|
9 | 9 | "\n", |
10 | 10 | "## Learning Objectives:\n", |
11 | 11 | "\n", |
12 | | - "- Understand the principles of the Zarr file format\n", |
13 | | - "- Learn how to read and write Zarr files using the `zarr-python` library\n", |
14 | | - "- Explore how to use Zarr files with `xarray` for data analysis and visualization\n", |
| 12 | + "- Understand the principles of the Zarr data format\n", |
| 13 | + "- Learn how to read and write Zarr stores using the `zarr-python` library\n", |
| 14 | + "- Explore how to use Zarr stores with `xarray` for data analysis and visualization\n", |
15 | 15 | "\n", |
16 | 16 | "This notebook provides a brief introduction to Zarr and how to\n", |
17 | 17 | "use it in cloud environments for scalable, chunked, and compressed data storage.\n", |
18 | 18 | "\n", |
19 | | - "Zarr is a file format with implementations in different languages. In this tutorial, we will look at an example of how to use the Zarr format by looking at some features of the `zarr-python` library and how Zarr files can be opened with `xarray`.\n", |
| 19 | + "Zarr is a data format with implementations in different languages. In this tutorial, we will look at an example of how to use the Zarr format by looking at some features of the `zarr-python` library and how Zarr files can be opened with `xarray`.\n", |
20 | 20 | "\n", |
21 | 21 | "## What is Zarr?\n", |
22 | 22 | "\n", |
|
25 | 25 | "### Zarr Data Organization:\n", |
26 | 26 | "- **Arrays**: N-dimensional arrays that can be chunked and compressed.\n", |
27 | 27 | "- **Groups**: A container for organizing multiple arrays and other groups with a hierarchical structure.\n", |
28 | | - "- **Metadata**: JSON-like metadata describing the arrays and groups, including information about dimensions, data types, groups, and compression.\n", |
| 28 | + "- **Metadata**: JSON-like metadata describing the arrays and groups, including information about data types, dimensions, chunking, compression, and user-defined key-value fields. \n", |
29 | 29 | "- **Dimensions and Shape**: Arrays can have any number of dimensions, and their shape is defined by the number of elements in each dimension.\n", |
