diff --git a/README.md b/README.md
index 615923e9..468816c7 100644
--- a/README.md
+++ b/README.md
@@ -9,7 +9,7 @@
Scale Efficiently: Evaluate and Optimize Your LLM Deployments for Real-World Inference
-[](https://github.com/neuralmagic/guidellm/releases) [](https://github.com/neuralmagic/guidellm/tree/main/docs) [](https://github.com/neuralmagic/guidellm/blob/main/LICENSE) [](https://pypi.python.org/pypi/guidellm) [](https://pypi.python.org/pypi/guidellm-nightly) [](https://pypi.python.org/pypi/guidellm) [](https://github.com/neuralmagic/guidellm/actions/workflows/nightly.yml)
+[](https://github.com/neuralmagic/guidellm/releases) [](https://github.com/neuralmagic/guidellm/tree/main/docs) [](https://github.com/neuralmagic/guidellm/blob/main/LICENSE) [](https://pypi.python.org/pypi/guidellm) [](https://pypi.python.org/pypi/guidellm) [](https://github.com/neuralmagic/guidellm/actions/workflows/nightly.yml)
## Overview
@@ -20,7 +20,7 @@ Scale Efficiently: Evaluate and Optimize Your LLM Deployments for Real-World Inf
-**GuideLLM** is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality.
+**GuideLLM** is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality.
### Key Features
@@ -38,7 +38,13 @@ Before installing, ensure you have the following prerequisites:
- OS: Linux or MacOS
- Python: 3.9 – 3.13
-GuideLLM can be installed using pip:
+The latest GuideLLM release can be installed using pip:
+
+```bash
+pip install guidellm
+```
+
+Or from source code using pip:
```bash
pip install git+https://github.com/neuralmagic/guidellm.git
@@ -48,9 +54,9 @@ For detailed installation instructions and requirements, see the [Installation G
### Quick Start
-#### 1a. Start an OpenAI Compatible Server (vLLM)
+#### 1. Start an OpenAI Compatible Server (vLLM)
-GuideLLM requires an OpenAI-compatible server to run evaluations. [vLLM](https://github.com/vllm-project/vllm) is recommended for this purpose. To start a vLLM server with a Llama 3.1 8B quantized model, run the following command:
+GuideLLM requires an OpenAI-compatible server to run evaluations. [vLLM](https://github.com/vllm-project/vllm) is recommended for this purpose. After installing vLLM on your desired server (`pip install vllm`), start a vLLM server with a Llama 3.1 8B quantized modelby running the following command:
```bash
vllm serve "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16"
@@ -58,93 +64,94 @@ vllm serve "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16"
For more information on starting a vLLM server, see the [vLLM Documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
-#### 1b. Start an OpenAI Compatible Server (Hugging Face TGI)
+For information on starting other supported inference servers or platforms, see the [Supported Backends documentation](https://github.com/neuralmagic/guidellm/tree/main/docs/backends.md).
-GuideLLM requires an OpenAI-compatible server to run evaluations. [Text Generation Inference](https://github.com/huggingface/text-generation-inference) can be used here. To start a TGI server with a Llama 3.1 8B using docker, run the following command:
-
-```bash
-docker run --gpus 1 -ti --shm-size 1g --ipc=host --rm -p 8080:80 \
- -e MODEL_ID=meta-llama/Meta-Llama-3.1-8B-Instruct \
- -e NUM_SHARD=1 \
- -e MAX_INPUT_TOKENS=4096 \
- -e MAX_TOTAL_TOKENS=6000 \
- -e HF_TOKEN=$(cat ~/.cache/huggingface/token) \
- ghcr.io/huggingface/text-generation-inference:2.2.0
-```
+#### 2. Run a GuideLLM Benchmark
-For more information on starting a TGI server, see the [TGI Documentation](https://huggingface.co/docs/text-generation-inference/index).
+To run a GuideLLM benchmark, use the `guidellm benchmark` command with the target set to an OpenAI compatible server. For this example, the target is set to 'http://localhost:8000', assuming that vLLM is active and running on the same server. Be sure to update it appropriately. By default, GuideLLM will automatically determine the model avaialble on the server and use that. To target a different model, pass the desired name with the `--model` argument. Additionally, the `--rate-type` is set to `sweep` which will run a range of benchmarks automatically determining the minimum and maximum rates the server and model can support. Each benchmark run under the sweep will run for 30 seconds, as set by the `--max-seconds` argument. Finally, `--data` is set to a synthetic dataset with 256 prompt tokens and 128 output tokens per request. For more arguments, supported scenarios, and configurations, jump to the [Configurations Section](#configurations) or run `guidellm benchmark --help`.
-#### 2. Run a GuideLLM Evaluation
-
-To run a GuideLLM evaluation, use the `guidellm` command with the appropriate model name and options on the server hosting the model or one with network access to the deployment server. For example, to evaluate the full performance range of the previously deployed Llama 3.1 8B model, run the following command:
+Now, to start benchmarking, run the following command:
```bash
guidellm benchmark \
--target "http://localhost:8000" \
- --model "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16" \
--rate-type sweep \
+ --max-seconds 30 \
--data "prompt_tokens=256,output_tokens=128"
```
-The above command will begin the evaluation and output progress updates similar to the following (if running on a different server, be sure to update the target!):  +The above command will begin the evaluation and provide progress updates similar to the following:
-Notes:
+#### 3. Analyze the Results
-- The `--target` flag specifies the server hosting the model. In this case, it is a local vLLM server.
-- The `--model` flag specifies the model to evaluate. The model name should match the name of the model deployed on the server
-- The `--rate-type` flag specifies what load generation pattern GuideLLM will use when sending requests to the server. If `sweep` is specified GuideLLM will run multiple performance evaluations across different request rates.
-- By default GuideLLM will run over a fixed workload of 1000 requests configurable by `--max-requests`. If `--max-seconds` is set GuideLLM will instead run over a fixed time.
+After the evaluation is completed, GuideLLM will summarize the results into three sections:
-#### 3. Analyze the Results
+1. Benchmarks Metadata: A summary of the benchmark run and the arguments used to create it, including the server, data, profile, and more.
+2. Benchmarks Info: A high level view of each benchmark and the requests that were run, including the type, duration, request statuses, and number of tokens.
+3. Benchmarks Stats: A summary of the statistics for each benchmark run, including the requests rate, concurrency, latency, and token level metrics such as TTFT, ITL, and more.
-After the evaluation is completed, GuideLLM will summarize the results, including various performance metrics.
+The sections will look similar to the following:
+The above command will begin the evaluation and provide progress updates similar to the following:
-Notes:
+#### 3. Analyze the Results
-- The `--target` flag specifies the server hosting the model. In this case, it is a local vLLM server.
-- The `--model` flag specifies the model to evaluate. The model name should match the name of the model deployed on the server
-- The `--rate-type` flag specifies what load generation pattern GuideLLM will use when sending requests to the server. If `sweep` is specified GuideLLM will run multiple performance evaluations across different request rates.
-- By default GuideLLM will run over a fixed workload of 1000 requests configurable by `--max-requests`. If `--max-seconds` is set GuideLLM will instead run over a fixed time.
+After the evaluation is completed, GuideLLM will summarize the results into three sections:
-#### 3. Analyze the Results
+1. Benchmarks Metadata: A summary of the benchmark run and the arguments used to create it, including the server, data, profile, and more.
+2. Benchmarks Info: A high level view of each benchmark and the requests that were run, including the type, duration, request statuses, and number of tokens.
+3. Benchmarks Stats: A summary of the statistics for each benchmark run, including the requests rate, concurrency, latency, and token level metrics such as TTFT, ITL, and more.
-After the evaluation is completed, GuideLLM will summarize the results, including various performance metrics.
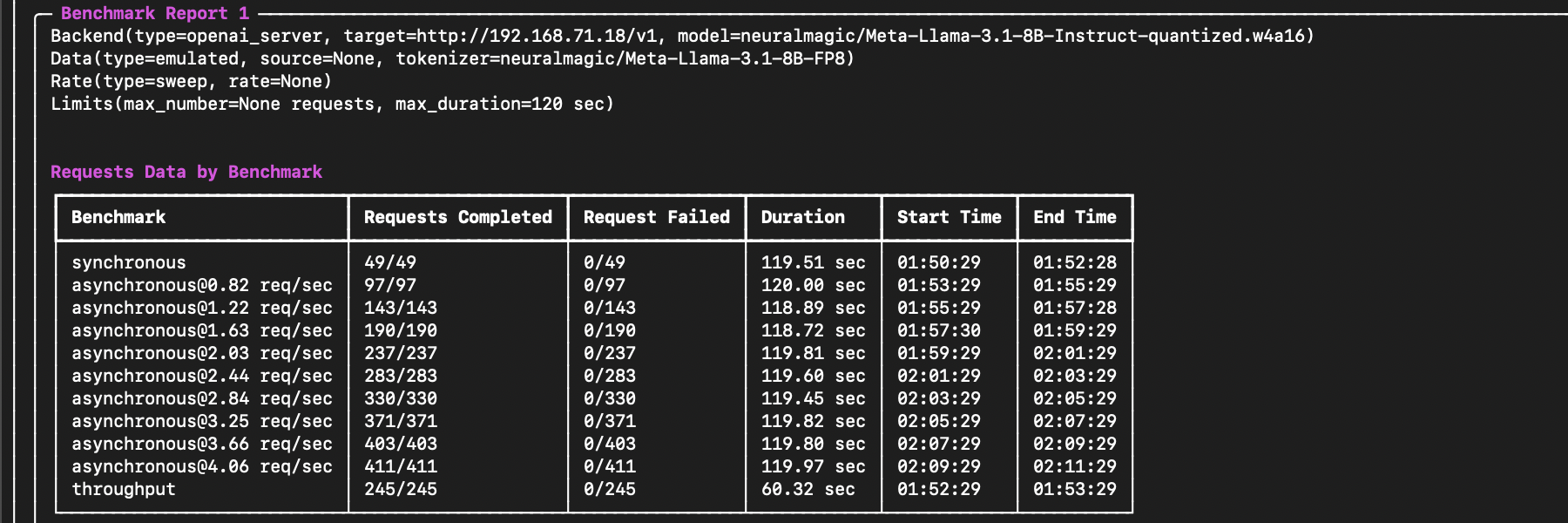
+The sections will look similar to the following: 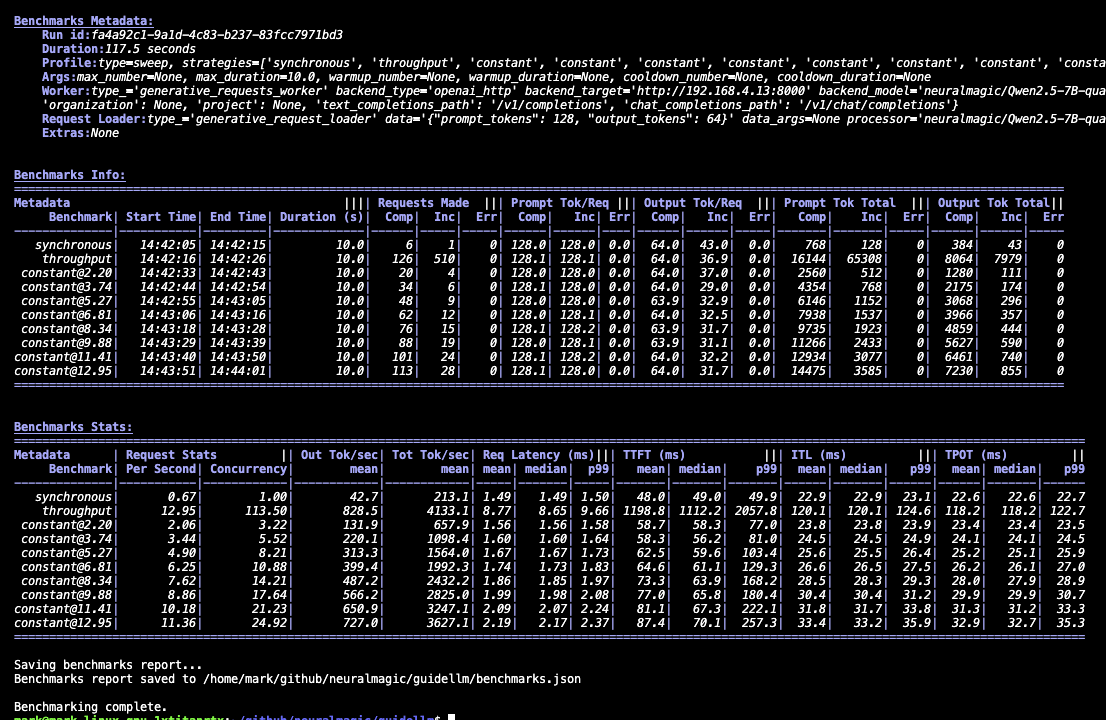 -The output results will start with a summary of the evaluation, followed by the requests data for each benchmark run. For example, the start of the output will look like the following:
+For further details about the metrics and definitions, view the [Metrics documentation](https://raw.githubusercontent.com/neuralmagic/guidellm/main/docs/metrics.md).
