diff --git a/_toc.yml b/_toc.yml
index b8cfb204..fbf8c3d2 100644
--- a/_toc.yml
+++ b/_toc.yml
@@ -44,6 +44,7 @@ parts:
- file: intermediate/indexing/boolean-masking-indexing.ipynb
- file: intermediate/hierarchical_computation.ipynb
- file: intermediate/xarray_and_dask
+ - file: intermediate/intro-to-zarr.ipynb
- file: intermediate/xarray_ecosystem
- file: intermediate/hvplot
- file: intermediate/remote_data/index
diff --git a/fundamentals/01.1_io.ipynb b/fundamentals/01.1_io.ipynb
index f5328c4c..317c961c 100644
--- a/fundamentals/01.1_io.ipynb
+++ b/fundamentals/01.1_io.ipynb
@@ -51,9 +51,27 @@
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"id": "2",
"metadata": {},
+ "outputs": [],
+ "source": [
+ "# Ensure we start with a clean directory for the tutorial\n",
+ "import pathlib\n",
+ "import shutil\n",
+ "\n",
+ "datadir = pathlib.Path('../data/io-tutorial')\n",
+ "if datadir.exists():\n",
+ " shutil.rmtree(datadir)\n",
+ "else:\n",
+ " datadir.mkdir()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3",
+ "metadata": {},
"source": [
"The constructor of `Dataset` takes three parameters:\n",
"\n",
@@ -66,7 +84,7 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "3",
+ "id": "4",
"metadata": {},
"outputs": [],
"source": [
@@ -94,16 +112,16 @@
")\n",
"\n",
"# write datasets\n",
- "ds1.to_netcdf(\"ds1.nc\")\n",
- "ds2.to_netcdf(\"ds2.nc\")\n",
+ "ds1.to_netcdf(datadir / \"ds1.nc\")\n",
+ "ds2.to_netcdf(datadir / \"ds2.nc\")\n",
"\n",
"# write dataarray\n",
- "ds1.a.to_netcdf(\"da1.nc\")"
+ "ds1.a.to_netcdf(datadir / \"da1.nc\")"
]
},
{
"cell_type": "markdown",
- "id": "4",
+ "id": "5",
"metadata": {},
"source": [
"Reading those files is just as simple:\n"
@@ -112,26 +130,26 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "5",
+ "id": "6",
"metadata": {},
"outputs": [],
"source": [
- "xr.open_dataset(\"ds1.nc\")"
+ "xr.open_dataset(datadir / \"ds1.nc\")"
]
},
{
"cell_type": "code",
"execution_count": null,
- "id": "6",
+ "id": "7",
"metadata": {},
"outputs": [],
"source": [
- "xr.open_dataarray(\"da1.nc\")"
+ "xr.open_dataarray(datadir / \"da1.nc\")"
]
},
{
"cell_type": "markdown",
- "id": "7",
+ "id": "8",
"metadata": {},
"source": [
" \n",
@@ -151,16 +169,16 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "8",
+ "id": "9",
"metadata": {},
"outputs": [],
"source": [
- "ds1.to_zarr(\"ds1.zarr\", mode=\"w\")"
+ "ds1.to_zarr(datadir / \"ds1.zarr\", mode=\"w\")"
]
},
{
"cell_type": "markdown",
- "id": "9",
+ "id": "10",
"metadata": {},
"source": [
"We can then read the created file with:\n"
@@ -169,16 +187,16 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "10",
+ "id": "11",
"metadata": {},
"outputs": [],
"source": [
- "xr.open_zarr(\"ds1.zarr\", chunks=None)"
+ "xr.open_zarr(datadir / \"ds1.zarr\", chunks=None)"
]
},
{
"cell_type": "markdown",
- "id": "11",
+ "id": "12",
"metadata": {},
"source": [
"setting the `chunks` parameter to `None` avoids `dask` (more on that in a later\n",
@@ -187,7 +205,7 @@
},
{
"cell_type": "markdown",
- "id": "12",
+ "id": "13",
"metadata": {},
"source": [
"**tip:** You can write to any dictionary-like (`MutableMapping`) interface:"
@@ -196,7 +214,7 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "13",
+ "id": "14",
"metadata": {},
"outputs": [],
"source": [
@@ -207,7 +225,7 @@
},
{
"cell_type": "markdown",
- "id": "14",
+ "id": "15",
"metadata": {},
"source": [
"## Raster files using rioxarray\n",
@@ -220,7 +238,7 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "15",
+ "id": "16",
"metadata": {},
"outputs": [],
"source": [
@@ -241,16 +259,16 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "16",
+ "id": "17",
"metadata": {},
"outputs": [],
"source": [
- "da.rio.to_raster('ds1_a.tiff')"
+ "da.rio.to_raster(datadir / 'ds1_a.tiff')"
]
},
{
"cell_type": "markdown",
- "id": "17",
+ "id": "18",
"metadata": {},
"source": [
"NOTE: you can now load this file into GIS tools like [QGIS](https://www.qgis.org)! Or open back into Xarray:"
@@ -259,11 +277,11 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "18",
+ "id": "19",
"metadata": {},
"outputs": [],
"source": [
- "DA = xr.open_dataarray('ds1_a.tiff', engine='rasterio')\n",
+ "DA = xr.open_dataarray(datadir / 'ds1_a.tiff', engine='rasterio')\n",
"DA.rio.crs"
]
}
@@ -279,11 +297,6 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3"
- },
- "vscode": {
- "interpreter": {
- "hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
- }
}
},
"nbformat": 4,
diff --git a/intermediate/intro-to-zarr.ipynb b/intermediate/intro-to-zarr.ipynb
new file mode 100644
index 00000000..e991cf4f
--- /dev/null
+++ b/intermediate/intro-to-zarr.ipynb
@@ -0,0 +1,686 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "0",
+ "metadata": {},
+ "source": [
+ "# Introduction to Zarr\n",
+ "\n",
+ "## Learning Objectives:\n",
+ "\n",
+ "- Understand the principles of the Zarr data format\n",
+ "- Learn how to read and write Zarr stores using the `zarr-python` library\n",
+ "- Explore how to use Zarr stores with `xarray` for data analysis and visualization\n",
+ "\n",
+ "This notebook provides a brief introduction to Zarr and how to\n",
+ "use it in cloud environments for scalable, chunked, and compressed data storage.\n",
+ "\n",
+ "Zarr is a data format with implementations in different languages. In this tutorial, we will look at an example of how to use the Zarr format by looking at some features of the `zarr-python` library and how Zarr files can be opened with `xarray`.\n",
+ "\n",
+ "## What is Zarr?\n",
+ "\n",
