RLHF模块构建了完整的人类反馈强化学习技术栈,集成前沿的偏好优化和人类对齐框架。核心框架包括:Huggingface TRL(Transformer强化学习标准库,PPO训练详解)、OpenRLHF(易用可扩展RLHF框架,支持70B+ PPO全量微调、迭代DPO、LoRA和RingAttention)、字节veRL(火山引擎强化学习框架,工业级部署)、EasyR1(基于veRL的高效多模态RL训练框架)。
创新技术融入通义WorldPM(72B参数的世界偏好模型,引领偏好建模新范式)等前沿研究成果。技术覆盖从PPO(Proximal Policy Optimization)算法实现、DPO(Direct Preference Optimization)直接偏好优化,到GRPO等先进算法,支持全参数微调、LoRA高效微调等多种训练模式,为大模型的人类价值对齐提供从理论到实践的完整解决方案。
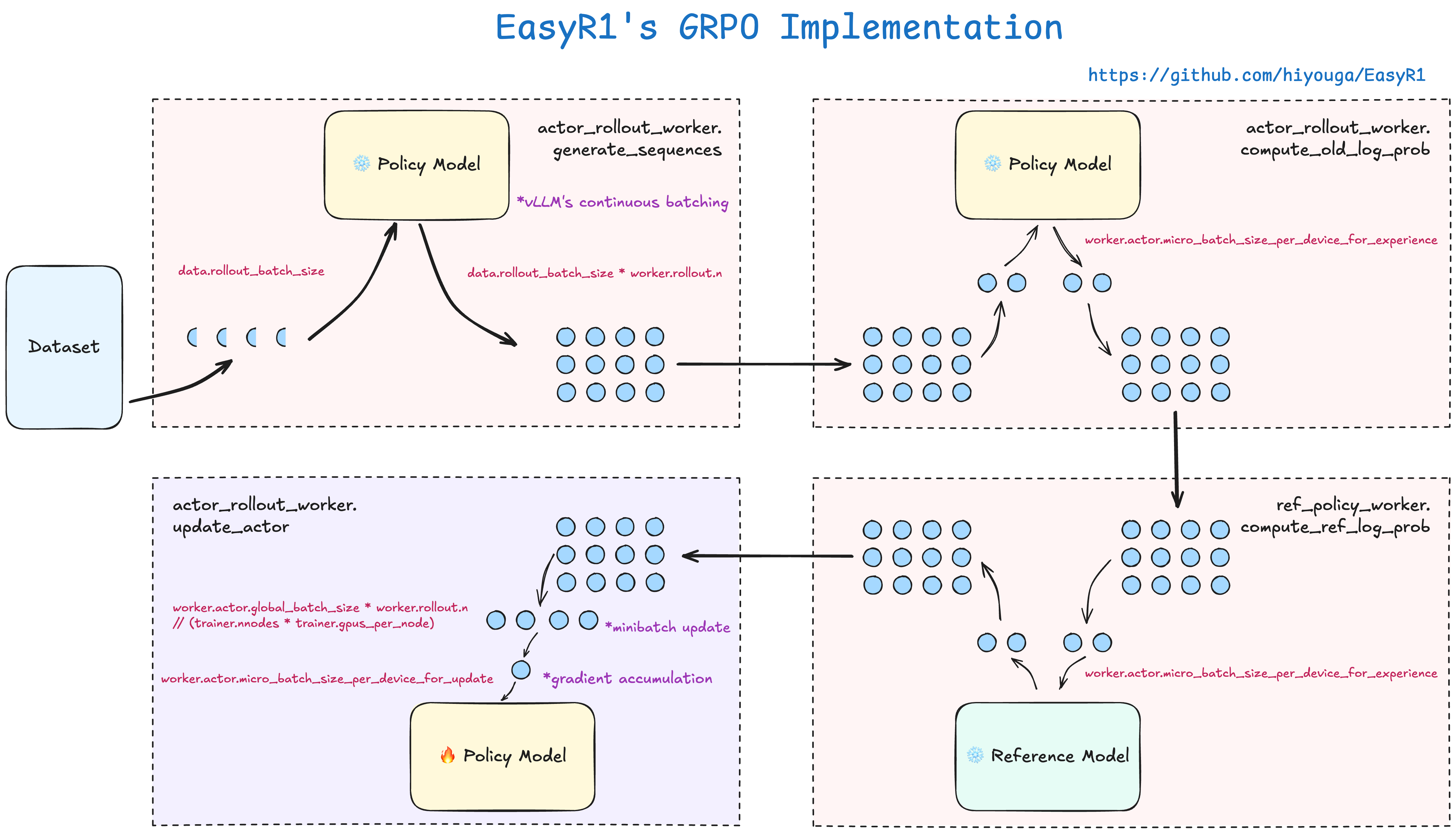
EasyR1是一个高效、可扩展的多模态强化学习(RL)训练框架,基于veRL项目改进以支持视觉语言模型。它借助HybirdEngine设计和vLLM的SPMD模式实现高效扩展,支持多种模型、算法、数据集及训练技巧。
- 支持多类型模型:涵盖Llama3、Qwen2等语言模型,Qwen2-VL等视觉语言模型及DeepSeek-R1蒸馏模型。
- 多种算法支持:支持GRPO、Reinforce++、ReMax、RLOO等多种RL算法。
- 适配多格式数据集:可处理特定格式的文本、图像-文本和多图像-文本数据集。
- 训练技巧丰富:提供Padding-free训练、从检查点恢复、并支持Wandb、SwanLab、Mlflow和Tensorboard等训练过程跟踪工具。
EasyR1的核心技术原理在于其对原有veRL项目的继承与优化,特别体现在以下两点:
- HybridEngine架构:该框架得益于veRL的HybridEngine设计,实现了高效的训练流程。HybridEngine是一种混合引擎,旨在提高强化学习训练的灵活性和效率。
- vLLM的SPMD模式:结合了vLLM 0.7最新版本的SPMD(Single Program, Multiple Data)模式,有效提升了大规模语言模型和多模态模型的训练性能和可扩展性,尤其对于内存管理和并行计算提供了优化。