-
-The output results will start with a summary of the evaluation, followed by the requests data for each benchmark run. For example, the start of the output will look like the following:
+For further details about the metrics and definitions, view the [Metrics documentation](https://raw.githubusercontent.com/neuralmagic/guidellm/main/docs/metrics.md).
- +#### 4. Explore the Results File
-The end of the output will include important performance summary metrics such as request latency, time to first token (TTFT), inter-token latency (ITL), and more:
+By default, the full results, including full statistics and request data, are saved to a file `benchmarks.json` in the current working directory. This file can be used for further analysis or reporting and additionally can be reloaded into Python for further analysis using the `guidellm.benchmark.GenerativeBenchmarksReport` class. You can specify a different file name and extension with the `--output` argument.
-
+#### 4. Explore the Results File
-The end of the output will include important performance summary metrics such as request latency, time to first token (TTFT), inter-token latency (ITL), and more:
+By default, the full results, including full statistics and request data, are saved to a file `benchmarks.json` in the current working directory. This file can be used for further analysis or reporting and additionally can be reloaded into Python for further analysis using the `guidellm.benchmark.GenerativeBenchmarksReport` class. You can specify a different file name and extension with the `--output` argument.
- +For further details about the supported output file types, view the [Outputs documentation](raw.githubusercontent.com/neuralmagic/guidellm/main/docs/outputs.md).
#### 4. Use the Results
The results from GuideLLM are used to optimize your LLM deployment for performance, resource efficiency, and cost. By analyzing the performance metrics, you can identify bottlenecks, determine the optimal request rate, and select the most cost-effective hardware configuration for your deployment.
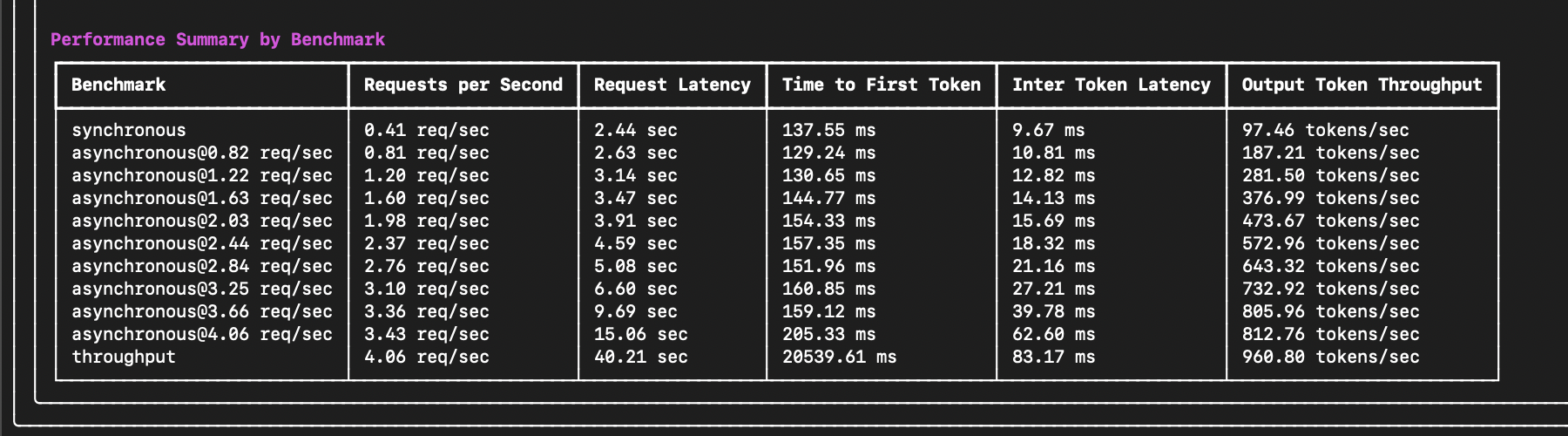
-For example, if we deploy a latency-sensitive chat application, we likely want to optimize for low time to first token (TTFT) and inter-token latency (ITL). A reasonable threshold will depend on the application requirements. Still, we may want to ensure time to first token (TTFT) is under 200ms and inter-token latency (ITL) is under 50ms (20 updates per second). From the example results above, we can see that the model can meet these requirements on average at a request rate of 2.37 requests per second for each server. If you'd like to target a higher percentage of requests meeting these requirements, you can use the **Performance Stats by Benchmark** section to determine the rate at which 90% or 95% of requests meet these requirements.
+For example, if we are deploying a chat application, we likely want to guarantee our time to first token (TTFT) and inter-token latency (ITL) are under certain thresholds to meet our service level objectives (SLOs) or agreements (SLAs). For example, setting TTFT to 200ms and ITL 25ms for the sample data provided in the example above, we can see that even though the server is capable of handling up to 13 requests per second, we would only be able to meet our SLOs for 99% of users at a request rate of 3.5 requests per second. If we relax our constraints on ITL to 50ms, then we can meet the TTFT SLA for 99% of users at a request rate of roughly 10 requests per second.
-If we deploy a throughput-sensitive summarization application, we likely want to optimize for the maximum requests the server can handle per second. In this case, the throughput benchmark shows that the server maxes out at 4.06 requests per second. If we need to handle more requests, consider adding more servers or upgrading the hardware configuration.
+For further details about deterimining the optimal request rate and SLOs, view the [SLOs documentation](https://raw.githubusercontent.com/neuralmagic/guidellm/main/docs/service_level_objectives.md).
### Configurations
-GuideLLM provides various CLI and environment options to customize evaluations, including setting the duration of each benchmark run, the number of concurrent requests, and the request rate.
+GuideLLM provides a variety of configurations through both the benchmark CLI command alongside environment variables which handle default values and more granular controls. Below, the most common configurations are listed. A complete list is easily accessible, though, by running `guidellm benchmark --help` or `guidellm config` respectively.
-Some typical configurations for the CLI include:
+#### Benchmark CLI
-- `--rate-type`: The rate to use for benchmarking. Options include `sweep`, `synchronous`, `throughput`, `constant`, and `poisson`.
- - `--rate-type sweep`: (default) Sweep runs through the full range of the server's performance, starting with a `synchronous` rate, then `throughput`, and finally, 10 `constant` rates between the min and max request rate found.
- - `--rate-type synchronous`: Synchronous runs requests synchronously, one after the other.
- - `--rate-type throughput`: Throughput runs requests in a throughput manner, sending requests as fast as possible.
- - `--rate-type constant`: Constant runs requests at a constant rate. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- - `--rate-type poisson`: Poisson draws from a Poisson distribution with the mean at the specified rate, adding some real-world variance to the runs. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- - `--rate-type concurrent`: Concurrent runs requests at a fixed concurrency. When a requests completes it is immediately replaced with a new request to maintain the set concurrency. Specify the request concurrency with `--rate`.
-- `--data`: A hugging face dataset name or arguments to generate a synthetic dataset.
-- `--max-seconds`: The maximum number of seconds to run each benchmark.
-- `--max-requests`: The maximum number of requests to run in each benchmark.
+The `guidellm benchmark` command is used to run benchmarks against a generative AI backend/server. The command accepts a variety of arguments to customize the benchmark run. The most common arguments include:
-For a complete list of supported CLI arguments, run the following command:
+- `--target`: Specifies the target path for the backend to run benchmarks against. For example, `http://localhost:8000`. This is required to define the server endpoint.
-```bash
-guidellm --help
-```
+- `--model`: Allows selecting a specific model from the server. If not provided, it defaults to the first model available on the server. Useful when multiple models are hosted on the same server.
-For a full list of configuration options, run the following command:
+- `--processor`: Used only for synthetic data creation or when the token source configuration is set to local for calculating token metrics locally. It must match the model's processor/tokenizer to ensure compatibility and correctness. This supports either a HuggingFace model ID or a local path to a processor/tokenizer.
-```bash
-guidellm-config
-```
+- `--data`: Specifies the dataset to use. This can be a HuggingFace dataset ID, a local path to a dataset, or standard text files such as CSV, JSONL, and more. Additionally, synthetic data configurations can be provided using JSON or key-value strings. Synthetic data options include:
+
+ - `prompt_tokens`: Average number of tokens for prompts.
+ - `output_tokens`: Average number of tokens for outputs.
+ - `TYPE_stdev`, `TYPE_min`, `TYPE_max`: Standard deviation, minimum, and maximum values for the specified type (e.g., `prompt_tokens`, `output_tokens`). If not provided, will use the provided tokens value only.
+ - `samples`: Number of samples to generate, defaults to 1000.
+ - `source`: Source text data for generation, defaults to a local copy of Pride and Prejudice.
+
+- `--data-args`: A JSON string used to specify the columns to source data from (e.g., `prompt_column`, `output_tokens_count_column`) and additional arguments to pass into the HuggingFace datasets constructor.
+
+- `--data-sampler`: Enables applying `random` shuffling or sampling to the dataset. If not set, no sampling is applied.
+
+- `--rate-type`: Defines the type of benchmark to run (default sweep). Supported types include:
+
+ - `synchronous`: Runs a single stream of requests one at a time. `--rate` must not be set for this mode.
+ - `throughput`: Runs all requests in parallel to measure the maximum throughput for the server (bounded by GUIDELLM\_\_MAX_CONCURRENCY config argument). `--rate` must not be set for this mode.
+ - `concurrent`: Runs a fixed number of streams of requests in parallel. `--rate` must be set to the desired concurrency level/number of streams.
+ - `constant`: Sends requests asynchronously at a constant rate set by `--rate`.
+ - `poisson`: Sends requests at a rate following a Poisson distribution with the mean set by `--rate`.
+ - `sweep`: Automatically determines the minimum and maximum rates the server can support by running synchronous and throughput benchmarks and then runs a series of benchmarks equally spaced between the two rates. The number of benchmarks is set by `--rate` (default is 10).
+
+- `--max-seconds`: Sets the maximum duration (in seconds) for each benchmark run. If not provided, the benchmark will run until the dataset is exhausted or `--max-requests` is reached.
-See the [GuideLLM Documentation](#Documentation) for further information.
+- `--max-requests`: Sets the maximum number of requests for each benchmark run. If not provided, the benchmark will run until `--max-seconds` is reached or the dataset is exhausted.
+
+- `--warmup-percent`: Specifies the percentage of the benchmark to treat as a warmup phase. Requests during this phase are excluded from the final results.
+
+- `--cooldown-percent`: Specifies the percentage of the benchmark to treat as a cooldown phase. Requests during this phase are excluded from the final results.
+
+- `--output-path`: Defines the path to save the benchmark results. Supports JSON, YAML, or CSV formats. If a directory is provided, the results will be saved as `benchmarks.json` in that directory. If not set, the results will be saved in the current working directory.
## Resources
@@ -155,9 +162,10 @@ Our comprehensive documentation provides detailed guides and resources to help y
### Core Docs
- [**Installation Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/install.md) - This guide provides step-by-step instructions for installing GuideLLM, including prerequisites and setup tips.
+- [**Backends Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/backends.md) - A comprehensive overview of supported backends and how to set them up for use with GuideLLM.
+- [**Metrics Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/metrics.md) - Detailed explanations of the metrics used in GuideLLM, including definitions and how to interpret them.