+ "The Zarr data format is an open, community-maintained format designed for efficient, scalable storage of large N-dimensional arrays. It stores data as compressed and chunked arrays in a format well-suited to parallel processing and cloud-native workflows. \n",
+ "\n",
+ "### Zarr Data Organization:\n",
+ "- **Arrays**: N-dimensional arrays that can be chunked and compressed.\n",
+ "- **Groups**: A container for organizing multiple arrays and other groups with a hierarchical structure.\n",
+ "- **Metadata**: JSON-like metadata describing the arrays and groups, including information about data types, dimensions, chunking, compression, and user-defined key-value fields. \n",
+ "- **Dimensions and Shape**: Arrays can have any number of dimensions, and their shape is defined by the number of elements in each dimension.\n",
+ "- **Coordinates & Indexing**: Zarr supports coordinate arrays for each dimension, allowing for efficient indexing and slicing.\n",
+ "\n",
+ "The diagram below from [the Zarr v3 specification](https://wiki.earthdata.nasa.gov/display/ESO/Zarr+Format) showing the structure of a Zarr store:\n",
+ "\n",
+ "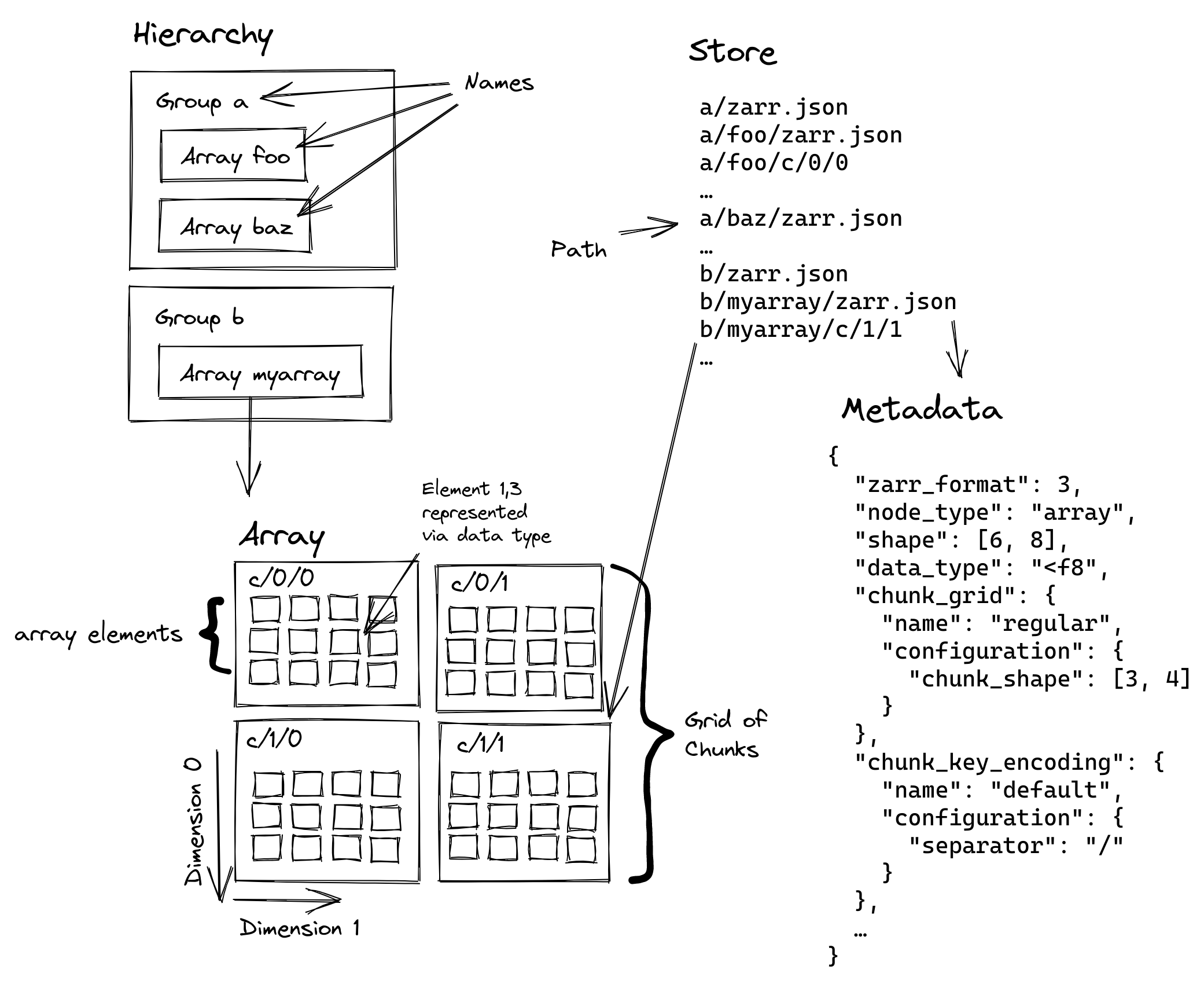\n",
+ "\n",
+ "\n",
+ "NetCDF and Zarr share similar terminology and functionality, but the key difference is that NetCDF is a single file, while Zarr is a directory-based “store” composed of many chunked files, making it better suited for distributed and cloud-based workflows."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### Zarr Fundamenals\n",
+ "A Zarr array has the following important properties:\n",
+ "- **Shape**: The dimensions of the array.\n",
+ "- **Dtype**: The data type of each element (e.g., float32).\n",
+ "- **Attributes**: Metadata stored as key-value pairs (e.g., units, description.\n",
+ "- **Compressors**: Algorithms used to compress each chunk (e.g., Zstd, Blosc, Zlib).\n",
+ "\n",
+ "\n",
+ "#### Example: Creating and Inspecting a Zarr Array\n",
+ "\n",
+ "Here we create a simple 2D array of shape `(40, 50)` with chunks of size `(10, 10)` ,write to the `LocalStore` in the `test.zarr` directory. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import zarr\n",
+ "import pathlib\n",
+ "import shutil\n",
+ "\n",
+ "# Ensure we start with a clean directory for the tutorial\n",
+ "datadir = pathlib.Path('../data/zarr-tutorial')\n",
+ "if datadir.exists():\n",
+ " shutil.rmtree(datadir)\n",
+ "\n",
+ "output = datadir / 'test.zarr'\n",
+ "z = zarr.create_array(shape=(40, 50), chunks=(10, 10), dtype='f8', store=output)\n",
+ "z"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3",
+ "metadata": {},
+ "source": [
+ "`.info` provides a summary of the array's properties, including shape, data type, and compression settings.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.info"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.fill_value"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6",
+ "metadata": {},
+ "source": [
+ "No data has been written to the array yet. If we try to access the data, we will get a fill value: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z[0, 0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8",
+ "metadata": {},
+ "source": [
+ "This is how we assign data to the array. When we do this it gets written immediately."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "z[:] = 1\n",
+ "z[0, :] = np.arange(50)\n",
+ "z[:]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10",
+ "metadata": {},
+ "source": [
+ "#### Attributes\n",
+ "\n",
+ "We can attach arbitrary metadata to our Array via attributes:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "11",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.attrs['units'] = 'm/s'\n",
+ "z.attrs['standard_name'] = 'wind_speed'\n",
+ "print(dict(z.attrs))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "12",
+ "metadata": {},
+ "source": [
+ "### Zarr Data Storage\n",
+ "\n",
+ "Zarr can be stored in memory, on disk, or in cloud storage systems like Amazon S3.\n",
+ "\n",
+ "Let's look under the hood. _The ability to look inside a Zarr store and understand what is there is a deliberate design decision._"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.store"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14",
+ "metadata": {
+ "tags": [
+ "hide-output"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "!tree -a {output}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "15",
+ "metadata": {
+ "tags": [
+ "hide-output"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "!cat {output}/zarr.json"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "16",
+ "metadata": {},
+ "source": [
+ "### Hierarchical Groups"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17",
+ "metadata": {},
+ "source": [
+ "Zarr allows you to create hierarchical groups, similar to directories. To create groups in your store, use the `create_group` method after creating a root group. Here, we’ll create two groups, `temp` and `precip`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "store = zarr.storage.MemoryStore()\n",
+ "root = zarr.create_group(store=store)\n",
+ "temp = root.create_group('temp')\n",
+ "precip = root.create_group('precip')\n",
+ "t2m = temp.create_array('t2m', shape=(100, 100), chunks=(10, 10), dtype='i4')\n",
+ "prcp = precip.create_array('prcp', shape=(1000, 1000), chunks=(10, 10), dtype='i4')\n",
+ "root.tree()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "19",
+ "metadata": {},
+ "source": [
