You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: about/changelog.md
+39-1Lines changed: 39 additions & 1 deletion
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -9,6 +9,43 @@ products: [cloud]
9
9
10
10
All the latest features and updates to $CLOUD_LONG.
11
11
12
+
## 🧭 Activity log and TimescaleDB v2.24
13
+
<Labeltype="date">December 12, 2025</Label>
14
+
15
+
### Activity log
16
+
Tiger Cloud Console now offers the `Activity` tab that displays the activity log for all your services. This serves as a record of actions that have happened to your services and Tiger Cloud account, such as service resizes and project invitations. The activity log includes the corresponding service (where applicable), the user who performed the action, and a description of the action itself. You can suggest new actions to record on the `Activity` tab.
17
+
18
+
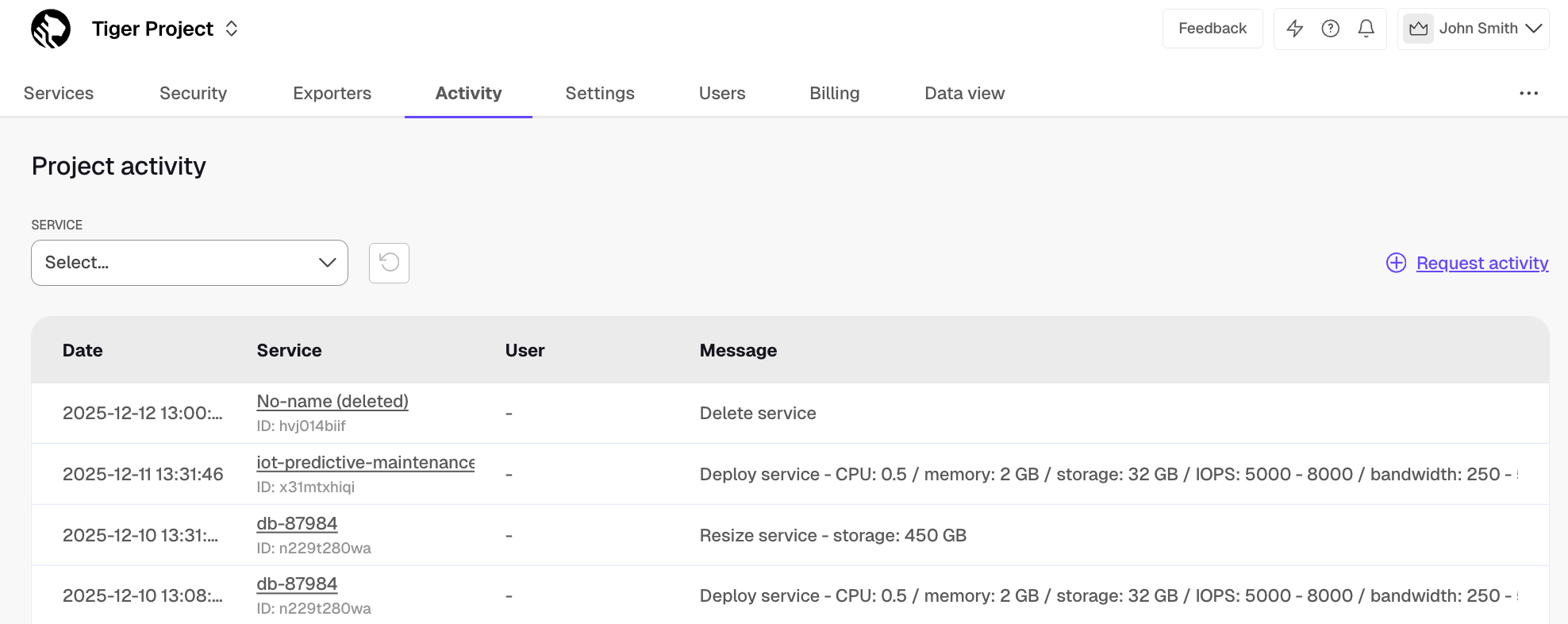
19
+
20
+
### TimescaleDB 2.24
21
+
TimescaleDB 2.24 was released on December 3rd and is now available to all users on Tiger Cloud. TimescaleDB 2.24 delivers more efficient recompression operations, expanded use of continuous aggregates, and better invalidation behavior. It also brings back support for bloom filters on ARM-based architectures.
