Monitor and Reduce Kafka Consumer Lag
Apache Kafka's distributed streaming platform excels in real-time data processing and durable event storage, enabling scalable and resilient application architectures. However, maintaining optimal performance requires careful management of consumer lag —a critical metric indicating how far consumers trail behind producers in processing messages.
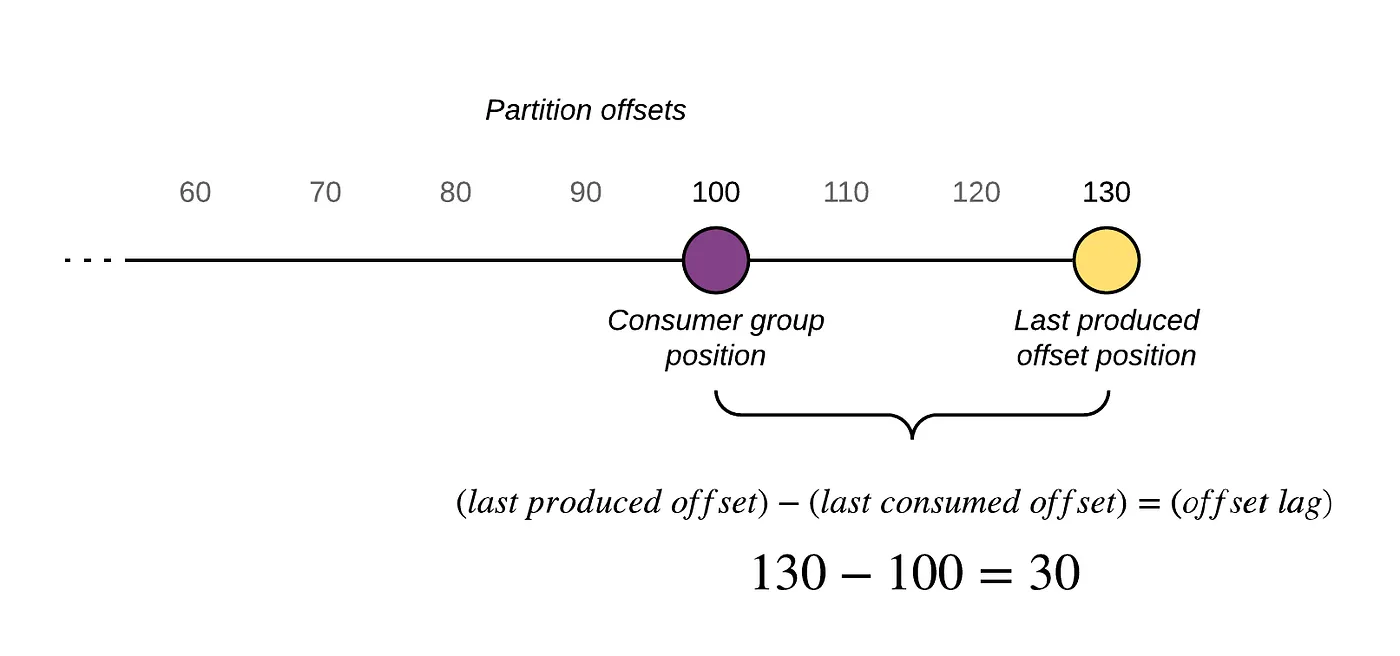
Consumer lag measures the offset difference between the last message written to a partition (log-end offset) and the last message processed by a consumer (current offset). This gap reflects real-time processing delays and serves as a health check for Kafka-based systems. Persistent or increasing lag signals underlying issues affecting performance.
-
Producers : Applications publishing messages to Kafka topics.
-
Brokers : Servers store messages in partitions within topics.
-
Consumers : Applications reading messages from partitions, grouped into consumer groups for scalability.
-
Partitions : Subdivisions of topics that enable parallel processing.
-
Consumer Offsets : Track the progress of consumers within partitions, stored in a dedicated Kafka topic.
- Command :
bin/kafka-consumer-groups.sh --bootstrap-server <broker> --describe --group <group_name>
-
Output : Lists
CURRENT-OFFSET,LOG-END-OFFSET, andLAGper partition.
