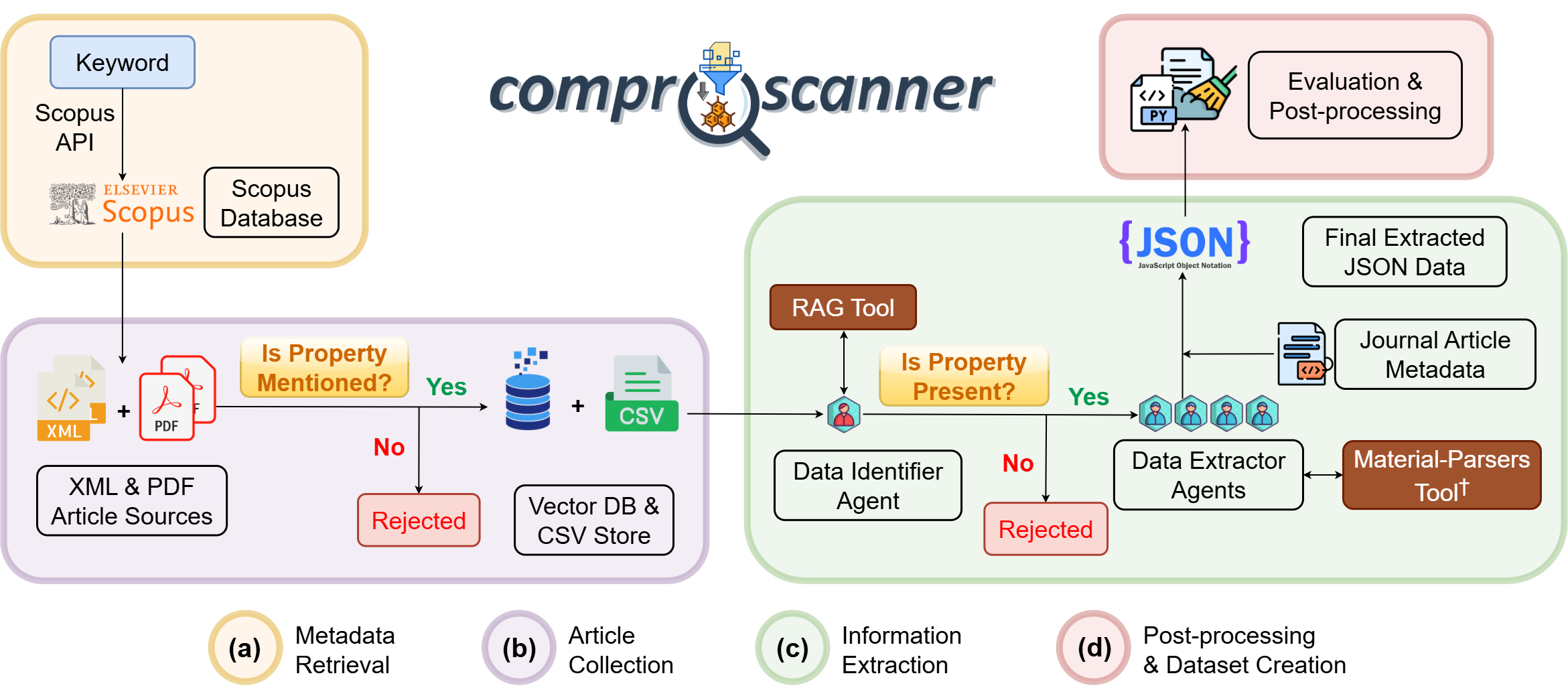
Releases: slimeslab/ComProScanner
v2026.5.19
Added
-
Added
SCIENCEDIRECT_INSTTOKENenvironment variable support inElsevierArticleProcessorfor off-campus remote access to subscription-based Elsevier articles and figures. When set, the token is sent as theX-ELS-Insttokenheader in all ScienceDirect API requests and figure downloads. The variable is optional; omitting it does not affect on-campus access. -
New
value_error_thresholdsparameter added to bothevaluate_semantic()andevaluate_agentic()for range-based absolute error tolerances on numeric property value comparisons:-
Accepts a dict mapping
(min, max)tuples to absolute error thresholds. Ranges are interpreted as layers: the narrowest range containing the ground-truth value determines the tolerance. For example,(-150, 150): 1applies only to values in (-150, -50) and (50, 150) when(-50, 50): 0.5is also present — no need for separate positive/negative sub-ranges. Tuple element order is irrelevant:(-150, 150)and(150, -150)are equivalent. Values outside all configured ranges fall back to exact comparison. -
Semantic evaluation: handled inside
_is_value_in_range()via the new_get_error_threshold()helper inMaterialsDataSemanticEvaluator. -
Agentic evaluation: a new
GetValueErrorThresholdTool(CrewAIBaseTool) is added to the composition evaluator agent when thresholds are configured. The agent calls this tool with the reference value to retrieve the tolerance before deciding on each numeric match. No tool is added and no prompt changes are made when no thresholds are provided.