22
+
23
+
#### Highlighted features in TimescaleDB 2.24
24
+
25
+
**In-memory recompression**
26
+
27
+
A new `recompress := true` option for `convert_to_columnstore()` performs batch compaction entirely in memory.
28
+
29
+
For example: `CALL convert_to_columnstore('<chunk_name>', recompress := true);`
30
+
31
+
This approach is 4–5 times faster than the previous spill-to-disk method, and reduces I/O for workloads with many small or uneven batches. This can be helpful if you are ingesting unordered data via direct compress and need to optimize your batches, or when you add new sparse indexes and need to build them on existing chunks.
32
+
33
+
**Bloom filters on ARM-based Tiger Cloud services**
34
+
35
+
On ARM-based Tiger Cloud services, bloom filters return with corrected hashing support for the ARM architecture. A misconfigured hashing library previously required disabling bloom indexes on ARM-based services. This release restores bloom filter functionality with a new index version.
36
+
37
+
For self-hosted TimescaleDB users, nothing changes if you're using an AMD64 architecture. Otherwise, please [see here](https://github.com/timescale/timescaledb/pull/8761#user-content-changelog). For Tiger Cloud customers, recompression is only required for services where you want to rebuild bloom filters on existing chunks. New chunks receive bloom indexes automatically.
38
+
39
+
**Continuous aggregate updates**
40
+
41
+
-**Smarter invalidation range capping** prevents massive refresh windows when out-of-order or faulty timestamps span large gaps. Invalidation now stays bounded to chunk ranges, reducing unnecessary refresh work.
42
+
43
+
-**Direct compress invalidation support** enables continuous aggregates on hypertables that ingest directly into the columnstore. Min/max batch timestamps now generate invalidation entries without needing row-level WAL.
44
+
45
+
-**UUIDv7 support** unlocks continuous aggregates on UUIDv7-partitioned tables through an extended `time_bucket()` that accepts UUIDv7 and outputs a timestamp.
46
+
47
+
For complete details, refer to the [TimescaleDB 2.24 release notes](https://github.com/timescale/timescaledb/releases/tag/2.24.0).
48
+
12
49
## New navigation in Console
13
50
<Labeltype="date">December 5, 2025</Label>
14
51
@@ -23,7 +60,7 @@ We have updated the design of the navigation in Console to improve consistency,
23
60
24
61
The S3 source connector is now production-ready, delivering major improvements in reliability, performance, and correctness across the entire ingestion pipeline. We resolved extensive issues related to file state transitions, workflow ordering, live sync consistency, and error handling, while adding support for retries, skipping files, better conflict handling, and more stable pause/resume behavior. Import operations are now more resilient, deterministic, and traceable, with clearer progress reporting and more accurate file and worker state visibility.
25
62
26
-
Performance and scalability have been significantly enhanced through better autoscaling, improved worker resource allocation, faster preview and import operations, optimized scheduling, reduced memory usage, and higher throughput for small and large files.
63
+
Performance and scalability have been significantly enhanced through better autoscaling, improved worker resource allocation, faster preview and import operations, optimized scheduling, reduced memory usage, and higher throughput for small and large files.
27
64
28
65
The user experience has been upgraded across the UI with improved file filtering, pagination, column mapping, input validation, clearer states and sizes, and more robust multi-step flows. Numerous bugs affecting import previews, table selection, schema handling, hypertable creation, and navigation were fixed. Combined, these changes make the S3 source connector significantly more stable, predictable, and user-friendly—ready for GA adoption.
29
66
@@ -49,6 +86,7 @@ Tiger Lake is now available in public beta and ready for broader use. The public
49
86
50
87
Read the [documentation](https://www.tigerdata.com/docs/use-timescale/latest/tigerlake) to get started.
0 commit comments