|
97 | 97 | }, |
98 | 98 | "outputs": [], |
99 | 99 | "source": [ |
100 | | - "!pip install remotezip tqdm opencv-python einops \n", |
| 100 | + "!pip install remotezip tqdm opencv-python einops\n", |
101 | 101 | "# Install TensorFlow 2.10\n", |
102 | 102 | "!pip install tensorflow==2.10.0" |
103 | 103 | ] |
|
156 | 156 | " List the files in each class of the dataset given the zip URL.\n", |
157 | 157 | "\n", |
158 | 158 | " Args:\n", |
159 | | - " zip_url: URL from which the files can be unzipped. \n", |
| 159 | + " zip_url: URL from which the files can be unzipped.\n", |
160 | 160 | "\n", |
161 | 161 | " Return:\n", |
162 | 162 | " files: List of files in each of the classes.\n", |
|
181 | 181 | "\n", |
182 | 182 | "def get_files_per_class(files):\n", |
183 | 183 | " \"\"\"\n", |
184 | | - " Retrieve the files that belong to each class. \n", |
| 184 | + " Retrieve the files that belong to each class.\n", |
185 | 185 | "\n", |
186 | 186 | " Args:\n", |
187 | 187 | " files: List of files in the dataset.\n", |
|
242 | 242 | " Args:\n", |
243 | 243 | " zip_url: Zip URL containing data.\n", |
244 | 244 | " num_classes: Number of labels.\n", |
245 | | - " splits: Dictionary specifying the training, validation, test, etc. (key) division of data \n", |
| 245 | + " splits: Dictionary specifying the training, validation, test, etc. (key) division of data\n", |
246 | 246 | " (value is number of files per split).\n", |
247 | 247 | " download_dir: Directory to download data to.\n", |
248 | 248 | "\n", |
|
282 | 282 | " Pad and resize an image from a video.\n", |
283 | 283 | " \n", |
284 | 284 | " Args:\n", |
285 | | - " frame: Image that needs to resized and padded. \n", |
| 285 | + " frame: Image that needs to resized and padded.\n", |
286 | 286 | " output_size: Pixel size of the output frame image.\n", |
287 | 287 | "\n", |
288 | 288 | " Return:\n", |
|
306 | 306 | " \"\"\"\n", |
307 | 307 | " # Read each video frame by frame\n", |
308 | 308 | " result = []\n", |
309 | | - " src = cv2.VideoCapture(str(video_path)) \n", |
| 309 | + " src = cv2.VideoCapture(str(video_path))\n", |
310 | 310 | "\n", |
311 | 311 | " video_length = src.get(cv2.CAP_PROP_FRAME_COUNT)\n", |
312 | 312 | "\n", |
|
338 | 338 | "\n", |
339 | 339 | "class FrameGenerator:\n", |
340 | 340 | " def __init__(self, path, n_frames, training = False):\n", |
341 | | - " \"\"\" Returns a set of frames with their associated label. \n", |
| 341 | + " \"\"\" Returns a set of frames with their associated label.\n", |
342 | 342 | "\n", |
343 | 343 | " Args:\n", |
344 | 344 | " path: Video file paths.\n", |
345 | | - " n_frames: Number of frames. \n", |
| 345 | + " n_frames: Number of frames.\n", |
346 | 346 | " training: Boolean to determine if training dataset is being created.\n", |
347 | 347 | " \"\"\"\n", |
348 | 348 | " self.path = path\n", |
|
365 | 365 | " random.shuffle(pairs)\n", |
366 | 366 | "\n", |
367 | 367 | " for path, name in pairs:\n", |
368 | | - " video_frames = frames_from_video_file(path, self.n_frames) \n", |
| 368 | + " video_frames = frames_from_video_file(path, self.n_frames)\n", |
369 | 369 | " label = self.class_ids_for_name[name] # Encode labels\n", |
370 | 370 | " yield video_frames, label" |
371 | 371 | ] |
|
380 | 380 | "source": [ |
381 | 381 | "URL = 'https://storage.googleapis.com/thumos14_files/UCF101_videos.zip'\n", |