+- [**Outputs Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/outputs.md) - Information on the different output formats supported by GuideLLM and how to use them.
- [**Architecture Overview**](https://github.com/neuralmagic/guidellm/tree/main/docs/architecture.md) - A detailed look at GuideLLM's design, components, and how they interact.
-- [**CLI Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/cli.md) - Comprehensive usage information for running GuideLLM via the command line, including available commands and options.
-- [**Configuration Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/configuration.md) - Instructions on configuring GuideLLM to suit various deployment needs and performance goals.
### Supporting External Documentation
@@ -185,10 +193,8 @@ We appreciate contributions to the code, examples, integrations, documentation,
We invite you to join our growing community of developers, researchers, and enthusiasts passionate about LLMs and optimization. Whether you're looking for help, want to share your own experiences, or stay up to date with the latest developments, there are plenty of ways to get involved:
-- [**Neural Magic Community Slack**](https://neuralmagic.com/community/) - Join our Slack channel to connect with other GuideLLM users and developers. Ask questions, share your work, and get real-time support.
+- [**vLLM Slack**](https://inviter.co/vllm-slack) - Join the vLLM Slack community to connect with other users, ask questions, and share your experiences.
- [**GitHub Issues**](https://github.com/neuralmagic/guidellm/issues) - Report bugs, request features, or browse existing issues. Your feedback helps us improve GuideLLM.
-- [**Subscribe to Updates**](https://neuralmagic.com/subscribe/) - Sign up for the latest news, announcements, and updates about GuideLLM, webinars, events, and more.
-- [**Contact Us**](http://neuralmagic.com/contact/) - Use our contact form for general questions about Neural Magic or GuideLLM.
### Cite
@@ -202,3 +208,6 @@ If you find GuideLLM helpful in your research or projects, please consider citin
howpublished={\url{https://github.com/neuralmagic/guidellm}},
}
```
+
+```
+```
diff --git a/docs/architecture.md b/docs/architecture.md
index d30962bd..047648ec 100644
--- a/docs/architecture.md
+++ b/docs/architecture.md
@@ -1 +1,97 @@
-# Coming Soon
+# GuideLLM Architecture
+
+GuideLLM is designed to evaluate and optimize large language model (LLM) deployments by simulating real-world inference workloads. The architecture is modular, enabling flexibility and scalability. Below is an overview of the core components and their interactions.
+
+```
++------------------+ +------------------+ +------------------+
+| DatasetCreator | ---> | RequestLoader | ---> | Scheduler |
++------------------+ +------------------+ +------------------+
+ / | \
+ / | \
+ / | \
+ v v v
+ +------------------+ +------------------+
+ | RequestsWorker | | RequestsWorker |
+ +------------------+ +------------------+
+ | |
+ v v
+ +------------------+ +------------------+
+ | Backend | | Backend |
+ +------------------+ +------------------+
+ | |
+ v v
+ +---------------------------------------+
+ | BenchmarkAggregator |
+ +---------------------------------------+
+ |
+ v
+ +------------------+
+ | Benchmarker |
+ +------------------+
+```
+
+## Core Components
+
+### 1. **Backend**
+
+The `Backend` is an abstract interface for interacting with generative AI backends. It is responsible for processing requests and generating results. GuideLLM supports OpenAI-compatible HTTP servers, such as vLLM, as backends.
+
+- **Responsibilities:**
+ - Accept requests from the `RequestsWorker`.
+ - Generate responses for text or chat completions.
+ - Validate backend readiness and available models.
+
+### 2. **RequestLoader**
+
+The `RequestLoader` handles sourcing data from an iterable and generating requests for the backend. It ensures that data is properly formatted and ready for processing.
+
+- **Responsibilities:**
+ - Load data from datasets or synthetic sources.
+ - Generate requests in a format compatible with the backend.
+
+### 3. **DatasetCreator**
+
+The `DatasetCreator` is responsible for loading data sources and converting them into Hugging Face (HF) dataset items. These items can then be streamed by the `RequestLoader`.
+
+- **Responsibilities:**
+ - Load datasets from local files, Hugging Face datasets, or synthetic data.
+ - Convert data into a format compatible with the `RequestLoader`.
+
+### 4. **Scheduler**
+
+The `Scheduler` manages the scheduling of requests to the backend. It uses multiprocessing and multithreading with asyncio to minimize overheads and maximize throughput.
+
+- **Responsibilities:**
+ - Schedule requests to the backend.
+ - Manage queues for requests and results.
+ - Ensure efficient utilization of resources.
+
+### 5. **RequestsWorker**
+
+The `RequestsWorker` is a worker process that pulls requests from a queue, processes them using the backend, and sends the results back to the scheduler.
+
+- **Responsibilities:**
+ - Process requests from the scheduler.
+ - Interact with the backend to generate results.
+ - Return results to the scheduler.
+
+### 6. **Benchmarker**
+
+The `Benchmarker` wraps around multiple invocations of the `Scheduler`, one for each benchmark. It aggregates results using a `BenchmarkAggregator` and compiles them into a `Benchmark` once complete.
+
+- **Responsibilities:**
+ - Manage multiple benchmarks.
+ - Aggregate results from the scheduler.
+ - Compile results into a final benchmark report.
+
+### 7. **BenchmarkAggregator**
+
+The `BenchmarkAggregator` is responsible for storing and compiling results from the benchmarks.
+
+- **Responsibilities:**
+ - Aggregate results from multiple benchmarks.
+ - Compile results into a `Benchmark` object.
+
+## Component Interactions
+
+The following diagram illustrates the relationships between the core components:
diff --git a/docs/assets/sample-benchmarks.gif b/docs/assets/sample-benchmarks.gif
index 160763b7..d9cfc6a8 100644
Binary files a/docs/assets/sample-benchmarks.gif and b/docs/assets/sample-benchmarks.gif differ
diff --git a/docs/assets/sample-output-end.png b/docs/assets/sample-output-end.png
deleted file mode 100644
index 7211807b..00000000
Binary files a/docs/assets/sample-output-end.png and /dev/null differ
diff --git a/docs/assets/sample-output-start.png b/docs/assets/sample-output-start.png
deleted file mode 100644
index 777db81a..00000000
Binary files a/docs/assets/sample-output-start.png and /dev/null differ
diff --git a/docs/assets/sample-output.png b/docs/assets/sample-output.png
new file mode 100644
index 00000000..c830d20d
Binary files /dev/null and b/docs/assets/sample-output.png differ
diff --git a/docs/backends.md b/docs/backends.md
new file mode 100644
index 00000000..9bb053f0
--- /dev/null
+++ b/docs/backends.md
@@ -0,0 +1,45 @@
+# Supported Backends for GuideLLM
+
+GuideLLM is designed to work with OpenAI-compatible HTTP servers, enabling seamless integration with a variety of generative AI backends. This compatibility ensures that users can evaluate and optimize their large language model (LLM) deployments efficiently. While the current focus is on OpenAI-compatible servers, we welcome contributions to expand support for other backends, including additional server implementations and Python interfaces.
+
+## Supported Backends
+
+### OpenAI-Compatible HTTP Servers
+
+GuideLLM supports OpenAI-compatible HTTP servers, which provide a standardized API for interacting with LLMs. This includes popular implementations such as [vLLM](https://github.com/vllm-project/vllm) and [Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference). These servers allow GuideLLM to perform evaluations, benchmarks, and optimizations with minimal setup.
+
+## Examples for Spinning Up Compatible Servers
+
+### 1. vLLM
+
+[vLLM](https://github.com/vllm-project/vllm) is a high-performance OpenAI-compatible server designed for efficient LLM inference. It supports a variety of models and provides a simple interface for deployment.
+
+First ensure you have vLLM installed (`pip install vllm`), and then run the following command to start a vLLM server with a Llama 3.1 8B quantized model:
+
+```bash
+vllm serve "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16"
+```
+
+For more information on starting a vLLM server, see the [vLLM Documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
+
+### 2. Text Generation Inference (TGI)
+
+[Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is another OpenAI-compatible server that supports a wide range of models, including those hosted on Hugging Face. TGI is optimized for high-throughput and low-latency inference.
+
+To start a TGI server with a Llama 3.1 8B model using Docker, run the following command:
+
+```bash
+docker run --gpus 1 -ti --shm-size 1g --ipc=host --rm -p 8080:80 \
+ -e MODEL_ID=meta-llama/Meta-Llama-3.1-8B-Instruct \
+ -e NUM_SHARD=1 \
+ -e MAX_INPUT_TOKENS=4096 \
+ -e MAX_TOTAL_TOKENS=6000 \
+ -e HF_TOKEN=$(cat ~/.cache/huggingface/token) \
+ ghcr.io/huggingface/text-generation-inference:2.2.0
+```
+
+For more information on starting a TGI server, see the [TGI Documentation](https://huggingface.co/docs/text-generation-inference/index).
+
+## Expanding Backend Support
+
+GuideLLM is an open platform, and we encourage contributions to extend its backend support. Whether it's adding new server implementations, integrating with Python-based backends, or enhancing existing capabilities, your contributions are welcome. For more details on how to contribute, see the [CONTRIBUTING.md](https://github.com/neuralmagic/guidellm/blob/main/CONTRIBUTING.md) file.
diff --git a/docs/install.md b/docs/install.md
index d30962bd..2237f8af 100644
--- a/docs/install.md
+++ b/docs/install.md
@@ -1 +1,87 @@
-# Coming Soon
+# Installation Guide for GuideLLM
+
+GuideLLM can be installed using several methods depending on your requirements. Below are the detailed instructions for each installation pathway.
+
+## Prerequisites
+
+Before installing GuideLLM, ensure you have the following prerequisites:
+
+- **Operating System:** Linux or MacOS
+
+- **Python Version:** 3.9 – 3.13
+
+- **Pip Version:** Ensure you have the latest version of pip installed. You can upgrade pip using the following command:
+
+ ```bash
+ python -m pip install --upgrade pip
+ ```
+
+## Installation Methods
+
+### 1. Install the Latest Release from PyPI
+
+The simplest way to install GuideLLM is via pip from the Python Package Index (PyPI):
+
+```bash
+pip install guidellm
+```
+
+This will install the latest stable release of GuideLLM.
+
+### 2. Install a Specific Version from PyPI
+
+If you need a specific version of GuideLLM, you can specify the version number during installation. For example, to install version `0.2.0`:
+
+```bash
+pip install guidellm==0.2.0
+```
+
+### 3. Install from Source on the Main Branch
+
+To install the latest development version of GuideLLM from the main branch, use the following command:
+
+```bash
+pip install git+https://github.com/neuralmagic/guidellm.git
+```
+
+This will clone the repository and install GuideLLM directly from the main branch.
+
+### 4. Install from a Specific Branch
+
+If you want to install GuideLLM from a specific branch (e.g., `feature-branch`), use the following command:
+
+```bash
+pip install git+https://github.com/neuralmagic/guidellm.git@feature-branch
+```
+
+Replace `feature-branch` with the name of the branch you want to install.
+
+### 5. Install from a Local Clone
+
+If you have cloned the GuideLLM repository locally and want to install it, navigate to the repository directory and run:
+
+```bash
+pip install .
+```
+
+Alternatively, for development purposes, you can install it in editable mode:
+
+```bash
+pip install -e .
+```
+
+This allows you to make changes to the source code and have them reflected immediately without reinstalling.
+
+## Verifying the Installation
+
+After installation, you can verify that GuideLLM is installed correctly by running:
+
+```bash
+guidellm --help
+```
+
+This should display the installed version of GuideLLM.
+
+## Troubleshooting
+
+If you encounter any issues during installation, ensure that your Python and pip versions meet the prerequisites. For further assistance, please refer to the [GitHub Issues](https://github.com/neuralmagic/guidellm/issues) page or consult the [Documentation](https://github.com/neuralmagic/guidellm/tree/main/docs).
diff --git a/docs/metrics.md b/docs/metrics.md
new file mode 100644
index 00000000..2666033b
--- /dev/null
+++ b/docs/metrics.md
@@ -0,0 +1,112 @@
+# Metrics Documentation
+
+GuideLLM provides a comprehensive set of metrics to evaluate and optimize the performance of large language model (LLM) deployments. These metrics are designed to help users understand the behavior of their models under various conditions, identify bottlenecks, and make informed decisions about scaling and resource allocation. Below, we outline the key metrics measured by GuideLLM, their definitions, use cases, and how they can be interpreted.