30 | 30 | "- **Coordinates & Indexing**: Zarr supports coordinate arrays for each dimension, allowing for efficient indexing and slicing.\n", |
31 | 31 | "\n", |
32 | | - "The diagram below from [the NASA Earthdata wiki](https://wiki.earthdata.nasa.gov/display/ESO/Zarr+Format) showing the structure of a Zarr store:\n", |
| 32 | + "The diagram below from [the Zarr v3 specification](https://wiki.earthdata.nasa.gov/display/ESO/Zarr+Format) showing the structure of a Zarr store:\n", |
33 | 33 | "\n", |
34 | | - "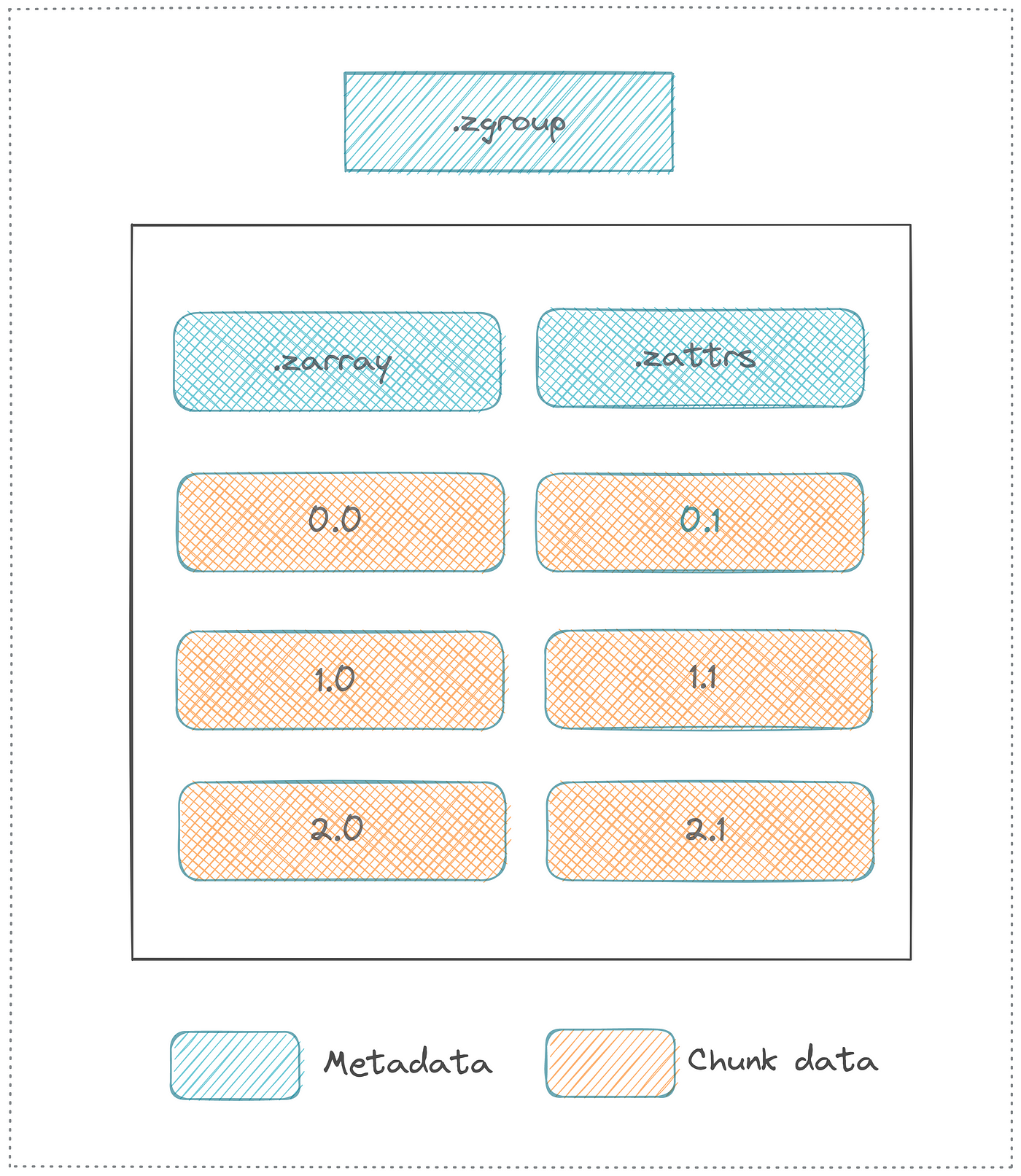\n", |
| 34 | + "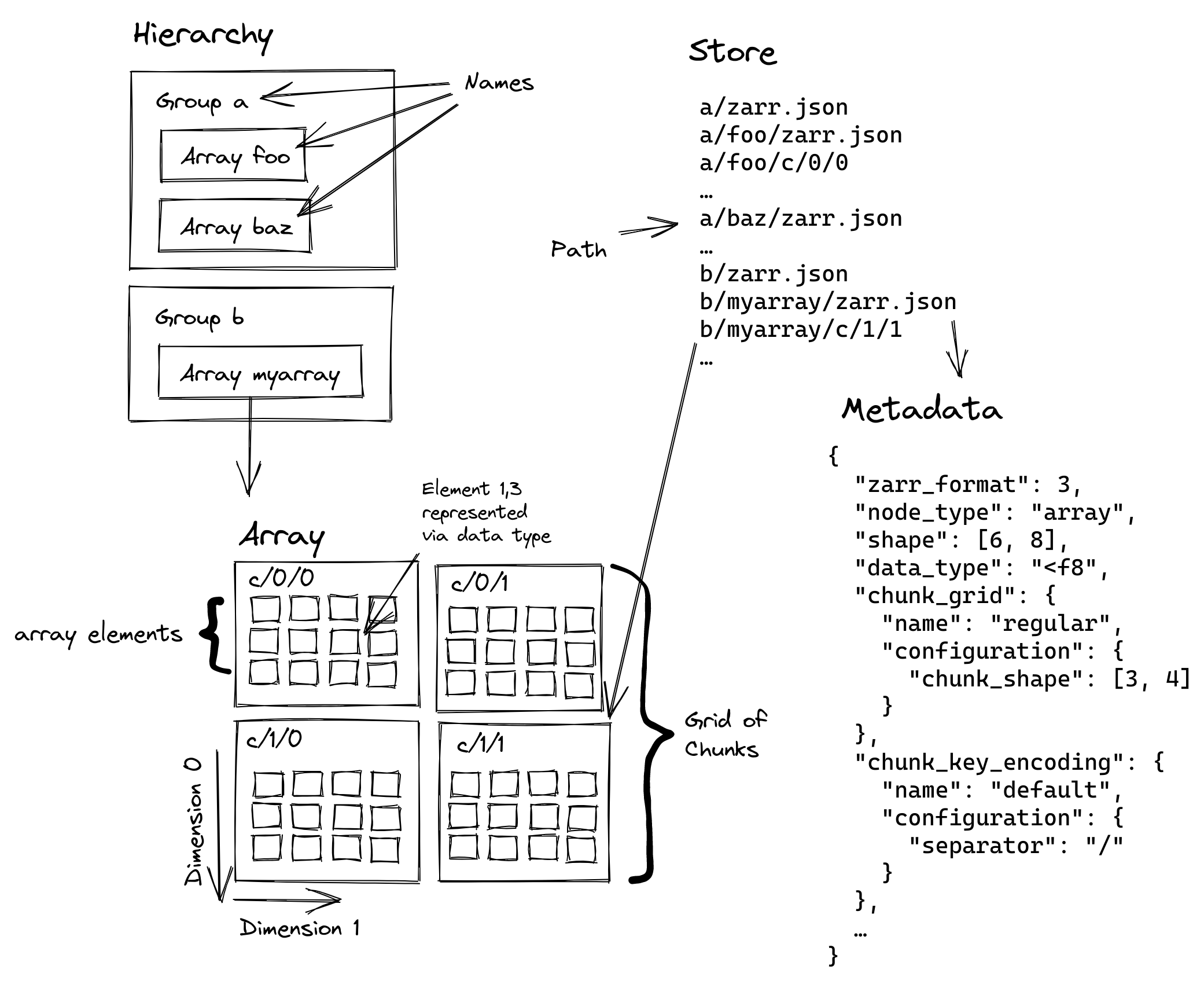\n", |
35 | 35 | "\n", |
36 | 36 | "\n", |
37 | | - "NetCDF and Zarr share similar terminology and functionality, but the key difference is that NetCDF is a single file, while Zarr is a directory-based “store” composed of many chunked files—making it better suited for distributed and cloud-based workflows.\n", |
38 | | - "\n" |
| 37 | + "NetCDF and Zarr share similar terminology and functionality, but the key difference is that NetCDF is a single file, while Zarr is a directory-based “store” composed of many chunked files, making it better suited for distributed and cloud-based workflows." |
39 | 38 | ] |
40 | 39 | }, |
41 | 40 | { |
|
69 | 68 | "source": [ |
70 | 69 | "import zarr\n", |
71 | 70 | "\n", |
72 | | - "z = zarr.create(shape=(40, 50), chunks=(10, 10), dtype='f8', store='test.zarr', mode='w')\n", |
| 71 | + "z = zarr.create_array(shape=(40, 50), chunks=(10, 10), dtype='f8', store='test.zarr')\n", |
73 | 72 | "z" |
74 | 73 | ] |
75 | 74 | }, |
|
228 | 227 | "metadata": {}, |
229 | 228 | "outputs": [], |
230 | 229 | "source": [ |
231 | | - "root = zarr.group()\n", |
| 230 | + "store = zarr.storage.MemoryStore()\n", |
| 231 | + "root = zarr.create_group(store=store)\n", |
232 | 232 | "temp = root.create_group('temp')\n", |
233 | 233 | "precip = root.create_group('precip')\n", |
234 | 234 | "t2m = temp.create_array('t2m', shape=(100, 100), chunks=(10, 10), dtype='i4')\n", |
235 | | - "prcp = precip.create_array('prcp', shape=(1000, 1000), chunks=(10, 10), dtype='i4')" |
