|
466 | 466 | "print(f\"Label: {labels.shape}\")" |
467 | 467 | ] |
468 | 468 | }, |
| 469 | + { |
| 470 | + "cell_type": "markdown", |
| 471 | + "metadata": { |
| 472 | + "id": "lxbhPqXGvc_F" |
| 473 | + }, |
| 474 | + "source": [ |
| 475 | + "## What are MoViNets?\n", |
| 476 | + "\n", |
| 477 | + "As mentioned previously, [MoViNets](https://arxiv.org/abs/2103.11511) are video classification models used for streaming video or online inference in tasks, such as action recognition. Consider using MoViNets to classify your video data for action recognition.\n", |
| 478 | + "\n", |
| 479 | + "A 2D frame based classifier is efficient and simple to run over whole videos, or streaming one frame at a time. Because they can't take temporal context into account they have limited accuracy and may give inconsistent outputs from frame to frame.\n", |
| 480 | + "\n", |
| 481 | + "A simple 3D CNN uses bidirectional temporal context which can increase accuracy and temporal consistency. These networks may require more resources and because they look into the future they can't be used for streaming data.\n", |
| 482 | + "\n", |
| 483 | + "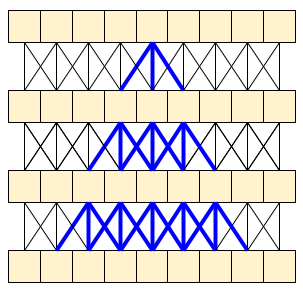\n", |
| 484 | + "\n", |
| 485 | + "The MoViNet architecture uses 3D convolutions that are \"causal\" along the time axis (like `layers.Conv1D` with `padding=\"causal\"`). This gives some of the advantages of both approaches, mainly it allow for efficient streaming.\n", |
| 486 | + "\n", |
| 487 | + "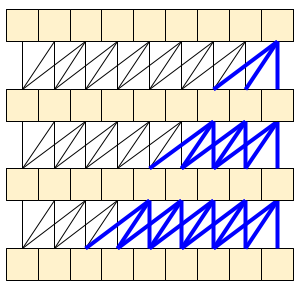\n", |
| 488 | + "\n", |
| 489 | + "Causal convolution ensures that the output at time *t* is computed using only inputs up to time *t*. To demonstrate how this can make streaming more efficient, start with a simpler example you may be familiar with: an RNN. The RNN passes state forward through time:\n", |
| 490 | + "\n", |
| 491 | + "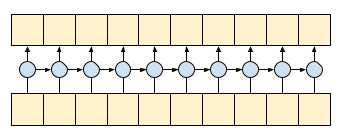" |
| 492 | + ] |
| 493 | + }, |
| 494 | + { |
| 495 | + "cell_type": "code", |
| 496 | + "execution_count": null, |
| 497 | + "metadata": { |
| 498 | + "id": "dMvDkgfFZC6a" |
| 499 | + }, |
| 500 | + "outputs": [], |
| 501 | + "source": [ |
| 502 | + "gru = layers.GRU(units=4, return_sequences=True, return_state=True)\n", |
| 503 | + "\n", |
| 504 | + "inputs = tf.random.normal(shape=[1, 10, 8]) # (batch, sequence, channels)\n", |
| 505 | + "\n", |
| 506 | + "result, state = gru(inputs) # Run it all at once" |
| 507 | + ] |
| 508 | + }, |
| 509 | + { |
| 510 | + "cell_type": "markdown", |
| 511 | + "metadata": { |
| 512 | + "id": "T7xyb5C4bTs7" |
| 513 | + }, |
| 514 | + "source": [ |
| 515 | + "By setting the RNN's `return_sequences=True` argument you ask it to return the state at the end of the computation. This allows you to pause and then continue where you left off, to get exactly the same result:\n", |
| 516 | + "\n", |
| 517 | + "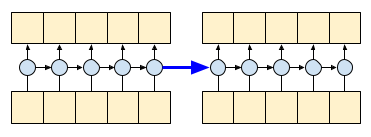" |
| 518 | + ] |
| 519 | + }, |
| 520 | + { |
| 521 | + "cell_type": "code", |
| 522 | + "execution_count": null, |
| 523 | + "metadata": { |
| 524 | + "id": "bI8FOPRRXXPa" |
| 525 | + }, |
| 526 | + "outputs": [], |
| 527 | + "source": [ |
| 528 | + "first_half, state = gru(inputs[:, :5, :]) # run the first half, and capture the state\n", |
| 529 | + "second_half, _ = gru(inputs[:,5:, :], initial_state=state) # Use the state to continue where you left off.\n", |
| 530 | + "\n", |
| 531 | + "print(np.allclose(result[:, :5,:], first_half))\n", |
| 532 | + "print(np.allclose(result[:, 5:,:], second_half))" |
| 533 | + ] |
| 534 | + }, |
| 535 | + { |
| 536 | + "cell_type": "markdown", |
| 537 | + "metadata": { |
| 538 | + "id": "KM3MArumY_Qk" |
| 539 | + }, |
| 540 | + "source": [ |
| 541 | + "Causal convolutions can be used the same way, if handled with care. This technique was used in the [Fast Wavenet Generation Algorithm](https://arxiv.org/abs/1611.09482) by Le Paine et al. In the [MoVinet paper](https://arxiv.org/abs/2103.11511), the `state` is referred to as the \"Stream Buffer\".\n", |
| 542 | + "\n", |
| 543 | + "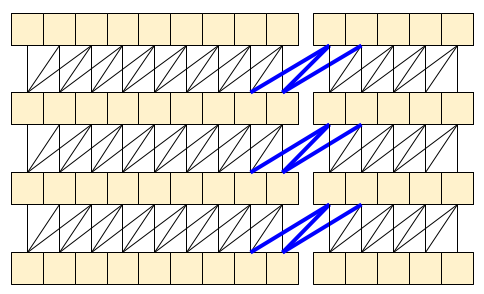\n", |
| 544 | + "\n", |
| 545 | + "By passing this little bit of state forward, you can avoid recalculating the whole receptive field that shown above. " |
| 546 | + ] |
| 547 | + }, |
469 | 548 | { |
470 | 549 | "cell_type": "markdown", |
471 | 550 | "metadata": { |
472 | 551 | "id": "1UsxiPs8yA2e" |
473 | 552 | }, |
474 | 553 | "source": [ |
475 | | - "## Download pre-trained MoViNet model\n", |
| 554 | + "## Download a pre-trained MoViNet model\n", |
476 | 555 | "\n", |