+
+## Request Status Metrics
+
+### Successful, Incomplete, and Error Requests
+
+- **Successful Requests**: The number of requests that were completed successfully without any errors.
+- **Incomplete Requests**: The number of requests that were started but not completed, often due to timeouts or interruptions.
+- **Error Requests**: The number of requests that failed due to errors, such as invalid inputs or server issues.
+
+These metrics provide a breakdown of the overall request statuses, helping users identify the reliability and stability of their LLM deployment.
+
+### Requests Made
+
+- **Definition**: The total number of requests made during a benchmark run, broken down by status (successful, incomplete, error).
+- **Use Case**: Helps gauge the workload handled by the system and identify the proportion of requests that were successful versus those that failed or were incomplete.
+
+## Token Metrics
+
+### Prompt Tokens and Counts
+
+- **Definition**: The number of tokens in the input prompts sent to the LLM.
+- **Use Case**: Useful for understanding the complexity of the input data and its impact on model performance.
+
+### Output Tokens and Counts
+
+- **Definition**: The number of tokens generated by the LLM in response to the input prompts.
+- **Use Case**: Helps evaluate the model's output length and its correlation with latency and resource usage.
+
+## Performance Metrics
+
+### Request Rate (Requests Per Second)
+
+- **Definition**: The number of requests processed per second.
+- **Use Case**: Indicates the throughput of the system and its ability to handle concurrent workloads.
+
+### Request Concurrency
+
+- **Definition**: The number of requests being processed simultaneously.
+- **Use Case**: Helps evaluate the system's capacity to handle parallel workloads.
+
+### Output Tokens Per Second
+
+- **Definition**: The average number of output tokens generated per second as a throughput metric across all requests.
+- **Use Case**: Provides insights into the server's performance and efficiency in generating output tokens.
+
+### Total Tokens Per Second
+
+- **Definition**: The combined rate of prompt and output tokens processed per second as a throughput metric across all requests.
+- **Use Case**: Provides insights into the server's overall performance and efficiency in processing both prompt and output tokens.
+
+### Request Latency
+
+- **Definition**: The time taken to process a single request, from start to finish.
+- **Use Case**: A critical metric for evaluating the responsiveness of the system.
+
+### Time to First Token (TTFT)
+
+- **Definition**: The time taken to generate the first token of the output.
+- **Use Case**: Indicates the initial response time of the model, which is crucial for user-facing applications.
+
+### Inter-Token Latency (ITL)
+
+- **Definition**: The average time between generating consecutive tokens in the output, excluding the first token.
+- **Use Case**: Helps assess the smoothness and speed of token generation.
+
+### Time Per Output Token
+
+- **Definition**: The average time taken to generate each output token, including the first token.
+- **Use Case**: Provides a detailed view of the model's token generation efficiency.
+
+## Statistical Summaries
+
+GuideLLM provides detailed statistical summaries for each of the above metrics using the `StatusDistributionSummary` and `DistributionSummary` models. These summaries include the following statistics:
+
+### Summary Statistics
+
+- **Mean**: The average value of the metric.
+- **Median**: The middle value of the metric when sorted.
+- **Mode**: The most frequently occurring value of the metric.
+- **Variance**: The measure of how much the values of the metric vary.
+- **Standard Deviation (Std Dev)**: The square root of the variance, indicating the spread of the values.
+- **Min**: The minimum value of the metric.
+- **Max**: The maximum value of the metric.
+- **Count**: The total number of data points for the metric.
+- **Total Sum**: The sum of all values for the metric.
+
+### Percentiles
+
+GuideLLM calculates a comprehensive set of percentiles for each metric, including:
+
+- **0.1th Percentile (p001)**: The value below which 0.1% of the data falls.
+- **1st Percentile (p01)**: The value below which 1% of the data falls.
+- **5th Percentile (p05)**: The value below which 5% of the data falls.
+- **10th Percentile (p10)**: The value below which 10% of the data falls.
+- **25th Percentile (p25)**: The value below which 25% of the data falls.
+- **75th Percentile (p75)**: The value below which 75% of the data falls.
+- **90th Percentile (p90)**: The value below which 90% of the data falls.
+- **95th Percentile (p95)**: The value below which 95% of the data falls.
+- **99th Percentile (p99)**: The value below which 99% of the data falls.
+- **99.9th Percentile (p999)**: The value below which 99.9% of the data falls.
+
+### Use Cases for Statistical Summaries
+
+- **Mean and Median**: Provide a central tendency of the metric values.
+- **Variance and Std Dev**: Indicate the variability and consistency of the metric.
+- **Min and Max**: Highlight the range of the metric values.
+- **Percentiles**: Offer a detailed view of the distribution, helping identify outliers and performance at different levels of service.
+
+By combining these metrics and statistical summaries, GuideLLM enables users to gain a deep understanding of their LLM deployments, optimize performance, and ensure scalability and cost-effectiveness.
diff --git a/docs/outputs.md b/docs/outputs.md
new file mode 100644
index 00000000..ea3d9a6f
--- /dev/null
+++ b/docs/outputs.md
@@ -0,0 +1,109 @@
+# Supported Output Types for GuideLLM
+
+GuideLLM provides flexible options for outputting benchmark results, catering to both console-based summaries and file-based detailed reports. This document outlines the supported output types, their configurations, and how to utilize them effectively.
+
+For all of the output formats, `--output-extras` can be used to include additional information. This could include tags, metadata, hardware details, and other relevant information that can be useful for analysis. This must be supplied as a JSON encoded string. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --output-extras '{"tag": "my_tag", "metadata": {"key": "value"}}'
+```
+
+## Console Output
+
+By default, GuideLLM displays benchmark results and progress directly in the console. The console progress and outputs are divided into multiple sections:
+
+1. **Initial Setup Progress**: Displays the progress of the initial setup, including server connection and data preparation.
+2. **Benchmark Progress**: Shows the progress of the benchmark runs, including the number of requests completed and the current rate.
+3. **Final Results**: Summarizes the benchmark results, including average latency, throughput, and other key metrics.
+ 1. **Benchmarks Metadata**: Summarizes the benchmark run, including server details, data configurations, and profile arguments.
+ 2. **Benchmarks Info**: Provides a high-level overview of each benchmark, including request statuses, token counts, and durations.
+ 3. **Benchmarks Stats**: Displays detailed statistics for each benchmark, such as request rates, concurrency, latency, and token-level metrics.
+
+### Disabling Console Output
+
+To disable the progress outputs to the console, use the `disable-progress` flag when running the `guidellm benchmark` command. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --disable-progress
+```
+
+To disable console output, use the `--disable-console-outputs` flag when running the `guidellm benchmark` command. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --disable-console-outputs
+```
+
+### Enabling Extra Information
+
+GuideLLM includes the option to display extra information during the benchmark runs to monitor the overheads and performance of the system. This can be enabled by using the `--display-scheduler-stats` flag when running the `guidellm benchmark` command. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --display-scheduler-stats
+```
+
+The above command will display an additional row for each benchmark within the progress output, showing the scheduler overheads and other relevant information.
+
+## File-Based Outputs
+
+GuideLLM supports saving benchmark results to files in various formats, including JSON, YAML, and CSV. These files can be used for further analysis, reporting, or reloading into Python for detailed exploration.
+
+### Supported File Formats
+
+1. **JSON**: Contains all benchmark results, including full statistics and request data. This format is ideal for reloading into Python for in-depth analysis.
+2. **YAML**: Similar to JSON, YAML files include all benchmark results and are human-readable.
+3. **CSV**: Provides a summary of the benchmark data, focusing on key metrics and statistics. Note that CSV does not include detailed request-level data.
+
+### Configuring File Outputs
+
+- **Output Path**: Use the `--output-path` argument to specify the file path or directory for saving the results. If a directory is provided, the results will be saved as `benchmarks.json` by default. The file type is determined by the file extension (e.g., `.json`, `.yaml`, `.csv`).
+- **Sampling**: To limit the size of the output files, you can configure sampling options for the dataset using the `--output-sampling` argument.
+
+Example command to save results in YAML format:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --output-path "results/benchmarks.csv" \
+ --output-sampling 20
+```
+
+### Reloading Results
+
+JSON and YAML files can be reloaded into Python for further analysis using the `GenerativeBenchmarksReport` class. Below is a sample code snippet for reloading results:
+
+```python
+from guidellm.benchmark import GenerativeBenchmarksReport
+
+report = GenerativeBenchmarksReport.load_file(
+ path="benchmarks.json",
+)
+benchmarks = report.benchmarks
+
+for benchmark in benchmarks:
+ print(benchmark.id_)
+```
+
+For more details on the `GenerativeBenchmarksReport` class and its methods, refer to the [source code](https://github.com/neuralmagic/guidellm/blob/main/src/guidellm/benchmark/output.py).
diff --git a/docs/service_level_objectives.md b/docs/service_level_objectives.md
new file mode 100644
index 00000000..f45100a5
--- /dev/null
+++ b/docs/service_level_objectives.md
@@ -0,0 +1,102 @@
+# Service Level Objectives (SLOs) and Service Level Agreements (SLAs)
+
+Service Level Objectives (SLOs) and Service Level Agreements (SLAs) are critical for ensuring the quality and reliability of large language model (LLM) deployments. They define measurable performance and reliability targets that a system must meet to satisfy user expectations and business requirements. Below, we outline the key concepts, tradeoffs, and examples of SLOs/SLAs for various LLM use cases.
+
+## Definitions
+
+### Service Level Objectives (SLOs)
+
+SLOs are internal performance and reliability targets that guide the operation and optimization of a system. They are typically defined as measurable metrics, such as latency, throughput, or error rates, and serve as benchmarks for evaluating system performance.
+
+### Service Level Agreements (SLAs)
+
+SLAs are formal agreements between a service provider and its users or customers. They specify the performance and reliability guarantees that the provider commits to delivering. SLAs often include penalties or compensations if the agreed-upon targets are not met.
+
+## Tradeoffs Between Latency and Throughput
+
+When setting SLOs and SLAs for LLM deployments, it is essential to balance the tradeoffs between latency, throughput, and cost efficiency:
+
+- **Latency**: The time taken to process individual requests, including metrics like Time to First Token (TTFT) and Inter-Token Latency (ITL). Low latency is critical for user-facing applications where responsiveness is key.
+- **Throughput**: The number of requests processed per second. High throughput is essential for handling large-scale workloads efficiently.
+- **Cost Efficiency**: The cost per request, which depends on the system's resource utilization and throughput. Optimizing for cost efficiency often involves increasing throughput, which may come at the expense of higher latency for individual requests.
+
+For example, a chat application may prioritize low latency to ensure a smooth user experience, while a batch processing system for content generation may prioritize high throughput to minimize costs.
+
+## Examples of SLOs/SLAs for Common LLM Use Cases
+
+### Real-Time, Application-Facing Usage
+
+This category includes use cases where low latency is critical for external-facing applications. These systems must ensure quick responses to maintain user satisfaction and meet stringent performance requirements.
+
+#### 1. Chat Applications
+
+**Enterprise Use Case**: A customer support chatbot for an e-commerce platform, where quick responses are critical to maintaining user satisfaction and resolving issues in real time.
+
+- **SLOs**:
+ - TTFT: ≤ 200ms for 99% of requests
+ - ITL: ≤ 50ms for 99% of requests
+
+#### 2. Retrieval-Augmented Generation (RAG)
+
+**Enterprise Use Case**: A legal document search tool that retrieves and summarizes relevant case law in real time for lawyers during court proceedings.
+
+- **SLOs**:
+ - Request Latency: ≤ 3s for 99% of requests
+ - TTFT: ≤ 300ms for 99% of requests (if iterative outputs are shown)
+ - ITL: ≤ 100ms for 99% of requests (if iterative outputs are shown)
+
+#### 3. Instruction Following / Agentic AI
+
+**Enterprise Use Case**: A virtual assistant for scheduling meetings and managing tasks, where quick responses are essential for user productivity.