+ "Groups can easily be accessed by name and index.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "20",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "display(root['temp'])\n",
+ "root['temp/t2m'][:, 3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "21",
+ "metadata": {},
+ "source": [
+ "To get a look at your overall dataset, the `tree` and `info` methods are helpful.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "22",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "root.info"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "23",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "root.tree()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "24",
+ "metadata": {},
+ "source": [
+ "#### Chunking\n",
+ "Chunking is the process of dividing Zarr arrays into smaller pieces. This allows for parallel processing and efficient storage.\n",
+ "\n",
+ "One of the important parameters in Zarr is the chunk shape, which determines how the data is divided into smaller, manageable pieces. This is crucial for performance, especially when working with large datasets.\n",
+ "\n",
+ "To examine the chunk shape of a Zarr array, you can use the `chunks` attribute. This will show you the size of each chunk in each dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "25",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.chunks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "26",
+ "metadata": {},
+ "source": [
+ "When selecting chunk shapes, we need to keep in mind two constraints:\n",
+ "\n",
+ "- Concurrent writes are possible as long as different processes write to separate chunks, enabling highly parallel data writing. \n",
+ "- When reading data, if any piece of the chunk is needed, the entire chunk has to be loaded. \n",
+ "\n",
+ "The optimal chunk shape will depend on how you want to access the data. E.g., for a 2-dimensional array, if you only ever take slices along the first dimension, then chunk across the second dimension.\n",
+ "\n",
+ "Here we will compare two different chunking strategies.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "27",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = datadir / 'c.zarr'\n",
+ "c = zarr.create_array(shape=(200, 200, 200), chunks=(1, 200, 200), dtype='f8', store=output)\n",
+ "c[:] = np.random.randn(*c.shape)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%time _ = c[:, 0, 0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = datadir / 'd.zarr'\n",
+ "d = zarr.create_array(shape=(200, 200, 200), chunks=(200, 200, 1), dtype='f8', store=output)\n",
+ "d[:] = np.random.randn(*d.shape)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "30",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%time _ = d[:, 0, 0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "31",
+ "metadata": {},
+ "source": [
+ "### Sharding\n",
+ "When working with large arrays and small chunks, Zarr’s sharding feature can improve storage efficiency and performance. Instead of writing each chunk to a separate file—which can overwhelm file systems and cloud object stores—sharding groups multiple chunks into a single storage object.\n",
+ "\n",
+ "Why Use Sharding?\n",
+ "\n",
+ "- File systems struggle with too many small files.\n",
+ "- Small files (e.g., 1 MB or less) may waste space due to filesystem block size.\n",
+ "- Object storage systems (e.g., S3) can slow down with a high number of objects.\n",
+ "\n",
+ "With sharding, you choose:\n",
+ "- Shard size: the logical shape of each shard, which is expected to include one or more chunks\n",
+ "- Chunk size: the shape of each compressed chunk\n",
+ "\n",
+ "It is important to remember that the shard is the minimum unit of writing. This means that writers must be able to fit the entire shard (including all of the compressed chunks) in memory before writing a shard to a store.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32",
+ "metadata": {},
+ "source": [
+ "This example shows how to create a sharded Zarr array with a chunk size of `(100, 100, 100)` and a shard size of `(1000, 1000, 1000)`. This means that each shard will contain 10 chunks, and each chunk will be of size `(100, 100, 100)`.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z6 = zarr.create_array(\n",
+ " store={},\n",
+ " shape=(10000, 10000, 1000),\n",
+ " chunks=(100, 100, 100),\n",
+ " shards=(1000, 1000, 1000),\n",
+ " dtype='uint8',\n",
+ ")\n",
+ "\n",
+ "z6.info"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34",
+ "metadata": {},
+ "source": [
+ "\n",
+ "```{tip}\n",
+ "Choose shard and chunk sizes that balance I/O performance and manageability for your filesystem or cloud backend.\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "35",
+ "metadata": {},
+ "source": [
+ "#### Compressors\n",
+ "A number of different compressors can be used with Zarr. The built-in options include Blosc, Zstandard, and Gzip. Additional compressors are available through the [NumCodecs](https://numcodecs.readthedocs.io) package, which supports LZ4, Zlib, BZ2, and LZMA. \n",
+ "\n",
+ "Let's check the compressor we used when creating the array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.compressors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37",
+ "metadata": {},
+ "source": [
+ "If you don’t specify a compressor, by default Zarr uses the Zstandard compressor."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "38",
+ "metadata": {},
+ "source": [
