A major goal of neuroscience is to understand brain computations during visual processing in naturalistic settings. A dominant approach is to use image-computable deep neural networks trained with different task objectives as a basis for linear encoding models. However, in addition to requiring tuning a large number of parameters, the linear encoding approach ignores the structure of the feature maps both in the brain and the models. Recently proposed alternatives have focused on decomposing the linear mapping to spatial and feature components but focus on finding static receptive fields for units that are applicable only in early visual areas. In this work, we employ the attention mechanism used in the transformer architecture to study how retinotopic visual features can be dynamically routed to category-selective areas in high-level visual processing. We show that this computational motif is significantly more powerful than alternative methods in predicting brain activity during natural scene viewing, across different feature basis models and modalities. We also show that this approach is inherently more interpretable, without the need to create importance maps, by interpreting the attention routing signal for different high-level categorical areas. Our approach proposes a mechanistic model of how visual information from retinotopic maps can be routed based on the relevance of the input content to different category-selective regions.
Adeli, H., Sun, M., & Kriegeskorte, N. (2025). Transformer brain encoders explain human high-level visual responses. arXiv preprint arXiv:2505.17329. [arxiv]
@article{adeli2025transformer,
title={Transformer brain encoders explain human high-level visual responses},
author={Adeli, Hossein and Sun, Minni and Kriegeskorte, Nikolaus},
journal={arXiv preprint arXiv:2505.17329},
year={2025}
}
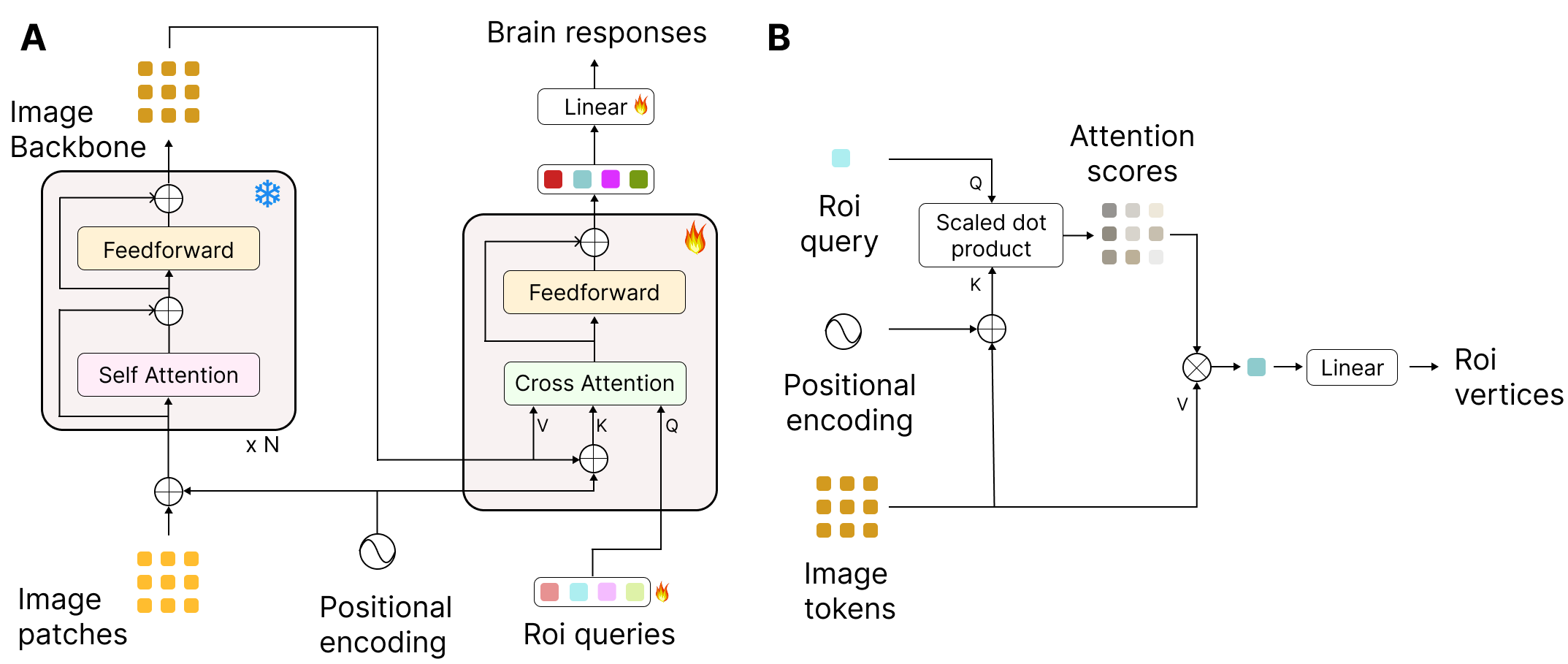
A. Brain encoder architecture. The input patches are first encoded using a frozen backbone model. The features are then mapped using a transformer decoder to brain responses. B. The cross attention mechanism showing how learned queries for each ROI can route only the relevant tokens to predict the vertices in the corresponding ROI.
You can train the model using the code below.
python main.py --run 1 --subj 1 --enc_output_layer 1 --readout_res 'rois_all'Here the run number is given, the subject number, which encoder layer output should be fed to the decoder ([-1] in this case), and what type of queries should the transformer decoder be using.