-
多模态大模型的强化学习训练:特别适用于训练Qwen2.5-VL等多模态模型,以提升其在特定任务上的表现。
-
数学问题求解:可用于训练数学模型,例如在Geometry3k数据集上进行几何问题求解。
-
视觉问答与推理:可应用于图像-文本相关的视觉推理任务,如CLEVR-70k-Counting和GeoQA-8k数据集上的任务。
-
研究与开发:为研究人员和开发者提供一个强大的平台,探索新的RL算法和多模态模型的训练方法,并集成实验跟踪和可视化工具。
-
hiyouga/EasyR1: EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework based on veRL
OpenRLHF是首个基于Ray、vLLM、ZeRO - 3和HuggingFace Transformers构建的易于使用、高性能的开源RLHF框架,具有分布式架构、推理加速、内存高效训练等特点,支持多种算法和功能。
- 分布式训练:利用Ray进行高效分布式调度,支持多模型分离到不同GPU。
- 推理加速:结合vLLM和AutoTP实现高吞吐量、内存高效的样本生成。
- 多算法支持:实现分布式PPO、REINFORCE++等多种算法。
- 数据处理:提供多种数据处理方法,支持混合数据集。
- 模型训练:支持监督微调、奖励模型训练、PPO训练等。
- 异步训练:支持异步RLHF和基于代理的RLHF。
- 分布式架构:借助Ray进行任务调度,分离不同模型到不同GPU,支持混合引擎调度以提高GPU利用率。
- 推理加速:基于vLLM和AutoTP,减少样本生成时间,与HuggingFace Transformers集成实现快速生成。
- 内存优化:基于DeepSpeed的ZeRO - 3、deepcompile和AutoTP,直接与HuggingFace配合进行大模型训练。
- 算法优化:采用优化的PPO实现,结合实用技巧提升训练稳定性和奖励质量。
-
大语言模型微调:对大型语言模型进行监督微调、奖励模型训练和强化学习微调。
-
多智能体系统训练:如MARTI利用其训练基于LLM的多智能体系统。
-
多模态任务:为多模态任务提供高性能RL基础设施,如LMM - R1。