+ "How much space was saved by compression?\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "39",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.info_complete()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "40",
+ "metadata": {},
+ "source": [
+ "You can set `compression=None` when creating a Zarr array to turn off compression. This is useful for debugging or when you want to store data without compression."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41",
+ "metadata": {},
+ "source": [
+ "```{note}\n",
+ "`.info_complete()` provides a more detailed view of the Zarr array, including metadata about the chunks, compressors, and attributes, but will be slower for larger arrays. \n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "42",
+ "metadata": {},
+ "source": [
+ "#### Consolidated Metadata\n",
+ "Zarr supports consolidated metadata, which allows you to store all metadata in a single file. This can improve performance when reading metadata, especially for large datasets.\n",
+ "\n",
+ "So far we have only been dealing in single array Zarr data stores. In this next example, we will create a zarr store with multiple arrays and then consolidate metadata. The speed up is significant when dealing in remote storage options, which we will see in the following example on accessing cloud storage."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "43",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "store = zarr.storage.MemoryStore()\n",
+ "group = zarr.create_group(store=store)\n",
+ "group.create_array(shape=(1,), name='a', dtype='float64')\n",
+ "group.create_array(shape=(2, 2), name='b', dtype='float64')\n",
+ "group.create_array(shape=(3, 3, 3), name='c', dtype='float64')\n",
+ "zarr.consolidate_metadata(store)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "44",
+ "metadata": {},
+ "source": [
+ "Now, if we open that group, the Group’s metadata has a zarr.core.group.ConsolidatedMetadata that can be used:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "45",
+ "metadata": {
+ "tags": [
+ "hide-output"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from pprint import pprint\n",
+ "\n",
+ "consolidated = zarr.open_group(store=store)\n",
+ "consolidated_metadata = consolidated.metadata.consolidated_metadata.metadata\n",
+ "\n",
+ "pprint(dict(sorted(consolidated_metadata.items())))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "46",
+ "metadata": {},
+ "source": [
+ "Note that while Zarr-Python supports consolidated metadata for v2 and v3 formatted Zarr stores, it is not technically part of the specification (hence the warning above). \n",
+ "\n",
+ "⚠️ Use Caution When ⚠️\n",
+ "- **Stale or incomplete consolidated metadata**: If the dataset is updated but the consolidated metadata entrypoint isn't re-consolidated, readers may miss chunks or metadata. Always run zarr.consolidate_metadata() after changes.\n",
+ "- **Concurrent writes or multi-writer pipelines**: Consolidated metadata can lead to inconsistent reads if multiple processes write without coordination. Use with caution in dynamic or shared write environments.\n",
+ "- **Local filesystems or mixed toolchains**: On local storage, consolidation offers little benefit as hierarchy discovery is generally quite cheap. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "47",
+ "metadata": {},
+ "source": [
+ "### Object Storage as a Zarr Store\n",
+ "\n",
+ "Zarr’s layout (many files/chunks per array) maps perfectly onto object storage, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage. Each chunk is stored as a separate object, enabling distributed reads/writes.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "48",
+ "metadata": {},
+ "source": [
+ "Here are some examples of Zarr stores on the cloud:\n",
+ "\n",
+ "* [Zarr data in Microsoft's Planetary Computer](https://planetarycomputer.microsoft.com/catalog?filter=zarr)\n",
+ "* [Zarr data from Google](https://console.cloud.google.com/marketplace/browse?filter=solution-type:dataset&_ga=2.226354714.1000882083.1692116148-1788942020.1692116148&pli=1&q=zarr)\n",
+ "* [Amazon Sustainability Data Initiative available from Registry of Open Data on AWS](https://registry.opendata.aws/collab/asdi/) - Enter \"Zarr\" in the Search input box.\n",
+ "* [Pangeo-Forge Data Catalog](https://pangeo-forge.org/catalog)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "49",
+ "metadata": {},
+ "source": [
+ "### Xarray and Zarr\n",
+ "\n",
+ "Xarray has built-in support for reading and writing Zarr data. You can use the `xarray.open_zarr()` function to open a Zarr store as an Xarray dataset.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "50",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import xarray as xr\n",
+ "\n",
+ "store = 'https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/gpcp-feedstock/gpcp.zarr'\n",
+ "\n",
+ "ds = xr.open_dataset(store, engine='zarr', chunks={}, consolidated=True)\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "51",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.precip"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "52",
+ "metadata": {},
+ "source": [
+ "::::{admonition} Exercise\n",
+ ":class: tip\n",
+ "\n",
+ "Can you calculate the mean precipitation for January 2020 in the GPCP dataset and plot it?\n",
+ "\n",
+ ":::{admonition} Solution\n",
+ ":class: dropdown\n",
+ "\n",
+ "```python\n",
+ "ds.precip.sel(time=slice('2020-01-01', '2020-01-31')).mean(dim='time').plot()\n",
+ "```\n",
+ ":::\n",
+ "::::"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "53",
