QQ群“ai-proofreader 校对插件”:1055031650
一个用于文档和图书校对、基于大语言模型的VS Code插件,支持选中文本直接校对和长文档切分后校对两种工作流,这里是代码库。本插件与相应的Python校对工具库的功能大致相同。
另外,你也可以设置自己的提示词,用于其他文本处理场景,比如翻译、注释、编写练习题等。
A VS Code extension for document and book proofreading based on LLM services, supporting two workflows: proofreading selected text directly and proofreading long documents after segmentation. Here is the code repository. This extension has roughly the same functions as the corresponding Python proofreading tool library.
Additionally, you can also set your own prompts for other text processing scenarios, such as translation, annotation, creating exercises, and more.
- 打开VS Code中插件界面(Ctrl+Shift+X)
- 搜索AI Proofreader
- 点击安装按钮install安装
- 安装后点击设置按钮⚙️,选中弹出菜单中的设置项Settings
- 在设置界面选择下面的一个大语言模型服务平台
- Deepseek开放平台(默认)
- 阿里云百炼,模型列表
- Google Gemini,模型列表
- Ollama本地模型,对计算机性能、专业知识要求较高
- 填写所选平台的API秘钥(须到上述平台通过注册、实名认证、生成API秘钥、充值等操作后获得有效的秘钥)
- 对于Ollama,填写本地服务地址(如:http://localhost:11434)
-
校对文档中的选段
- 打开或新建一个markdown文档(后缀为
.md),选中其中的一段文字 - 在所选右键打开菜单,使用其中的
AI proofreader: proofread selection项校对选中文本 - 其间可选上下文范围、参考文本和温度
- 最后会自动展示校对前后的差异,效果如下:
- 打开或新建一个markdown文档(后缀为
-
切分文档后批量校对
- 打开markdown文档,打开右键菜单,使用其中的
AI proofreader: split file选项,选择切分模式(按长度、按标题、按标题和长度、带上下文等),把当前的切分为JSON文档 - 打开上述JSON文档,打开右键菜单,使用其中的
AI proofreader: proofread file选项,批量校对切分好的片段 - 最后会提示你查看结果:前后差异、差异文件、JSON结果、日志文件
- 打开markdown文档,打开右键菜单,使用其中的
-
尝试所有命令

在打开的markdown(或选中其中一段文字)、JSON文件窗口,可以使用右键菜单访问与文本类型相关的命令。
本扩展所有功能,则可以通过命令面板(Ctrl+Shift+P)查找、访问:
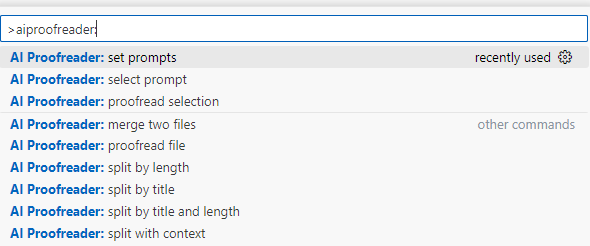
{kind=link}
从VS Code界面左下角或扩展界面的⚙️,或从命令面板(Ctrl+Shift+P)查找命令Preferences: Open Settings (UI)都能进入扩展配置界面。
我的经验,在一般语言文字和知识校对场景中,大语言模型一次输出六百到八百字会有比较好的效果。因此,一本十来万字的书稿需要切分成三百多段,然后交给大模型校对。
打开markdown文件,右键点击编辑器,可以看到切分选项 AI proofreader: split file
或通过命令面板查找更具体的选项:
- 按长度切分 (Split File by Length)
- 输入目标切分长度
- 按标题切分 (Split File by Title)
- 输入标题级别(如:1,2)
- 按标题和长度切分 (Split File by Title and Length)