382 | 382 | "download_dir = pathlib.Path('./UCF101_subset/')\n", |
383 | | - "subset_paths = download_ufc_101_subset(URL, \n", |
384 | | - " num_classes = 10, \n", |
| 383 | + "subset_paths = download_ufc_101_subset(URL,\n", |
| 384 | + " num_classes = 10,\n", |
385 | 385 | " splits = {\"train\": 30, \"val\": 10, \"test\": 10},\n", |
386 | 386 | " download_dir = download_dir)" |
387 | 387 | ] |
|
447 | 447 | "\n", |
448 | 448 | "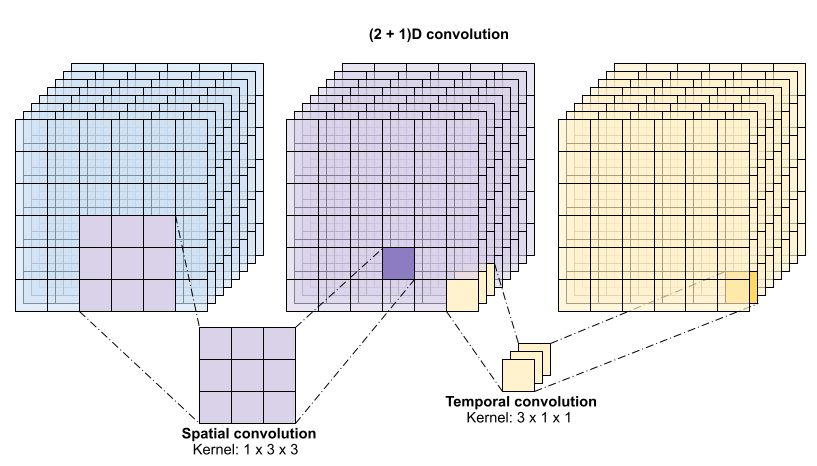\n", |
449 | 449 | "\n", |
450 | | - "The main advantage of this approach is that it reduces the number of parameters. In the (2 + 1)D convolution the spatial convolution takes in data of the shape `(1, width, height)`, while the temporal convolution takes in data of the shape `(time, 1, 1)`. For example, a (2 + 1)D convolution with kernel size `(3 x 3 x 3)` would need weight matrices of size `(9 * channels**2) + (3 * channels**2)`, less than half as many as the full 3D convolution. This tutorial implements (2 + 1)D ResNet18, where each convolution in the resnet is replaced by a (2+1)D convolution." |
| 450 | + "The main advantage of this approach is that it reduces the number of parameters. In the (2 + 1)D convolution the spatial convolution takes in data of the shape `(1, width, height)`, while the temporal convolution takes in data of the shape `(time, 1, 1)`. For example, a (2 + 1)D convolution with kernel size `(3 x 3 x 3)` would need weight matrices of size `(9 * channels**2) + (3 * channels**2)`, less than half as many as the full 3D convolution. This tutorial implements (2 + 1)D ResNet18, where each convolution in the ResNet is replaced by a (2+1)D convolution." |
451 | 451 | ] |
452 | 452 | }, |
453 | 453 | { |
|
499 | 499 | "id": "I-fCAddqEORZ" |
500 | 500 | }, |
501 | 501 | "source": [ |
502 | | - "A ResNet model resnet model is made from a sequence of residual blocks.\n", |
| 502 | + "A ResNet model is made from a sequence of residual blocks.\n", |
503 | 503 | "A residual block has two branches. The main branch performs the calculatoion, but is difficult for gradients to flow through.\n", |
504 | 504 | "The residual branch bypasses the main calculation and mostly just adds the input to the output of the main branch.\n", |
505 | 505 | "Gradients flow easily through this branch.\n", |
|
530 | 530 | " padding='same'),\n", |
531 | 531 | " layers.LayerNormalization(),\n", |
532 | 532 | " layers.ReLU(),\n", |
533 | | - " Conv2Plus1D(filters=filters, \n", |
| 533 | + " Conv2Plus1D(filters=filters,\n", |
534 | 534 | " kernel_size=kernel_size,\n", |
535 | 535 | " padding='same'),\n", |
536 | 536 | " layers.LayerNormalization()\n", |
|
559 | 559 | "source": [ |
560 | 560 | "class Project(keras.layers.Layer):\n", |
561 | 561 | " \"\"\"\n", |
562 | | - " Project certain dimensions of the tensor as the data is passed through different \n", |
563 | | - " sized filters and downsampled. \n", |
| 562 | + " Project certain dimensions of the tensor as the data is passed through different\n", |
| 563 | + " sized filters and downsampled.\n", |
564 | 564 | " \"\"\"\n", |
565 | 565 | " def __init__(self, units):\n", |
566 | 566 | " super().__init__()\n", |
|
595 | 595 | " Add residual blocks to the model. If the last dimensions of the input data\n", |
