Versículo chave: "Consagre ao Senhor tudo o que você faz, e os seus planos serão bem-sucedidos." - Provérbios 16:3
Suporte para AZ, AWS, GCP, OCI, Alibaba Cloud, Linode, Docker, Kubernetes, GitHub.
Uma infraestrutura de TI (Tecnologia da Informação) é o conjunto de recursos físicos, lógicos e organizacionais que sustentam o funcionamento dos sistemas tecnológicos de uma empresa, possibilitando o armazenamento, processamento e comunicação de dados. Em outras palavras, é tudo o que dá suporte às operações digitais, desde o hardware até os serviços e políticas que garantem a disponibilidade e segurança da informação.
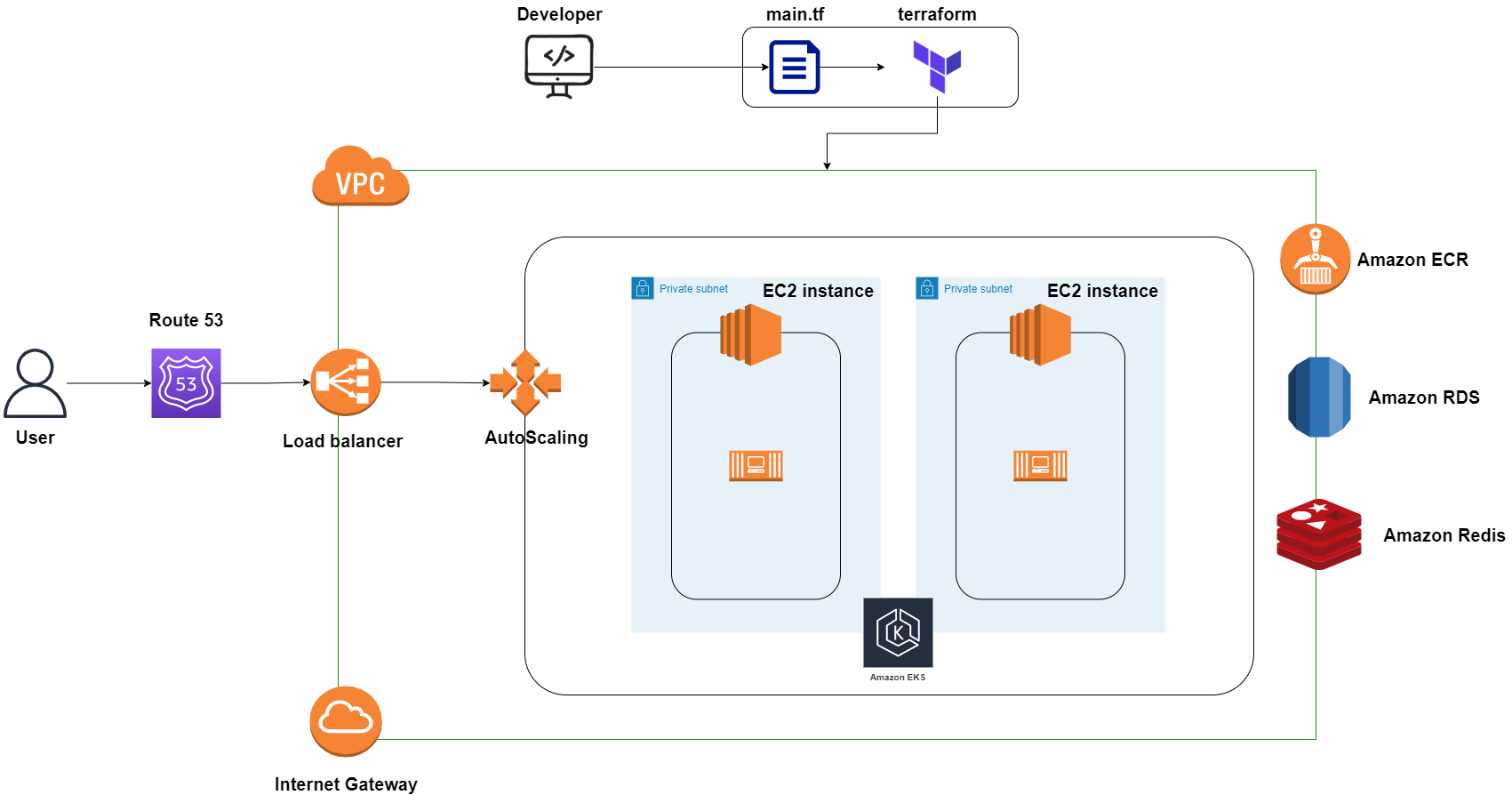
Todos os recursos da AWS serão provisionados via CDK, o que significa que em questão de minutos você terá uma infraestrutura confiável, pronta para produção e escalável implantada na sua conta AWS, permitindo que suas equipes escalem de forma independente e entreguem iterações rápidas de negócio.
Sem dúvidas, ela é uma etapa muito importante quando estamos desenvolvendo System Design, sempre temos que alinhar com a infraestrutura do nosso sistema.
Ela é composta basicamente por quatro camadas principais:
 |
 |
- A primeira é hardware, que inclui servidores, computadores, roteadores, switches, cabos, dispositivos de armazenamento, data centers e até equipamentos de rede Wi-Fi — ou seja, a parte física.
- A segunda é software, que abrange os sistemas operacionais, bancos de dados, aplicações corporativas, ferramentas de virtualização, soluções de monitoramento e todos os programas usados para administrar e executar os serviços de TI.
- A terceira é rede, que integra e conecta todos os componentes, permitindo que dados trafeguem entre usuários, servidores e sistemas — isso envolve internet, intranet, VPNs, firewalls e protocolos de comunicação.
- A quarta é serviços, que compreende tudo o que envolve suporte, manutenção, segurança cibernética, backup, gestão de usuários, governança de TI e práticas de observabilidade.
Atualmente, há também uma divisão entre infraestrutura local (on-premises) e infraestrutura em nuvem (cloud). No modelo local, a empresa mantém e administra seus próprios servidores e redes internamente. Já na nuvem, ela utiliza recursos fornecidos por provedores como AWS, Azure ou Google Cloud, que oferecem escalabilidade, automação e elasticidade sob demanda. Em muitos casos, as organizações adotam o modelo híbrido, combinando os dois mundos — por exemplo, mantendo dados sensíveis localmente e workloads dinâmicos na nuvem.
Em suma, a infraestrutura de TI é a espinha dorsal digital de uma organização. Ela garante que sistemas fiquem disponíveis, seguros, integrados e com desempenho adequado para suportar tanto as operações cotidianas quanto a inovação tecnológica — o que faz dela um dos pilares estratégicos de qualquer empresa moderna.

Podemos comparar uma infraestrutura de TI com uma infraestrutura civil, cujo possui várias rodovias para vários destinos de um cidadão.
Uma infraestrutura de TI é um conjunto de serviços e recursos de TI conectados entre si e trabalhando lado a lado, a fim de realizar uma determinada funcionalidade ou ação de um serviço computacional. Seja esse serviço computacional um(a):

- Deploy, ou seja, a hospedagem de uma aplicação front-end ou back-end no servidor;
- Controle de Versões, configurando as versões da aplicação para cada tipo de ambiente computacional;
- Análise e monitoramento em tempo real das aplicações rodando em qualquer tipo de ambiente;
- Detecção de anomalias encontradas em alguma aplicação ou projeto;
- Automatização de aplicações para que ela rode da melhor forma possível no determinado tipo de ambiente computacional, sem precisar configurar manualmente;
- Conexão entre aplicações para que as aplicações se conectem uma com a outra em ambientes separados.

Cheatsheets: Abordagens utilizadas nas etapas de desenvolvimento, homologação, QA e produção.
 |
 |
 |


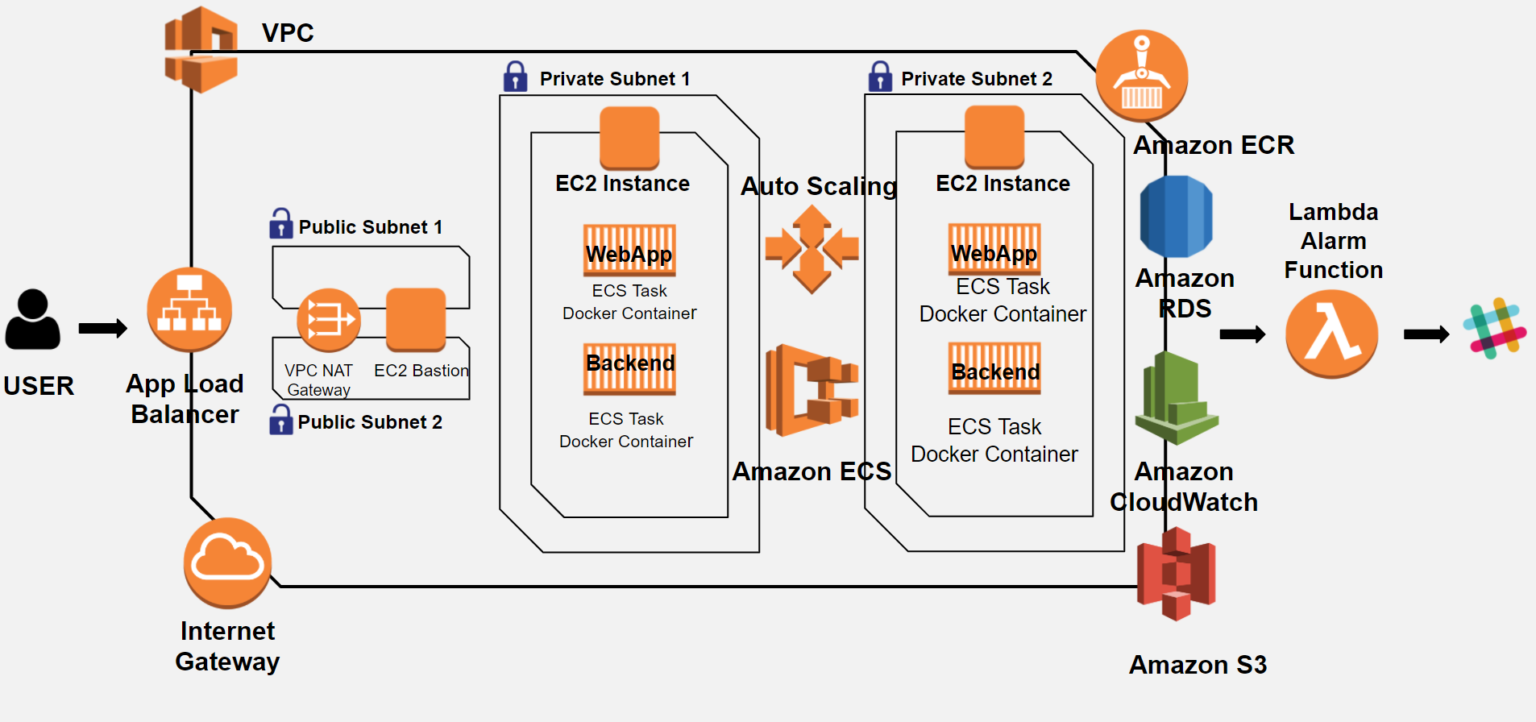
Uma forma simples de implantar uma aplicação em alta disponibilidade utilizando uma simples instância EC2 + ALB + Auto Scaling.