477 | 556 | "In this section, you will:\n", |
478 | 557 | "\n", |
479 | 558 | "1. You can create a MoViNet model using the open source code provided in [`official/projects/movinet`](https://github.com/tensorflow/models/tree/master/official/projects/movinet) from TensorFlow models.\n", |
480 | 559 | "2. Load the pretrained weights. \n", |
481 | | - "3. Freeze the convolutional base, or all other layers except the final classifier head, in order to speed up fine-tuning.\n", |
| 560 | + "3. Freeze the convolutional base, or all other layers except the final classifier head, to speed up fine-tuning.\n", |
482 | 561 | "\n", |
483 | | - "To build the model, you can start with the `a0` configuration because it is the fastest to train when benchmarked against other models. Check out the [available models](https://github.com/tensorflow/models/blob/master/official/projects/movinet/configs/movinet.py) to see what might work for your use-case." |
| 562 | + "To build the model, you can start with the `a0` configuration because it is the fastest to train when benchmarked against other models. Check out the [available MoViNet models on TensorFlow Model Garden](https://github.com/tensorflow/models/blob/master/official/projects/movinet/configs/movinet.py) to find what might work for your use case." |
484 | 563 | ] |
485 | 564 | }, |
486 | 565 | { |
|
520 | 599 | "id": "BW23HVNtCXff" |
521 | 600 | }, |
522 | 601 | "source": [ |
523 | | - "To build a classifier, create a function that takes the backbone and the number of classes in a dataset. The `build_classifier` function will take the backbone and the number of classes in a dataset in order to build the classifier. In this case, the new classifier will take a `num_classes` outputs (10 classes for this subset of UCF101)." |
| 602 | + "To build a classifier, create a function that takes the backbone and the number of classes in a dataset. The `build_classifier` function will take the backbone and the number of classes in a dataset to build the classifier. In this case, the new classifier will take a `num_classes` outputs (10 classes for this subset of UCF101)." |
524 | 603 | ] |
525 | 604 | }, |
526 | 605 | { |
|
633 | 712 | "id": "OkFst2gsHBwD" |
634 | 713 | }, |
635 | 714 | "source": [ |
636 | | - "To visualize model performance further, use a [confusion matrix](https://www.tensorflow.org/api_docs/python/tf/math/confusion_matrix). The confusion matrix allows you to assess the performance of the classification model beyond accuracy. In order to build the confusion matrix for this multi-class classification problem, get the actual values in the test set and the predicted values." |
| 715 | + "To visualize model performance further, use a [confusion matrix](https://www.tensorflow.org/api_docs/python/tf/math/confusion_matrix). The confusion matrix allows you to assess the performance of the classification model beyond accuracy. To build the confusion matrix for this multi-class classification problem, get the actual values in the test set and the predicted values." |
637 | 716 | ] |
638 | 717 | }, |
639 | 718 | { |
|
718 | 797 | "source": [ |
719 | 798 | "## Next steps\n", |
720 | 799 | "\n", |
721 | | - "Now that you have some familiarity with the MoViNet model and how to leverage various TensorFlow APIs (for example, for transfer learning), try using the code in this tutorial with your own dataset. The data does not have to be limited to video data. Volumetric data, such as MRI scans, can also be used with 3D CNNs. The NUSDAT and IMH datasets mentioned in [Brain MRI-based 3D Convolutional Neural Networks for\n", |
722 | | - "Classification of Schizophrenia and Controls ](https://arxiv.org/pdf/2003.08818.pdf) could be two such sources for MRI data.\n", |
| 800 | + "Now that you have some familiarity with the MoViNet model and how to leverage various TensorFlow APIs (for example, for transfer learning), try using the code in this tutorial with your own dataset. The data does not have to be limited to video data. Volumetric data, such as MRI scans, can also be used with 3D CNNs. The NUSDAT and IMH datasets mentioned in [Brain MRI-based 3D Convolutional Neural Networks for Classification of Schizophrenia and Controls](https://arxiv.org/pdf/2003.08818.pdf) could be two such sources for MRI data.\n", |
723 | 801 | "\n", |
724 | 802 | "In particular, using the `FrameGenerator` class used in this tutorial and the other video data and classification tutorials will help you load data into your models.\n", |
725 | 803 | "\n", |
|
0 commit comments