WorldPM(世界偏好建模)证明了偏好建模遵循与语言建模类似的扩展规律,通过对1500万条来自StackExchange的偏好数据进行大规模训练,让偏好模型学习统一的偏好表示。在对抗性和客观评估中表现出明显扩展趋势,对抗性评估测试损失幂律下降,客观指标有涌现现象;主观评估无明显扩展趋势,可能受风格偏好影响。
- 偏好学习:从大规模偏好数据中学习统一的人类偏好表示。
- 对抗评估:提升识别包含意图错误、不相关或不完整回复的能力。
- 客观指标评估:助力大模型获取客观知识偏好,展现出测试损失的幂律下降。
- 基础与微调:提供基础模型WorldPM - 72B,并支持在不同规模数据集上微调。
- 数据收集:从StackExchange、Reddit、Quora等公共论坛收集偏好数据,经评估选StackExchange数据为代表。
- 训练方法:遵循人类偏好建模框架,用偏好模型预测奖励并优化BT - loss,不同规模模型保持一致超参数。
- 评估方法:用BT - loss计算测试性能,使用多个RM基准的不同领域测试集评估。
-
模型微调:作为基础助力不同规模人类偏好数据集的偏好模型微调。
-
语言模型对齐:通过Best - of - N采样使语言模型输出符合人类偏好,在Arena Hard和Alpaca Eval等基准评估。
verl是由字节跳动Seed团队发起、verl社区维护的强化学习训练库,是HybridFlow论文的开源版本。它灵活高效、适用于生产,用于大语言模型(LLM)的后训练,能与多种现有LLM框架集成,支持多种强化学习算法。

- 算法扩展:可轻松扩展多种强化学习算法,如PPO、GRPO等。
- 框架集成:通过模块化API与现有LLM框架无缝集成,支持FSDP、Megatron - LM等训练框架,vLLM、SGLang等推理框架。
- 设备映射:支持将模型灵活放置在不同GPU集上,实现高效资源利用和集群扩展。
- 多类型支持:支持基于模型和函数的奖励、视觉语言模型(VLM)和多模态强化学习、多轮对话及工具调用等。
- 性能优化:具有先进的吞吐量,通过3D - HybridEngine实现高效的actor模型重分片。
- 混合编程模型:结合单控制器和多控制器范式的优势,灵活表示和高效执行复杂的后训练数据流。
- 3D - HybridEngine:在训练和生成阶段的转换中消除内存冗余,显著减少通信开销。
