
![]()
Excalibur Hash is a high-speed hash map and hash set, ideal for performance-critical uses like video games. Its design focuses on being friendly to the CPU cache, making it very efficient and fast. It uses an open addressing hash table and manages removed items with a method called tombstones.
Engineered for ease of use, Excalibur Hash, in the vast majority of cases (99%), serves as a seamless, drop-in alternative to std::unordered_map. However, it's important to note that Excalibur Hash does not guarantee stable addressing. So, if your project needs to hold direct pointers to the keys or values, Excalibur Hash might not work as you expect. It also offers improved iterator design, which is not 100% compatible with STL iterators and might require some minor code changes. That aside, its design and efficiency make it a great choice for applications where speed is crucial.
- Extremely fast (see Performance section for details)
- CPU cache friendly
- Built-in configurable inline storage
- Can either work as a map (key, value) or as a set (keys only)
- Header-only library
- Standard container-like interface
- Support for custom key types via
KeyInfo<T>specialization
- C++17 compatible compiler
- Supported compilers: MSVC, GCC, Clang
- Platforms: Windows, Linux, macOS
ExcaliburHash achieves its exceptional performance through several carefully engineered design decisions and optimizations:
Open Addressing with Linear Probing
- Uses a single contiguous array instead of separate chaining, providing excellent cache locality
- Linear probing minimizes memory indirection and maximizes CPU cache efficiency
- No pointer chasing or dynamic memory allocation for individual elements
Tombstone Management
- Deleted elements are marked as "tombstones" rather than shifting elements
- Maintains stable iteration order and prevents expensive rehashing on deletions
- Smart load factor calculation includes tombstones to prevent performance degradation
rehash()method available to clean up tombstones when needed
Configurable Inline Storage
- Small hash tables store elements directly within the object (no heap allocation)
- Default inline storage for 1 element eliminates malloc/free overhead for small maps
- Configurable via template parameter:
HashTable<K,V,64>for 64 inline elements - Seamlessly transitions to heap allocation when capacity is exceeded
Cache-Friendly Design
- Power-of-2 bucket sizing enables fast modulo operations using bit masking
- Contiguous memory layout maximizes cache line utilization
- Elements stored in-place with proper alignment for optimal memory access
Advanced Load Factor Management
- Maintains 75% load factor (including tombstones) for optimal performance
- Uses bit shifts for fast threshold calculation:
(buckets >> 1) + (buckets >> 2) + 1 - Prevents pathological cases where tombstones degrade lookup performance
- Automatic growth by 2x when threshold is exceeded
High-Quality Hash Function
- Uses WyHash algorithm, one of the fastest non-cryptographic hash functions
- Platform-optimized implementation using compiler intrinsics
- Multiplier constants derived from research (https://arxiv.org/abs/2001.05304)
- Excellent distribution properties minimize clustering
Template Metaprogramming
- Single implementation for both const/non-const variants using
std::conditional_t - Eliminates code duplication while maintaining type safety
- Zero-cost abstractions for different iterator types
- Compile-time feature detection for optimal code paths
Branch Prediction Friendly
- Optimizes common cases (successful lookups, non-full tables)
- Helps CPU branch predictor make better decisions
Memory Access Patterns
__restrictkeywords inform compiler about non-aliasing pointers- Enables aggressive compiler optimizations and vectorization
- Aligned memory allocation for SIMD-friendly access patterns
KeyInfo Specialization
- Type traits system for custom key types
- Defines empty/tombstone values and hash/equality functions
- Compile-time customization without runtime overhead
- Built-in optimized implementations for common types
ExcaliburHash takes a fundamentally different approach to iteration compared to standard library containers, prioritizing clarity, performance, and true genericity between maps and sets.