+ "metadata": {},
+ "source": [
+ "Check out our other [tutorial notebook]() that highlights the CMIP6 Zarr dataset stored in the Cloud\n",
+ "\n",
+ "## Additional Resources\n",
+ "\n",
+ "- [Zarr Documentation](https://zarr.readthedocs.io/en/stable/)\n",
+ "- [Cloud Optimized Geospatial Formats](https://guide.cloudnativegeo.org/zarr/zarr-in-practice.html)\n",
+ "- [Scalable and Computationally Reproducible Approaches to Arctic Research](https://learning.nceas.ucsb.edu/2025-04-arctic/sections/zarr.html)\n",
+ "- [Zarr Cloud Native Geospatial Tutorial](https://github.com/zarr-developers/tutorials/blob/main/zarr_cloud_native_geospatial_2022.ipynb)"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/intermediate/remote_data/cmip6-cloud.ipynb b/intermediate/remote_data/cmip6-cloud.ipynb
index e93eabf6..fa27ff7f 100644
--- a/intermediate/remote_data/cmip6-cloud.ipynb
+++ b/intermediate/remote_data/cmip6-cloud.ipynb
@@ -5,6 +5,7 @@
"id": "0",
"metadata": {},
"source": [
+ "(cmip6-cloud)=\n",
"# Zarr in Cloud Object Storage\n",
"\n",
"In this tutorial, we'll cover the following:\n",
\n",
@@ -151,16 +169,16 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "8",
+ "id": "9",
"metadata": {},
"outputs": [],
"source": [
- "ds1.to_zarr(\"ds1.zarr\", mode=\"w\")"
+ "ds1.to_zarr(datadir / \"ds1.zarr\", mode=\"w\")"
]
},
{
"cell_type": "markdown",
- "id": "9",
+ "id": "10",
"metadata": {},
"source": [
"We can then read the created file with:\n"
@@ -169,16 +187,16 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "10",
+ "id": "11",
"metadata": {},
"outputs": [],
"source": [
- "xr.open_zarr(\"ds1.zarr\", chunks=None)"
+ "xr.open_zarr(datadir / \"ds1.zarr\", chunks=None)"
]
},
{
"cell_type": "markdown",
- "id": "11",
+ "id": "12",
"metadata": {},
"source": [
"setting the `chunks` parameter to `None` avoids `dask` (more on that in a later\n",
@@ -187,7 +205,7 @@
},
{
"cell_type": "markdown",
- "id": "12",
+ "id": "13",
"metadata": {},
"source": [
"**tip:** You can write to any dictionary-like (`MutableMapping`) interface:"
@@ -196,7 +214,7 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "13",
+ "id": "14",
"metadata": {},
"outputs": [],
"source": [
@@ -207,7 +225,7 @@
},
{
"cell_type": "markdown",
- "id": "14",
+ "id": "15",
"metadata": {},
"source": [
"## Raster files using rioxarray\n",
@@ -220,7 +238,7 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "15",
+ "id": "16",
"metadata": {},
"outputs": [],
"source": [
@@ -241,16 +259,16 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "16",
+ "id": "17",
"metadata": {},
"outputs": [],
"source": [
- "da.rio.to_raster('ds1_a.tiff')"
+ "da.rio.to_raster(datadir / 'ds1_a.tiff')"
]
},
{
"cell_type": "markdown",
- "id": "17",
+ "id": "18",
"metadata": {},
"source": [
"NOTE: you can now load this file into GIS tools like [QGIS](https://www.qgis.org)! Or open back into Xarray:"
@@ -259,11 +277,11 @@
{
"cell_type": "code",
"execution_count": null,
- "id": "18",
+ "id": "19",
"metadata": {},
"outputs": [],
"source": [
- "DA = xr.open_dataarray('ds1_a.tiff', engine='rasterio')\n",
+ "DA = xr.open_dataarray(datadir / 'ds1_a.tiff', engine='rasterio')\n",
"DA.rio.crs"
]
}
@@ -279,11 +297,6 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3"
- },
- "vscode": {
- "interpreter": {
- "hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
- }
}
},
"nbformat": 4,
diff --git a/intermediate/intro-to-zarr.ipynb b/intermediate/intro-to-zarr.ipynb
new file mode 100644
index 00000000..e991cf4f
--- /dev/null
+++ b/intermediate/intro-to-zarr.ipynb
@@ -0,0 +1,686 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "0",
+ "metadata": {},
+ "source": [
+ "# Introduction to Zarr\n",
+ "\n",
+ "## Learning Objectives:\n",
+ "\n",
+ "- Understand the principles of the Zarr data format\n",
+ "- Learn how to read and write Zarr stores using the `zarr-python` library\n",
+ "- Explore how to use Zarr stores with `xarray` for data analysis and visualization\n",
+ "\n",
+ "This notebook provides a brief introduction to Zarr and how to\n",
+ "use it in cloud environments for scalable, chunked, and compressed data storage.\n",
+ "\n",
+ "Zarr is a data format with implementations in different languages. In this tutorial, we will look at an example of how to use the Zarr format by looking at some features of the `zarr-python` library and how Zarr files can be opened with `xarray`.\n",
+ "\n",
+ "## What is Zarr?\n",
+ "\n",
+ "The Zarr data format is an open, community-maintained format designed for efficient, scalable storage of large N-dimensional arrays. It stores data as compressed and chunked arrays in a format well-suited to parallel processing and cloud-native workflows. \n",
+ "\n",
+ "### Zarr Data Organization:\n",
+ "- **Arrays**: N-dimensional arrays that can be chunked and compressed.\n",
+ "- **Groups**: A container for organizing multiple arrays and other groups with a hierarchical structure.\n",
+ "- **Metadata**: JSON-like metadata describing the arrays and groups, including information about data types, dimensions, chunking, compression, and user-defined key-value fields. \n",
+ "- **Dimensions and Shape**: Arrays can have any number of dimensions, and their shape is defined by the number of elements in each dimension.\n",
+ "- **Coordinates & Indexing**: Zarr supports coordinate arrays for each dimension, allowing for efficient indexing and slicing.\n",
+ "\n",