- 模块化设计:解耦计算和数据依赖,便于与现有LLM框架集成。
-
大语言模型训练:如对DeepSeek - 671b、Qwen3 - 236b等大模型进行强化学习训练。
-
代码生成与数学推理:在编码、数学等领域进行模型训练,提升模型在这些任务上的表现。
-
视觉语言模型:支持Qwen2.5 - vl、Kimi - VL等视觉语言模型的多模态强化学习。
-
多轮对话与工具调用:实现大语言模型的多轮对话及工具调用功能。
-
volcengine/verl: verl: Volcano Engine Reinforcement Learning for LLMs
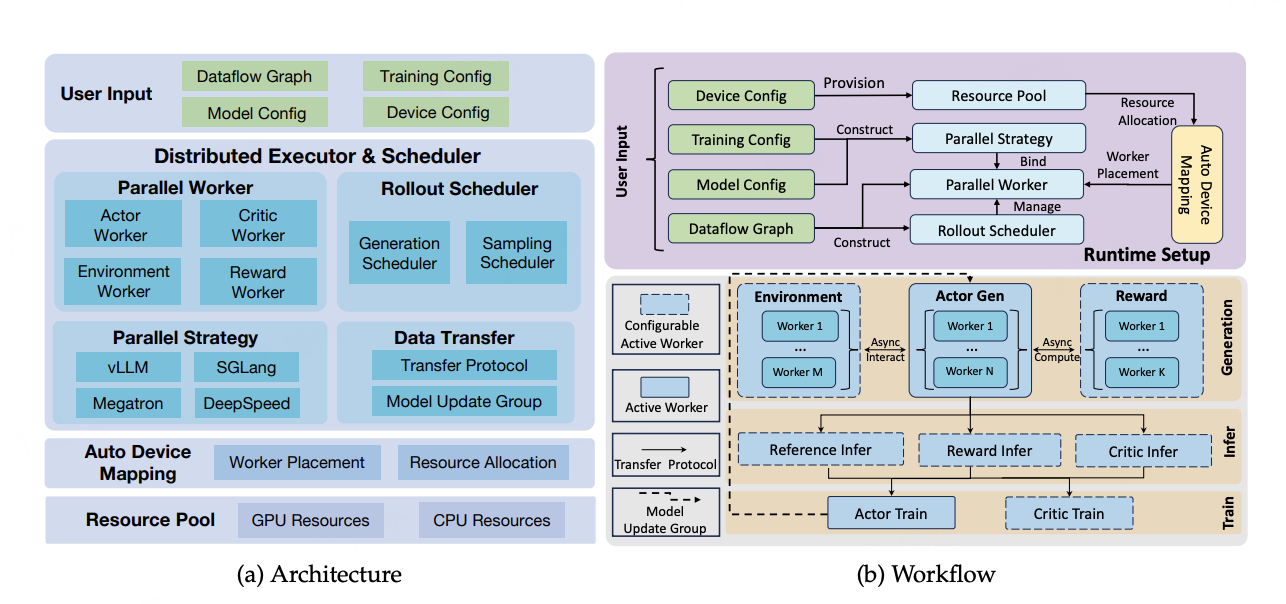
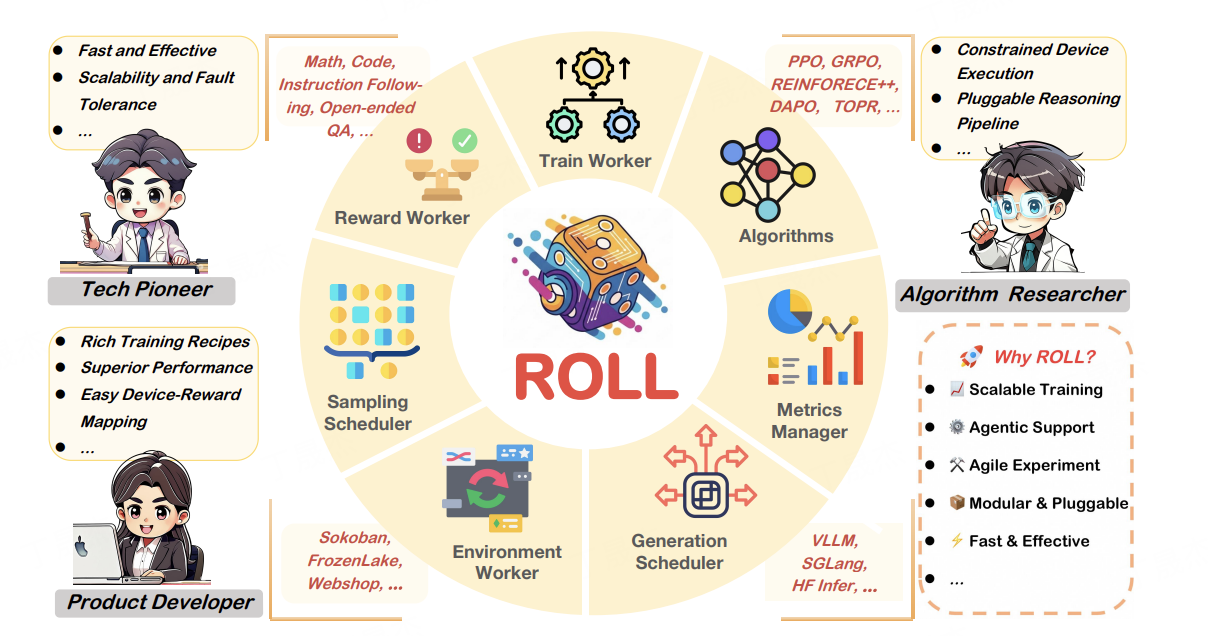
ROLL 是阿里巴巴开源的一个高效且用户友好的强化学习 (RL) 库,专为利用大规模 GPU 资源的大型语言模型 (LLMs) 的强化学习优化而设计。它旨在解决将 RL 应用于 LLM 时面临的挑战,提供一套可扩展、模块化的训练框架,尤其适用于复杂的多轮智能体交互场景。
- 大规模分布式训练: 支持利用大规模 GPU 资源进行 LLM 的强化学习训练,实现高效的并行化。
- 多角色分布式架构: 基于 Ray 构建灵活的多角色分布式架构,实现资源弹性分配和异构任务调度。
- 集成前沿加速技术: 整合 Megatron-Core, SGLang 和 vLLM 等业界领先工具,显著加速 LLM 的训练和推理过程。
- 支持多种 RL 范式: 能够支持 RLVR (Reinforcement Learning with Visual and Rewards) 和 Agentic RL (Agent-based Reinforcement Learning) 等高级强化学习范式的训练。
- 模块化设计: 提供 Actor Worker、Critic Worker、Reward Worker 和 Environment Worker 等抽象角色,简化 RL 训练管道的构建和自定义。
- 高级采样与调度: 实现了“动态采样”等先进策略,并通过组合式样本-奖励路由 (Compositional Sample-Reward Route) 和高效的工作器调度器 (Worker Scheduler) 优化数据流和性能。