+
+- **SLOs**:
+ - Request Latency: ≤ 5s for 99% of requests
+
+### Real-Time, Internal Usage
+
+This category includes use cases where low latency is important but less stringent compared to external-facing applications. These systems are often used by internal teams within enterprises, but if provided as a service, they may require external-facing guarantees.
+
+#### 4. Content Generation
+
+**Enterprise Use Case**: An internal marketing tool for generating ad copy and social media posts, where slightly higher latencies are acceptable compared to external-facing applications.
+
+- **SLOs**:
+ - TTFT: ≤ 600ms for 99% of requests
+ - ITL: ≤ 200ms for 99% of requests
+
+#### 5. Code Generation
+
+**Enterprise Use Case**: A developer productivity tool for generating boilerplate code and API integrations, used internally by engineering teams.
+
+- **SLOs**:
+ - TTFT: ≤ 500ms for 99% of requests
+ - ITL: ≤ 150ms for 99% of requests
+
+#### 6. Code Completion
+
+**Enterprise Use Case**: An integrated development environment (IDE) plugin for auto-completing code snippets, improving developer efficiency.
+
+- **SLOs**:
+ - Request Latency: ≤ 2s for 99% of requests
+
+### Offline, Batch Use Cases
+
+This category includes use cases where maximizing throughput is the primary concern. These systems process large volumes of data in batches, often during off-peak hours, to optimize resource utilization and cost efficiency.
+
+#### 7. Summarization
+
+**Enterprise Use Case**: A tool for summarizing customer reviews to extract insights for product improvement, processed in large batches overnight.
+
+- **SLOs**:
+ - Maximize Throughput: ≥ 100 requests per second
+
+#### 8. Analysis
+
+**Enterprise Use Case**: A data analysis pipeline for generating actionable insights from sales data, used to inform quarterly business strategies.
+
+- **SLOs**:
+ - Maximize Throughput: ≥ 150 requests per second
+
+## Conclusion
+
+Setting appropriate SLOs and SLAs is essential for optimizing LLM deployments to meet user expectations and business requirements. By balancing latency, throughput, and cost efficiency, organizations can ensure high-quality service while minimizing operational costs. The examples provided above serve as a starting point for defining SLOs and SLAs tailored to specific use cases.
diff --git a/pyproject.toml b/pyproject.toml
index bc352c45..5e27a12b 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -17,7 +17,7 @@ include = ["*"]
[project]
name = "guidellm"
-version = "0.1.0"
+version = "0.2.0"
description = "Guidance platform for deploying and managing large language models."
readme = { file = "README.md", content-type = "text/markdown" }
requires-python = ">=3.9.0,<4.0"
@@ -79,7 +79,6 @@ dev = [
[project.entry-points.console_scripts]
guidellm = "guidellm.__main__:cli"
-guidellm-config = "guidellm.config:print_config"
# ************************************************
diff --git a/src/guidellm/__init__.py b/src/guidellm/__init__.py
index 3bf38f03..237ef1f3 100644
--- a/src/guidellm/__init__.py
+++ b/src/guidellm/__init__.py
@@ -10,9 +10,11 @@
import contextlib
-with open(os.devnull, "w") as devnull, contextlib.redirect_stderr(
- devnull
-), contextlib.redirect_stdout(devnull):
+with (
+ open(os.devnull, "w") as devnull,
+ contextlib.redirect_stderr(devnull),
+ contextlib.redirect_stdout(devnull),
+):
from transformers.utils import logging as hf_logging # type: ignore[import]
# Set the log level for the transformers library to ERROR
diff --git a/src/guidellm/__main__.py b/src/guidellm/__main__.py
index f6b0e3d8..f38b11aa 100644
--- a/src/guidellm/__main__.py
+++ b/src/guidellm/__main__.py
@@ -7,6 +7,7 @@
from guidellm.backend import BackendType
from guidellm.benchmark import ProfileType, benchmark_generative_text
+from guidellm.config import print_config
from guidellm.scheduler import StrategyType
STRATEGY_PROFILE_CHOICES = set(
@@ -42,7 +43,9 @@ def cli():
pass
-@cli.command()
+@cli.command(
+ help="Run a benchmark against a generative model using the specified arguments."
+)
@click.option(
"--target",
required=True,
@@ -277,5 +280,15 @@ def benchmark(
)
+@cli.command(
+ help=(
+ "Print out the available configuration settings that can be set "
+ "through environment variables."
+ )
+)
+def config():
+ print_config()
+
+
if __name__ == "__main__":
cli()
diff --git a/src/guidellm/config.py b/src/guidellm/config.py
index dd5be74b..cfd0dcd5 100644
--- a/src/guidellm/config.py
+++ b/src/guidellm/config.py
@@ -210,7 +210,3 @@ def print_config():
Print the current configuration settings
"""
print(f"Settings: \n{settings.generate_env_file()}") # noqa: T201
-
-
-if __name__ == "__main__":
- print_config()
diff --git a/src/guidellm/scheduler/scheduler.py b/src/guidellm/scheduler/scheduler.py
index b56684de..68dcab21 100644
--- a/src/guidellm/scheduler/scheduler.py
+++ b/src/guidellm/scheduler/scheduler.py
@@ -113,9 +113,12 @@ async def run(
if max_duration is not None and max_duration < 0:
raise ValueError(f"Invalid max_duration: {max_duration}")
- with multiprocessing.Manager() as manager, ProcessPoolExecutor(
- max_workers=scheduling_strategy.processes_limit
- ) as executor:
+ with (
+ multiprocessing.Manager() as manager,
+ ProcessPoolExecutor(
+ max_workers=scheduling_strategy.processes_limit
+ ) as executor,
+ ):
requests_iter: Optional[Iterator[Any]] = None
futures, requests_queue, responses_queue = await self._start_processes(
manager, executor, scheduling_strategy
diff --git a/src/guidellm/utils/text.py b/src/guidellm/utils/text.py
index ee3cb2e7..a735940a 100644
--- a/src/guidellm/utils/text.py
+++ b/src/guidellm/utils/text.py
@@ -150,9 +150,10 @@ def load_text(data: Union[str, Path], encoding: Optional[str] = None) -> str:
# check package data
if isinstance(data, str) and data.startswith("data:"):
resource_path = files(package_data).joinpath(data[5:])
- with as_file(resource_path) as resource_file, gzip.open(
- resource_file, "rt", encoding=encoding
- ) as file:
+ with (
+ as_file(resource_path) as resource_file,
+ gzip.open(resource_file, "rt", encoding=encoding) as file,
+ ):
return file.read()
# check gzipped files
diff --git a/tests/unit/benchmark/test_output.py b/tests/unit/benchmark/test_output.py
index 5089dbb2..9076834b 100644
--- a/tests/unit/benchmark/test_output.py
+++ b/tests/unit/benchmark/test_output.py
@@ -166,9 +166,11 @@ def test_console_print_table():
console = GenerativeBenchmarksConsole(enabled=True)
headers = ["Header1", "Header2"]
rows = [["Row1Col1", "Row1Col2"], ["Row2Col1", "Row2Col2"]]
- with patch.object(console, "print_section_header") as mock_header, patch.object(
- console, "print_table_divider"
- ) as mock_divider, patch.object(console, "print_table_row") as mock_row:
+ with (
+ patch.object(console, "print_section_header") as mock_header,
+ patch.object(console, "print_table_divider") as mock_divider,
+ patch.object(console, "print_table_row") as mock_row,
+ ):
console.print_table(headers, rows, "Test Table")
mock_header.assert_called_once()
mock_divider.assert_called()
@@ -179,9 +181,10 @@ def test_console_print_benchmarks_metadata():
console = GenerativeBenchmarksConsole(enabled=True)
mock_benchmark = mock_generative_benchmark()
console.benchmarks = [mock_benchmark]
- with patch.object(console, "print_section_header") as mock_header, patch.object(
- console, "print_labeled_line"
- ) as mock_labeled:
+ with (
+ patch.object(console, "print_section_header") as mock_header,
+ patch.object(console, "print_labeled_line") as mock_labeled,
+ ):
console.print_benchmarks_metadata()
mock_header.assert_called_once()
mock_labeled.assert_called()
+For further details about the supported output file types, view the [Outputs documentation](raw.githubusercontent.com/neuralmagic/guidellm/main/docs/outputs.md).
#### 4. Use the Results
The results from GuideLLM are used to optimize your LLM deployment for performance, resource efficiency, and cost. By analyzing the performance metrics, you can identify bottlenecks, determine the optimal request rate, and select the most cost-effective hardware configuration for your deployment.
-For example, if we deploy a latency-sensitive chat application, we likely want to optimize for low time to first token (TTFT) and inter-token latency (ITL). A reasonable threshold will depend on the application requirements. Still, we may want to ensure time to first token (TTFT) is under 200ms and inter-token latency (ITL) is under 50ms (20 updates per second). From the example results above, we can see that the model can meet these requirements on average at a request rate of 2.37 requests per second for each server. If you'd like to target a higher percentage of requests meeting these requirements, you can use the **Performance Stats by Benchmark** section to determine the rate at which 90% or 95% of requests meet these requirements.
+For example, if we are deploying a chat application, we likely want to guarantee our time to first token (TTFT) and inter-token latency (ITL) are under certain thresholds to meet our service level objectives (SLOs) or agreements (SLAs). For example, setting TTFT to 200ms and ITL 25ms for the sample data provided in the example above, we can see that even though the server is capable of handling up to 13 requests per second, we would only be able to meet our SLOs for 99% of users at a request rate of 3.5 requests per second. If we relax our constraints on ITL to 50ms, then we can meet the TTFT SLA for 99% of users at a request rate of roughly 10 requests per second.
-If we deploy a throughput-sensitive summarization application, we likely want to optimize for the maximum requests the server can handle per second. In this case, the throughput benchmark shows that the server maxes out at 4.06 requests per second. If we need to handle more requests, consider adding more servers or upgrading the hardware configuration.
+For further details about deterimining the optimal request rate and SLOs, view the [SLOs documentation](https://raw.githubusercontent.com/neuralmagic/guidellm/main/docs/service_level_objectives.md).
### Configurations
-GuideLLM provides various CLI and environment options to customize evaluations, including setting the duration of each benchmark run, the number of concurrent requests, and the request rate.
+GuideLLM provides a variety of configurations through both the benchmark CLI command alongside environment variables which handle default values and more granular controls. Below, the most common configurations are listed. A complete list is easily accessible, though, by running `guidellm benchmark --help` or `guidellm config` respectively.
-Some typical configurations for the CLI include:
+#### Benchmark CLI
-- `--rate-type`: The rate to use for benchmarking. Options include `sweep`, `synchronous`, `throughput`, `constant`, and `poisson`.
- - `--rate-type sweep`: (default) Sweep runs through the full range of the server's performance, starting with a `synchronous` rate, then `throughput`, and finally, 10 `constant` rates between the min and max request rate found.
- - `--rate-type synchronous`: Synchronous runs requests synchronously, one after the other.
- - `--rate-type throughput`: Throughput runs requests in a throughput manner, sending requests as fast as possible.
- - `--rate-type constant`: Constant runs requests at a constant rate. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- - `--rate-type poisson`: Poisson draws from a Poisson distribution with the mean at the specified rate, adding some real-world variance to the runs. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- - `--rate-type concurrent`: Concurrent runs requests at a fixed concurrency. When a requests completes it is immediately replaced with a new request to maintain the set concurrency. Specify the request concurrency with `--rate`.
-- `--data`: A hugging face dataset name or arguments to generate a synthetic dataset.
-- `--max-seconds`: The maximum number of seconds to run each benchmark.
-- `--max-requests`: The maximum number of requests to run in each benchmark.
+The `guidellm benchmark` command is used to run benchmarks against a generative AI backend/server. The command accepts a variety of arguments to customize the benchmark run. The most common arguments include:
-For a complete list of supported CLI arguments, run the following command:
+- `--target`: Specifies the target path for the backend to run benchmarks against. For example, `http://localhost:8000`. This is required to define the server endpoint.