+ "The diagram below from [the Zarr v3 specification](https://wiki.earthdata.nasa.gov/display/ESO/Zarr+Format) showing the structure of a Zarr store:\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "NetCDF and Zarr share similar terminology and functionality, but the key difference is that NetCDF is a single file, while Zarr is a directory-based “store” composed of many chunked files, making it better suited for distributed and cloud-based workflows."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### Zarr Fundamenals\n",
+ "A Zarr array has the following important properties:\n",
+ "- **Shape**: The dimensions of the array.\n",
+ "- **Dtype**: The data type of each element (e.g., float32).\n",
+ "- **Attributes**: Metadata stored as key-value pairs (e.g., units, description.\n",
+ "- **Compressors**: Algorithms used to compress each chunk (e.g., Zstd, Blosc, Zlib).\n",
+ "\n",
+ "\n",
+ "#### Example: Creating and Inspecting a Zarr Array\n",
+ "\n",
+ "Here we create a simple 2D array of shape `(40, 50)` with chunks of size `(10, 10)` ,write to the `LocalStore` in the `test.zarr` directory. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import zarr\n",
+ "import pathlib\n",
+ "import shutil\n",
+ "\n",
+ "# Ensure we start with a clean directory for the tutorial\n",
+ "datadir = pathlib.Path('../data/zarr-tutorial')\n",
+ "if datadir.exists():\n",
+ " shutil.rmtree(datadir)\n",
+ "\n",
+ "output = datadir / 'test.zarr'\n",
+ "z = zarr.create_array(shape=(40, 50), chunks=(10, 10), dtype='f8', store=output)\n",
+ "z"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3",
+ "metadata": {},
+ "source": [
+ "`.info` provides a summary of the array's properties, including shape, data type, and compression settings.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.info"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.fill_value"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6",
+ "metadata": {},
+ "source": [
+ "No data has been written to the array yet. If we try to access the data, we will get a fill value: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z[0, 0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8",
+ "metadata": {},
+ "source": [
+ "This is how we assign data to the array. When we do this it gets written immediately."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "z[:] = 1\n",
+ "z[0, :] = np.arange(50)\n",
+ "z[:]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10",
+ "metadata": {},
+ "source": [
+ "#### Attributes\n",
+ "\n",
+ "We can attach arbitrary metadata to our Array via attributes:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "11",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.attrs['units'] = 'm/s'\n",
+ "z.attrs['standard_name'] = 'wind_speed'\n",
+ "print(dict(z.attrs))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "12",
+ "metadata": {},
+ "source": [
+ "### Zarr Data Storage\n",
+ "\n",
+ "Zarr can be stored in memory, on disk, or in cloud storage systems like Amazon S3.\n",
+ "\n",
+ "Let's look under the hood. _The ability to look inside a Zarr store and understand what is there is a deliberate design decision._"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.store"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14",
+ "metadata": {
+ "tags": [
+ "hide-output"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "!tree -a {output}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "15",
+ "metadata": {
+ "tags": [
+ "hide-output"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "!cat {output}/zarr.json"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "16",
+ "metadata": {},
+ "source": [
+ "### Hierarchical Groups"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17",
+ "metadata": {},
+ "source": [
+ "Zarr allows you to create hierarchical groups, similar to directories. To create groups in your store, use the `create_group` method after creating a root group. Here, we’ll create two groups, `temp` and `precip`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "store = zarr.storage.MemoryStore()\n",
+ "root = zarr.create_group(store=store)\n",
+ "temp = root.create_group('temp')\n",
+ "precip = root.create_group('precip')\n",
+ "t2m = temp.create_array('t2m', shape=(100, 100), chunks=(10, 10), dtype='i4')\n",
+ "prcp = precip.create_array('prcp', shape=(1000, 1000), chunks=(10, 10), dtype='i4')\n",
+ "root.tree()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "19",
+ "metadata": {},
+ "source": [
+ "Groups can easily be accessed by name and index.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "20",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "display(root['temp'])\n",
+ "root['temp/t2m'][:, 3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "21",
+ "metadata": {},
+ "source": [
+ "To get a look at your overall dataset, the `tree` and `info` methods are helpful.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "22",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "root.info"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "23",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "root.tree()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "24",
+ "metadata": {},
+ "source": [
+ "#### Chunking\n",
+ "Chunking is the process of dividing Zarr arrays into smaller pieces. This allows for parallel processing and efficient storage.\n",
+ "\n",
+ "One of the important parameters in Zarr is the chunk shape, which determines how the data is divided into smaller, manageable pieces. This is crucial for performance, especially when working with large datasets.\n",
+ "\n",