-
-
Exposed
value_error_thresholdsin public evaluation methods:ComProScanner.evaluate_semantic(),ComProScanner.evaluate_agentic(),comproscanner.evaluate_semantic(), andcomproscanner.evaluate_agentic(). -
VLM-based graph data extraction added across all publishers and PDF processors:
-
New
GraphExtractorTool— a CrewAI agent tool that reads saved figures for a given DOI and uses a vision LLM to extract composition-property value pairs from graphs and charts. Default VLM:gemini/gemini-3-flash-preview. -
New
FigureExtractorutility — shared helper for caption keyword-based figure filtering and saving, used by all article processors. -
New
main_figure_keywordsparameter inprocess_articles()andextract_composition_property_data(), and newvlm_modelandrelated_figures_base_pathparameters inextract_composition_property_data().
-
-
New unit tests added for all three agent tools in
tests/test_agent_tools/. -
Added
save_failed_pdf_reportandfailed_pdf_report_pathtoprocess_articles(), with filename-derived DOI validation and failed-PDF reporting for local PDF workflows. -
Added
save_failed_automated_reportandfailed_automated_report_pathtoprocess_articles()for automated publisher sources (Elsevier, Springer Nature, IOP, Wiley), mirroring the existing PDF failure report. Failed articles are written as tab-separateddoi,publisher,reasonentries toresults/failed_automated_articles.txtby default. -
Added image-aware fallback in
DataExtractionFlow.identify_materials_data_presence():- The Materials Data Identifier still runs text RAG first.
- If RAG returns
no, the flow now checks saved DOI figures with VLM and upgrades the decision toyeswhen relevant graph/figure evidence is found (including doping concentration vs property plots where full formulas are absent).
-
Added
is_store_unresolved_compositionsandunresolved_compositions_fileparameters toclean_data()to optionally log split composition-property resolution statistics (source,filtered,unresolved,resolvedcounts) and persist filtered and unresolved composition keys in a JSON file keyed by DOI under"filtered"and"unresolved"top-level keys. -
Added explicit Equation Tool model control:
- New
equation_modelparameter inextract_composition_property_data()(threaded throughDataExtractionFlowandCompositionExtractionCrewintoEquationTool). - EquationTool model precedence is now:
equation_modelargument -> API-key-based auto-selection.
- New
-
Clarified Equation Tool instruction customization in extraction docs and API:
formula_instructionremains available inextract_composition_property_data()for domain-specific formula-derivation guidance, while preserving the built-in default instruction when unset.
Changed
- Versioning scheme migrated from Semantic Versioning (SemVer) to Calendar Versioning (CalVer) using the
YYYY.MM.DDformat. Starting from this release, version numbers reflect the release date rather than an incrementing major/minor/patch scheme.
Fixed
-
_parse_json_output()now recovers JSON from mixed-text crew outputs (e.g.Thought: … { "json": "here" }) by scanning for the first{/[and last}/]and retryingjson.loads()on the extracted substring, before falling back toast.literal_eval(). -
Composition formatter agent now verifies
MaterialParserTooloutput for incomplete variable substitution (e.g.(1-x-y)partially resolved as(0.9-0.010)) and overrides with the correct fully-substituted BODMAS expression when the tool is wrong. -
process_articles()now routes user-provideddoi_listbygeneral_publisherfrom metadata and sends each DOI only to its matching source processor. -
PNG, GIF, and WEBP figures now convert correctly to JPEG: transparent images are composited onto a white background, animated GIFs are pinned to frame 0, and two additional Springer Nature CDN URL patterns are tried to improve download success for these formats.
-
Added and updated tests for new extraction-flow behavior:
- EquationTool model selection tests now cover explicit arg override, env override, and updated model defaults.
- DataExtractionFlow tests now cover figure-based materials-data fallback and
equation_modelforwarding intoCompositionExtractionCrew.
Full Changelog: v0.1.6...v2026.5.19
v0.1.6
Changed
- Updated README.md, CITATION.cff and docs with the published version (advance article) of the ComProScanner paper in Digital Discovery as fully open access:
Added
- Guide for API key creation for various LLM providers and publisher APIs added to the documentation at
docs/getting-started/api-key-guide.mdwith detailed instructions for each provider.
Fixed
- Model prefix handling in
rag_tool.pystandardized to reflect the docs. HF_TOKENdocumentation clarified as optional — only required for gated or private Hugging Face models.
Full Changelog: v0.1.5...v0.1.6
Edit Archived version of ComProScanner referenced in the Digital Discovery paper
Archived version of ComProScanner which is referenced in the Digital Discovery paper.