- 可配置标题级别、阈值(过大则切分)、切分长度和最小长度(过小则合并)
- 按长度切分,以标题范围为上下文 (Split File with Title Based Context)
- 输入切分长度、题级级别
- 按长度切分,扩展前后段落为上下文 (Split File with Paragraph Based Context)
- 输入切分长度、前文段落数和后文段落数
切分后都生成同名的 .json(用于校对) 和 .json.md(可查看切分情况) 两个结果文件。
切分操作都会生成日志文件(.log),记录切分统计信息。
切分完成后会提示用户选择查看结果的方式:比较前后差异、查看JSON结果或查看日志文件。
请注意,本扩展默认用户需要校对的文档为markdown格式,文档切分依赖markdown文档中的两种标记:(一)空行。在markdown中,一个或多个空行表示分段,没有空行的断行在渲染时被忽略。(二)各级标题。如## 开头的是二级标题。至少要有空行,否则无法切分。
插件每次调用大语言模型时能提交三种文本:要处理的目标文本(target,必须)、参考资料(reference,可选)、上下文(context,可选)。比如以一篇文章中的一部分作为target,那么整篇就可以作为context,而在处理中有参考价值的资料,如相关词条,就可以作为reference。
假设你校对一本书,切分后得到包含300个target的JSON文件。那么可以准备相同数量、一一对应的上下文或参考文献,切分成包含相同数量target的JSON文件。然后使用合并命令,将上下文文本中的target作为context合并,将参考文本中的target作为reference合并。
合并 JSON 文件 (Merge Two Files):
- 打开已切分的要校对的 JSON 文件
- 打开右键菜单,选择
AI proofreader: Merge Two Files(或通过命令面板查找)命令 - 选择要合并的文件
- 确定要插入/更新的字段和来源字段
菜单见上两图。
- 校对选中文本 (Proofread Selection)
- 打开文本文件(支持常见文本文件,推荐使用Markdown)
- 选中要校对的段落
- 从右键菜单中选择 Proofread Selection
- 可选择上下文范围、参考文件和温度
- 最后会自动展示校对前后的差异
- 并生成日志
- 校对 JSON 文件 (Proofread File)
- 打开已切分的 JSON 文件
- 右键选择Proofread File
- 自动使用配置的默认值进行校对
- 支持进度显示和取消操作
- 最后会提示你查看结果:前后差异、差异文件、JSON结果、日志文件
- 如有未完成的条目,可重新校对,重新校对时只处理未完成的条目
在当前markdown或json界面,使用右键菜单diff it with another file,如果当前是markdown则有两种模式:
- 调用vscode内置的diff editor比较。查看“前后差异”的功能与此相通。对于长文本,diff editor有段落无法对齐的问题。此时,可以通过分行或删除分行来帮助diff。
- 用jsdiff生成HTML形式的比较结果文件。本模式还支持JSON文件,自动拼接JSON一级元素或
target字段内容进行比较,支持每次比较的片段数量(默认0表示所有片段),生成多个有序的差异文件,避免过长文本无法渲染的问题
本插件目前默认提示词的功能是校对一般的语言文字错误和知识性错误,具体内容见代码库种的proofreader.ts文件。
通过命令面板(Ctrl+Shift+P)可以
- 管理提示词 (AI Proofreader: set prompts),可增、删、改
- 选择当前使用的提示词 (AI Proofreader: select prompt)
也可以在配置文件中处理提示词,但不适合没有编程知识的用户使用。
为了写好提示词,你需要了解本插件的工作原理:
- 把你的提示词作为系统命令/系统提示词交给大模型
- 在第一轮对话中提交
<reference>${reference}</reference>和<context>${context}</context>; - 在第二轮对话中提交
<target>${target}</target> - 接收、处理第二轮对话的输出作为结果