Default Iterator Behavior: Keys First
Excalibur::HashMap<int, std::string> map;
// Default iteration - keys only (different from STL!)
for (const auto& key : map) {
// 'key' is an int, not a pair
std::cout << "Key: " << key << std::endl;
}
// Compare with STL:
std::unordered_map<int, std::string> stdMap;
for (const auto& pair : stdMap) {
// 'pair' is std::pair<const int, std::string>
std::cout << "Key: " << pair.first << std::endl;
}Three Specialized Iterator Types
ExcaliburHash provides three distinct iterator types for different use cases:
Excalibur::HashMap<int, std::string> map;
// 1. Key-only iteration (IteratorK)
for (const auto& key : map.keys()) {
std::cout << "Key: " << key << std::endl;
}
// 2. Value-only iteration (IteratorV) - hash maps only
for (auto& value : map.values()) {
value += "_modified";
}
// 3. Key-value iteration (IteratorKV) - hash maps only
for (const auto& item : map.items()) {
std::cout << "Key: " << item.key() << ", Value: " << item.value() << std::endl;
}Python-Inspired Design
This approach mirrors Python's dictionary iteration, which many developers find intuitive:
# Python dictionaries
for key in my_dict.keys(): # Keys only
for value in my_dict.values(): # Values only
for key, value in my_dict.items(): # Key-value pairsWhy This Design?
1. Intent-Driven API
map.keys()clearly expresses "I want to iterate over keys"map.values()clearly expresses "I want to iterate over values"map.items()clearly expresses "I want both keys and values"
2. Semantic Clarity
item.key()anditem.value()are self-documenting- No confusion about
.firstvs.secondlike STL pairs - Prevents common bugs from mixing up pair members
3. True Map/Set Genericity
The most important benefit: the same code works for both maps and sets:
template<typename Container>
void process_keys(const Container& container) {
// Same code works for both maps and sets!
for (const auto& key : container) { // Always iterates keys
std::cout << key << std::endl;
}
}
// Usage:
Excalibur::HashMap<int, std::string> map; // Key-value container
Excalibur::HashSet<int> set; // Key-only container
process_keys(map); // ✅ Works
process_keys(set); // ✅ Works - same exact code!STL Cannot Achieve This
template<typename Container>
void process_keys_stl(const Container& container) {
for (const auto& item : container) {
// ❌ Breaks! item.first doesn't exist for std::set
std::cout << item.first << std::endl;
}
}Iterator Availability Matrix
The type system automatically provides appropriate iterators based on container type:
// Hash Map: HashTable<Key, Value>
map.keys() // ✅ Available
map.values() // ✅ Available
map.items() // ✅ Available
// Hash Set: HashTable<Key, std::nullptr_t>
set.keys() // ✅ Available
set.values() // ❌ Compile error - no values in sets
set.items() // ❌ Compile error - no key-value pairs in setsThis design enables writing truly generic algorithms that work across both container types without runtime checks, template specialization, or different APIs. The type system enforces correctness at compile time while maintaining optimal performance.
The combination of these optimizations results in a hash table that often outperforms std::unordered_map by 2-10x in real-world scenarios while maintaining a familiar API.
In this section, you can see a performance comparison against a few popular hash table implementations. This comparison will show their speed and efficiency, helping you understand which hash table might work best for your project.
Unless otherwise stated, all tests were run using the following configuration
OS: Windows 11 Pro (22621.4317)
CPU: Intel i9-12900K
RAM: 128Gb
Compiled in the Release mode using VS2022 (19.39.33520)
absl::flat_hash_map
boost::unordered_map
boost::unordered_flat_map
ska::flat_hash_map
ska::unordered_map
folly::F14ValueMap
llvm::DenseMap
Luau::DenseHashMap
phmap::flat_hash_map
tsl::robin_map
google::dense_hash_map
std::unordered_map
Excalibur::HashTable
Create and immediatly delete 300,000 hash tables on the stack, using a 'heavyweight' object as the value. This test quickly shows which hash map implementations 'cheat' by creating many key/value pairs in advance.