+ "To examine the chunk shape of a Zarr array, you can use the `chunks` attribute. This will show you the size of each chunk in each dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "25",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.chunks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "26",
+ "metadata": {},
+ "source": [
+ "When selecting chunk shapes, we need to keep in mind two constraints:\n",
+ "\n",
+ "- Concurrent writes are possible as long as different processes write to separate chunks, enabling highly parallel data writing. \n",
+ "- When reading data, if any piece of the chunk is needed, the entire chunk has to be loaded. \n",
+ "\n",
+ "The optimal chunk shape will depend on how you want to access the data. E.g., for a 2-dimensional array, if you only ever take slices along the first dimension, then chunk across the second dimension.\n",
+ "\n",
+ "Here we will compare two different chunking strategies.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "27",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = datadir / 'c.zarr'\n",
+ "c = zarr.create_array(shape=(200, 200, 200), chunks=(1, 200, 200), dtype='f8', store=output)\n",
+ "c[:] = np.random.randn(*c.shape)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%time _ = c[:, 0, 0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output = datadir / 'd.zarr'\n",
+ "d = zarr.create_array(shape=(200, 200, 200), chunks=(200, 200, 1), dtype='f8', store=output)\n",
+ "d[:] = np.random.randn(*d.shape)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "30",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%time _ = d[:, 0, 0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "31",
+ "metadata": {},
+ "source": [
+ "### Sharding\n",
+ "When working with large arrays and small chunks, Zarr’s sharding feature can improve storage efficiency and performance. Instead of writing each chunk to a separate file—which can overwhelm file systems and cloud object stores—sharding groups multiple chunks into a single storage object.\n",
+ "\n",
+ "Why Use Sharding?\n",
+ "\n",
+ "- File systems struggle with too many small files.\n",
+ "- Small files (e.g., 1 MB or less) may waste space due to filesystem block size.\n",
+ "- Object storage systems (e.g., S3) can slow down with a high number of objects.\n",
+ "\n",
+ "With sharding, you choose:\n",
+ "- Shard size: the logical shape of each shard, which is expected to include one or more chunks\n",
+ "- Chunk size: the shape of each compressed chunk\n",
+ "\n",
+ "It is important to remember that the shard is the minimum unit of writing. This means that writers must be able to fit the entire shard (including all of the compressed chunks) in memory before writing a shard to a store.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32",
+ "metadata": {},
+ "source": [
+ "This example shows how to create a sharded Zarr array with a chunk size of `(100, 100, 100)` and a shard size of `(1000, 1000, 1000)`. This means that each shard will contain 10 chunks, and each chunk will be of size `(100, 100, 100)`.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z6 = zarr.create_array(\n",
+ " store={},\n",
+ " shape=(10000, 10000, 1000),\n",
+ " chunks=(100, 100, 100),\n",
+ " shards=(1000, 1000, 1000),\n",
+ " dtype='uint8',\n",
+ ")\n",
+ "\n",
+ "z6.info"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34",
+ "metadata": {},
+ "source": [
+ "\n",
+ "```{tip}\n",
+ "Choose shard and chunk sizes that balance I/O performance and manageability for your filesystem or cloud backend.\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "35",
+ "metadata": {},
+ "source": [
+ "#### Compressors\n",
+ "A number of different compressors can be used with Zarr. The built-in options include Blosc, Zstandard, and Gzip. Additional compressors are available through the [NumCodecs](https://numcodecs.readthedocs.io) package, which supports LZ4, Zlib, BZ2, and LZMA. \n",
+ "\n",
+ "Let's check the compressor we used when creating the array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.compressors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37",
+ "metadata": {},
+ "source": [
+ "If you don’t specify a compressor, by default Zarr uses the Zstandard compressor."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "38",
+ "metadata": {},
+ "source": [
+ "How much space was saved by compression?\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "39",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.info_complete()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "40",
+ "metadata": {},
+ "source": [
+ "You can set `compression=None` when creating a Zarr array to turn off compression. This is useful for debugging or when you want to store data without compression."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41",
+ "metadata": {},
+ "source": [
+ "```{note}\n",
+ "`.info_complete()` provides a more detailed view of the Zarr array, including metadata about the chunks, compressors, and attributes, but will be slower for larger arrays. \n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "42",
+ "metadata": {},
+ "source": [
+ "#### Consolidated Metadata\n",
+ "Zarr supports consolidated metadata, which allows you to store all metadata in a single file. This can improve performance when reading metadata, especially for large datasets.\n",
+ "\n",