Um Bastion Host, em português "Servidor Bastião", é um servidor de rede especialmente configurado que é projetado para fortalecer a segurança de uma rede protegendo-a contra ameaças externas. Ele age como um ponto de entrada seguro em uma rede, permitindo que administradores acessem e gerenciem sistemas internos sem expor diretamente esses sistemas à Internet. Os Bastion Hosts são usados em arquiteturas de segurança em camadas para proteger sistemas sensíveis e melhorar a segurança de uma rede.
 |
 |
Um Bastion Host é um conceito fundamental em segurança de redes, representando uma fortaleza digital estrategicamente posicionada para proteger os recursos mais valiosos de uma infraestrutura. Imagine um castelo medieval: enquanto a cidade interna abriga os tesouros e a família real, existe uma torre fortificada na entrada, especialmente reforçada, projetada para ser o único ponto de acesso e capaz de resistir a ataques diretos. Essa torre é o bastion host no mundo da cibersegurança.
Em termos técnicos, um bastion host é um servidor especificamente projetado e configurado para resistir a ataques. Ele é intencionalmente exposto à internet ou a redes não confiáveis e serve como o único ponto de entrada para acessar uma rede privada interna. Todos os outros servidores e recursos críticos permanecem protegidos atrás de firewalls adicionais em uma rede interna, inacessíveis diretamente a partir do mundo exterior. O bastion host age como um portal, um salto intermediário obrigatório para qualquer administrador ou serviço que precise acessar esses sistemas protegidos.
A arquitetura típica coloca o bastion host em uma sub-rede desilitarizada, frequentemente chamada de DMZ. De um lado, ele enfrenta a internet selvagem; do outro, ele se comunica com a rede interna através de um firewall restritivo que só permite tráfego específico e autorizado a partir do próprio bastion host. Essa posição estratégica significa que a superfície de ataque da organização é drasticamente reduzida. Em vez de ter dezenas de servidores com portas abertas para a internet, apenas o bastion host precisa ser fortificado e monitorado intensivamente.
O endurecimento de um bastion host é um processo meticuloso que segue o princípio do privilégio mínimo. Todos os serviços não essenciais são removidos ou desabilitados. Não há interfaces gráficas, não há softwares desnecessários, não há contas de usuário padrão. O acesso é estritamente controlado através de chaves criptográficas SSH, nunca por senhas simples. Todas as portas abertas são justificadas e monitoradas, e logs detalhados de todas as conexões e atividades são mantidos e analisados. A configuração é travada, imutável na maioria dos casos, e qualquer modificação deve passar por um processo rigoroso de controle de mudanças.
Os casos de uso mais comuns para bastion hosts envolvem acesso administrativo remoto. Quando um administrador de sistema precisa gerenciar um conjunto de servidores em uma nuvem privada virtual ou em um data center privado, ele primeiro se conecta ao bastion host usando SSH e, a partir dessa sessão segura, estabelece uma segunda conexão para o servidor de destino. Em ambientes de cloud computing como AWS, Azure ou Google Cloud, os bastion hosts são frequentemente a maneira recomendada para acessar instâncias em sub-redes privadas que não possuem endereços IP públicos.
Além do acesso SSH, um bastion host pode ser configurado para outros serviços específicos. Pode hospedar um serviço de VPN que fornece acesso controlado à rede interna, pode atuar como proxy para tráfego web, ou pode gerenciar o acesso a bancos de dados e outros serviços críticos. No entanto, cada serviço adicional aumenta a complexidade e a superfície de ataque, portanto a tendência moderna é manter os bastion hosts o mais especializados e simples possível.
A evolução desse conceito levou ao que hoje chamamos de "Jump Hosts" ou "Jump Servers", que são essencialmente bastion hosts com funcionalidades mais refinadas. Em arquiteturas modernas, especialmente com o surgimento do zero trust, o papel do bastion host está se adaptando. Em vez de simplesmente fornecer acesso à rede interna, ele está se tornando um componente de um sistema maior de controle de acesso, frequentemente integrado com autenticação multifator, auditoria de sessão em tempo real e gravação de todas as atividades para fins de compliance e detecção de ameaças.

Um bastion host bem implementado representa a materialização de vários princípios de segurança: defesa em profundidade, onde múltiplas camadas de segurança protegem os ativos; redução da superfície de ataque, concentrando a defesa em um único ponto; e o princípio do menor privilégio, garantindo que o acesso aos sistemas internos seja estritamente controlado e monitorado. Ele permanece como uma defesa essencial no arsenal de qualquer arquitetura de rede que precise equilibrar acessibilidade remota com segurança robusta.
O AWS VPC Peering é um recurso da Amazon Web Services que permite conectar duas redes virtuais (VPCs) de forma direta e privada, como se elas estivessem dentro da mesma rede, mesmo estando separadas. A ideia central é simples: você tem duas VPCs isoladas — cada uma com seus próprios recursos, como instâncias EC2, bancos de dados, Lambdas etc e quer que elas se comuniquem entre si sem passar pela internet pública. O VPC Peering cria exatamente esse “canal privado” entre elas.

Quando o peering é estabelecido, os recursos de uma VPC podem se comunicar com os da outra usando endereços IP privados, como se fosse uma rede interna. Isso é importante porque garante baixa latência, mais segurança e elimina a necessidade de expor serviços via internet ou configurar VPNs mais complexas. Por baixo dos panos, o tráfego nunca sai da infraestrutura da AWS, o que também melhora performance e reduz riscos.
Mas tem um detalhe importante: o VPC Peering não é automático. Você precisa configurar rotas nas tabelas de roteamento de cada VPC para dizer explicitamente que o tráfego destinado ao range de IP da outra VPC deve passar pela conexão de peering. Além disso, grupos de segurança e ACLs de rede ainda se aplicam, então você controla exatamente o que pode ou não trafegar entre as redes.
Um ponto crítico que muita gente erra é achar que isso funciona como uma rede totalmente integrada, tipo uma malha. Não funciona assim. O VPC Peering não é transitivo. Isso significa que, se você tem três VPCs — A, B e C — e A está conectada com B, e B está conectada com C, isso não quer dizer que A consegue falar com C automaticamente. Você precisaria criar um peering direto entre A e C também. Esse detalhe impacta bastante arquiteturas maiores.
Na prática, o VPC Peering é muito usado em cenários como separar ambientes (produção, staging, dev), conectar serviços entre contas diferentes (multi-account), ou integrar sistemas sem expor APIs publicamente. Por exemplo, você pode ter uma VPC com um banco de dados e outra com uma aplicação, e permitir que apenas a aplicação acesse o banco via rede privada.
Comparando com outras soluções, o VPC Peering é simples e direto, mas não escala tão bem para arquiteturas muito grandes. Quando você começa a ter muitas VPCs e precisa de conectividade mais complexa (tipo topologia hub-and-spoke), geralmente entra em cena o AWS Transit Gateway, que resolve justamente as limitações de não-transitividade e complexidade de múltiplos peerings.
Resumindo de forma direta: o VPC Peering é uma forma de conectar duas redes privadas na AWS de maneira segura, direta e com baixa latência, permitindo comunicação interna sem passar pela internet — mas com limitações importantes que precisam ser consideradas em arquiteturas maiores.

Building an end-to-end CI/CD pipeline for Django applications using Jenkins, Docker, Kubernetes, EKS, ArgoCD, GitHub Actions, AWS EC2, and Terraform can be quite a robust setup. In this article, we will guide you through setting up a comprehensive CI/CD pipeline using AWS EC2, AWS EKS, Jenkins, Github actions, Docker, trivy scan, SonarQube, ArgoCD, Kubernetes cluster of your choice, and terraform.
- https://medium.com/@adewopol/devops-project-8ef09a0e172a
- https://medium.com/django-unleashed/technical-guide-end-to-end-ci-cd-devops-with-jenkins-docker-kubernetes-argocd-github-actions-fee466fe949e
- https://medium.com/@ahammed.jabirp/complete-jenkins-ci-cd-project-f5ebecf04281?source=email-afeafff77325-1698905016499-digest.reader--f5ebecf04281----7-98------------------bd54f64e_8d5a_454d_a7bd_2007552b92c5-1
 |
 |
 |
Projeto DevSecOps Kubernetes de ponta a ponta! Neste projeto abrangente, vamos explicar o processo de configuração de uma arquitetura robusta de três níveis na AWS usando Kubernetes, melhores práticas DevOps e medidas de segurança. Este projeto tem como objetivo fornecer experiência prática na implantação, segurança e monitoramento de um ambiente de aplicação escalável.