-```bash
-guidellm --help
-```
+- `--model`: Allows selecting a specific model from the server. If not provided, it defaults to the first model available on the server. Useful when multiple models are hosted on the same server.
-For a full list of configuration options, run the following command:
+- `--processor`: Used only for synthetic data creation or when the token source configuration is set to local for calculating token metrics locally. It must match the model's processor/tokenizer to ensure compatibility and correctness. This supports either a HuggingFace model ID or a local path to a processor/tokenizer.
-```bash
-guidellm-config
-```
+- `--data`: Specifies the dataset to use. This can be a HuggingFace dataset ID, a local path to a dataset, or standard text files such as CSV, JSONL, and more. Additionally, synthetic data configurations can be provided using JSON or key-value strings. Synthetic data options include:
+
+ - `prompt_tokens`: Average number of tokens for prompts.
+ - `output_tokens`: Average number of tokens for outputs.
+ - `TYPE_stdev`, `TYPE_min`, `TYPE_max`: Standard deviation, minimum, and maximum values for the specified type (e.g., `prompt_tokens`, `output_tokens`). If not provided, will use the provided tokens value only.
+ - `samples`: Number of samples to generate, defaults to 1000.
+ - `source`: Source text data for generation, defaults to a local copy of Pride and Prejudice.
+
+- `--data-args`: A JSON string used to specify the columns to source data from (e.g., `prompt_column`, `output_tokens_count_column`) and additional arguments to pass into the HuggingFace datasets constructor.
+
+- `--data-sampler`: Enables applying `random` shuffling or sampling to the dataset. If not set, no sampling is applied.
+
+- `--rate-type`: Defines the type of benchmark to run (default sweep). Supported types include:
+
+ - `synchronous`: Runs a single stream of requests one at a time. `--rate` must not be set for this mode.
+ - `throughput`: Runs all requests in parallel to measure the maximum throughput for the server (bounded by GUIDELLM\_\_MAX_CONCURRENCY config argument). `--rate` must not be set for this mode.
+ - `concurrent`: Runs a fixed number of streams of requests in parallel. `--rate` must be set to the desired concurrency level/number of streams.
+ - `constant`: Sends requests asynchronously at a constant rate set by `--rate`.
+ - `poisson`: Sends requests at a rate following a Poisson distribution with the mean set by `--rate`.
+ - `sweep`: Automatically determines the minimum and maximum rates the server can support by running synchronous and throughput benchmarks and then runs a series of benchmarks equally spaced between the two rates. The number of benchmarks is set by `--rate` (default is 10).
+
+- `--max-seconds`: Sets the maximum duration (in seconds) for each benchmark run. If not provided, the benchmark will run until the dataset is exhausted or `--max-requests` is reached.
-See the [GuideLLM Documentation](#Documentation) for further information.
+- `--max-requests`: Sets the maximum number of requests for each benchmark run. If not provided, the benchmark will run until `--max-seconds` is reached or the dataset is exhausted.
+
+- `--warmup-percent`: Specifies the percentage of the benchmark to treat as a warmup phase. Requests during this phase are excluded from the final results.
+
+- `--cooldown-percent`: Specifies the percentage of the benchmark to treat as a cooldown phase. Requests during this phase are excluded from the final results.
+
+- `--output-path`: Defines the path to save the benchmark results. Supports JSON, YAML, or CSV formats. If a directory is provided, the results will be saved as `benchmarks.json` in that directory. If not set, the results will be saved in the current working directory.
## Resources
@@ -155,9 +162,10 @@ Our comprehensive documentation provides detailed guides and resources to help y
### Core Docs
- [**Installation Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/install.md) - This guide provides step-by-step instructions for installing GuideLLM, including prerequisites and setup tips.
+- [**Backends Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/backends.md) - A comprehensive overview of supported backends and how to set them up for use with GuideLLM.
+- [**Metrics Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/metrics.md) - Detailed explanations of the metrics used in GuideLLM, including definitions and how to interpret them.
+- [**Outputs Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/outputs.md) - Information on the different output formats supported by GuideLLM and how to use them.
- [**Architecture Overview**](https://github.com/neuralmagic/guidellm/tree/main/docs/architecture.md) - A detailed look at GuideLLM's design, components, and how they interact.
-- [**CLI Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/cli.md) - Comprehensive usage information for running GuideLLM via the command line, including available commands and options.
-- [**Configuration Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/configuration.md) - Instructions on configuring GuideLLM to suit various deployment needs and performance goals.
### Supporting External Documentation
@@ -185,10 +193,8 @@ We appreciate contributions to the code, examples, integrations, documentation,
We invite you to join our growing community of developers, researchers, and enthusiasts passionate about LLMs and optimization. Whether you're looking for help, want to share your own experiences, or stay up to date with the latest developments, there are plenty of ways to get involved:
-- [**Neural Magic Community Slack**](https://neuralmagic.com/community/) - Join our Slack channel to connect with other GuideLLM users and developers. Ask questions, share your work, and get real-time support.
+- [**vLLM Slack**](https://inviter.co/vllm-slack) - Join the vLLM Slack community to connect with other users, ask questions, and share your experiences.
- [**GitHub Issues**](https://github.com/neuralmagic/guidellm/issues) - Report bugs, request features, or browse existing issues. Your feedback helps us improve GuideLLM.
-- [**Subscribe to Updates**](https://neuralmagic.com/subscribe/) - Sign up for the latest news, announcements, and updates about GuideLLM, webinars, events, and more.
-- [**Contact Us**](http://neuralmagic.com/contact/) - Use our contact form for general questions about Neural Magic or GuideLLM.
### Cite
@@ -202,3 +208,6 @@ If you find GuideLLM helpful in your research or projects, please consider citin
howpublished={\url{https://github.com/neuralmagic/guidellm}},
}
```
+
+```
+```
diff --git a/docs/architecture.md b/docs/architecture.md
index d30962bd..047648ec 100644
--- a/docs/architecture.md
+++ b/docs/architecture.md
@@ -1 +1,97 @@
-# Coming Soon
+# GuideLLM Architecture
+
+GuideLLM is designed to evaluate and optimize large language model (LLM) deployments by simulating real-world inference workloads. The architecture is modular, enabling flexibility and scalability. Below is an overview of the core components and their interactions.
+
+```
++------------------+ +------------------+ +------------------+
+| DatasetCreator | ---> | RequestLoader | ---> | Scheduler |
++------------------+ +------------------+ +------------------+
+ / | \
+ / | \
+ / | \
+ v v v
+ +------------------+ +------------------+
+ | RequestsWorker | | RequestsWorker |
+ +------------------+ +------------------+
+ | |
+ v v
+ +------------------+ +------------------+
+ | Backend | | Backend |
+ +------------------+ +------------------+
+ | |
+ v v
+ +---------------------------------------+
+ | BenchmarkAggregator |
+ +---------------------------------------+
+ |
+ v
+ +------------------+
+ | Benchmarker |
+ +------------------+
+```
+
+## Core Components
+
+### 1. **Backend**
+
+The `Backend` is an abstract interface for interacting with generative AI backends. It is responsible for processing requests and generating results. GuideLLM supports OpenAI-compatible HTTP servers, such as vLLM, as backends.
+
+- **Responsibilities:**
+ - Accept requests from the `RequestsWorker`.
+ - Generate responses for text or chat completions.
+ - Validate backend readiness and available models.
+
+### 2. **RequestLoader**
+
+The `RequestLoader` handles sourcing data from an iterable and generating requests for the backend. It ensures that data is properly formatted and ready for processing.
+
+- **Responsibilities:**
+ - Load data from datasets or synthetic sources.
+ - Generate requests in a format compatible with the backend.
+
+### 3. **DatasetCreator**
+
+The `DatasetCreator` is responsible for loading data sources and converting them into Hugging Face (HF) dataset items. These items can then be streamed by the `RequestLoader`.
+
+- **Responsibilities:**
+ - Load datasets from local files, Hugging Face datasets, or synthetic data.
+ - Convert data into a format compatible with the `RequestLoader`.
+
+### 4. **Scheduler**
+
+The `Scheduler` manages the scheduling of requests to the backend. It uses multiprocessing and multithreading with asyncio to minimize overheads and maximize throughput.
+
+- **Responsibilities:**
+ - Schedule requests to the backend.
+ - Manage queues for requests and results.
+ - Ensure efficient utilization of resources.
+
+### 5. **RequestsWorker**
+
+The `RequestsWorker` is a worker process that pulls requests from a queue, processes them using the backend, and sends the results back to the scheduler.
+
+- **Responsibilities:**
+ - Process requests from the scheduler.
+ - Interact with the backend to generate results.
+ - Return results to the scheduler.
+
+### 6. **Benchmarker**
+
+The `Benchmarker` wraps around multiple invocations of the `Scheduler`, one for each benchmark. It aggregates results using a `BenchmarkAggregator` and compiles them into a `Benchmark` once complete.
+
+- **Responsibilities:**
+ - Manage multiple benchmarks.
+ - Aggregate results from the scheduler.
+ - Compile results into a final benchmark report.
+
+### 7. **BenchmarkAggregator**
+
+The `BenchmarkAggregator` is responsible for storing and compiling results from the benchmarks.
+
+- **Responsibilities:**
+ - Aggregate results from multiple benchmarks.
+ - Compile results into a `Benchmark` object.
+
+## Component Interactions
+
+The following diagram illustrates the relationships between the core components:
diff --git a/docs/assets/sample-benchmarks.gif b/docs/assets/sample-benchmarks.gif
index 160763b7..d9cfc6a8 100644
Binary files a/docs/assets/sample-benchmarks.gif and b/docs/assets/sample-benchmarks.gif differ
diff --git a/docs/assets/sample-output-end.png b/docs/assets/sample-output-end.png
deleted file mode 100644
index 7211807b..00000000
Binary files a/docs/assets/sample-output-end.png and /dev/null differ
diff --git a/docs/assets/sample-output-start.png b/docs/assets/sample-output-start.png
deleted file mode 100644
index 777db81a..00000000
Binary files a/docs/assets/sample-output-start.png and /dev/null differ
diff --git a/docs/assets/sample-output.png b/docs/assets/sample-output.png
new file mode 100644
index 00000000..c830d20d
Binary files /dev/null and b/docs/assets/sample-output.png differ
diff --git a/docs/backends.md b/docs/backends.md
new file mode 100644
index 00000000..9bb053f0
--- /dev/null
+++ b/docs/backends.md
@@ -0,0 +1,45 @@
+# Supported Backends for GuideLLM
+
+GuideLLM is designed to work with OpenAI-compatible HTTP servers, enabling seamless integration with a variety of generative AI backends. This compatibility ensures that users can evaluate and optimize their large language model (LLM) deployments efficiently. While the current focus is on OpenAI-compatible servers, we welcome contributions to expand support for other backends, including additional server implementations and Python interfaces.
+
+## Supported Backends
+
+### OpenAI-Compatible HTTP Servers
+
+GuideLLM supports OpenAI-compatible HTTP servers, which provide a standardized API for interacting with LLMs. This includes popular implementations such as [vLLM](https://github.com/vllm-project/vllm) and [Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference). These servers allow GuideLLM to perform evaluations, benchmarks, and optimizations with minimal setup.
+
+## Examples for Spinning Up Compatible Servers
+
+### 1. vLLM
+
+[vLLM](https://github.com/vllm-project/vllm) is a high-performance OpenAI-compatible server designed for efficient LLM inference. It supports a variety of models and provides a simple interface for deployment.
+
+First ensure you have vLLM installed (`pip install vllm`), and then run the following command to start a vLLM server with a Llama 3.1 8B quantized model:
+
+```bash
+vllm serve "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16"
+```
+
+For more information on starting a vLLM server, see the [vLLM Documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
+
+### 2. Text Generation Inference (TGI)
+
+[Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is another OpenAI-compatible server that supports a wide range of models, including those hosted on Hugging Face. TGI is optimized for high-throughput and low-latency inference.
