|
1 | 1 |
|
2 | 2 | # Introduction |
3 | 3 |
|
4 | | -自动监听并录制B站直播和弹幕(含付费留言、礼物等),根据分辨率转换弹幕、语音识别字幕并渲染进视频,根据弹幕密度切分精彩片段并通过视频理解大模型生成有趣的标题,自动投稿视频和切片至B站,兼容无GPU版本,兼容超低配置服务器与主机。 |
| 4 | +> **Warning: This project is only for learning and exchange, please record after obtaining the consent of the other party, please do not use the content without authorization for commercial purposes, please do not use it for large-scale recording, otherwise it will be banned by the official, legal consequences will be self-borne.** |
5 | 5 |
|
6 | | -## Major features |
7 | | - |
8 | | -- **速度快**:采用 `pipeline` 流水线处理视频,理想情况下录播与直播相差半小时以内,没下播就能上线录播,**目前已知 b 站录播最快版本**! |
9 | | -- **多房间**:同时录制多个直播间内容视频以及弹幕文件(包含普通弹幕,付费弹幕以及礼物上舰等信息)。 |
10 | | -- **占用小**:自动删除本地已上传的视频,极致节省空间。 |
11 | | -- **模版化**:无需复杂配置,开箱即用,( :tada: NEW)通过 b 站搜索建议接口自动抓取相关热门标签。 |
12 | | -- **检测片段并合并**:对于网络问题或者直播连线导致的视频流分段,能够自动检测合并成为完整视频。 |
13 | | -- **自动渲染弹幕**:自动转换xml为ass弹幕文件并且渲染到视频中形成**有弹幕版视频**并自动上传。 |
14 | | -- **硬件要求极低**:无需GPU,只需最基础的单核CPU搭配最低的运存即可完成录制,弹幕渲染,上传等等全部过程,无最低配置要求,10年前的电脑或服务器依然可以使用! |
15 | | -- **( :tada: NEW)自动渲染字幕**(如需使用本功能,则需保证有 Nvidia 显卡):采用 OpenAI 的开源模型 [`whisper`](https://github.com/openai/whisper),自动识别视频内语音并转换为字幕渲染至视频中。 |
16 | | -- **( :tada: NEW)自动切片上传**:根据弹幕密度计算寻找高能片段并切片,结合多模态视频理解大模型 [`GLM-4V-PLUS`](https://bigmodel.cn/dev/api/normal-model/glm-4) 自动生成有意思的切片标题及内容,并且自动上传。 |
17 | | - |
18 | | - |
19 | | -## Architecture diagram |
| 6 | +Automatically monitors and records Bilibili live broadcasts and danmaku (including paid comments, gifts, etc.), converts danmaku according to resolution, recognizes speech and renders subtitles into videos, splits exciting fragments according to danmaku density, and generates interesting titles through video understanding models, automatically generates video covers using image generation models, and automatically posts videos and slices to Bilibili, compatible with the version without GPU, compatible with low-configuration servers and hosts. |
20 | 7 |
|
21 | | -项目架构流程如下: |
22 | | - |
23 | | -```mermaid |
24 | | -graph TD |
25 | | - User((用户))--record-->startRecord(启动录制) |
26 | | - startRecord(启动录制)--保存视频和字幕文件-->videoFolder[(Video 文件夹)] |
27 | | -
|
28 | | - User((用户))--scan-->startScan(启动扫描 Video 文件夹) |