Advanced End-to-End DevSecOps Kubernetes Three-Tier Project using Terraform, AWS EKS, ArgoCD, Prometheus, Grafana, and Jenkins
Neste projeto, abordaremos os seguintes aspectos-chave:
-
Configuração do Usuário IAM: Crie um usuário IAM na AWS com as permissões necessárias para facilitar atividades de implantação e gerenciamento.
-
Entendendo a estrutura como código (IaC): Use Terraform e AWS CLI para configurar o servidor Jenkins (instância EC2) na AWS.
-
Configuração do Servidor Jenkins: Instale e configure ferramentas essenciais no servidor Jenkins, incluindo o próprio Jenkins, Docker, Sonarqube, Terraform, Kubectl, AWS CLI e Trivy.
-
Implantação de Cluster EKS: Utilize comandos eksctl para criar um cluster Amazon EKS, um serviço Kubernetes gerenciado na AWS.
-
Configuração do Load Balancer: Configure o AWS Application Load Balancer (ALB) para o cluster EKS.
-
Repositórios Amazon ECR: Crie repositórios privados tanto para imagens Docker frontend quanto backend no Amazon Elastic Container Registry (ECR).
-
Instalação do ArgoCD: Instale e configure o ArgoCD para entrega contínua e GitOps.
-
Integração com Sonarqube: Integre Sonarqube para análise de qualidade de código no pipeline DevSecOps.
-
Pipelines Jenkins: Crie pipelines Jenkins para implantar código backend e frontend no cluster EKS.
-
Configuração de Monitoramento: Implementar monitoramento para o cluster EKS usando Helm, Prometheus e Grafana.
-
Implantação de Aplicações ArgoCD: Use ArgoCD para implantar a aplicação de três camadas, incluindo componentes de banco de dados, backend, frontend e entrada.
-
Configuração de DNS: Configure as configurações de DNS para tornar a aplicação acessível via subdomínios personalizados.
-
Persistência de Dados: Implemente volumes persistentes e reivindicações de volumes persistentes para pods de banco de dados para garantir a persistência dos dados.
-
Conclusão e Monitoramento: Conclua o projeto resumindo as principais conquistas e monitorando o desempenho do cluster EKS usando o Grafana.
Pré-requisitos: Antes de iniciar o projeto, certifique-se de cumprir os seguintes pré-requisitos:
- Uma conta AWS com as permissões necessárias para criar recursos.
- Terraform e AWS CLI estão instalados na sua máquina local.
- Familiaridade básica com Kubernetes, Docker, Jenkins e princípios de DevOps.
Passo 1: Precisamos criar um usuário IAM e gerar a chave AWS Access - Crie um novo usuário IAM na AWS e dê a ele AdministratorAccess para fins de teste (não recomendado para os Projetos da sua organização). Vá até o AWS IAM Service e clique em Users.
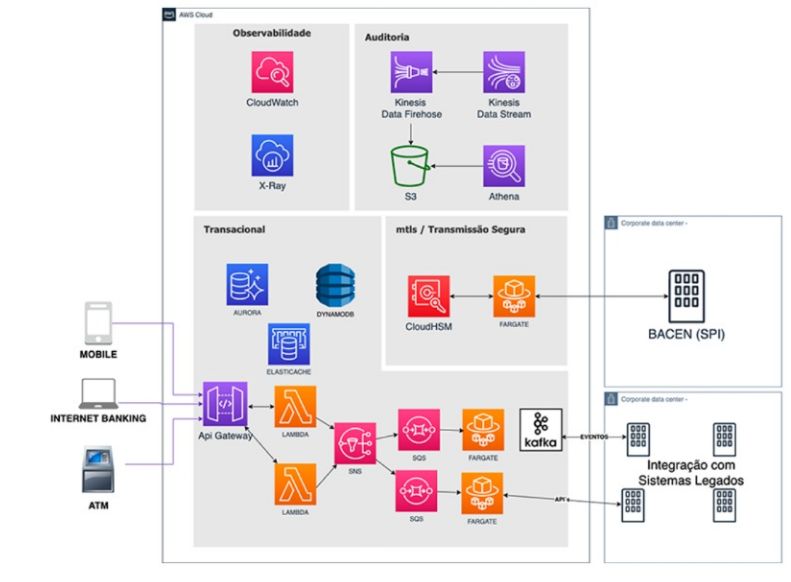
Com a tecnologia de Clusters podemos criar ambientes baseados em contêineres (AWS ECS/EKS), sendo o core da nossa infraestrutura, e escalar eles com ALB - Application Load Balancer dentro de instâncias EC2 com banco de dados AWS RDS e configurá-las com bastion host utilizando subnets públicas e privadas para melhor segurança, permissões com IAM roles, além de monitoramento com AWS CloudWatch e AWS Lambda para criar alarmes via Webhook no canal do Slack.
Essa infraestrutura é a mais moderna do mercado sendo utilizada pela maioria das grandes empresas para a implantação de aplicações, e ela é adaptada também com CI/CD Pipeline para automatizar o seu ciclo de vida e ecossistema (AWS CodeBuild e AWS CodePipeline) e Amazon S3 para armazenar os artefatos. A infraestrutura pode ser personálizavel com AWS CloudFront para CDN ou AWS API Gateway, cache ou até mesmo implementando mensageria com AWS SQN/SQS.
Os segredos e variáveis de ambiente da infraestrutura ficam armazenados no AWS Secrets Manager e AWS Systems Manager > Parameter Store.
Quando falam em “Pod Standard Solution” no contexto do Amazon EKS, estão basicamente se referindo a um padrão arquitetural padronizado de como pods devem ser definidos, implantados e operados dentro do cluster Kubernetes gerenciado pela Amazon Web Services. Não é um produto oficial da AWS com esse nome, mas sim uma prática comum em times de platform engineering para trazer consistência e governança.
Dentro do EKS, você tem toda a flexibilidade do Kubernetes, o que é ótimo, mas também perigoso: cada time pode criar seus pods de um jeito diferente, com configurações inconsistentes de recursos, segurança, observabilidade e deploy. O “Pod Standard Solution” surge justamente para evitar esse caos. Ele define um modelo padrão de pod, que todos os serviços da empresa seguem.
Esse padrão normalmente inclui várias camadas já resolvidas. Por exemplo, o container principal da aplicação roda junto com sidecars que cuidam de responsabilidades transversais. É comum ter um sidecar para logs (enviando para CloudWatch), outro para métricas (Prometheus/OpenTelemetry), ou até um proxy de service mesh. Isso garante que qualquer pod já nasce “observável” por padrão, sem o desenvolvedor precisar reinventar isso.
Além disso, o padrão define como o pod deve se comportar dentro da infraestrutura da AWS. Isso inclui integração com IAM via IRSA (IAM Roles for Service Accounts), limites e requests de CPU/memória bem definidos, health checks (liveness/readiness probes), políticas de segurança (como Pod Security Standards) e até padrões de rede dentro do cluster (usando VPC CNI, security groups por pod, etc.). Tudo isso faz com que os pods sejam previsíveis e seguros.
Outro ponto importante é o deploy. Em ambientes EKS mais maduros, esse “standard pod” não é só um conceito — ele vira algo concreto, como templates Helm, charts internos ou até plataformas que geram manifests automaticamente. O desenvolvedor basicamente só define variáveis mínimas (imagem, porta, algumas configs), e o resto já vem pronto seguindo o padrão da empresa. Isso é o famoso “golden path”.