ROLL 的技术基石在于其分布式架构和强化学习算法优化。
- 分布式架构: 采用基于 Ray 的多角色分布式框架。
- 资源管理与任务调度: Ray 提供了强大的分布式计算原语,使得 ROLL 能够在大规模 GPU 集群上高效地分配资源并调度不同类型的 RL 任务(如策略更新、环境交互、奖励计算),实现训练的并行化和加速。
- LLM 加速集成: 通过深度集成 Megatron-Core 实现 LLM 的模型并行和数据并行训练,结合 SGLang 和 vLLM 优化 LLM 的推理性能,特别是在处理长序列和并发请求时,显著提高吞吐量和降低延迟。
- 强化学习优化策略:
- 职责分离工作器: 将复杂的 RL 训练流程拆分为独立的 Actor Worker (生成动作), Critic Worker (评估状态-动作价值), Reward Worker (计算奖励), Environment Worker (环境交互),各司其职,提高了系统的可维护性和可扩展性。
- 动态采样与反馈机制: 引入“动态采样”等先进的采样策略,以应对 LLM 复杂环境中的探索-利用权衡挑战。组合式样本-奖励路由机制旨在更有效地处理稀疏奖励和长序列决策问题,确保奖励信号能及时准确地回传。
- 高效调度器: 优化工作器之间的协调与数据同步,特别是在处理 LLM 与环境间的复杂、异步交互时,确保训练效率和稳定性。
-
大型语言模型强化学习微调 (RLHF): 对 LLM 进行基于人类反馈或环境反馈的强化学习微调,以提升模型在特定指令遵循、价值观对齐或对话质量等方面的能力。
-
具身智能体与游戏 AI: 训练能够与复杂虚拟环境或物理世界进行交互的具身智能体,例如在机器人控制、虚拟游戏角色行为学习等领域。
-
多轮对话系统与智能体决策: 应用于需要 LLM 在多轮交互中进行复杂推理和决策的场景,如智能客服、自动编程助手、策略规划型 AI 等。
-
内容创作与个性化推荐: 通过强化学习优化 LLM 生成内容的相关性、吸引力或用户满意度,例如在新闻摘要、广告文案生成、推荐系统等方面。
-
大规模 AI 研究与开发平台: 作为企业或研究机构构建下一代大规模 LLM 强化学习研究和开发平台的基础设施,加速前沿算法的实验和部署。
-