| 235 | + "prcp = precip.create_array('prcp', shape=(1000, 1000), chunks=(10, 10), dtype='i4')\n", |
| 236 | + "root.tree()" |
236 | 237 | ] |
237 | 238 | }, |
238 | 239 | { |
|
251 | 252 | "metadata": {}, |
252 | 253 | "outputs": [], |
253 | 254 | "source": [ |
254 | | - "root['temp']\n", |
| 255 | + "display(root['temp'])\n", |
255 | 256 | "root['temp/t2m'][:, 3]" |
256 | 257 | ] |
257 | 258 | }, |
|
281 | 282 | "metadata": {}, |
282 | 283 | "outputs": [], |
283 | 284 | "source": [ |
284 | | - "root.tree(expand=True)" |
| 285 | + "root.tree()" |
285 | 286 | ] |
286 | 287 | }, |
287 | 288 | { |
|
290 | 291 | "metadata": {}, |
291 | 292 | "source": [ |
292 | 293 | "#### Chunking\n", |
293 | | - "Chunking is the process of dividing the data arrays into smaller pieces. This allows for parallel processing and efficient storage.\n", |
| 294 | + "Chunking is the process of dividing Zarr arrays into smaller pieces. This allows for parallel processing and efficient storage.\n", |
294 | 295 | "\n", |
295 | 296 | "One of the important parameters in Zarr is the chunk shape, which determines how the data is divided into smaller, manageable pieces. This is crucial for performance, especially when working with large datasets.\n", |
296 | 297 | "\n", |
|
329 | 330 | "metadata": {}, |
330 | 331 | "outputs": [], |
331 | 332 | "source": [ |
332 | | - "c = zarr.create(shape=(200, 200, 200), chunks=(1, 200, 200), dtype='f8', store='c.zarr')\n", |
| 333 | + "c = zarr.create_array(shape=(200, 200, 200), chunks=(1, 200, 200), dtype='f8', store='c.zarr')\n", |
333 | 334 | "c[:] = np.random.randn(*c.shape)" |
334 | 335 | ] |
335 | 336 | }, |
|
350 | 351 | "metadata": {}, |
351 | 352 | "outputs": [], |
352 | 353 | "source": [ |
353 | | - "d = zarr.create(shape=(200, 200, 200), chunks=(200, 200, 1), dtype='f8', store='d.zarr')\n", |
| 354 | + "d = zarr.create_array(shape=(200, 200, 200), chunks=(200, 200, 1), dtype='f8', store='d.zarr')\n", |
354 | 355 | "d[:] = np.random.randn(*d.shape)" |
355 | 356 | ] |
356 | 357 | }, |
|
377 | 378 | "- File systems struggle with too many small files.\n", |
378 | 379 | "- Small files (e.g., 1 MB or less) may waste space due to filesystem block size.\n", |