No contexto de AWS, isso se conecta com vários serviços. Logs podem ir para CloudWatch, métricas para Prometheus/Grafana, tracing via OpenTelemetry, secrets via AWS Secrets Manager, e integração de rede com VPC. Ou seja, o pod já nasce totalmente integrado ao ecossistema cloud sem esforço manual.
Então, o “Pod Standard Solution” no EKS é, na prática, uma abstração organizacional sobre Kubernetes. Ele transforma a liberdade total (e caótica) do Kubernetes em um caminho controlado e repetível. Isso melhora onboarding, reduz erros, aumenta segurança e facilita muito a operação em escala.
Resumindo de forma direta: não é uma feature da AWS, mas sim um padrão que as empresas criam sobre o EKS para garantir que todos os pods sigam boas práticas de execução, observabilidade, segurança e integração com a nuvem. É basicamente Kubernetes com governança e engenharia de plataforma aplicada.
Quando você fala em uma “Service Mesh Standard Solution com HashiCorp Consul no Amazon Web Services”, você está entrando em uma camada ainda mais avançada da arquitetura — onde o foco deixa de ser apenas infraestrutura (VPC, subnets, EC2) ou execução (Kubernetes/EKS) e passa a ser controle de comunicação entre serviços distribuídos.
No cenário do diagrama abaixo, você tem uma VPC dividida em múltiplas Availability Zones, com subnets públicas e privadas, NAT Gateways e instâncias organizadas em Auto Scaling Groups. Dentro das subnets privadas, aparecem os componentes do Consul: clients e servers. Isso já indica um padrão clássico de service mesh com Consul em modo “self-managed” dentro da AWS.
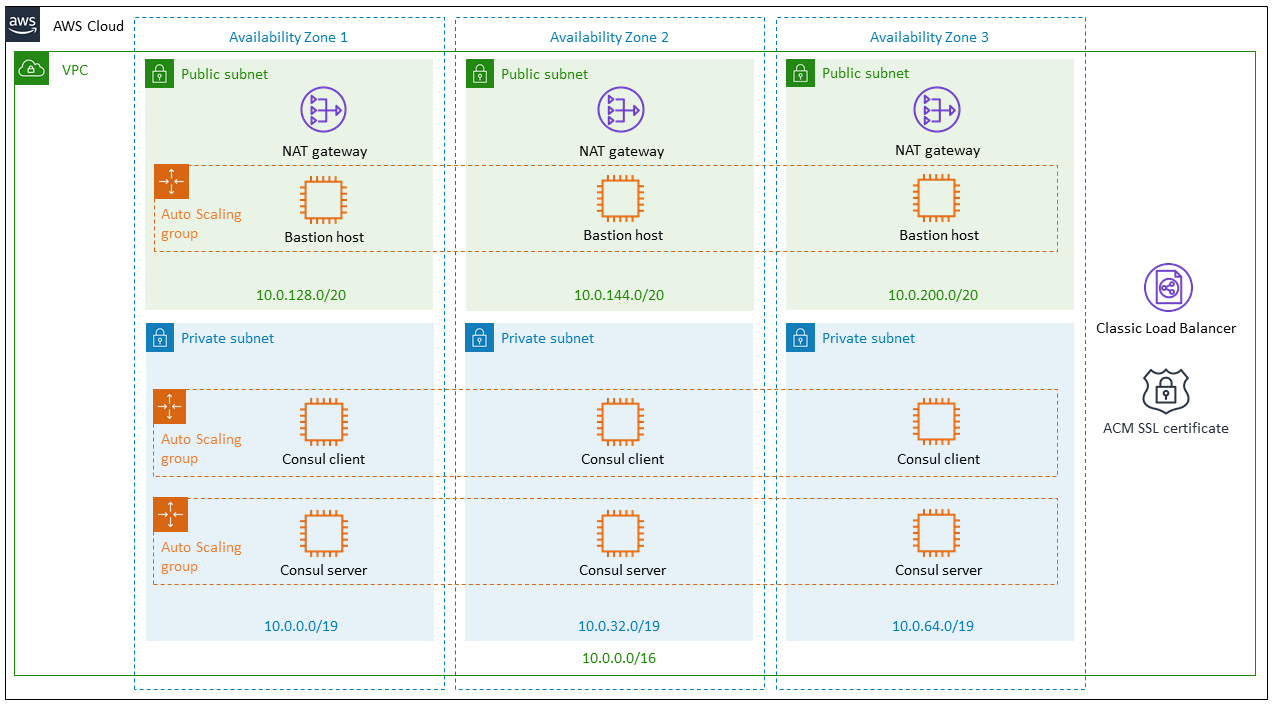
O que o Consul faz nesse contexto é transformar a rede em algo inteligente e orientado a serviços, em vez de apenas IP + porta. Em um ambiente tradicional, um serviço precisa saber o endereço de outro serviço (ou usar DNS básico). Com o Consul, você passa a ter service discovery, ou seja, os serviços se registram automaticamente e podem ser encontrados por nome lógico. Isso elimina acoplamento direto com IPs ou endpoints fixos.
Mas o ponto mais importante é que o Consul evoluiu para um service mesh completo, onde cada serviço roda com um proxy (geralmente Envoy) como sidecar. Isso cria uma camada de rede abstrata onde você pode controlar comunicação entre serviços com regras, políticas e observabilidade. Por exemplo, você pode definir que um serviço A só pode falar com B, mas não com C, ou aplicar mTLS automaticamente entre todos os serviços sem precisar mexer no código da aplicação.
No diagrama, os Consul servers são responsáveis pelo controle central — eles mantêm o estado do cluster, catálogo de serviços e configuração do mesh. Já os Consul clients rodam próximos aos serviços (nas instâncias ou pods) e fazem a ponte entre a aplicação e o plano de controle. Essa separação é importante para escalabilidade e resiliência.
A presença de múltiplas Availability Zones mostra que essa solução está pensada para alta disponibilidade. Os servers do Consul são distribuídos entre zonas para evitar single point of failure, enquanto os clients escalam junto com as aplicações via Auto Scaling Groups. Isso garante que o service mesh continue funcionando mesmo com falhas parciais.
O bastion host nas subnets públicas indica um ponto de acesso seguro para administração, enquanto o NAT Gateway permite que instâncias privadas acessem a internet sem ficarem expostas. Já o load balancer e certificados SSL (ACM) cuidam da entrada externa segura na aplicação.
Agora, conceitualmente, o que esse “Service Mesh Standard Solution” resolve? Ele resolve o problema clássico de sistemas distribuídos: comunicação, segurança e observabilidade entre serviços. Em vez de cada aplicação implementar retry, circuit breaker, TLS, logging de rede etc., tudo isso é movido para a camada do mesh.
Isso conecta diretamente com o que você já trabalha em observability. Um service mesh com Consul permite coletar métricas de tráfego entre serviços, latência, erros, throughput, além de aplicar políticas de retry, timeout e failover. Ou seja, ele transforma a rede em algo programável.
Comparando com outras abordagens, isso é semelhante ao que o AWS App Mesh faz, mas o Consul é mais flexível e multi-cloud, enquanto o App Mesh é mais integrado ao ecossistema AWS.
Resumindo de forma direta: o “AWS Service Mesh Standard Solution com Consul” é um padrão arquitetural onde você usa Consul dentro da AWS para criar uma malha de serviços inteligente, segura e observável, rodando sobre VPCs distribuídas, com alta disponibilidade e integração com práticas modernas de microserviços. Ele é uma camada acima da infraestrutura, focada em governar como os serviços conversam entre si em escala.
A melhor arquitetura da AWS para hospedar e implantar um site estático na AWS com CDN, um domínio personalizado e HTTPS usando AWS S3, AWS Route 53, AWS CloudFront e AWS Certificate Manager.
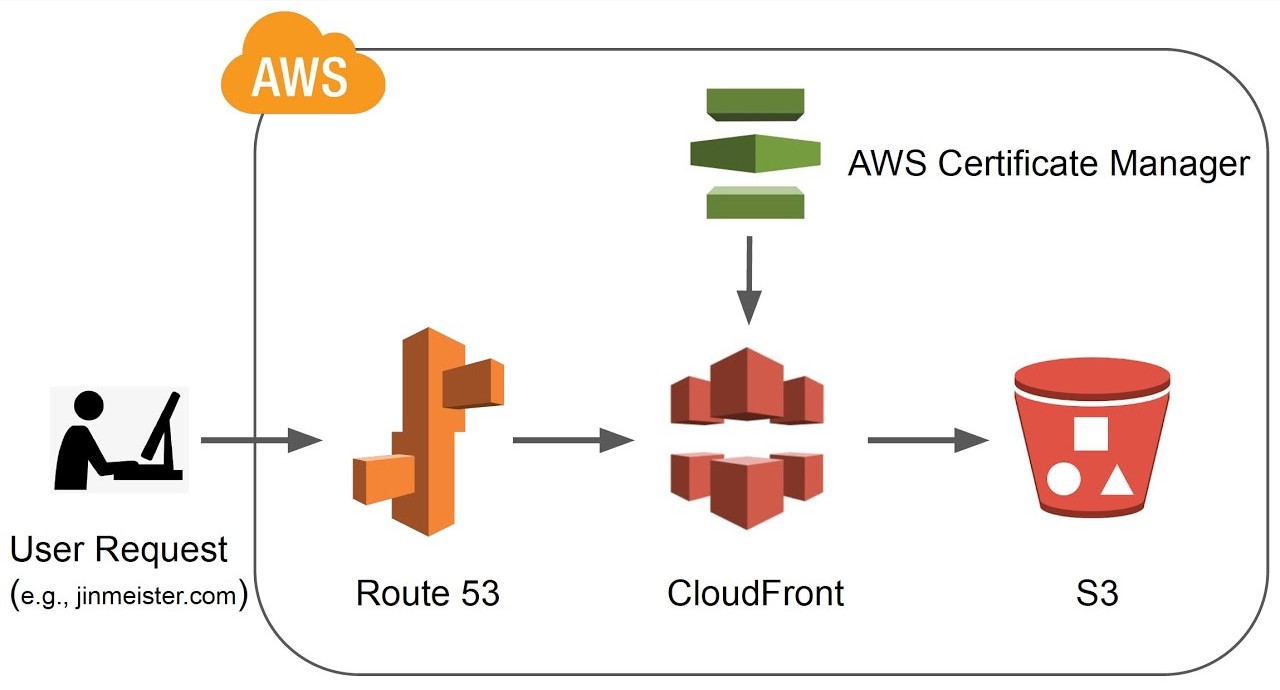 |
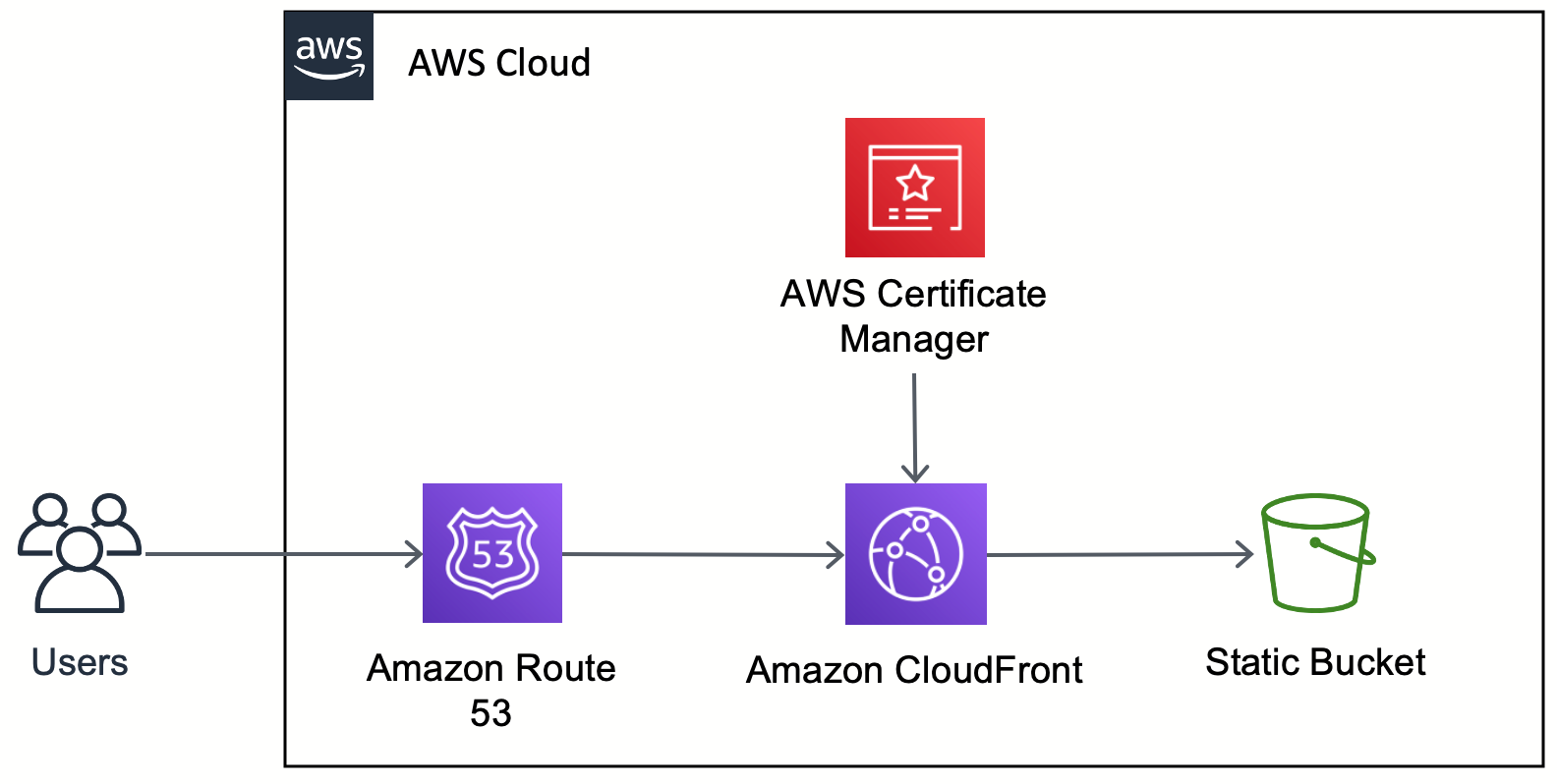 |
Utilizando CI/CD Pipeline: Realizando testes unitários + fazendo build para gerar o diretório ./dist dos arquivos estáticos da aplicação web.
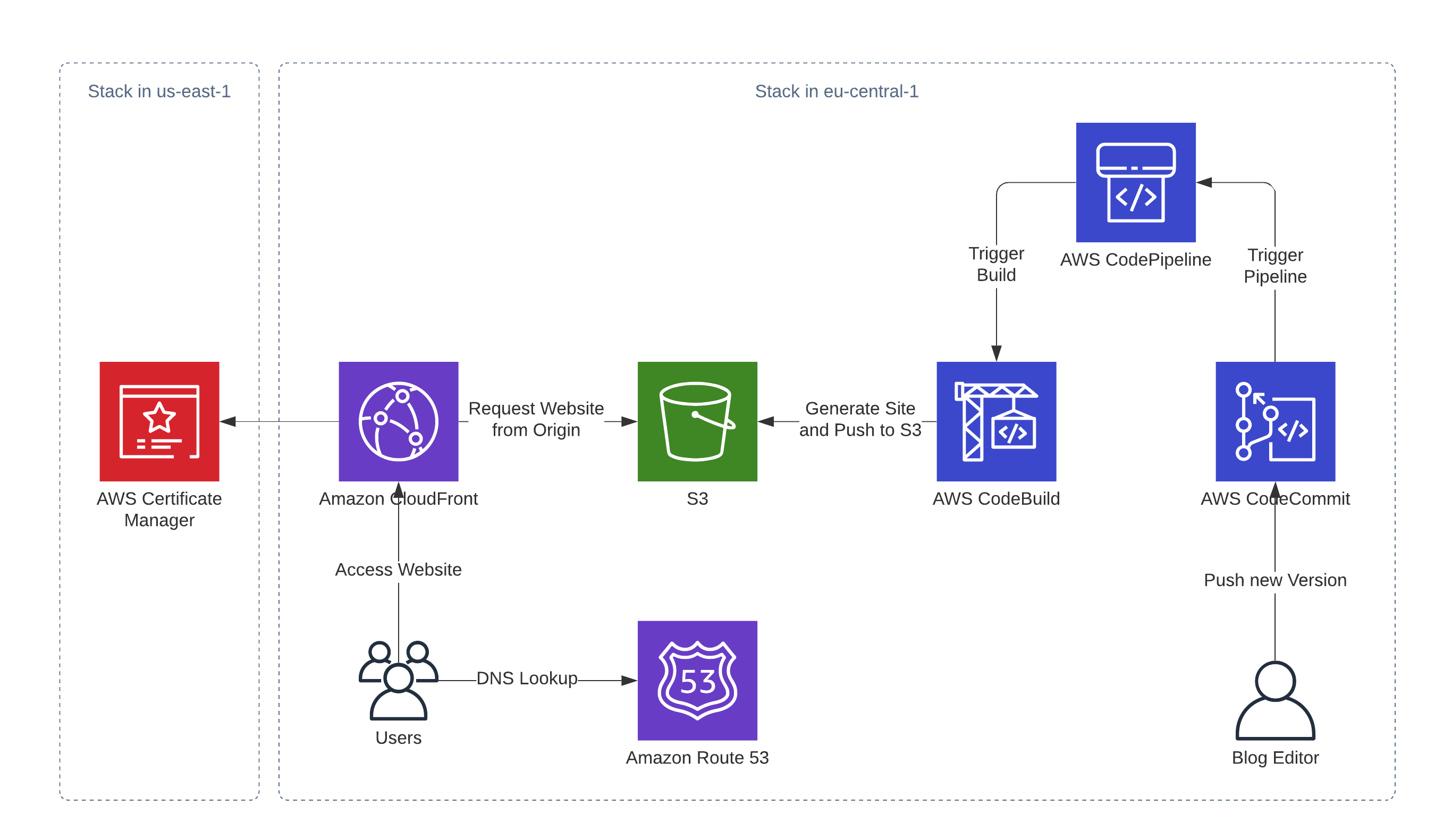 |
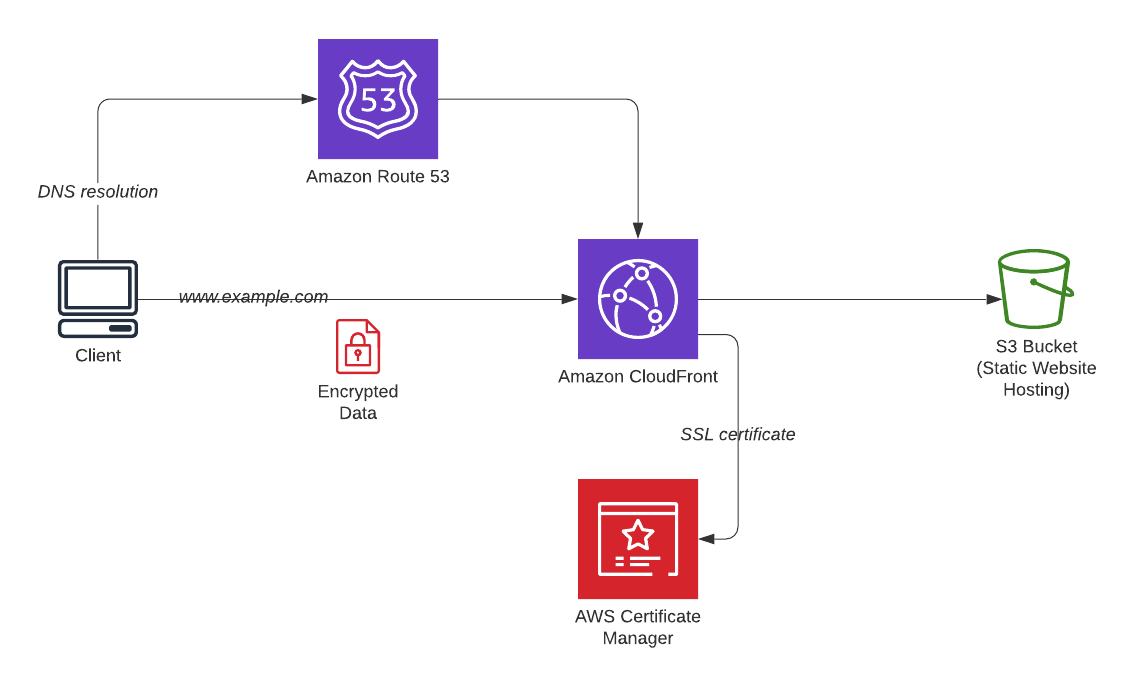 |
Uma visão geral de alto nível de uma arquitetura AWS sem servidor de fato para hospedagem e implantação de micro-frontends mono-repositórios baseados no plugin Module Federation Webpack:

