Run state-of-the-art LLMs fully offline on Android using llama.cpp and GGUF models.
No cloud. No servers. No tracking. Everything runs locally on-device.
This project demonstrates that multiple major model architectures run flawlessly on Android when integrated with llama.cpp, Kotlin, and Jetpack Compose.
The app is available as a pre-built APK here:
🔗 Download Archon AI (APK)
https://github.com/AnishKMBtech/archon-ai-Llama.cpp-kotlin-integration/releases/tag/master
ℹ️ The source code is not uploaded.
This repository focuses on architecture, implementation, and proof-of-work, not cloning or building.

 |
 |
 |
 |
- 💬 Offline Chat with LLMs
- 🔒 100% Private – No Internet Required
- ⚡ Real-time Token Streaming
- 🔁 Model Loading & Switching
- 📥 Local GGUF Model Support
- 🧠 Multiple Model Architectures Supported
- 🎨 Modern UI with Jetpack Compose
- 📱 Optimized for Mobile Devices
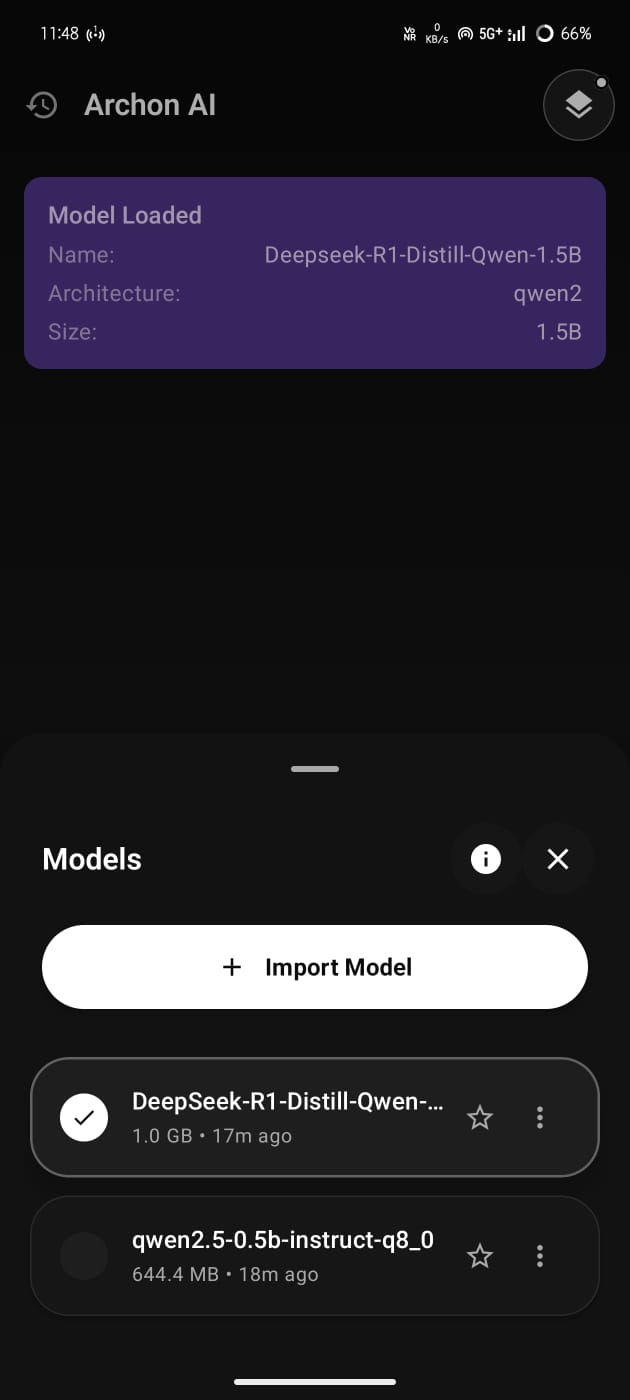
The following models were tested successfully and run flawlessly in Archon AI:
- ✅ DeepSeek 1.5B
- ✅ Qwen 2.5 – 0.5B
- ✅ Gemma 1B Instruct
- ✅ Llama 3 – 1B Instruct
➡️ This confirms that major architectures (LLaMA, Qwen, Gemma, DeepSeek) are fully compatible with llama.cpp on Android.
⚠️ Performance depends on your device RAM and storage.