论文标题:Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Skywork-Reward-V2 是昆仑万维(SkyworkAI)开源的第二代奖励模型系列,旨在为大型语言模型(LLMs)提供卓越的人类偏好评估能力。该系列包含八个不同参数规模(从6亿到80亿)的模型,通过大规模、高质量的偏好数据训练,在多项主流奖励模型评测榜单上取得了领先的性能,刷新了State-of-the-Art (SOTA) 记录,成为目前最强的人类偏好感应器之一。
- 人类偏好感知与量化: 精准识别、理解并量化人类对LLM生成内容的偏好程度,为模型输出质量提供客观依据。
- 强化学习奖励信号生成: 作为强化学习从人类反馈中学习(RLHF)的关键组件,提供高质量、稳定的奖励信号,以有效指导LLMs的行为对齐人类价值观和指令。
- 多任务通用性评估: 能够评估LLMs在广泛任务(如对话、摘要、写作等)中的表现,支持多领域和多场景的应用需求。
Skywork-Reward-V2系列模型核心基于Bradley-Terry模型进行训练,该模型擅长处理配对比较数据,以推断个体偏好。其技术亮点在于:
- 大规模高质量偏好数据: 模型在高达2600万对经过精心策划的高质量人类偏好数据上进行训练,显著提升了模型的泛化能力和准确性。
- 数据驱动的性能优化: 通过强调数据规模和质量的重要性,采用了先进的数据选择和过滤策略,确保训练数据的有效性和代表性。
- 模型架构多样性: 提供不同参数量级的模型,以满足不同应用场景下对计算资源和性能的需求平衡。
- 强化学习与偏好学习结合: 通过将人类反馈转化为奖励信号,驱动LLM在迭代优化中逐步学习并适应人类的复杂偏好模式,实现与人类意图的高度对齐。
- 大型语言模型(LLMs)对齐: 在RLHF流程中作为奖励函数,用于微调LLMs,使其生成内容更符合人类偏好、更安全、更无害。
- 内容生成质量评估: 自动评估由LLMs生成的文本内容(如对话回复、文章摘要、创意文案等)的质量、连贯性和相关性。
- 对话系统优化: 提高聊天机器人和虚拟助手的对话质量和用户满意度,使其能够生成更自然、更具吸引力的回复。
- 个性化推荐系统: 根据用户偏好对生成的内容或信息进行排序和过滤,提升推荐的准确性和用户体验。
- 模型效果迭代与对比: 作为衡量不同LLM版本或训练策略效果的基准,指导模型持续改进。