A arquitetura consiste em 3 partes principais:
- Mudanças no código mono-repositório acionando pipelines específicos de implantação.
- Pipelines de implantação criando e implantando artefatos em bundles para direcionar recursos da AWS.
- Infraestrutura de hospedagem globalmente escalável, adaptada para micro-frontends do lado do cliente.

Um pouco sobre a configuração do Mono-repositório: Micro-frontends fazem parte de uma configuração mono-repositório, ou seja, um único repositório com subpastas incluindo aplicativos web independentes, colados juntos pelo plugin Webpack Module Federation e Lerna. Um vislumbre da estrutura dos repositórios pode ser visto abaixo:
Se você for impaciente, pode ver como as micro-frontends são representadas por sistemas de Federação de Módulos na ideia abaixo, que será discutida em detalhes em um futuro próximo.
Resumindo, o código acima nos permite modelar micro-frontends como sistemas que podem ser carregados preguiçosamente como componentes Web no seu app. O truque é injetar dinamicamente cada script de micro-frontend na página do app para que possam ser carregados remotamente pelo app host/shell. Como dito, mais novidades virão no próximo artigo. Por enquanto, vamos analisar as 3 subarquiteturas mencionadas anteriormente.
Gatilhos mono-repositório: O objetivo dessa primeira etapa é capturar mudanças individuais de micro-frontend repositórios e acioná-las para uso posterior por componentes sem servidor.