+ "So far we have only been dealing in single array Zarr data stores. In this next example, we will create a zarr store with multiple arrays and then consolidate metadata. The speed up is significant when dealing in remote storage options, which we will see in the following example on accessing cloud storage."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "43",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "store = zarr.storage.MemoryStore()\n",
+ "group = zarr.create_group(store=store)\n",
+ "group.create_array(shape=(1,), name='a', dtype='float64')\n",
+ "group.create_array(shape=(2, 2), name='b', dtype='float64')\n",
+ "group.create_array(shape=(3, 3, 3), name='c', dtype='float64')\n",
+ "zarr.consolidate_metadata(store)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "44",
+ "metadata": {},
+ "source": [
+ "Now, if we open that group, the Group’s metadata has a zarr.core.group.ConsolidatedMetadata that can be used:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "45",
+ "metadata": {
+ "tags": [
+ "hide-output"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from pprint import pprint\n",
+ "\n",
+ "consolidated = zarr.open_group(store=store)\n",
+ "consolidated_metadata = consolidated.metadata.consolidated_metadata.metadata\n",
+ "\n",
+ "pprint(dict(sorted(consolidated_metadata.items())))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "46",
+ "metadata": {},
+ "source": [
+ "Note that while Zarr-Python supports consolidated metadata for v2 and v3 formatted Zarr stores, it is not technically part of the specification (hence the warning above). \n",
+ "\n",
+ "⚠️ Use Caution When ⚠️\n",
+ "- **Stale or incomplete consolidated metadata**: If the dataset is updated but the consolidated metadata entrypoint isn't re-consolidated, readers may miss chunks or metadata. Always run zarr.consolidate_metadata() after changes.\n",
+ "- **Concurrent writes or multi-writer pipelines**: Consolidated metadata can lead to inconsistent reads if multiple processes write without coordination. Use with caution in dynamic or shared write environments.\n",
+ "- **Local filesystems or mixed toolchains**: On local storage, consolidation offers little benefit as hierarchy discovery is generally quite cheap. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "47",
+ "metadata": {},
+ "source": [
+ "### Object Storage as a Zarr Store\n",
+ "\n",
+ "Zarr’s layout (many files/chunks per array) maps perfectly onto object storage, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage. Each chunk is stored as a separate object, enabling distributed reads/writes.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "48",
+ "metadata": {},
+ "source": [
+ "Here are some examples of Zarr stores on the cloud:\n",
+ "\n",
+ "* [Zarr data in Microsoft's Planetary Computer](https://planetarycomputer.microsoft.com/catalog?filter=zarr)\n",
+ "* [Zarr data from Google](https://console.cloud.google.com/marketplace/browse?filter=solution-type:dataset&_ga=2.226354714.1000882083.1692116148-1788942020.1692116148&pli=1&q=zarr)\n",
+ "* [Amazon Sustainability Data Initiative available from Registry of Open Data on AWS](https://registry.opendata.aws/collab/asdi/) - Enter \"Zarr\" in the Search input box.\n",
+ "* [Pangeo-Forge Data Catalog](https://pangeo-forge.org/catalog)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "49",
+ "metadata": {},
+ "source": [
+ "### Xarray and Zarr\n",
+ "\n",
+ "Xarray has built-in support for reading and writing Zarr data. You can use the `xarray.open_zarr()` function to open a Zarr store as an Xarray dataset.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "50",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import xarray as xr\n",
+ "\n",
+ "store = 'https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/gpcp-feedstock/gpcp.zarr'\n",
+ "\n",
+ "ds = xr.open_dataset(store, engine='zarr', chunks={}, consolidated=True)\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "51",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.precip"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "52",
+ "metadata": {},
+ "source": [
+ "::::{admonition} Exercise\n",
+ ":class: tip\n",
+ "\n",
+ "Can you calculate the mean precipitation for January 2020 in the GPCP dataset and plot it?\n",
+ "\n",
+ ":::{admonition} Solution\n",
+ ":class: dropdown\n",
+ "\n",
+ "```python\n",
+ "ds.precip.sel(time=slice('2020-01-01', '2020-01-31')).mean(dim='time').plot()\n",
+ "```\n",
+ ":::\n",
+ "::::"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "53",
+ "metadata": {},
+ "source": [
+ "Check out our other [tutorial notebook]() that highlights the CMIP6 Zarr dataset stored in the Cloud\n",
+ "\n",
+ "## Additional Resources\n",
+ "\n",
+ "- [Zarr Documentation](https://zarr.readthedocs.io/en/stable/)\n",
+ "- [Cloud Optimized Geospatial Formats](https://guide.cloudnativegeo.org/zarr/zarr-in-practice.html)\n",
+ "- [Scalable and Computationally Reproducible Approaches to Arctic Research](https://learning.nceas.ucsb.edu/2025-04-arctic/sections/zarr.html)\n",
+ "- [Zarr Cloud Native Geospatial Tutorial](https://github.com/zarr-developers/tutorials/blob/main/zarr_cloud_native_geospatial_2022.ipynb)"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/intermediate/remote_data/cmip6-cloud.ipynb b/intermediate/remote_data/cmip6-cloud.ipynb
index e93eabf6..fa27ff7f 100644
--- a/intermediate/remote_data/cmip6-cloud.ipynb
+++ b/intermediate/remote_data/cmip6-cloud.ipynb
@@ -5,6 +5,7 @@
"id": "0",
"metadata": {},
"source": [
+ "(cmip6-cloud)=\n",
"# Zarr in Cloud Object Storage\n",
"\n",
"In this tutorial, we'll cover the following:\n",