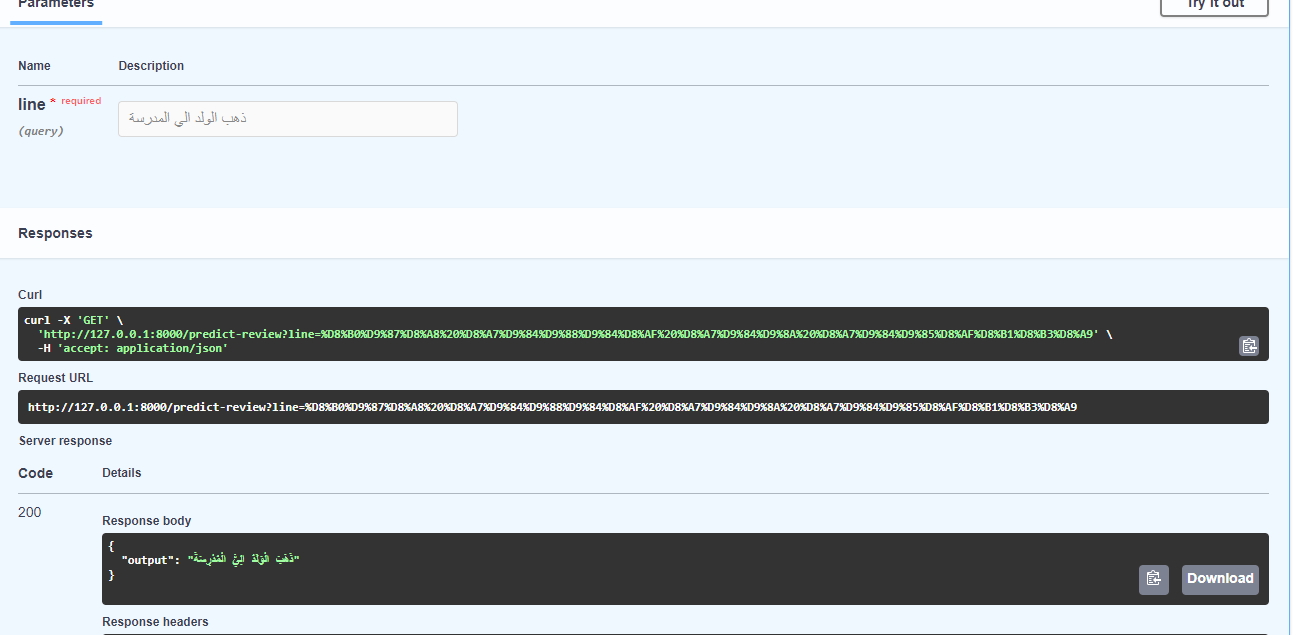
{kind=link}
{kind=link}
{kind=link}
In this project, we aim to take a deep learning approach to the problem of Arabic Diacritization. Our first milestone is to reproduce the work by the results by Fadel et al. [1], using an RNN model with Bidirectional LSTM layers. Next, we will attempt to improve the model through tuning hyperparameters.
Two measures have been developed to measure the accuracy of a diacritization system. The first is the Diacritic Error Rate (DER) which is the percentage of misclassified Arabic characters whether the character has 0, 1, or 2 diacritics. The other is Word Error Rate (WER) which is the percentage of words which have at least one misclassified Arabic character. We generally aim to reach a maximum DER of 3% and a maximum WER of 8%
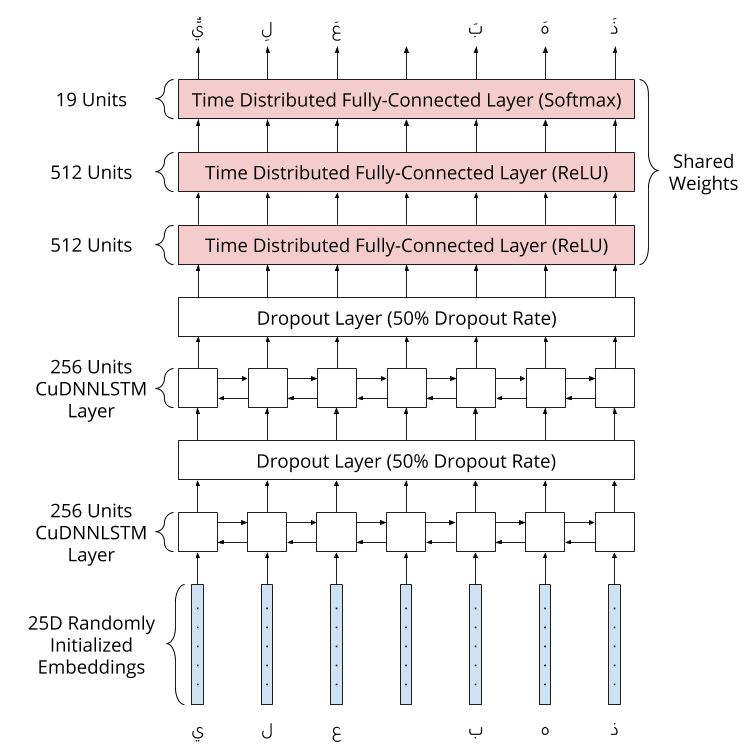
The used CuDDLSTM layers are bidirectional LTSM layers, where CuDDLTSM is a fast LSTM implementation backed by CuDNN and runable on GPU with the tensorflow backend.
A bidirectional LTSM runs inputs in two ways, one from past to future and one from future to past, allowing the model to preserve information from both past and future.
[1] Fadel, Ali, Ibraheem Tuffaha, Bara' Al-Jawarneh and M. Al-Ayyoub, “Neural Arabic Text Diacritization: State of the Art Results and a Novel Approach for Machine Translation.” WAT@EMNLP-IJCNL, 2019.