Desenvolvedores enviam as mudanças para seu micro-frontend pertencente via Github, embora o mesmo possa ser feito em outras plataformas de versionamento bem conhecidas, como o BitBucket. Por meio de um webhook do Github, as alterações são feitas por uma função Lambda exposta como uma API Restful via um ApiGateway. O principal objetivo do Lambda é associar a mudança de código micro-frontend ao pipeline de destino. Um guia manual dessa abordagem pode ser apreciado aqui, enquanto sua implementação no CDK fará parte do próximo artigo.
Pipeline de implantação O objetivo da segunda etapa é garantir que as mudanças individuais no repositório micro-frontend acionem pipelines de código individuais. Isso incentiva a independência da equipe, pois se apenas um micro-frontend for modificado (por exemplo: mfe-app1), queremos acionar apenas seu pipeline relacionado, e não todos os outros.

Uma vez que uma alteração de código é associada, um AWS Code Pipeline é iniciado. Isso inclui quatro etapas principais:
O próprio Code Pipeline, que gerencia a conexão do GitHub e busca o código-fonte associado do GitHub
O Code Build, que constrói o código-fonte receptor em um artefato de build. Como micro-frontends são baseados em JavaScript, eles vão aproveitar o yarn para construí-los em um conjunto de bundles a serem usados na próxima etapa.
O Código Implantado. Essa etapa pega os arquivos agrupados construídos das etapas anteriores e os implanta em um único Serviço de Armazenamento Simples (S3). Cada micro-frontend será armazenado em uma "pasta" (ou chave) independente, para que possam ser implantados individualmente.
A invalidação do cache da construção do código. A última etapa é mais uma etapa de Construção de Código, que garante que o cache do CloudFront seja invalidado toda vez que publicamos e implantamos novos artefatos no S3.
Infraestrutura de hospedagem Por último, mas não menos importante, recursos fundamentais da AWS precisam ser provisionados. O objetivo dessa última etapa é garantir que isso aconteça com uma arquitetura escalável, simples, mas inteligente e confiável.

Com a subarquitetura acima, os usuários finais acessarão a aplicação web por meio de uma distribuição CloudFront protegida por WAF, já que as micro-frontends são aplicações otimizadas para o cliente. O CloudFront se conecta ao bucket privado S3 via uma identidade OAI, garantindo que os dados sejam acessíveis publicamente apenas via CDN e não diretamente do bucket. O CloudFront utiliza uma função Lambda@Edge para despachar corretamente para diferentes origens vindas do único balde.
CDK para governar todos eles Tudo acima será provisionado por meio de uma aplicação CDK que inclui três stacks:
A pilha da fundação. Isso prevê os recursos fundamentais da AWS usados para hospedar o app, incluindo o bucket S3, uma função Lambda@Edge, uma distribuição CloudFront e várias políticas, funções e OAI de IAM para apoiar a privacidade e segurança corretas.
A segunda pilha é implícita porque é criada ao provisionar a função Lambda@Edge via a API Experimental CloudFront CDK, já que precisa implantar o Lambda@Edge em uma região AWS específica (us-east-1 é usado por padrão para todas as funções de borda).
A pilha implantação ci/cd. Sua função é provisionar todos os recursos AWS associados ao ApiGateway e ao Code Pipeline.
 |
 |
Detecção de anomalias (Anomaly Detection) é o processo de identificar padrões em dados que não se encaixam no comportamento esperado. Em outras palavras, ela busca detectar eventos, registros ou tendências incomuns — desvios que podem representar falhas, fraudes, problemas de desempenho, comportamentos suspeitos ou situações críticas que exigem atenção imediata.
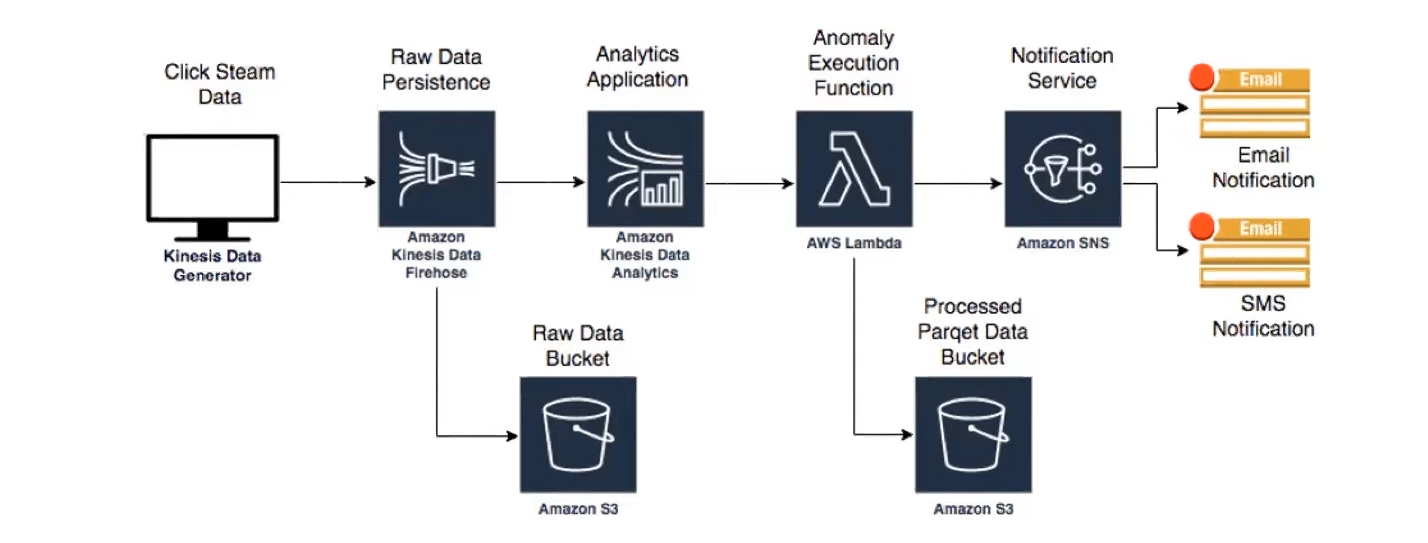 |
 |
No contexto de clickstream (rastreamento de cliques e interações de usuários em tempo real), a detecção de anomalias serve para identificar, por exemplo, acessos fora do padrão, picos suspeitos de tráfego, bots gerando requisições falsas, quedas bruscas de engajamento ou comportamento anormal em campanhas de marketing digital.
Em resumo, essa solução da AWS representa o estado da arte em observabilidade e monitoramento inteligente em tempo real, permitindo que empresas tomem decisões imediatas com base em detecções automáticas de eventos fora do padrão, sem precisar investir em grandes clusters locais ou arquiteturas rígidas.
A melhor solução de arquitetura AWS para detectar anomalias em clickstream em tempo real com Amazon Kinesis Analytics. As implantações locais de Apache Hadoop, Spark e armazenamento costumam ter altos custos, configurações rígidas e escala limitada.
A migração de análises, processamento de dados (ETL) e cargas de trabalho de ciência de dados para Clouds como a AWS, incluindo Amazon EMR, Glue, Kinesis, etc., ajuda a economizar custos, aumentar a agilidade e melhorar o desempenho em escala.