整个过程没有魔法,处理的目的和方法完全由提示词和三种文本及其标签(reference、context、target)来定义。这就是说,你可以通过自己的提示词,让AI根据三种文本做你期望的任何处理, 比如撰写大意、插图脚本、练习题、注释,绘制图表,注音,翻译,进行专项核查(专名统一性、内容安全、引文、年代、注释等)……
需要注意的是,在自定义提示词中,必须对要处理的目标文本(target)、参考资料(reference)、上下文(context)进行说明,如果用不到后两者也可以不说明。并且这种说明应尽可能与三种标签的字面意义相协调,比如target可以用作“要处理的目标文本”,也可以用作“要得到的具体目标”(作为系统提示词的补充),但不宜作为参考文本、样例等类。
提示词示例:
你是一位专业的儿童文学翻译家…… 我会提供一段需要翻译的目标文本(target),你的任务是把这段文本翻译成适合孩子阅读的汉语作品……
我如果供参考文本(reference),翻译时请模仿参考文本的语言风格,遵照参考文本中的人名、地名、术语等实体的指定译法……
我如果提供上下文(context),翻译时要根据上下文确定目标文本(target)的具体含义,确保翻译的准确性和连贯性……
输出要求:
- 翻译目标文本(target)后输出;
- ……
为了让用户能够核验、控制每一个步骤,插件会以要校对的文档的文件名(以“测试.md”为例)为基础,生成一些中间文件,各自的作用如下:
- 测试.md,要校对的文档
- 测试.json,切分上述文档的结果,供检查后用于校对;可以进一步与别的切分结果进行合并,以便搭配target + context + reference一起提交处理
- 测试.json.md,拼合上项JSON文件中的target的结果,用于查看或比较原始markdown文件,比JSON直观
- 测试.log,切分日志,用来检查切分是否合理
- 测试.proofread.json,校对上述JSON文件的直接结果,其中的
null项表示还没有校对结果,重新校对时只处理null对应的条目,而不会重复处理已经完成的条目 - 测试.proofread.json.md,拼合上项JSON文件中的结果,比较最初的markdown文件即可看出改动处;如果这个文件已经存在,则自动备份,名字加时间戳
- 测试.proofread.html:通过jsdiff库比较校对前后markdown文件所得的结果,与Word近似的行内标记,可通过浏览器打印成PDF。需要联网调用jsdiff库,并等待运算完成
- 测试.proofread.log,校对日志,校对文本选段的结果也会存在这里
请特别注意:除自动累加的日志文件和自动备份的测试.proofread.json.md,其余中间文件,每次操作都将重新生成!如有需要,请自行备份。
每个模型用于校对的最佳温度需要耐心测试才能得到。
以往的经验是,温度为1时极少有错误和无效改动。
提高模型温度可以增加随机性,如此多次尝试有可能提高召回率,同时也增加不稳定和错误率。
以下是官方资料:
-
deepseek
temperature参数默认为 1.0。官方建议根据如下表格,按使用场景设置
temperature。场景 温度 代码生成/数学解题 0.0 数据抽取/分析 1.0 通用对话 1.3 翻译 1.3 创意类写作/诗歌创作 1.5 -
阿里云百炼平台
- deepseek v3/r1: temperature:0.7(取值范围是
[0:2)) - qwen系列: 取值范围是
[0:2)
- deepseek v3/r1: temperature:0.7(取值范围是
-
Google Gemini
默认为1
- 从md反查PDF:从markdown文件选择文本,使用
Search Selection In PDF命令,将调用SumatraPDF打开同名的PDF文件,并搜索选中文本。须先安装好SumatraPDF,在高级选项中设置ReuseInstance = true可以避免重复打开同一个文件。 - 转换半角引号为全角:使用
AI Proofreader: convert quotes to Chinese命令或菜单。也可在设置中设定为自动处理。 - 文件格式转换功能,须先安装好Pandoc
- 使用命令
convert docx to markdown将docx转为markdown,与下面的命令行等效或:set myfilename="myfilename" pandoc -f docx -t markdown-smart+pipe_tables+footnotes --wrap=none --toc --extract-media="./attachments/%myfilename%" %myfilename%.docx -o %myfilename%.md