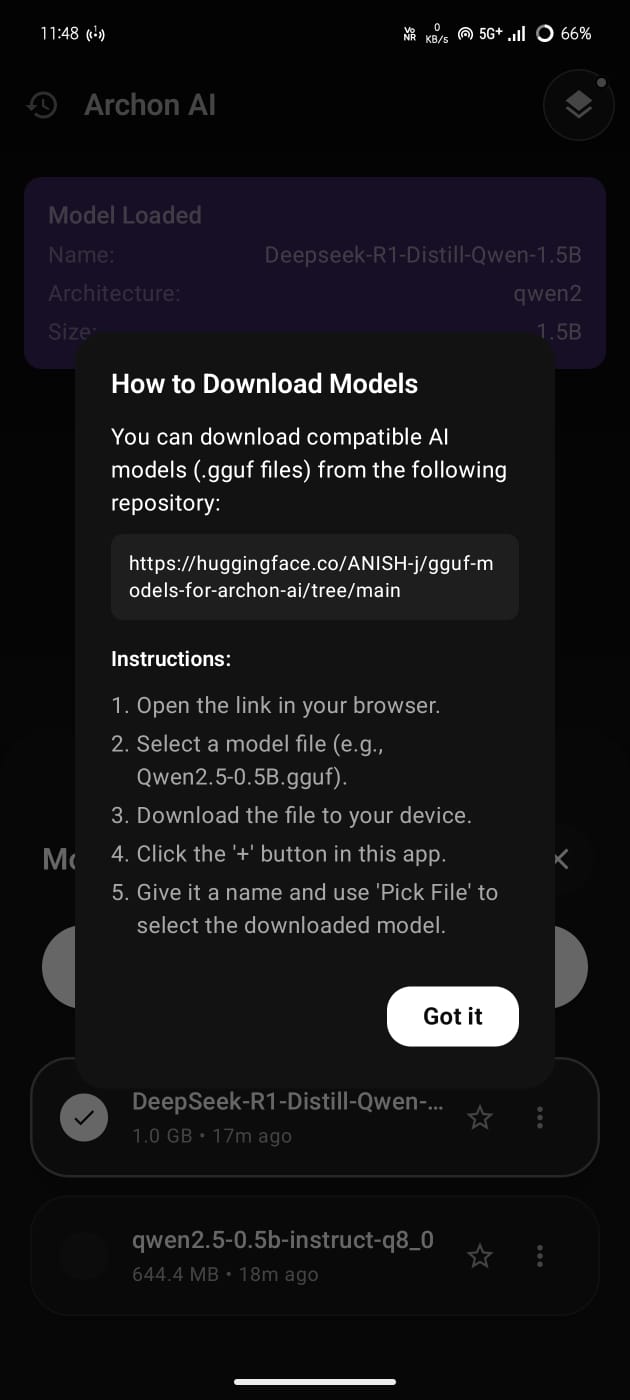
All tested and optimized GGUF models are available here:
🔗 Archon AI GGUF Models (Hugging Face)
https://huggingface.co/ANISH-j/gguf-models-for-archon-ai/tree/main
Recommended Quantization:
Q4_K_MQ4_0
These offer the best balance for mobile performance vs quality.
- Download GGUF models manually (Hugging Face or local storage)
- Models are stored locally on-device
- Select a GGUF file from storage
- llama.cpp initializes the model
- Metadata and readiness are shown in the UI
- Switch between models without reinstalling the app
- Each model runs independently
- Token-by-token streaming
- Low-latency responses
- Optimized for ARM64 devices
- Inference Engine: llama.cpp
- Model Format: GGUF
- Language: Kotlin
- UI: Jetpack Compose
- Architecture: On-device / Edge AI
- Native Layer: C/C++ via JNI
- Target Devices: ARM64 Android phones
- Android: 13+
- RAM:
- Minimum: 4 GB
- Recommended: 6–8 GB+
- Storage:
- 2–8 GB free (depends on model size)
- 🧑🎓 Learning & Q&A
- ✍️ Writing Assistance
- 💡 Idea Brainstorming
- 🌍 Language Practice
- 💻 Code Explanations
- 🔐 Fully Private AI Assistant
- Large models may cause OOM crashes on low-RAM devices
- Thermal throttling may affect long sessions
- Smaller models (≤1.5B) are ideal for phones
-
llama.cpp – https://github.com/ggerganov/llama.cpp
The backbone of on-device LLM inference -
GGML community & open-source contributors
This project integrates llama.cpp, licensed under the MIT License.
Model licenses depend on their respective authors.
Your personal, offline, edge AI assistant — powered by llama.cpp