This release includes:
- the snapshot of ComProScanner package which has been referenced in the Digital Discovery paper
examplesfolder with:- minimal and test (used script for evaluation) scripts to run ComProScanner
- 5 years of piezoelectric materials-related journal articles' metadata
- collected full-text articles where d33 were mentioned as CSV and vector-database entry
- data related 100 randomly chosen DOIs from the 3917 d33-mentioned articles to benchmark ComProScanner across 10 different cost-efficient LLMs.
- all model logs and outputs for 100 test articles across 10 LLMs.
- data related to the comparison with similar existing frameworks (Eunomia and the extraction agent by CMEG-IITR)
- scripts to regenerate graphs and other relation information for the paper.
v0.1.3
Fixed
- RecursiveCharacterTextSplitter importing updated for the latest langchain version to avoid import errors
Full Changelog: aritraroy24/ComProScanner@v0.1.2...v0.1.3
v0.1.2
Link to ComProScanner preprint on arXiv in the documentation index page and README.md:
arXiv:2510.20362
v0.1.1
README images updated with an external image link to fix the PyPI rendering issue.
v0.1.0
Initial release of ComProScanner
v0.1.5
Added
-
Data related to comparison with other agentic data extraction frameworks added for the ComProScanner paper in the
examples/piezo_test/comparing_existing_frameworksfolder. -
New parameter
apply_advanced_cleaningadded to data cleaning methods indata_cleaner.py. When set toTrue, it triggers the advanced cleaning pipeline. -
Advanced composition cleaning methods in
data_cleaner.py:_remove_miller_indices()- Removes crystal plane notations from chemical formulas_remove_zero_coefficient_elements()- Removes elements with zero coefficients_normalize_coefficients()- Removes trailing zeros from coefficients_expand_leading_and_trailing_coefficients()- Expands leading/trailing coefficient patterns_expand_parenthetical_coefficients()- Expands nested bracket coefficients
-
Enhanced documentation in
docs/usage/data-cleaning.md:- Added
apply_advanced_cleaningparameter documentation - Added Mermaid process flow diagram showing cleaning stages
- Added advanced cleaning examples with tables for each transformation type
- Added
-
Template for GitHub issues added to .github/ISSUE_TEMPLATE for the following topics:
- bug reports
- feature requests
- documentation improvements
- support questions
-
Changelog page added in the documentation. Also, CHANGELOG.md linked in README.md.
-
DeepWiki integration badge added to README.md for community Q&A support:
-
arXiv preprint badge added to README.md:
-
CITATION.cff added for standardized citation information based on the latest release and arXiv preprint.
Fixed
-
OAWorks API is replaced with OpenAlex API as OAWorks is no longer available.
-
Empty/corrupted PDF handled in
pdf_processor.pyandwiley_processor.pyto avoid having GLYPH errors during text extraction. -
Data extraction failures fixed if composition-property text data is empty.
-
CSV progress tracking in
elsevier_processor.py:- DtypeWarning resolved by adding
dtype=str, low_memory=Falsetopd.read_csv() - Data loss issue fixed with immediate CSV persistence for processed articles
- Sleep delays optimized for batch writes
- DtypeWarning resolved by adding
-
Type annotation warnings in documentation build (griffe/mkdocstrings):
- Added return type annotations to function signatures in
comproscanner.py - Added return type annotations to all visualization functions in
data_visualizer.pyandeval_visualizer.py - Fixed parameter type format in docstrings from colon to comma notation
- Added
TYPE_CHECKINGconditional imports for matplotlib Figure type - Fixed
**kwargstype annotations across multiple modules
- Added return type annotations to function signatures in
-
Numbered list formatting in
docs/about/contribution.md:- Fixed list continuation by using 4-space indentation for code blocks and nested lists
- Disabled format on save for Markdown files in
.vscode/settings.json
-
GitHub Actions CI disk space issue:
- Added
--no-cache-dirflag to pip install to reduce disk usage
- Added
Changed
- README badges section converted from HTML to markdown format for better compatibility across platforms.
Full Changelog: aritraroy24/ComProScanner@v2026.02.02...v0.1.5
v0.1.4
Added
-
New function
clean_data()added for improved data cleaning and preprocessing instead of integrating it into data extraction function. -
New documentation page for Data Cleaning added:
- docs/usage/data-cleaning.md
- Added to mkdocs.yml navigation.
-
New API overview documentation page added:
- docs/api.md
- Added to mkdocs.yml navigation.
- New mkdocstrings configuration added to mkdocs.yml for automatic API documentation generation.
-
New tests added for remaining utils functions.
-
Added pytest coverage tracking (50%) using
pytest-covand coverage report generation using codecov.
Fixed
- Tests updated to reflect changes in data cleaning process.
Removed
- Arguments related to data cleaning removed from data extraction function.
Changed
- README images updated with raw GitHub links for better reliability:
{kind=link}
{kind=link}
Full Changelog: aritraroy24/ComProScanner@v0.1.3...v0.1.4