #209
Description
Describe This Problem
We previously introduced WAL to decouple document ingestion and index construction (#117), which improves write throughput while ensuring write reliability.
However, as we all know, IO resource competition is a critical bottleneck in building a storage project, no matter whether the storage medium is a local disk or remote cloud storage.
Now there is an exact solution to reduce the IO resource consumption caused by reading WAL files. By the way, this optimization will also bring more real-time visibility to the documents just ingested.
Proposal
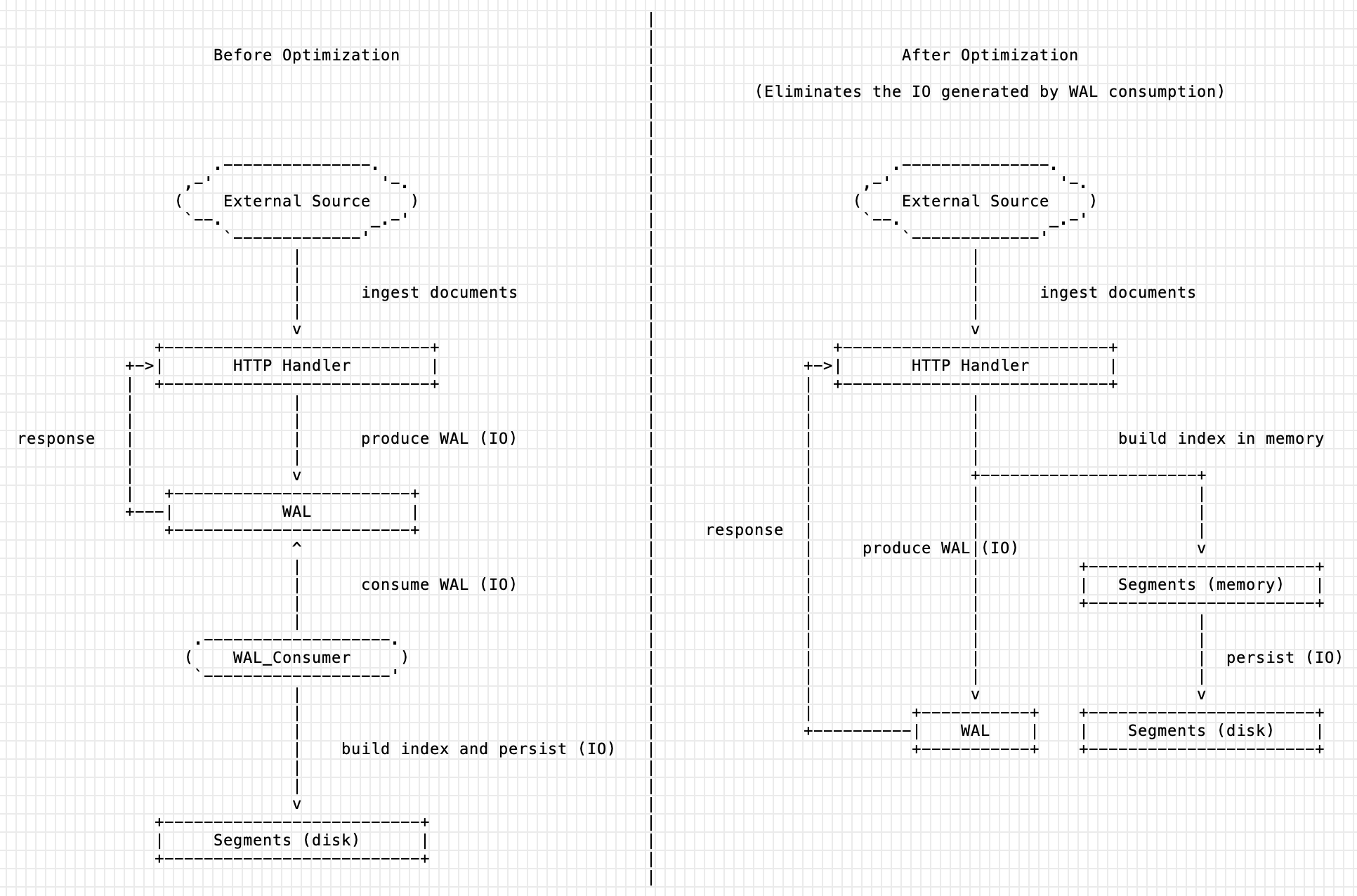
Additional Context
Since WAL will no longer be consumed in real-time (but only used to replay data when a failure occurs), how to keep its volume in an appropriate range also needs to be considered because now the log is truncated based on the consumption point, maybe there should be another POINT mechanic to accomplish this ability after the consumption behavior is removed.