596 | 596 | " and filter size does not match, project it such that last dimension matches.\n", |
597 | 597 | " \"\"\"\n", |
598 | | - " out = ResidualMain(filters, \n", |
| 598 | + " out = ResidualMain(filters,\n", |
599 | 599 | " kernel_size)(input)\n", |
600 | | - " \n", |
| 600 | + "\n", |
601 | 601 | " res = input\n", |
602 | 602 | " # Using the Keras functional APIs, project the last dimension of the tensor to\n", |
603 | 603 | " # match the new filter size\n", |
|
633 | 633 | "\n", |
634 | 634 | " def call(self, video):\n", |
635 | 635 | " \"\"\"\n", |
636 | | - " Use the einops library to resize the tensor. \n", |
| 636 | + " Use the einops library to resize the tensor.\n", |
637 | 637 | " \n", |
638 | 638 | " Args:\n", |
639 | 639 | " video: Tensor representation of the video, in the form of a set of frames.\n", |
|
743 | 743 | }, |
744 | 744 | "outputs": [], |
745 | 745 | "source": [ |
746 | | - "model.compile(loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True), \n", |
747 | | - " optimizer = keras.optimizers.Adam(learning_rate = 0.0001), \n", |
| 746 | + "model.compile(loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n", |
| 747 | + " optimizer = keras.optimizers.Adam(learning_rate = 0.0001),\n", |
748 | 748 | " metrics = ['accuracy'])" |
749 | 749 | ] |
750 | 750 | }, |
|
813 | 813 | "\n", |
814 | 814 | " ax1.set_ylim([0, np.ceil(max_loss)])\n", |
815 | 815 | " ax1.set_xlabel('Epoch')\n", |
816 | | - " ax1.legend(['Train', 'Validation']) \n", |
| 816 | + " ax1.legend(['Train', 'Validation'])\n", |
817 | 817 | "\n", |
818 | 818 | " # Plot accuracy\n", |
819 | 819 | " ax2.set_title('Accuracy')\n", |
|
837 | 837 | "source": [ |
838 | 838 | "## Evaluate the model\n", |
839 | 839 | "\n", |
840 | | - "Use Keras `Model.evaluate` to get the loss and accuracy on the test dataset. \n", |
| 840 | + "Use Keras `Model.evaluate` to get the loss and accuracy on the test dataset.\n", |
841 | 841 | "\n", |
842 | 842 | "Note: The example model in this tutorial uses a subset of the UCF101 dataset to keep training time reasonable. The accuracy and loss can be improved with further hyperparameter tuning or more training data. " |
843 | 843 | ] |
|
870 | 870 | }, |
871 | 871 | "outputs": [], |
872 | 872 | "source": [ |
873 | | - "def get_actual_predicted_labels(dataset): \n", |
| 873 | + "def get_actual_predicted_labels(dataset):\n", |
874 | 874 | " \"\"\"\n", |
875 | 875 | " Create a list of actual ground truth values and the predictions from the model.\n", |
876 | 876 | "\n", |
|
968 | 968 | "def calculate_classification_metrics(y_actual, y_pred, labels):\n", |
969 | 969 | " \"\"\"\n", |
970 | 970 | " Calculate the precision and recall of a classification model using the ground truth and\n", |
971 | | - " predicted values. \n", |
| 971 | + " predicted values.\n", |
972 | 972 | "\n", |
973 | 973 | " Args:\n", |
974 | 974 | " y_actual: Ground truth labels.\n", |
|
989 | 989 | " row = cm[i, :]\n", |
990 | 990 | " fn = np.sum(row) - tp[i] # Sum of row minus true positive, is false negative\n", |
991 | 991 | " \n", |
992 | | - " precision[labels[i]] = tp[i] / (tp[i] + fp) # Precision \n", |
| 992 | + " precision[labels[i]] = tp[i] / (tp[i] + fp) # Precision\n", |
993 | 993 | " \n", |
994 | 994 | " recall[labels[i]] = tp[i] / (tp[i] + fn) # Recall\n", |
995 | 995 | " \n", |
|
0 commit comments