RM-Gallery 是一个一站式的奖励模型平台,旨在提供奖励模型(Reward Model)的训练、构建和应用的全方位解决方案。它致力于简化奖励模型的开发和部署流程,为用户提供便捷高效的工具和服务。
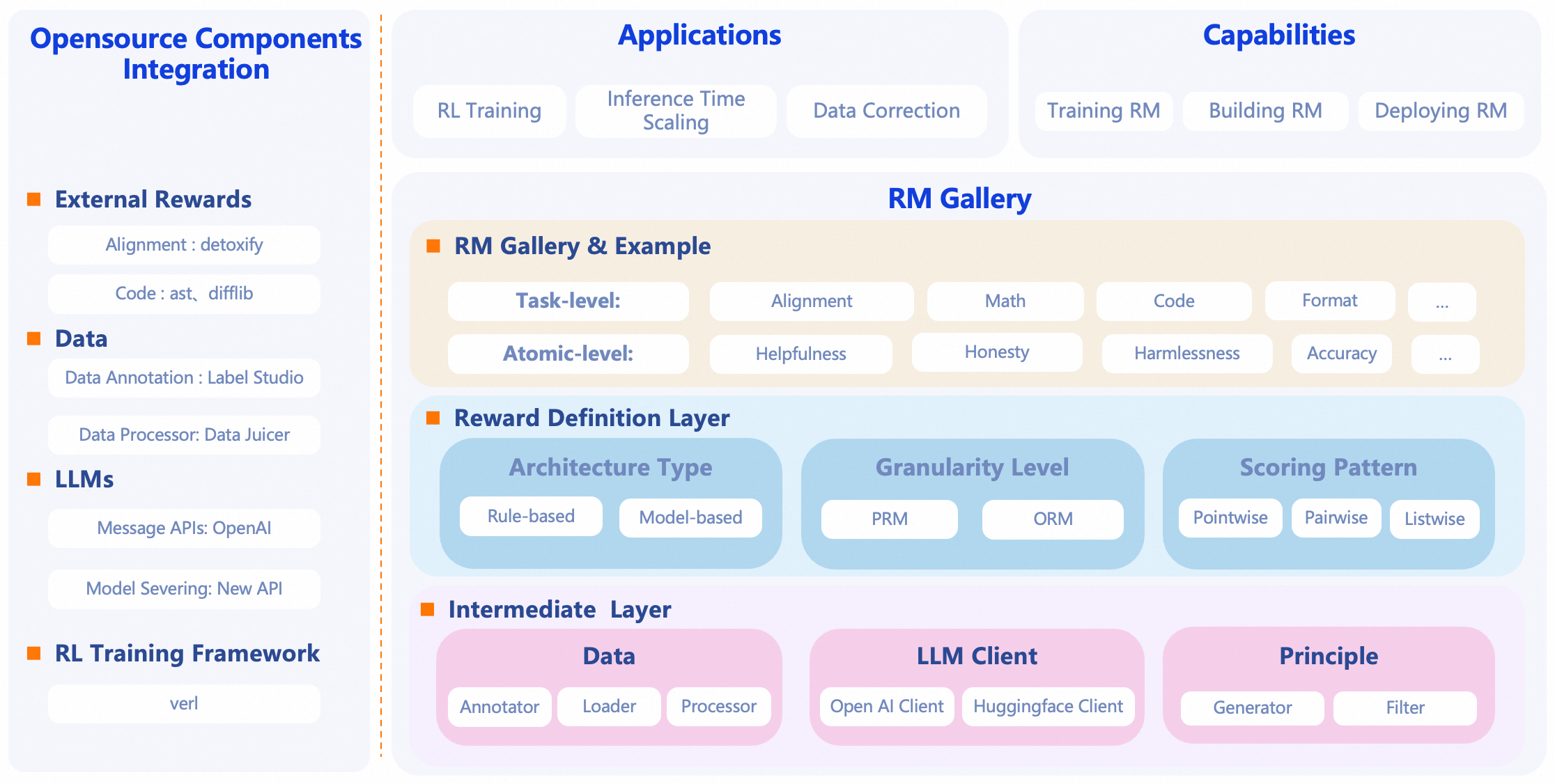
- 丰富的奖励模型库: 提供大量预训练和可直接使用的奖励模型实例,涵盖不同任务和领域。
- 模型组合与应用: 支持用户直接应用任务级(RMComposition)或组件级(RewardModel)的奖励模型,也可通过组件级模型组装定制化的任务级奖励模型。
- 全生命周期管理: 提供从数据标注、数据加载、数据处理到奖励模型训练的完整流程支持。
RM-Gallery 基于奖励模型的核心机制,通过构建和管理奖励函数,来评估模型输出的质量或偏好。其技术原理可能涉及:
- 偏好学习 (Preference Learning): 通过收集人类或其他评估者的偏好数据,训练奖励模型来预测文本或行为的“好坏”程度。
- 模型即服务 (Model-as-a-Service): 作为ModelScope生态的一部分,提供标准化的接口和流程,方便用户调用和部署奖励模型。
- 模块化与可组合性: 设计上区分任务级和组件级奖励模型,允许灵活组合不同的模型模块以适应多样化的应用需求。
- 数据管道自动化: 整合了数据标注、加载和处理工具,确保奖励模型训练数据的高效准备。
-
大模型对齐与微调: 用于强化学习与人类反馈(RLHF)等场景,使大型语言模型(LLM)的行为更符合人类偏好或特定目标。
-
内容生成与评估: 在文本生成、代码生成、图像生成等领域,对生成内容的质量进行自动评估和排序。
-
智能体行为优化: 引导智能体在复杂环境中学习更优的行为策略,例如在数学问题解决、编程辅助等任务中。
-
用户偏好学习: 捕捉和学习用户对不同输出的隐式或显式偏好,用于推荐系统或个性化服务。
⬆ 返回README目录 ⬆ Back to Contents
🔥 精选AI前沿资讯 | 📚 深度技术解读 | 💡 实战案例分享
🎯 更深入的内容 - 独家教程、项目实战、面试指导
⚡ 更高的更新频率 - 高频资讯推送、专家答疑、技术交流
🎁 限时优惠 - 与数千名AI学习者一起成长!
星球支持三天内免费退款,请放心订阅。
{kind=link}