Solução para criação de APIs e microserviços totalmente serverless na nuvem da AWS através de funções lambdas, AWS API Gateway e DynamoDB.
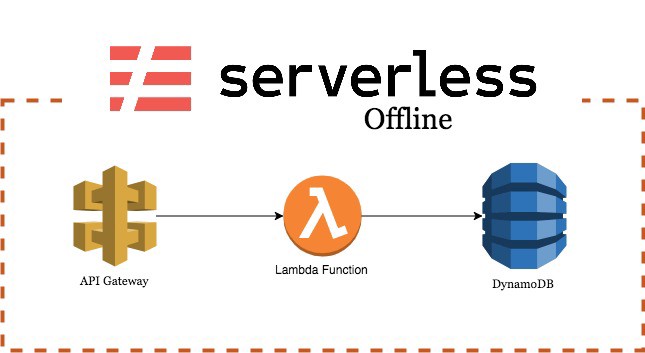 |
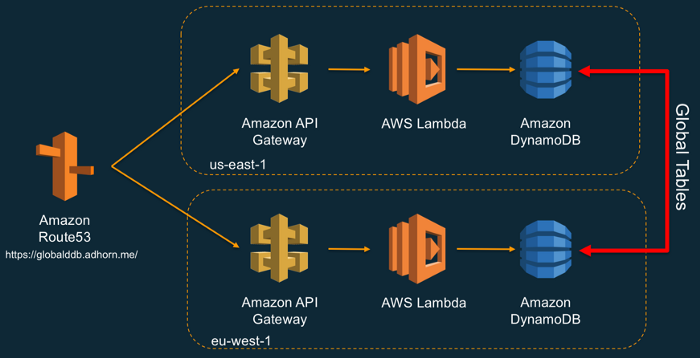 |
Case Studies:
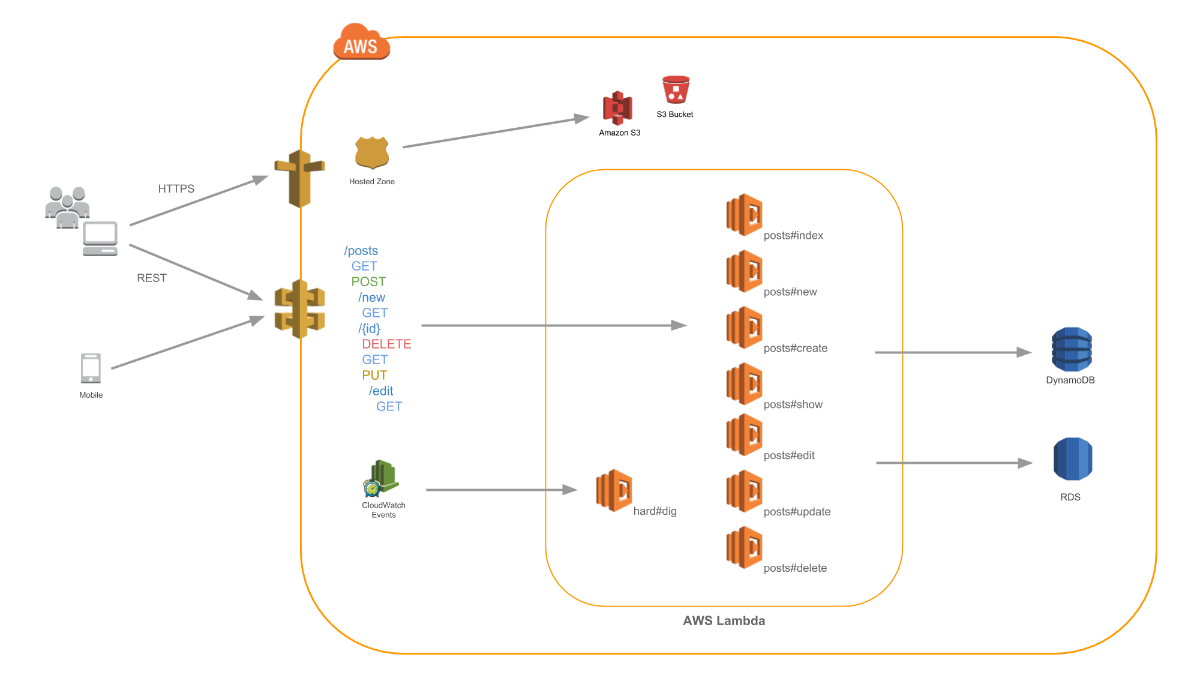
CI/CD Pipeline:

Microservices:

EDA - Event-Driven Architecture pattern:

E se criassemos uma Web Application do zero sem precisar de um servidor dedicado para o front-end e back-end, somente usando serverless. Isso é possível e viável? Claro que sim!
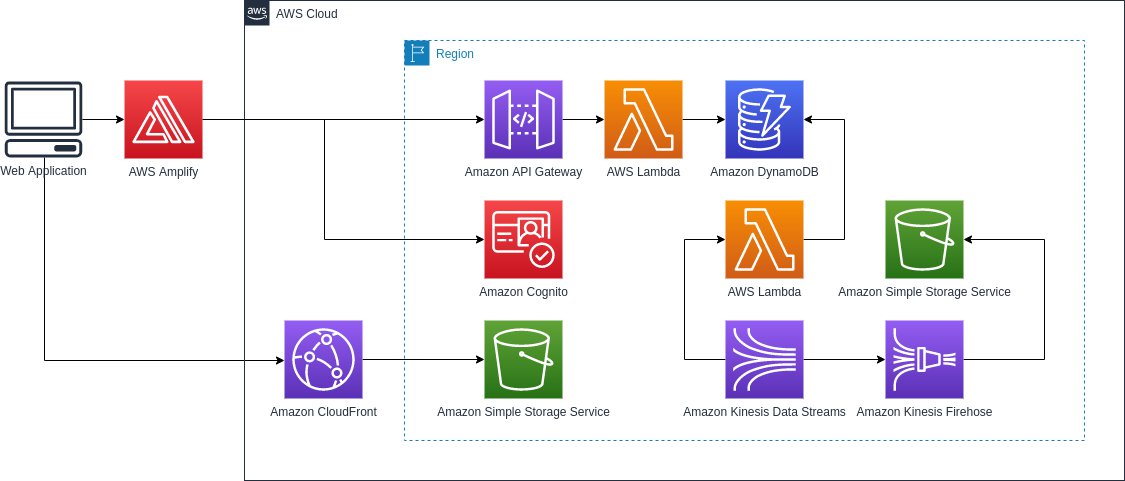
Isso não só é possível como já é uma abordagem bem consolidada hoje — e o diagrama representa exatamente esse tipo de arquitetura. Construir uma Web Application 100% serverless significa basicamente eliminar a necessidade de gerenciar servidores tradicionais, tanto no front-end quanto no back-end, e delegar toda a execução para serviços gerenciados na nuvem, como os da Amazon Web Services.
No front-end, em vez de um servidor web clássico (como Nginx ou Apache), você pode usar algo como AWS Amplify ou diretamente Amazon S3 para hospedar arquivos estáticos (HTML, CSS, JS), com distribuição global via Amazon CloudFront. Isso já resolve completamente a camada de entrega da interface sem precisar de um servidor rodando 24/7.
No back-end, a ideia é substituir servidores por funções sob demanda usando AWS Lambda. Em vez de manter uma API rodando continuamente, você expõe endpoints via Amazon API Gateway, que acionam funções Lambda apenas quando necessário. Isso muda completamente o modelo mental: você sai de um sistema baseado em processos contínuos para um sistema orientado a eventos.
O armazenamento também segue essa lógica. Em vez de bancos tradicionais gerenciados manualmente, você usa serviços como Amazon DynamoDB para dados estruturados e Amazon S3 para arquivos. Para autenticação, entra o Amazon Cognito, eliminando a necessidade de implementar login, JWT, refresh token etc. manualmente.
E quando você precisa de processamento em tempo real ou pipelines de dados, entram serviços como Amazon Kinesis e Firehose, que lidam com ingestão e entrega de dados em escala sem que você precise gerenciar infraestrutura.
Agora, sobre viabilidade: sim, é extremamente viável — principalmente para aplicações modernas, escaláveis e orientadas a eventos. Esse modelo traz vantagens muito fortes como escalabilidade automática, alta disponibilidade, pagamento sob demanda e menor overhead operacional. Você praticamente elimina a preocupação com provisionamento de servidores, patches de sistema operacional e balanceamento de carga.

Warning
Mas aqui entra a parte mais importante, e onde muita gente se engana: serverless não é uma bala de prata. Ele traz novos desafios. Latência de cold start em Lambdas pode impactar performance em alguns cenários, principalmente APIs síncronas. Debug e observabilidade ficam mais complexos, porque você não tem um servidor único, mas sim dezenas ou centenas de funções distribuídas. O acoplamento com o provedor (vendor lock-in) também aumenta bastante — sair de AWS depois pode ser caro e trabalhoso.
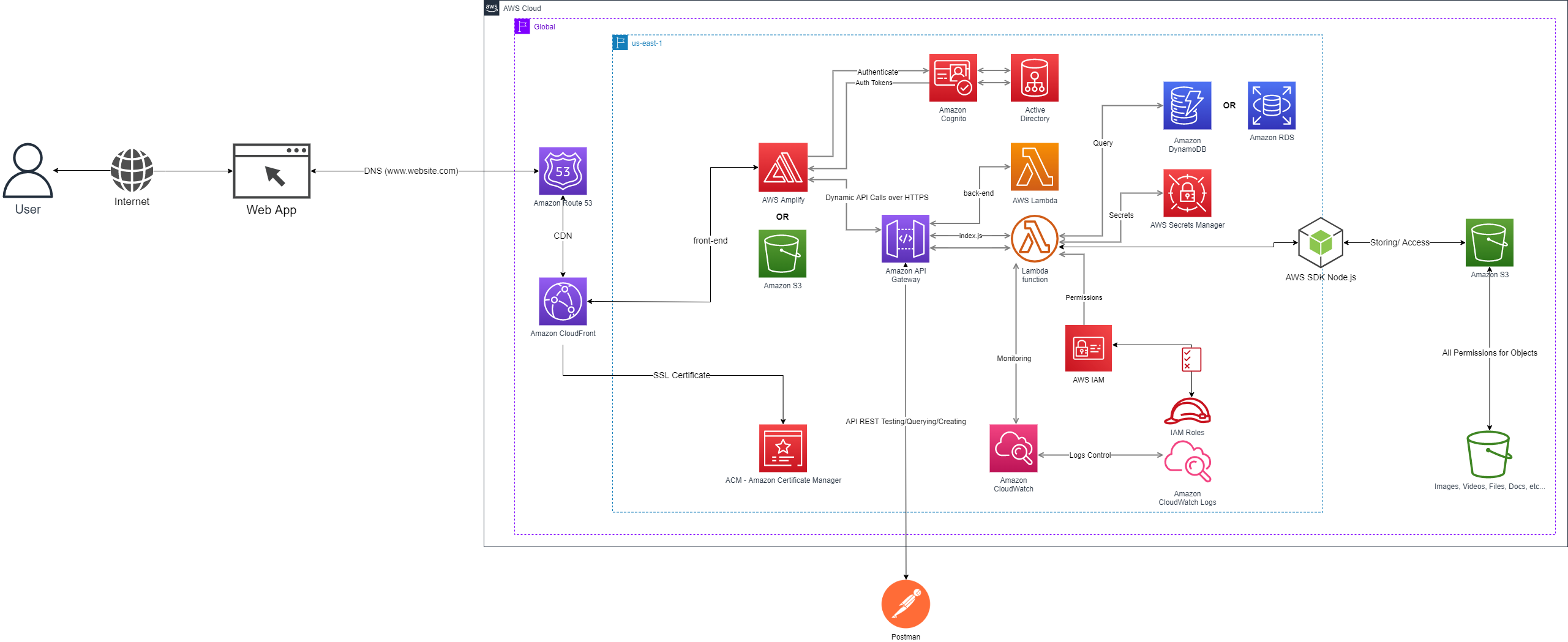
Além disso, nem todo tipo de aplicação se encaixa bem nesse modelo. Sistemas com processamento contínuo pesado, conexões persistentes (como WebSockets complexos) ou workloads muito previsíveis às vezes ficam mais baratos e simples com containers ou servidores tradicionais. Já aplicações event-driven, APIs REST/GraphQL, sistemas com picos de acesso e produtos em crescimento se beneficiam muito de serverless.
No seu contexto — considerando que você já trabalha com observabilidade, pipelines e integrações — essa arquitetura faz muito sentido. Ela conversa diretamente com conceitos que você já usa, como eventos, filas, processamento assíncrono e escalabilidade horizontal. Na prática, serverless é quase uma evolução natural de arquiteturas baseadas em microserviços e eventos, só que com menos preocupação com infraestrutura.

