https://tbrain.trendmicro.com.tw/Competitions/Details/17
中鋼50年來致力於鋼鐵產業,有舉足輕重的地位,為世界知名鋼鐵廠。隨著人工智慧科技在許多領域已超越人類智能,中鋼放眼下一個50年的發展,已定調「精緻鋼鐵」、「綠能產業」是我們經營發展的兩大主軸,透過「智能化」讓中鋼再精進升級,希冀保持領先的競爭力。為慶祝中鋼50周年,特別舉辦「人工智慧挑戰賽」,挑戰賽的主題與智能化鋼胚的管理有密切的相關。 本次參賽者要以人工智慧演算法,實現鋼胚上印刷或手寫序號的自動判別,將有助於問題源的返溯及品質的控管。參賽者除了要能辨識正常印刷之序號(含數字及英文字母),還得針對手寫序號、序號上下顛倒、重複印刷序號、或序號模糊等情況做有效的處理,以發展出適合實際產線運作的序號辨識系統。
總參賽隊伍:321隊
參賽隊伍名稱:皮卡丘萬歲
Public Leaderboard : 46/321名
Private Leaderboard : 45/321名
將影像直接丟入Resnet50 + GRU 輸出字串,並使用CTC loss訓練參數。
- 修改後的Resnet50將10281232大小的影像透過CNN layer特徵萃取成140之一維向量。
- 將140之向量當作RNN之GRU模型的輸入,經過GRU處理輸出3640大小矩陣,每一行代表這個位置的字母機率(包含空白, 0-9, A-Z沒有O)機率最大的則代表該位置的輸出。
- 神經網路經由CTC loss將輸出與label最小化損失去訓練參數。
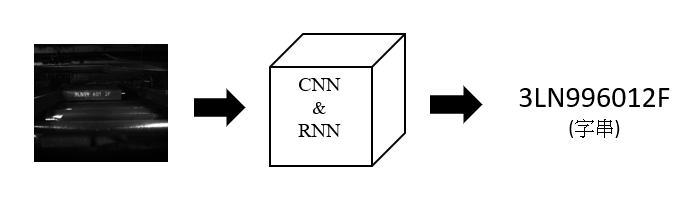
Testing score:1461/3000 (score:預測完全正確得0分,完全錯誤得1分)
Training Data還有提供每張影像的目標label位置的座標(四個角的座標)
因為整張影像包含太多不必要的像素,因此對於每張影像進入CNN + RNN的網路之前先裁切固定大小的影像才放入模型做訓練。

這樣所得到的影像資訊才能盡可能的保有label的特徵。
接著在輸入Resnet50 + GRU 輸出字串。
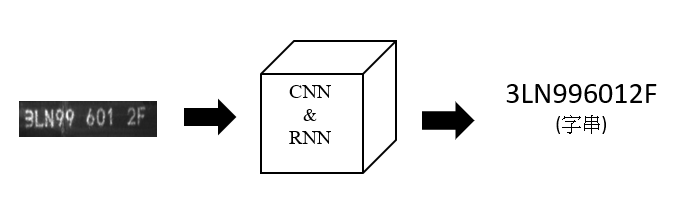
Testing score:1184/3000 (score:預測完全正確得0分,完全錯誤得1分)
考慮到字串位置不是固定在同一個差不多的位置,因此設計訓練了一個CNN先來學習預測字串位置,接著再由裁切好的影像進行字串的預測。此過程為Two stage model,透過兩個model兩個步驟來產生結果。
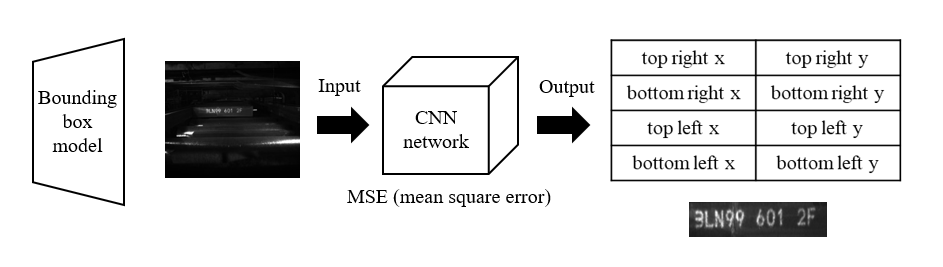
- Bounding box model:輸入影像,輸出邊界。
將影像透過Resnet + fully connected layer輸出8個邊界值,並使用MSE loss訓練參數。
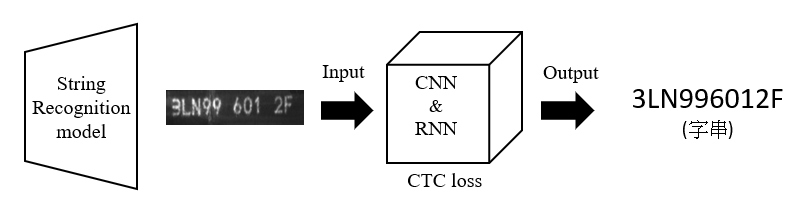
- String Recognition moel:輸入裁切好邊界之影像, 輸出字串。
將裁剪完之Image resize成32 x 160大小,放入Resnet + GRU透過CNN + RNN輸出字串,並使用CTC loss (output和label不等長時使用)訓練參數。
結合兩個Model組成字元辨識系統:
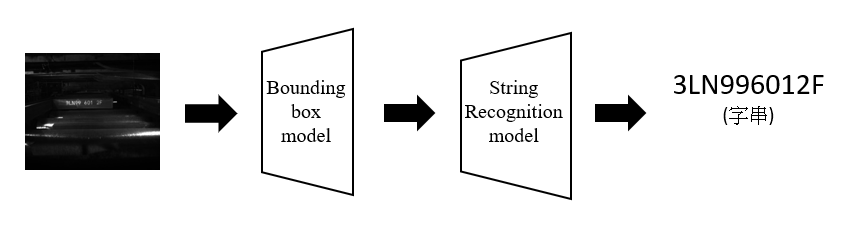
Testing score:1184/3000 (score:預測完全正確得0分,完全錯誤得1分)
Private score:2321/10000, 總名次Top15%(45/321)
透過這次競賽讓我明確知道「影像字串辨識」其中的理論與實作,比較不足的地方在於有些資料的影像是顛倒的,可能可以自己標註新的label「是否有顛倒」來進行一個model的訓練。