29 | | - videoFolder[(Video 文件夹)]<--间隔两分钟扫描一次-->startScan(启动扫描 Video 文件夹) |
30 | | - startScan <--视频文件--> whisper[whisperASR模型] |
31 | | - whisper[whisperASR模型] --生成字幕-->parameter[查询视频分辨率] |
32 | | - subgraph 启动新进程 |
33 | | - parameter[查询分辨率] -->ifDanmaku{判断} |
34 | | - ifDanmaku -->|有弹幕| DanmakuConvert[DanmakuConvert] |
35 | | - ifDanmaku -->|无弹幕| ffmpeg1[ffmpeg] |
36 | | - DanmakuConvert[DanmakuConvert] --根据分辨率转换弹幕--> ffmpeg1[ffmpeg] |
37 | | - ffmpeg1[ffmpeg] --渲染弹幕及字幕 --> Video[视频文件] |
38 | | - Video[视频文件] --计算弹幕密度并切片--> GLM[多模态视频理解模型] |
39 | | - GLM[多模态视频理解模型] --生成切片信息--> slice[视频切片] |
40 | | - end |
41 | | - |
42 | | - slice[视频切片] --> uploadQueue[(上传队列)] |
43 | | - Video[视频文件] --> uploadQueue[(上传队列)] |
| 8 | +## Major features |
44 | 9 |
|
45 | | - User((用户))--upload-->startUpload(启动视频上传进程) |
46 | | - startUpload(启动视频上传进程) <--扫描队列并上传视频--> uploadQueue[(上传队列)] |
47 | | -``` |
| 10 | +- **Fast**:Use the `pipeline` pipeline to process videos, in ideal conditions, the recording and live broadcast differ by half an hour, and the recording can be上线录播,**Currently the fastest version of Bilibili recording**! |
| 11 | +- **( 🎉 NEW)Multi-architecture**:Compatible with amd64 and arm64 architectures! |
| 12 | +- **Multiple rooms**:Simultaneously record the content of multiple live broadcast rooms and danmaku files (including normal danmaku, paid danmaku, and gift-up-ship information). |
| 13 | +- **Small memory usage**:Automatically delete locally uploaded videos, saving space. |
| 14 | +- **Template**:No complex configuration, ready to use, automatically fetch related popular tags through the Bilibili search suggestion interface. |
| 15 | +- **Detect and merge segments**:For video stream segments caused by network issues or live broadcast connection issues, it can automatically detect and merge them into complete videos. |
| 16 | +- **Automatically render danmaku**:Automatically convert xml to ass danmaku file, the danmaku conversion tool library has been open source [DanmakuConvert](https://github.com/timerring/DanmakuConvert) and rendered to the video to form **danmaku version video** and automatically upload. |