With 'rois_all', the routing is based on ROIs. You can use the visualize_results.ipynb to see the results after they are saved.
Results for subj 1 showing the differnce between the ROI-based transformer model and the regression model:
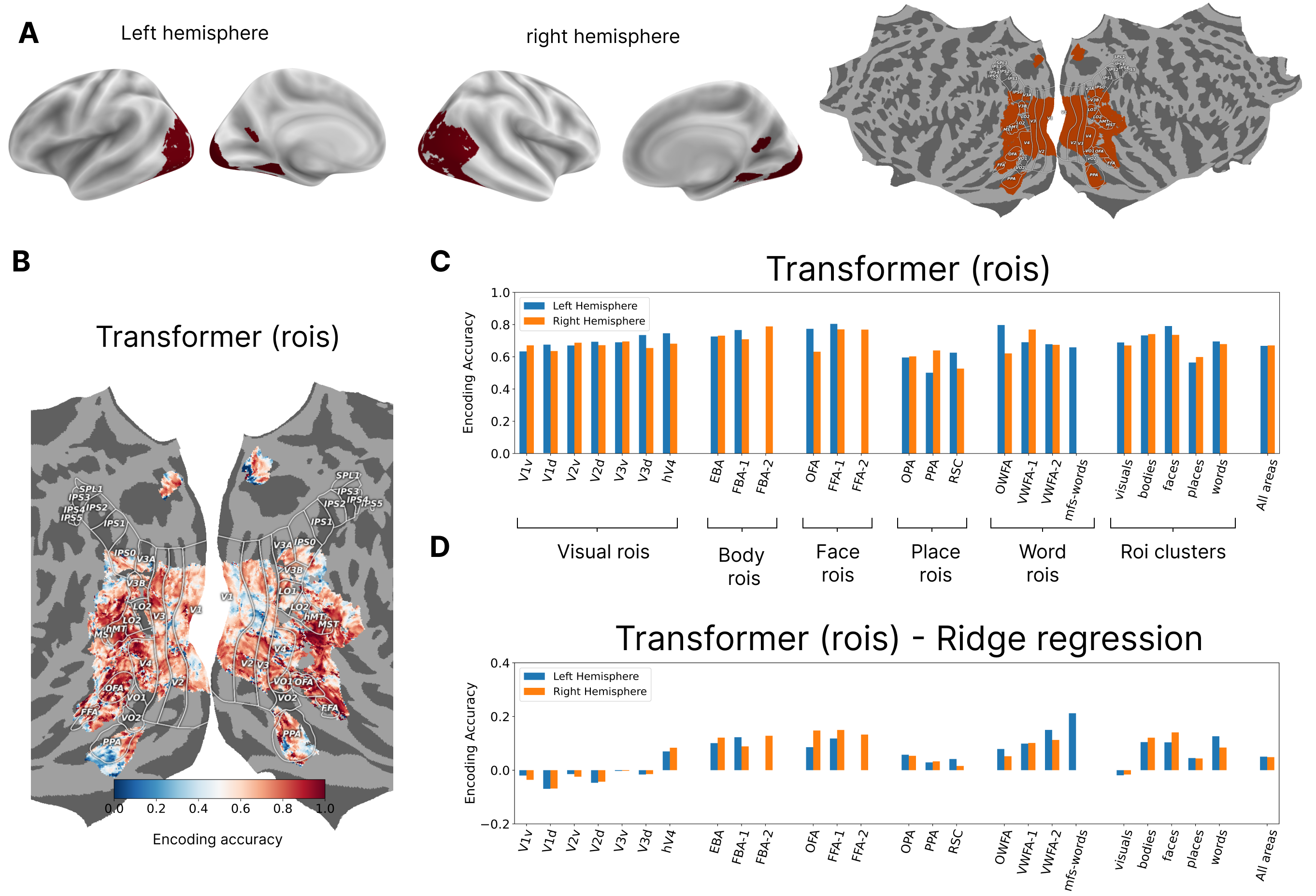
A. The general region of interest for highly visually responsive vertices in the back of the brain shown on different surface maps. B. Encoding accuracy (fraction of explained variance) shown for Subject 1 for all the vertices for the transformer model using ROIs for decoder queries. C. Encoding accuracy for individual ROIs and for ROI clusters based on category selectivity for the two hemispheres. D. The differences in encoding accuracy between the transformer and the ridge regression models showing that improvement in the former is driven by better prediction of higher visual areas.

Transformer decoder cross attention scores for three ROIs overlaid on the images. The selected ROIs show different ways in which the learned ROI queries can route information--- based on location (V2d), content (FBA), or a combination of the two (OFA) depending on the location of the ROI in the brain processing hierarchy.
We intially explored this solution in our our submission to the Algonauts 2023 challenge.
Challenge Leaderboard username: hosseinadeli
Adeli, H., Minni, S., & Kriegeskorte, N. (2023). Predicting brain activity using Transformers. bioRxiv, 2023-08. [bioRxiv]
The following repositories were used, either in close to original form or as an inspiration:
- facebookresearch/dinov2
- facebookresearch/dino
- facebookresearch/detr
- huggingface/pytorch-image-models
For questions -> Hossein Adeli
ha2366@columbia.edu