379 | 380 | "- Object storage systems (e.g., S3) can slow down with a high number of objects.\n", |
| 381 | + "\n", |
380 | 382 | "With sharding, you choose:\n", |
381 | | - "\n" |
| 383 | + "- Shard size: the logical shape of each shard, which is expected to include one or more chunks\n", |
| 384 | + "- Chunk size: the shape of each compressed chunk\n", |
| 385 | + "\n", |
| 386 | + "It is important to remember that the shard is the minimum unit of writing. This means that writers must be able to fit the entire shard (including all of the compressed chunks) in memory before writing a shard to a store.\n" |
382 | 387 | ] |
383 | 388 | }, |
384 | 389 | { |
|
526 | 531 | "metadata": {}, |
527 | 532 | "outputs": [], |
528 | 533 | "source": [ |
| 534 | + "from pprint import pprint\n", |
| 535 | + "\n", |
529 | 536 | "consolidated = zarr.open_group(store=store)\n", |
530 | 537 | "consolidated_metadata = consolidated.metadata.consolidated_metadata.metadata\n", |
531 | | - "from pprint import pprint\n", |
532 | 538 | "\n", |
533 | 539 | "pprint(dict(sorted(consolidated_metadata.items())))" |
534 | 540 | ] |
535 | 541 | }, |
| 542 | + { |
| 543 | + "cell_type": "markdown", |
| 544 | + "id": "a571acec-7a65-4a51-ad1e-c80b17494cd3", |
| 545 | + "metadata": {}, |
| 546 | + "source": [ |
| 547 | + "Note that while Zarr-Python supports consolidated metadata for v2 and v3 formatted Zarr stores, it is not technically part of the specification (hence the warning above). \n", |
| 548 | + "\n", |
| 549 | + "⚠️ Use Caution When ⚠️\n", |
| 550 | + "- **Stale or incomplete consolidated metadata**: If the dataset is updated but the consolidated metadata entrypoint isn't re-consolidated, readers may miss chunks or metadata. Always run zarr.consolidate_metadata() after changes.\n", |
| 551 | + "- **Concurrent writes or multi-writer pipelines**: Consolidated metadata can lead to inconsistent reads if multiple processes write without coordination. Use with caution in dynamic or shared write environments.\n", |
| 552 | + "- **Local filesystems or mixed toolchains**: On local storage, consolidation offers little benefit as hierarchy discovery is generally quite cheap. " |