+
+To start a TGI server with a Llama 3.1 8B model using Docker, run the following command:
+
+```bash
+docker run --gpus 1 -ti --shm-size 1g --ipc=host --rm -p 8080:80 \
+ -e MODEL_ID=meta-llama/Meta-Llama-3.1-8B-Instruct \
+ -e NUM_SHARD=1 \
+ -e MAX_INPUT_TOKENS=4096 \
+ -e MAX_TOTAL_TOKENS=6000 \
+ -e HF_TOKEN=$(cat ~/.cache/huggingface/token) \
+ ghcr.io/huggingface/text-generation-inference:2.2.0
+```
+
+For more information on starting a TGI server, see the [TGI Documentation](https://huggingface.co/docs/text-generation-inference/index).
+
+## Expanding Backend Support
+
+GuideLLM is an open platform, and we encourage contributions to extend its backend support. Whether it's adding new server implementations, integrating with Python-based backends, or enhancing existing capabilities, your contributions are welcome. For more details on how to contribute, see the [CONTRIBUTING.md](https://github.com/neuralmagic/guidellm/blob/main/CONTRIBUTING.md) file.
diff --git a/docs/install.md b/docs/install.md
index d30962bd..2237f8af 100644
--- a/docs/install.md
+++ b/docs/install.md
@@ -1 +1,87 @@
-# Coming Soon
+# Installation Guide for GuideLLM
+
+GuideLLM can be installed using several methods depending on your requirements. Below are the detailed instructions for each installation pathway.
+
+## Prerequisites
+
+Before installing GuideLLM, ensure you have the following prerequisites:
+
+- **Operating System:** Linux or MacOS
+
+- **Python Version:** 3.9 – 3.13
+
+- **Pip Version:** Ensure you have the latest version of pip installed. You can upgrade pip using the following command:
+
+ ```bash
+ python -m pip install --upgrade pip
+ ```
+
+## Installation Methods
+
+### 1. Install the Latest Release from PyPI
+
+The simplest way to install GuideLLM is via pip from the Python Package Index (PyPI):
+
+```bash
+pip install guidellm
+```
+
+This will install the latest stable release of GuideLLM.
+
+### 2. Install a Specific Version from PyPI
+
+If you need a specific version of GuideLLM, you can specify the version number during installation. For example, to install version `0.2.0`:
+
+```bash
+pip install guidellm==0.2.0
+```
+
+### 3. Install from Source on the Main Branch
+
+To install the latest development version of GuideLLM from the main branch, use the following command:
+
+```bash
+pip install git+https://github.com/neuralmagic/guidellm.git
+```
+
+This will clone the repository and install GuideLLM directly from the main branch.
+
+### 4. Install from a Specific Branch
+
+If you want to install GuideLLM from a specific branch (e.g., `feature-branch`), use the following command:
+
+```bash
+pip install git+https://github.com/neuralmagic/guidellm.git@feature-branch
+```
+
+Replace `feature-branch` with the name of the branch you want to install.
+
+### 5. Install from a Local Clone
+
+If you have cloned the GuideLLM repository locally and want to install it, navigate to the repository directory and run:
+
+```bash
+pip install .
+```
+
+Alternatively, for development purposes, you can install it in editable mode:
+
+```bash
+pip install -e .
+```
+
+This allows you to make changes to the source code and have them reflected immediately without reinstalling.
+
+## Verifying the Installation
+
+After installation, you can verify that GuideLLM is installed correctly by running:
+
+```bash
+guidellm --help
+```
+
+This should display the installed version of GuideLLM.
+
+## Troubleshooting
+
+If you encounter any issues during installation, ensure that your Python and pip versions meet the prerequisites. For further assistance, please refer to the [GitHub Issues](https://github.com/neuralmagic/guidellm/issues) page or consult the [Documentation](https://github.com/neuralmagic/guidellm/tree/main/docs).
diff --git a/docs/metrics.md b/docs/metrics.md
new file mode 100644
index 00000000..2666033b
--- /dev/null
+++ b/docs/metrics.md
@@ -0,0 +1,112 @@
+# Metrics Documentation
+
+GuideLLM provides a comprehensive set of metrics to evaluate and optimize the performance of large language model (LLM) deployments. These metrics are designed to help users understand the behavior of their models under various conditions, identify bottlenecks, and make informed decisions about scaling and resource allocation. Below, we outline the key metrics measured by GuideLLM, their definitions, use cases, and how they can be interpreted.
+
+## Request Status Metrics
+
+### Successful, Incomplete, and Error Requests
+
+- **Successful Requests**: The number of requests that were completed successfully without any errors.
+- **Incomplete Requests**: The number of requests that were started but not completed, often due to timeouts or interruptions.
+- **Error Requests**: The number of requests that failed due to errors, such as invalid inputs or server issues.
+
+These metrics provide a breakdown of the overall request statuses, helping users identify the reliability and stability of their LLM deployment.
+
+### Requests Made
+
+- **Definition**: The total number of requests made during a benchmark run, broken down by status (successful, incomplete, error).
+- **Use Case**: Helps gauge the workload handled by the system and identify the proportion of requests that were successful versus those that failed or were incomplete.
+
+## Token Metrics
+
+### Prompt Tokens and Counts
+
+- **Definition**: The number of tokens in the input prompts sent to the LLM.
+- **Use Case**: Useful for understanding the complexity of the input data and its impact on model performance.
+
+### Output Tokens and Counts
+
+- **Definition**: The number of tokens generated by the LLM in response to the input prompts.
+- **Use Case**: Helps evaluate the model's output length and its correlation with latency and resource usage.
+
+## Performance Metrics
+
+### Request Rate (Requests Per Second)
+
+- **Definition**: The number of requests processed per second.
+- **Use Case**: Indicates the throughput of the system and its ability to handle concurrent workloads.
+
+### Request Concurrency
+
+- **Definition**: The number of requests being processed simultaneously.
+- **Use Case**: Helps evaluate the system's capacity to handle parallel workloads.
+
+### Output Tokens Per Second
+
+- **Definition**: The average number of output tokens generated per second as a throughput metric across all requests.
+- **Use Case**: Provides insights into the server's performance and efficiency in generating output tokens.
+
+### Total Tokens Per Second
+
+- **Definition**: The combined rate of prompt and output tokens processed per second as a throughput metric across all requests.
+- **Use Case**: Provides insights into the server's overall performance and efficiency in processing both prompt and output tokens.
+
+### Request Latency
+
+- **Definition**: The time taken to process a single request, from start to finish.
+- **Use Case**: A critical metric for evaluating the responsiveness of the system.
+
+### Time to First Token (TTFT)
+
+- **Definition**: The time taken to generate the first token of the output.
+- **Use Case**: Indicates the initial response time of the model, which is crucial for user-facing applications.
+
+### Inter-Token Latency (ITL)
+
+- **Definition**: The average time between generating consecutive tokens in the output, excluding the first token.
+- **Use Case**: Helps assess the smoothness and speed of token generation.
+
+### Time Per Output Token
+
+- **Definition**: The average time taken to generate each output token, including the first token.
+- **Use Case**: Provides a detailed view of the model's token generation efficiency.
+
+## Statistical Summaries
+
+GuideLLM provides detailed statistical summaries for each of the above metrics using the `StatusDistributionSummary` and `DistributionSummary` models. These summaries include the following statistics:
+
+### Summary Statistics
+
+- **Mean**: The average value of the metric.
+- **Median**: The middle value of the metric when sorted.
+- **Mode**: The most frequently occurring value of the metric.
+- **Variance**: The measure of how much the values of the metric vary.
+- **Standard Deviation (Std Dev)**: The square root of the variance, indicating the spread of the values.
+- **Min**: The minimum value of the metric.
+- **Max**: The maximum value of the metric.
+- **Count**: The total number of data points for the metric.
+- **Total Sum**: The sum of all values for the metric.
+
+### Percentiles
+
+GuideLLM calculates a comprehensive set of percentiles for each metric, including:
+
+- **0.1th Percentile (p001)**: The value below which 0.1% of the data falls.
+- **1st Percentile (p01)**: The value below which 1% of the data falls.
+- **5th Percentile (p05)**: The value below which 5% of the data falls.
+- **10th Percentile (p10)**: The value below which 10% of the data falls.
+- **25th Percentile (p25)**: The value below which 25% of the data falls.
+- **75th Percentile (p75)**: The value below which 75% of the data falls.
+- **90th Percentile (p90)**: The value below which 90% of the data falls.
+- **95th Percentile (p95)**: The value below which 95% of the data falls.
+- **99th Percentile (p99)**: The value below which 99% of the data falls.
+- **99.9th Percentile (p999)**: The value below which 99.9% of the data falls.
+
+### Use Cases for Statistical Summaries
+
+- **Mean and Median**: Provide a central tendency of the metric values.
+- **Variance and Std Dev**: Indicate the variability and consistency of the metric.
+- **Min and Max**: Highlight the range of the metric values.
+- **Percentiles**: Offer a detailed view of the distribution, helping identify outliers and performance at different levels of service.
+
+By combining these metrics and statistical summaries, GuideLLM enables users to gain a deep understanding of their LLM deployments, optimize performance, and ensure scalability and cost-effectiveness.
diff --git a/docs/outputs.md b/docs/outputs.md
new file mode 100644
index 00000000..ea3d9a6f
--- /dev/null
+++ b/docs/outputs.md
@@ -0,0 +1,109 @@
+# Supported Output Types for GuideLLM
+
+GuideLLM provides flexible options for outputting benchmark results, catering to both console-based summaries and file-based detailed reports. This document outlines the supported output types, their configurations, and how to utilize them effectively.
+
+For all of the output formats, `--output-extras` can be used to include additional information. This could include tags, metadata, hardware details, and other relevant information that can be useful for analysis. This must be supplied as a JSON encoded string. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --output-extras '{"tag": "my_tag", "metadata": {"key": "value"}}'
+```
+
+## Console Output
+
+By default, GuideLLM displays benchmark results and progress directly in the console. The console progress and outputs are divided into multiple sections:
+
+1. **Initial Setup Progress**: Displays the progress of the initial setup, including server connection and data preparation.
+2. **Benchmark Progress**: Shows the progress of the benchmark runs, including the number of requests completed and the current rate.
+3. **Final Results**: Summarizes the benchmark results, including average latency, throughput, and other key metrics.
+ 1. **Benchmarks Metadata**: Summarizes the benchmark run, including server details, data configurations, and profile arguments.
+ 2. **Benchmarks Info**: Provides a high-level overview of each benchmark, including request statuses, token counts, and durations.
+ 3. **Benchmarks Stats**: Displays detailed statistics for each benchmark, such as request rates, concurrency, latency, and token-level metrics.
+
+### Disabling Console Output
+
+To disable the progress outputs to the console, use the `disable-progress` flag when running the `guidellm benchmark` command. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --disable-progress
+```
+
+To disable console output, use the `--disable-console-outputs` flag when running the `guidellm benchmark` command. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --disable-console-outputs
+```
+
+### Enabling Extra Information
+
+GuideLLM includes the option to display extra information during the benchmark runs to monitor the overheads and performance of the system. This can be enabled by using the `--display-scheduler-stats` flag when running the `guidellm benchmark` command. For example:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --display-scheduler-stats
+```
+
+The above command will display an additional row for each benchmark within the progress output, showing the scheduler overheads and other relevant information.
+
+## File-Based Outputs
+
+GuideLLM supports saving benchmark results to files in various formats, including JSON, YAML, and CSV. These files can be used for further analysis, reporting, or reloading into Python for detailed exploration.
+
+### Supported File Formats
+
+1. **JSON**: Contains all benchmark results, including full statistics and request data. This format is ideal for reloading into Python for in-depth analysis.
+2. **YAML**: Similar to JSON, YAML files include all benchmark results and are human-readable.
+3. **CSV**: Provides a summary of the benchmark data, focusing on key metrics and statistics. Note that CSV does not include detailed request-level data.
+
+### Configuring File Outputs
+
+- **Output Path**: Use the `--output-path` argument to specify the file path or directory for saving the results. If a directory is provided, the results will be saved as `benchmarks.json` by default. The file type is determined by the file extension (e.g., `.json`, `.yaml`, `.csv`).
+- **Sampling**: To limit the size of the output files, you can configure sampling options for the dataset using the `--output-sampling` argument.