-
Open-source tool using a sliding window to calculate lag without fixed thresholds.
-
Alerts via email/HTTP and integrates with monitoring systems.
-
Kafka Lag Exporter : Scala-based tool for estimating lag duration.
-
Kafka Exporter : Go-based exporter for Prometheus metrics.
There are other tools available to monitor Kafka Consumer Lag. Please refer to the following:Top 12 Free Kafka GUI Tools 2025
-
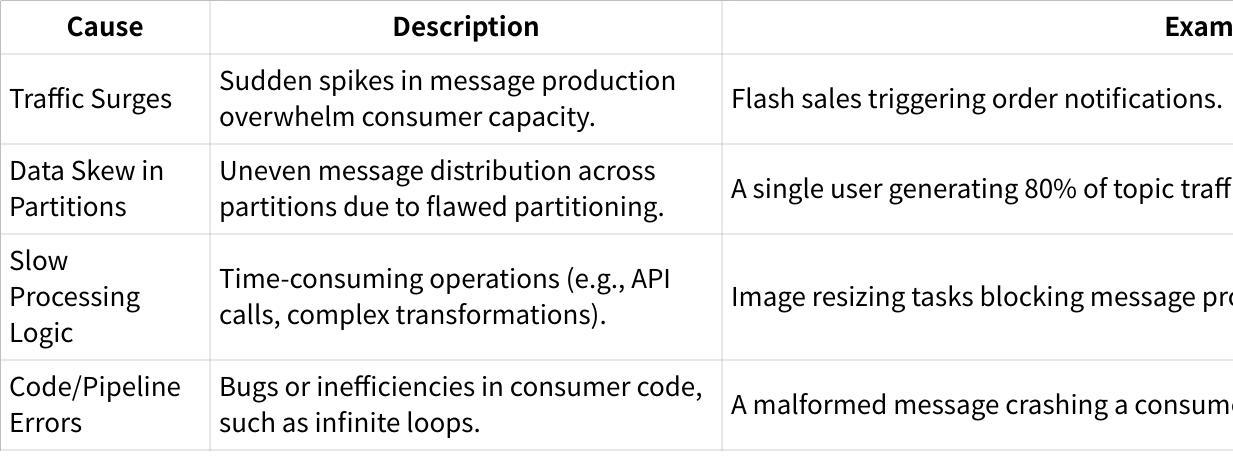
Action : Profile code to identify bottlenecks (e.g., synchronous I/O).
-
Example : Replace blocking database calls with asynchronous processing.
-
Action : Redistribute data using custom partition keys or increase partition count.
-
Example : Hash user IDs to distribute messages evenly across partitions.
-
Action : Offload processing to secondary queues (e.g., RabbitMQ, Redis).
-
Example : Use a worker pool to handle CPU-intensive tasks outside Kafka.
-
Key Parameters :
-
fetch.max.wait.ms: Time to wait for new data. -
max.poll.interval.ms: Prevent rebalances by adjusting timeout thresholds. -
session.timeout.ms: Control broker-side consumer liveliness checks.
-
To better integrate with modern observability systems, AutoMQ has significantly enhanced its monitoring capabilities by exposing all metrics through the Open Telemetry Protocol (OTLP). This design not only simplifies integration with contemporary observability platforms but also provides a more flexible and standardized approach to metrics collection. You can conveniently use AutoMQ's specially provided Grafana templates to seamlessly integrate these OTLP metrics, enabling visualization of monitoring data. After completing this integration configuration, you can fully utilize Grafana's powerful console features and its accompanying alerting tools to customize various monitoring thresholds and alarm rules according to business requirements, promptly detecting and responding to anomalous situations in the system.

Consumer lag is an inevitable but manageable aspect of Kafka deployments. By proactively monitoring lag with tools like Burrow or Prometheus and addressing root causes—whether through code optimization, partition adjustments, or configuration tuning—teams can ensure low-latency, high-throughput data pipelines. Regular performance reviews and automated alerting further safeguard against unexpected spikes in lag, maintaining system reliability in dynamic environments.
[1] Golang Kafka 101: Extract and Calculate our Consumer Lag