CUDA benchmarks might be misleading #47
Description
I wanted to try to improve/modify the torchsort code a little so I tried making a copy of the SoftSort class and the soft_sort function.
Running some benchmarks I got the following results:


Which was worrying. The carbon copy diverges at a similar point to the figure in the readme:
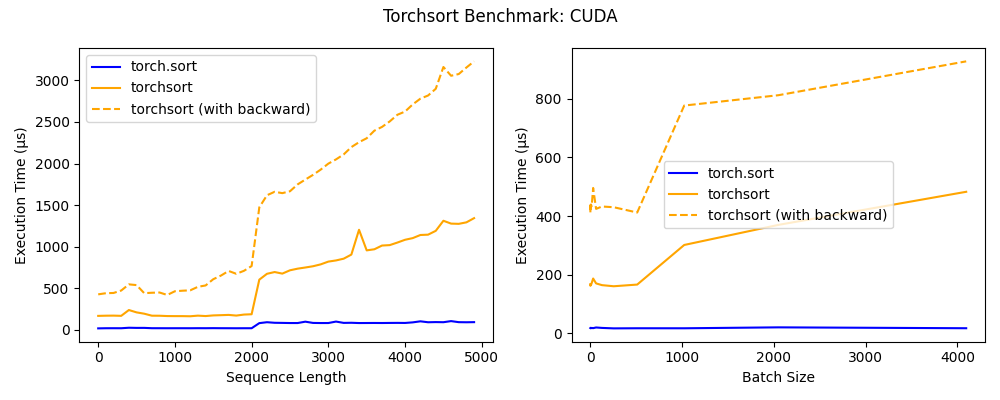
I then re-ran the benchmark with the exact same function twice (not even a copy) and got the same results.
That code can be found here:
import sys
from collections import defaultdict
from timeit import timeit
import matplotlib.pyplot as plt
import torch
import torchsort
try:
import fast_soft_sort.pytorch_ops as fss
except ImportError:
print("install fast_soft_sort:")
print("pip install git+https://github.com/google-research/fast-soft-sort")
sys.exit()
N = list(range(1, 5_000, 100))
B = [2 ** i for i in range(9)]
B_CUDA = [2 ** i for i in range(13)]
SAMPLES = 100
CONVERT = 1e-6 # convert seconds to micro-seconds
def time(f):
return timeit(f, number=SAMPLES) / SAMPLES / CONVERT
def backward(f, x):
y = f(x)
torch.autograd.grad(y.sum(), x)
def style(name):
if name == "torch.sort":
return {"color": "blue"}
linestyle = "--" if "backward" in name else "-"
if "fast_soft_sort" in name:
return {"color": "green", "linestyle": linestyle}
elif "again" in name:
return {"color": "red", "linestyle": linestyle}
else:
return {"color": "orange", "linestyle": linestyle}
def batch_size(ax):
data = defaultdict(list)
for b in B:
x = torch.randn(b, 100)
# data["torch.sort"].append(time(lambda: torch.sort(x)))
data["torchsort"].append(time(lambda: torchsort.soft_sort(x)))
data["torchsort_again"].append(time(lambda: torchsort.soft_sort(x)))
# data["fast_soft_sort"].append(time(lambda: fss.soft_sort(x)))
x = torch.randn(b, 100, requires_grad=True)
data["torchsort (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
data["torchsort_again (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
# data["fast_soft_sort (with backward)"].append(
# time(lambda: backward(fss.soft_sort, x))
# )
for label in data.keys():
ax.plot(B, data[label], label=label, **style(label))
ax.set_xlabel("Batch Size")
ax.set_ylim(0, 5000)
ax.set_ylabel("Execution Time (μs)")
ax.legend()
def sequence_length(ax):
data = defaultdict(list)
for n in N:
x = torch.randn(1, n)
# data["torch.sort"].append(time(lambda: torch.sort(x)))
data["torchsort"].append(time(lambda: torchsort.soft_sort(x)))
data["torchsort_again"].append(time(lambda: torchsort.soft_sort(x)))
# data["fast_soft_sort"].append(time(lambda: fss.soft_sort(x)))
x = torch.randn(1, n, requires_grad=True)
data["torchsort (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
data["torchsort_again (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
# data["fast_soft_sort (with backward)"].append(
# time(lambda: backward(fss.soft_sort, x))
# )
for label in data.keys():
ax.plot(N, data[label], label=label, **style(label))
ax.set_xlabel("Sequence Length")
ax.set_ylim(0, 1000)
ax.set_ylabel("Execution Time (μs)")
ax.legend()
def batch_size_cuda(ax):
data = defaultdict(list)
for b in B_CUDA:
x = torch.randn(b, 100).cuda()
# data["torch.sort"].append(time(lambda: torch.sort(x)))
data["torchsort"].append(time(lambda: torchsort.soft_sort(x)))
data["torchsort_again"].append(time(lambda: torchsort.soft_sort(x)))
x = torch.randn(b, 100, requires_grad=True).cuda()
data["torchsort (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
data["torchsort_again (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
for label in data.keys():
ax.plot(B_CUDA, data[label], label=label, **style(label))
ax.set_xlabel("Batch Size")
ax.set_ylabel("Execution Time (μs)")
ax.legend()
def sequence_length_cuda(ax):
data = defaultdict(list)
for n in N:
x = torch.randn(1, n).cuda()
# data["torch.sort"].append(time(lambda: torch.sort(x)))
data["torchsort"].append(time(lambda: torchsort.soft_sort(x)))
data["torchsort_again"].append(time(lambda: torchsort.soft_sort(x)))
x = torch.randn(1, n, requires_grad=True).cuda()
data["torchsort (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
data["torchsort_again (with backward)"].append(
time(lambda: backward(torchsort.soft_sort, x))
)
for label in data.keys():
ax.plot(N, data[label], label=label, **style(label))
ax.set_xlabel("Sequence Length")
ax.set_ylabel("Execution Time (μs)")
ax.legend()
if __name__ == "__main__":
# jit/warmup
x = torch.randn(1, 10, requires_grad=True)
backward(torchsort.soft_sort, x)
backward(fss.soft_sort, x)
fig, (ax1, ax2) = plt.subplots(figsize=(10, 4), ncols=2)
sequence_length(ax1)
batch_size(ax2)
fig.suptitle("Torchsort Benchmark: CPU")
fig.tight_layout()
plt.savefig("extra/benchmark3.png")
if torch.cuda.is_available():
# warmup
x = torch.randn(1, 10, requires_grad=True).cuda()
backward(torchsort.soft_sort, x)
fig, (ax1, ax2) = plt.subplots(figsize=(10, 4), ncols=2)
sequence_length_cuda(ax1)
batch_size_cuda(ax2)
fig.suptitle("Torchsort Benchmark: CUDA")
fig.tight_layout()
plt.savefig("extra/benchmark_cuda3.png")Any idea what this might depend on?