set myfilename="myfilename" pandoc -t markdown_strict --extract-media="./attachments/%myfilename%" %myfilename%.docx -o %myfilename%.md
- 使用命令或菜单
convert markdown to docx,将markdown转为docx,与下面的命令行等效pandoc -f markdown -t docx -o myfilename.docx myfilename.markdown
- 使用命令
- 确保在使用前已正确配置必要的 API 密钥
- 一般的语言文字校对依赖丰富的知识、语料,建议使用大规模、非推理模型。bug: 某些推理模型、混合模型可能因为运行时间过长而导致错误,而服务器端可能已经实际运行、计费。
- 长文本建议先切分后校对
- 校对过程可以随时取消,已处理的内容会得到保存,重新校对时不会重复处理
- 注意所用模型 API 调用频率和并发数限制,可通过配置调整
- vscode提供的比较(diff)功能:通过文件浏览器右键菜单使用;本插件在vscode中的比较即调用了本功能。vscode是这些年最流行的文本编辑器,有许多便捷的文字编辑功能,很适合编辑工用作主力编辑器。
- PDF查看器SumatraPDF,速度快,能跨行搜索
- 多功能文档格式转换工具Pandoc
- Acrobat、WPS等软件,可以把PDF文件转成docx或HTML,再用pandoc转markdown
- jsdiff支持JSON文件,允许用户指定每次jsdiff的片段数量,避免文本过长可能无法渲染
- 优化“转换半角引号为全角”算法,避免跨行引号转换错误
- markdown切分/选段校对,加入前后段落作为context
- 支持Ollama
- 禁用Gemini 模型的思考功能
- 用webwiew panel的持久面板代替切分和校对结果通知,可重新打开; 2. [x] 切分结果菜单增加一个“校对JSON结果”按钮 3. [ ] 呈现八切分摘要信息,如段落数、超长段落等
- 预置更多提示词,包括常用的专项校对
- PDF/OCR纯文本整理
- 练习题就地回答
- 翻译
- 按小学语文教材标准加拼音
- 标点符号用法专项校对
- 数字用法专项校对
- 年代、时间专项校对
- 专名统一性专项校对
- 自主发现、提出、校对知识性问题
- 检索、核对互联网资料
- 检索、核对本地词典
- 生成、提交校对记录
- 内部git版本管理
- 推理模型无法使用的问题(可能单纯是因为运行时间过长)
- 在按长度切分的基础上调用LLM辅助切分(似乎仅仅在没有空行分段文本上有必要)
- 支持Copilot(尝试过一次,回文说API还没有开放。还需要研究参考项目。)
- 取消校对时生成jsdiff html,改成提示用户生成
- 切分和校对结果改成Webview Panel呈现,在一个切分、校对流程中可以重新打开
- 切分结果菜单增加一个“校对JSON结果”按钮
- 禁用Gemini模型思考功能
- 添加重试机制
- 新增功能:支持Ollama本地模型,无需网络连接即可使用本地大语言模型进行校对(适合专家用户)
- 优化:为本地模型增加了更长的超时时间,适应本地计算的特点
- 优化:完善校对过程中给用户的配置信息、日志文件中输出的配置信息
- 新增功能:markdown切分/选段校对时,可以加入前后段落作为context
- 优化:转换半角引号为全角的算法,避免跨行引号转换错误
- 扩展了jsdiff比较并生成html的功能,支持JSON文件,并允许用户指定每次比较的片段数量,避免过长文本无法渲染的问题
- 优化了文件切分功能,新增统一的切分入口
- 改进了校对进度显示和取消操作
- 增强了自动备份功能
- 优化了临时文件管理
- 修复了并发请求数的默认值问题
- 完善了错误处理和用户提示
# 安装依赖
npm install
# 开发时实时编译
npm run watch
# 打包
npm run package
# 构建 vsix 扩展安装文件用
npm run package-vsix
# 发布
npm run publish