+
+Example command to save results in YAML format:
+
+```bash
+guidellm benchmark \
+ --target "http://localhost:8000" \
+ --rate-type sweep \
+ --max-seconds 30 \
+ --data "prompt_tokens=256,output_tokens=128" \
+ --output-path "results/benchmarks.csv" \
+ --output-sampling 20
+```
+
+### Reloading Results
+
+JSON and YAML files can be reloaded into Python for further analysis using the `GenerativeBenchmarksReport` class. Below is a sample code snippet for reloading results:
+
+```python
+from guidellm.benchmark import GenerativeBenchmarksReport
+
+report = GenerativeBenchmarksReport.load_file(
+ path="benchmarks.json",
+)
+benchmarks = report.benchmarks
+
+for benchmark in benchmarks:
+ print(benchmark.id_)
+```
+
+For more details on the `GenerativeBenchmarksReport` class and its methods, refer to the [source code](https://github.com/neuralmagic/guidellm/blob/main/src/guidellm/benchmark/output.py).
diff --git a/docs/service_level_objectives.md b/docs/service_level_objectives.md
new file mode 100644
index 00000000..f45100a5
--- /dev/null
+++ b/docs/service_level_objectives.md
@@ -0,0 +1,102 @@
+# Service Level Objectives (SLOs) and Service Level Agreements (SLAs)
+
+Service Level Objectives (SLOs) and Service Level Agreements (SLAs) are critical for ensuring the quality and reliability of large language model (LLM) deployments. They define measurable performance and reliability targets that a system must meet to satisfy user expectations and business requirements. Below, we outline the key concepts, tradeoffs, and examples of SLOs/SLAs for various LLM use cases.
+
+## Definitions
+
+### Service Level Objectives (SLOs)
+
+SLOs are internal performance and reliability targets that guide the operation and optimization of a system. They are typically defined as measurable metrics, such as latency, throughput, or error rates, and serve as benchmarks for evaluating system performance.
+
+### Service Level Agreements (SLAs)
+
+SLAs are formal agreements between a service provider and its users or customers. They specify the performance and reliability guarantees that the provider commits to delivering. SLAs often include penalties or compensations if the agreed-upon targets are not met.
+
+## Tradeoffs Between Latency and Throughput
+
+When setting SLOs and SLAs for LLM deployments, it is essential to balance the tradeoffs between latency, throughput, and cost efficiency:
+
+- **Latency**: The time taken to process individual requests, including metrics like Time to First Token (TTFT) and Inter-Token Latency (ITL). Low latency is critical for user-facing applications where responsiveness is key.
+- **Throughput**: The number of requests processed per second. High throughput is essential for handling large-scale workloads efficiently.
+- **Cost Efficiency**: The cost per request, which depends on the system's resource utilization and throughput. Optimizing for cost efficiency often involves increasing throughput, which may come at the expense of higher latency for individual requests.
+
+For example, a chat application may prioritize low latency to ensure a smooth user experience, while a batch processing system for content generation may prioritize high throughput to minimize costs.
+
+## Examples of SLOs/SLAs for Common LLM Use Cases
+
+### Real-Time, Application-Facing Usage
+
+This category includes use cases where low latency is critical for external-facing applications. These systems must ensure quick responses to maintain user satisfaction and meet stringent performance requirements.
+
+#### 1. Chat Applications
+
+**Enterprise Use Case**: A customer support chatbot for an e-commerce platform, where quick responses are critical to maintaining user satisfaction and resolving issues in real time.
+
+- **SLOs**:
+ - TTFT: ≤ 200ms for 99% of requests
+ - ITL: ≤ 50ms for 99% of requests
+
+#### 2. Retrieval-Augmented Generation (RAG)
+
+**Enterprise Use Case**: A legal document search tool that retrieves and summarizes relevant case law in real time for lawyers during court proceedings.
+
+- **SLOs**:
+ - Request Latency: ≤ 3s for 99% of requests
+ - TTFT: ≤ 300ms for 99% of requests (if iterative outputs are shown)
+ - ITL: ≤ 100ms for 99% of requests (if iterative outputs are shown)
+
+#### 3. Instruction Following / Agentic AI
+
+**Enterprise Use Case**: A virtual assistant for scheduling meetings and managing tasks, where quick responses are essential for user productivity.
+
+- **SLOs**:
+ - Request Latency: ≤ 5s for 99% of requests
+
+### Real-Time, Internal Usage
+
+This category includes use cases where low latency is important but less stringent compared to external-facing applications. These systems are often used by internal teams within enterprises, but if provided as a service, they may require external-facing guarantees.
+
+#### 4. Content Generation
+
+**Enterprise Use Case**: An internal marketing tool for generating ad copy and social media posts, where slightly higher latencies are acceptable compared to external-facing applications.
+
+- **SLOs**:
+ - TTFT: ≤ 600ms for 99% of requests
+ - ITL: ≤ 200ms for 99% of requests
+
+#### 5. Code Generation
+
+**Enterprise Use Case**: A developer productivity tool for generating boilerplate code and API integrations, used internally by engineering teams.
+
+- **SLOs**:
+ - TTFT: ≤ 500ms for 99% of requests
+ - ITL: ≤ 150ms for 99% of requests
+
+#### 6. Code Completion
+
+**Enterprise Use Case**: An integrated development environment (IDE) plugin for auto-completing code snippets, improving developer efficiency.
+
+- **SLOs**:
+ - Request Latency: ≤ 2s for 99% of requests
+
+### Offline, Batch Use Cases
+
+This category includes use cases where maximizing throughput is the primary concern. These systems process large volumes of data in batches, often during off-peak hours, to optimize resource utilization and cost efficiency.
+
+#### 7. Summarization
+
+**Enterprise Use Case**: A tool for summarizing customer reviews to extract insights for product improvement, processed in large batches overnight.
+
+- **SLOs**:
+ - Maximize Throughput: ≥ 100 requests per second
+
+#### 8. Analysis
+
+**Enterprise Use Case**: A data analysis pipeline for generating actionable insights from sales data, used to inform quarterly business strategies.
+
+- **SLOs**:
+ - Maximize Throughput: ≥ 150 requests per second
+
+## Conclusion
+
+Setting appropriate SLOs and SLAs is essential for optimizing LLM deployments to meet user expectations and business requirements. By balancing latency, throughput, and cost efficiency, organizations can ensure high-quality service while minimizing operational costs. The examples provided above serve as a starting point for defining SLOs and SLAs tailored to specific use cases.
diff --git a/pyproject.toml b/pyproject.toml
index bc352c45..5e27a12b 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -17,7 +17,7 @@ include = ["*"]
[project]
name = "guidellm"
-version = "0.1.0"
+version = "0.2.0"
description = "Guidance platform for deploying and managing large language models."
readme = { file = "README.md", content-type = "text/markdown" }
requires-python = ">=3.9.0,<4.0"
@@ -79,7 +79,6 @@ dev = [
[project.entry-points.console_scripts]
guidellm = "guidellm.__main__:cli"
-guidellm-config = "guidellm.config:print_config"
# ************************************************
diff --git a/src/guidellm/__init__.py b/src/guidellm/__init__.py
index 3bf38f03..237ef1f3 100644
--- a/src/guidellm/__init__.py
+++ b/src/guidellm/__init__.py
@@ -10,9 +10,11 @@
import contextlib
-with open(os.devnull, "w") as devnull, contextlib.redirect_stderr(
- devnull
-), contextlib.redirect_stdout(devnull):
+with (
+ open(os.devnull, "w") as devnull,
+ contextlib.redirect_stderr(devnull),
+ contextlib.redirect_stdout(devnull),
+):
from transformers.utils import logging as hf_logging # type: ignore[import]
# Set the log level for the transformers library to ERROR
diff --git a/src/guidellm/__main__.py b/src/guidellm/__main__.py
index f6b0e3d8..f38b11aa 100644
--- a/src/guidellm/__main__.py
+++ b/src/guidellm/__main__.py
@@ -7,6 +7,7 @@
from guidellm.backend import BackendType
from guidellm.benchmark import ProfileType, benchmark_generative_text
+from guidellm.config import print_config
from guidellm.scheduler import StrategyType
STRATEGY_PROFILE_CHOICES = set(
@@ -42,7 +43,9 @@ def cli():
pass
-@cli.command()
+@cli.command(
+ help="Run a benchmark against a generative model using the specified arguments."
+)
@click.option(
"--target",
required=True,
@@ -277,5 +280,15 @@ def benchmark(
)
+@cli.command(
+ help=(
+ "Print out the available configuration settings that can be set "
+ "through environment variables."
+ )
+)
+def config():
+ print_config()
+
+
if __name__ == "__main__":
cli()
diff --git a/src/guidellm/config.py b/src/guidellm/config.py
index dd5be74b..cfd0dcd5 100644
--- a/src/guidellm/config.py
+++ b/src/guidellm/config.py
@@ -210,7 +210,3 @@ def print_config():
Print the current configuration settings
"""
print(f"Settings: \n{settings.generate_env_file()}") # noqa: T201
-
-
-if __name__ == "__main__":
- print_config()
diff --git a/src/guidellm/scheduler/scheduler.py b/src/guidellm/scheduler/scheduler.py
index b56684de..68dcab21 100644
--- a/src/guidellm/scheduler/scheduler.py
+++ b/src/guidellm/scheduler/scheduler.py
@@ -113,9 +113,12 @@ async def run(
if max_duration is not None and max_duration < 0:
raise ValueError(f"Invalid max_duration: {max_duration}")
- with multiprocessing.Manager() as manager, ProcessPoolExecutor(
- max_workers=scheduling_strategy.processes_limit
- ) as executor:
+ with (
+ multiprocessing.Manager() as manager,
+ ProcessPoolExecutor(
+ max_workers=scheduling_strategy.processes_limit
+ ) as executor,
+ ):
requests_iter: Optional[Iterator[Any]] = None
futures, requests_queue, responses_queue = await self._start_processes(
manager, executor, scheduling_strategy
diff --git a/src/guidellm/utils/text.py b/src/guidellm/utils/text.py
index ee3cb2e7..a735940a 100644
--- a/src/guidellm/utils/text.py
+++ b/src/guidellm/utils/text.py
@@ -150,9 +150,10 @@ def load_text(data: Union[str, Path], encoding: Optional[str] = None) -> str:
# check package data
if isinstance(data, str) and data.startswith("data:"):
resource_path = files(package_data).joinpath(data[5:])
- with as_file(resource_path) as resource_file, gzip.open(
- resource_file, "rt", encoding=encoding
- ) as file:
+ with (
+ as_file(resource_path) as resource_file,
+ gzip.open(resource_file, "rt", encoding=encoding) as file,
+ ):
return file.read()
# check gzipped files
diff --git a/tests/unit/benchmark/test_output.py b/tests/unit/benchmark/test_output.py
index 5089dbb2..9076834b 100644
--- a/tests/unit/benchmark/test_output.py
+++ b/tests/unit/benchmark/test_output.py
@@ -166,9 +166,11 @@ def test_console_print_table():
console = GenerativeBenchmarksConsole(enabled=True)
headers = ["Header1", "Header2"]
rows = [["Row1Col1", "Row1Col2"], ["Row2Col1", "Row2Col2"]]
- with patch.object(console, "print_section_header") as mock_header, patch.object(
- console, "print_table_divider"
- ) as mock_divider, patch.object(console, "print_table_row") as mock_row:
+ with (
+ patch.object(console, "print_section_header") as mock_header,
+ patch.object(console, "print_table_divider") as mock_divider,
+ patch.object(console, "print_table_row") as mock_row,
+ ):
console.print_table(headers, rows, "Test Table")
mock_header.assert_called_once()
mock_divider.assert_called()
@@ -179,9 +181,10 @@ def test_console_print_benchmarks_metadata():
console = GenerativeBenchmarksConsole(enabled=True)
mock_benchmark = mock_generative_benchmark()
console.benchmarks = [mock_benchmark]
- with patch.object(console, "print_section_header") as mock_header, patch.object(
- console, "print_labeled_line"
- ) as mock_labeled:
+ with (
+ patch.object(console, "print_section_header") as mock_header,
+ patch.object(console, "print_labeled_line") as mock_labeled,
+ ):
console.print_benchmarks_metadata()
mock_header.assert_called_once()
mock_labeled.assert_called()