Resumindo de forma direta: dá pra construir uma aplicação completa sem servidor dedicado usando serverless, isso já é realidade no mercado, é altamente viável e escalável — mas exige uma mudança de mentalidade arquitetural e traz trade-offs que precisam ser bem entendidos antes de adotar.
Uma solução para criar chatbots personalizados no Slack, para enviar lembretes ou notificações das infraestruturas da AWS, uma observabilidade rápida. É importante conter a nomenclatura (sufixo + prefixo) da infraestrutura.
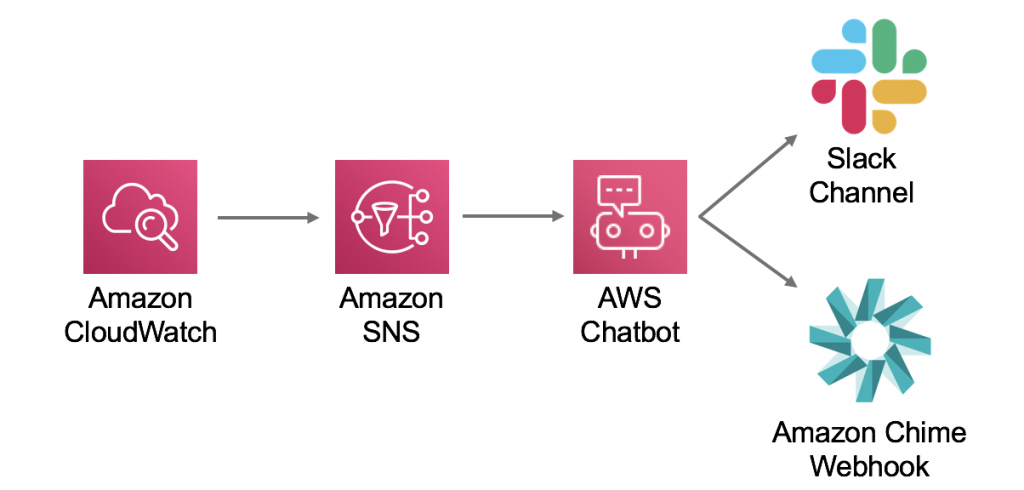
Poderíamos pra fazer o mesmo processo utilizando Lambda functions + Webhooks, mas esse processo é mais inerente na maioria dos casos de uso por ser mais prático.

Esse diagrama mostra parte da arquitetura de telemetria e eventos em tempo real usada pelo Disney+ Hotstar, e o termo “Hotstar Capture Emojis” se refere a um recurso de captura de reações dos usuários (por exemplo, emojis ou interações durante transmissões ao vivo) que o app coleta, processa e distribui em tempo real.
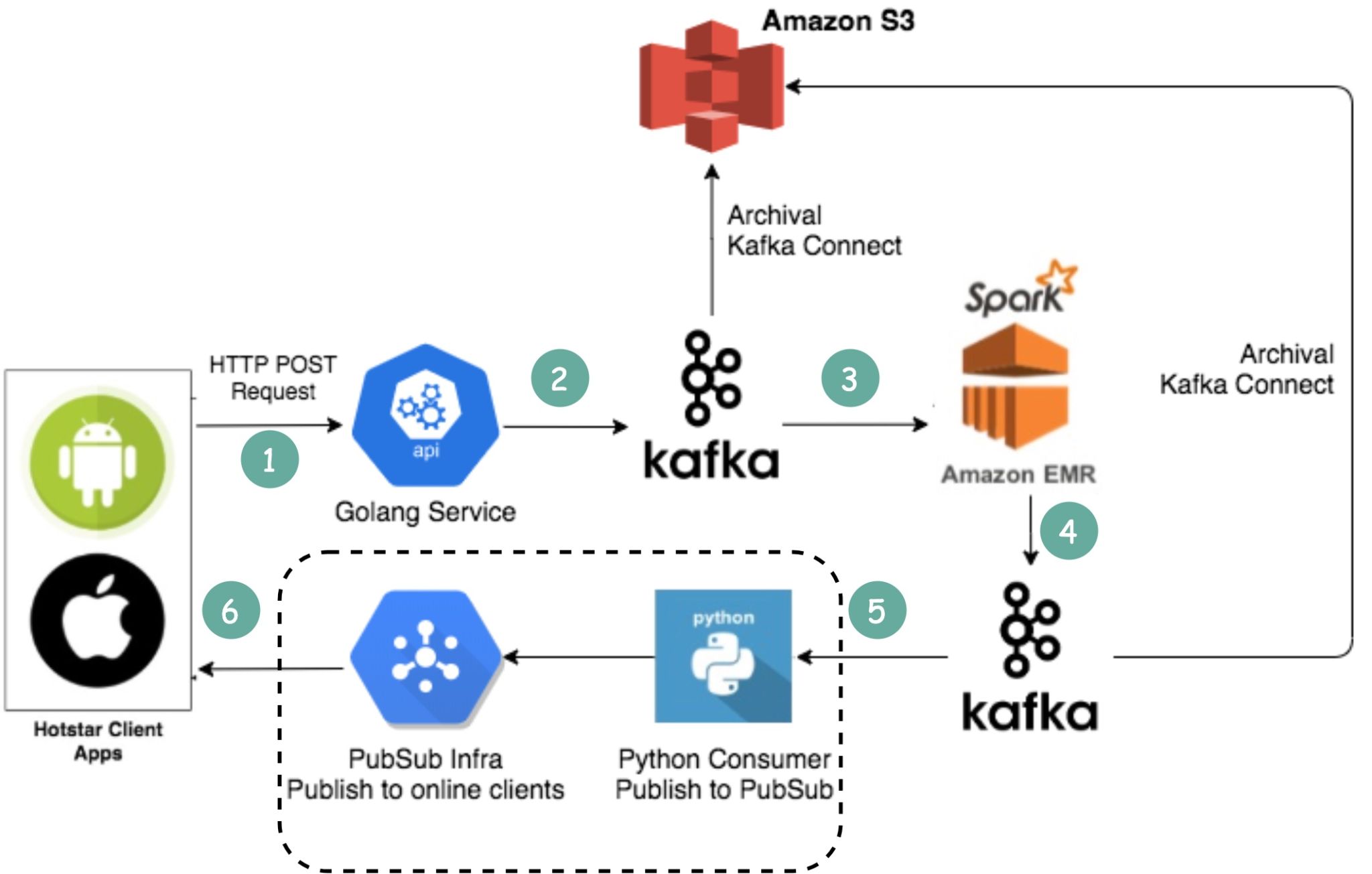
É um caso prático muito interessante de integração entre MLOps, streaming de dados e engenharia de software em larga escala, onde Golang, Kafka, Python, Spark e AWS trabalham em conjunto para manter uma experiência fluida e interativa.
Explicando com mais clareza: o Disney+ Hotstar (plataforma de streaming muito popular na Índia e pertencente à Disney) oferece eventos de streaming ao vivo, como partidas de críquete e shows. Durante essas transmissões, os usuários podem enviar emojis de reação (por exemplo, ❤️, 👏, 🔥, 😮) enquanto assistem. Esses emojis são capturados instantaneamente no aplicativo, enviados via API, processados em um pipeline de dados e retransmitidos para outros espectadores — criando uma experiência social e interativa.
No contexto da imagem, esse fluxo funciona da seguinte forma:
- 1️⃣ O aplicativo do Hotstar (Android/iOS) envia via HTTP POST as reações (emojis, comentários, curtidas) para o serviço em Golang.
- 2️⃣ Esse serviço publica os dados no Apache Kafka, um sistema de mensageria distribuído de alta performance.
- 3️⃣ O Amazon EMR com Apache Spark consome esses dados, processa e agrega as informações (como contagem de reações por segundo, tipo de emoji mais usado etc.).
- 4️⃣ Esses resultados podem ser armazenados no Amazon S3 para arquivamento ou análises posteriores.
- 5️⃣ Outro consumer em Python consome os eventos do Kafka e publica em uma infraestrutura Pub/Sub.
- 6️⃣ Essa camada Pub/Sub envia os dados processados de volta aos clientes online, para que todos vejam, em tempo real, os emojis e reações da comunidade na tela — sem atrasos perceptíveis.
Em outras palavras, o “Hotstar Capture Emojis” é o nome interno (ou informal) dado ao sistema de coleta e distribuição de reações em tempo real dos usuários dentro da plataforma. Ele combina componentes de stream processing, event-driven architecture e infraestrutura escalável em nuvem, garantindo que milhões de usuários possam reagir simultaneamente e ver o resultado instantaneamente, mesmo em transmissões massivas.