| 17 | +- **Low hardware requirements**:No GPU required, only the most basic single-core CPU and the lowest memory can complete the recording, danmaku rendering, upload, etc. All processes, no minimum configuration requirements, 10-year-old computers or servers can still be used! |
| 18 | +- **( :tada: NEW)Automatically render subtitles**:Use the OpenAI open source model `whisper`, automatically identify the speech in the video and convert it to subtitles, and render it to the video. |
| 19 | +- **( :tada: NEW)Auto-slice upload**:Calculate the danmaku density and find the high-energy fragments, the auto-slice tool library has been open source [auto-slice-video](https://github.com/timerring/auto-slice-video), combine the multi-modal video understanding large model to automatically generate interesting slice titles and content, and automatically upload, currently supported models: |
| 20 | + - `GLM-4V-PLUS` |
| 21 | + - `Gemini-2.0-flash` |
| 22 | + - `Qwen-2.5-72B-Instruct` |
| 23 | +- **( :tada: NEW)Persistent login/download/upload video (supports multi-part posting)**:[bilitool](https://github.com/timerring/bilitool) has been open source, implements persistent login, download video and danmaku (including multi-part)/upload video (can post multi-part), query posting status, query detailed information, etc., one-click pip installation, can be operated using the command line cli, and can also be used as an api call. |
| 24 | +- **( :tada: NEW)Auto-loop multi-platform live streaming**:The tool has been open source [looplive](https://github.com/timerring/looplive) is a 7 x 24 hours fully automatic **loop multi-platform live streaming** tool. |
| 25 | +- **( :tada: NEW)Generate style-transformed video covers**:Use the image-to-image multi-modal model to automatically obtain the video screenshot and upload the style-transformed video cover. |
| 26 | + - `Minimax image-01` |
| 27 | + - `Kwai Kolors` |
| 28 | + - `Tencent Hunyuan` |
| 29 | + - `Baidu ERNIE irag-1.0` |
| 30 | + - `Stable Diffusion 3.5 large turbo` |
| 31 | + - `Luma Photon` |
| 32 | + - `Ideogram V_2` |
| 33 | + - `Recraft` |
| 34 | + - `Amazon Titan Image Generator V2` |
| 35 | + |
| 36 | +The project architecture process is as follows: |
| 37 | + |
| 38 | +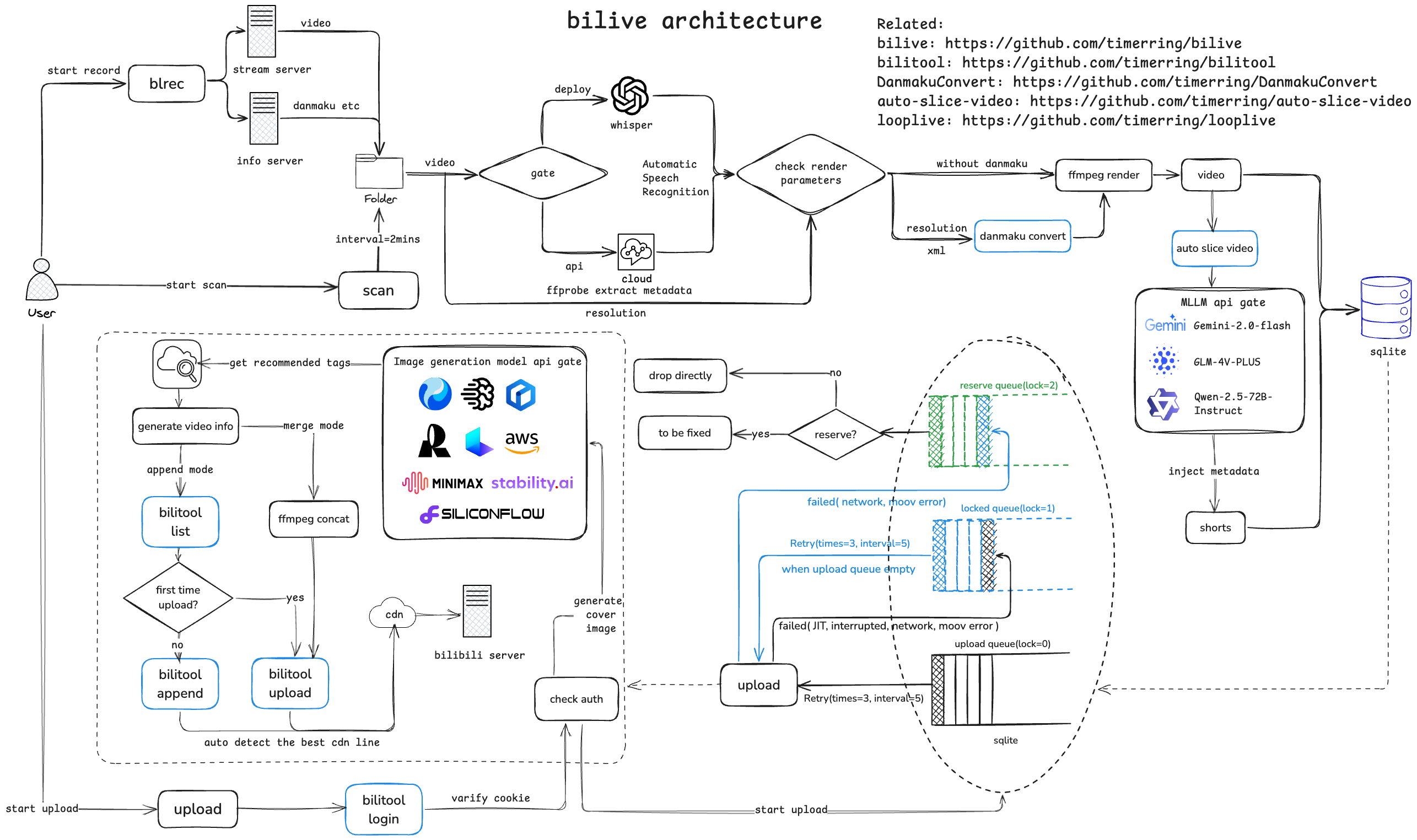 |
0 commit comments