| 553 | + ] |
| 554 | + }, |
536 | 555 | { |
537 | 556 | "cell_type": "markdown", |
538 | 557 | "id": "46", |
|
575 | 594 | "metadata": {}, |
576 | 595 | "outputs": [], |
577 | 596 | "source": [ |
| 597 | + "import xarray as xr\n", |
| 598 | + "\n", |
578 | 599 | "store = 'https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/gpcp-feedstock/gpcp.zarr'\n", |
579 | 600 | "\n", |
580 | 601 | "ds = xr.open_dataset(store, engine='zarr', chunks={}, consolidated=True)\n", |
|
599 | 620 | "::::{admonition} Exercise\n", |
600 | 621 | ":class: tip\n", |
601 | 622 | "\n", |
602 | | - "Can you calculate the mean precipitation over the time dimension in the GPCP dataset and plot it?\n", |
| 623 | + "Can you calculate the mean precipitation for January 2020 in the GPCP dataset and plot it?\n", |
603 | 624 | "\n", |
604 | 625 | ":::{admonition} Solution\n", |
605 | 626 | ":class: dropdown\n", |
606 | 627 | "\n", |
607 | 628 | "```python\n", |
608 | | - "ds.precip.mean(dim='time').plot()\n", |
609 | | - "\n", |
| 629 | + "ds.precip.sel(time=slice('2020-01-01', '2020-01-31')).mean(dim='time').plot()\n", |
610 | 630 | "```\n", |
611 | 631 | ":::\n", |
612 | 632 | "::::" |
|
628 | 648 | ] |
629 | 649 | }, |
630 | 650 | { |
631 | | - "cell_type": "markdown", |
632 | | - "id": "53", |
| 651 | + "cell_type": "code", |
| 652 | + "execution_count": null, |
| 653 | + "id": "09c50842-b522-4f3f-b04a-da22f9131b86", |
633 | 654 | "metadata": {}, |
| 655 | + "outputs": [], |
634 | 656 | "source": [] |
635 | 657 | } |
636 | 658 | ], |
637 | 659 | "metadata": { |
| 660 | + "kernelspec": { |
| 661 | + "display_name": "Python 3 (ipykernel)", |
| 662 | + "language": "python", |
| 663 | + "name": "python3" |
| 664 | + }, |
638 | 665 | "language_info": { |
639 | 666 | "codemirror_mode": { |
640 | 667 | "name": "ipython", |
|
644 | 671 | "mimetype": "text/x-python", |
645 | 672 | "name": "python", |
646 | 673 | "nbconvert_exporter": "python", |
647 | | - "pygments_lexer": "ipython3" |
| 674 | + "pygments_lexer": "ipython3", |
| 675 | + "version": "3.12.11" |
648 | 676 | } |
649 | 677 | }, |
650 | 678 | "nbformat": 4, |
|
0 commit comments