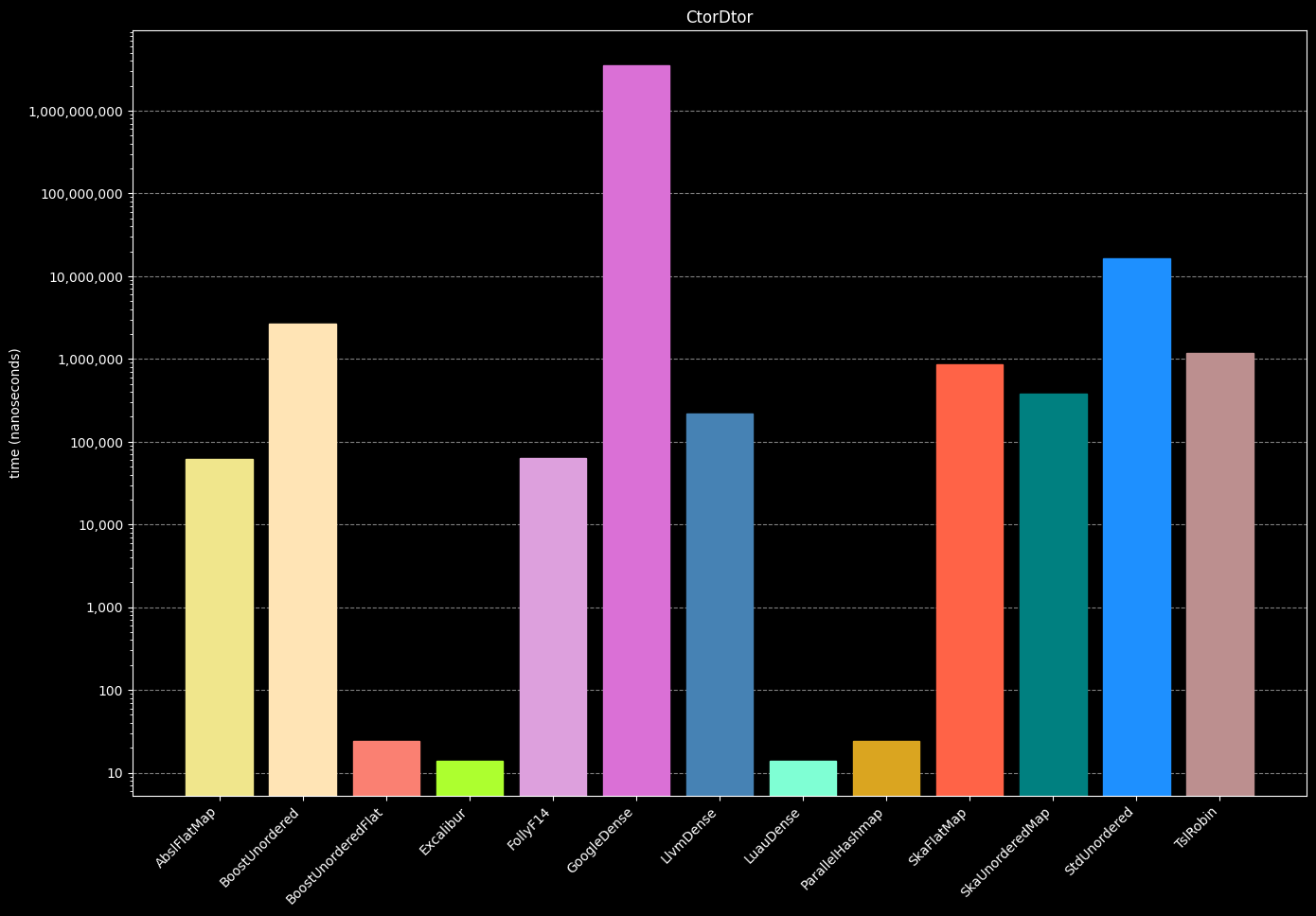
- Create a hash table
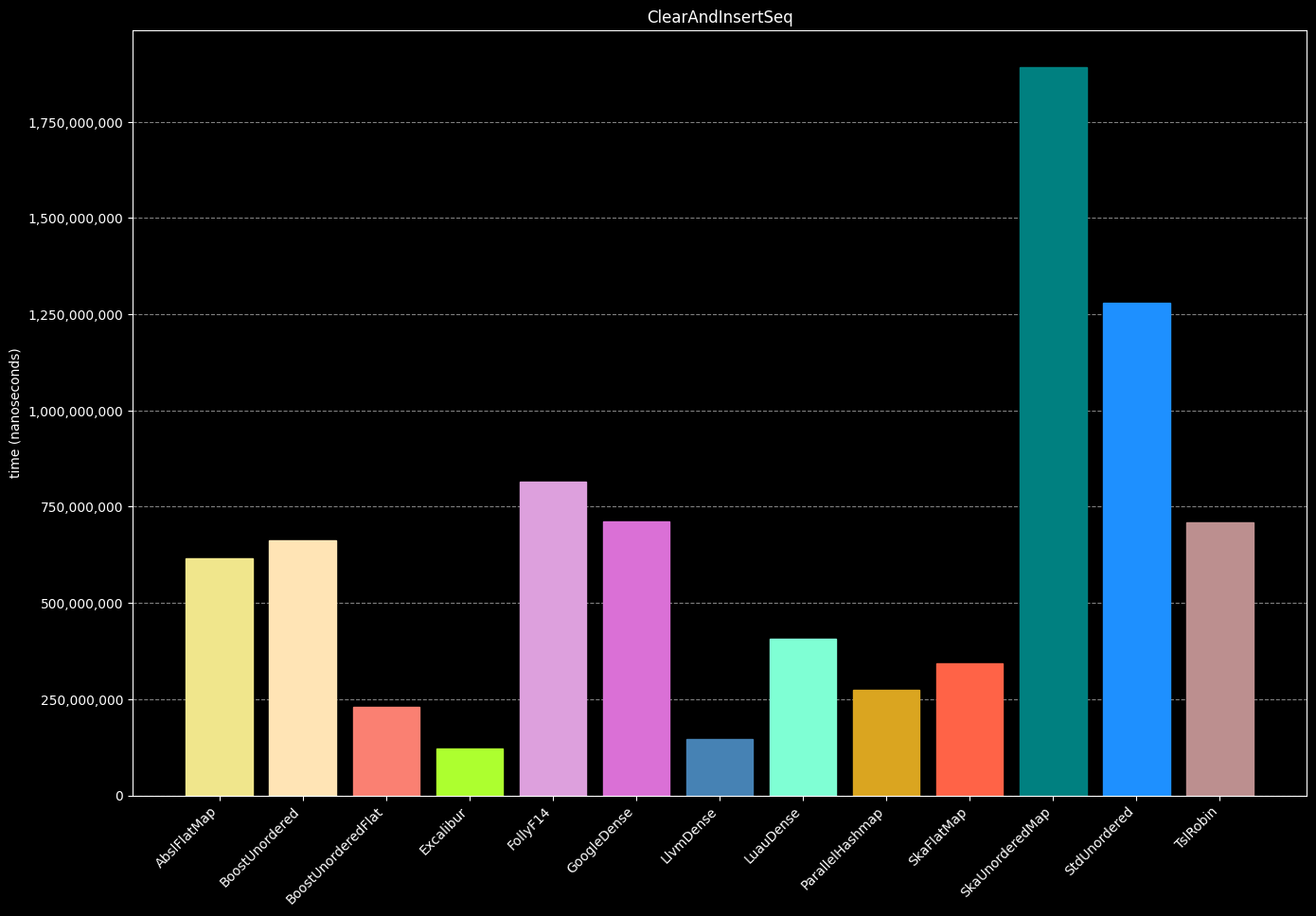
- Clear the hash table
- Insert 599,999 sequential values
- Repeat steps 2-3 (25 times)
- Destroy the hash table
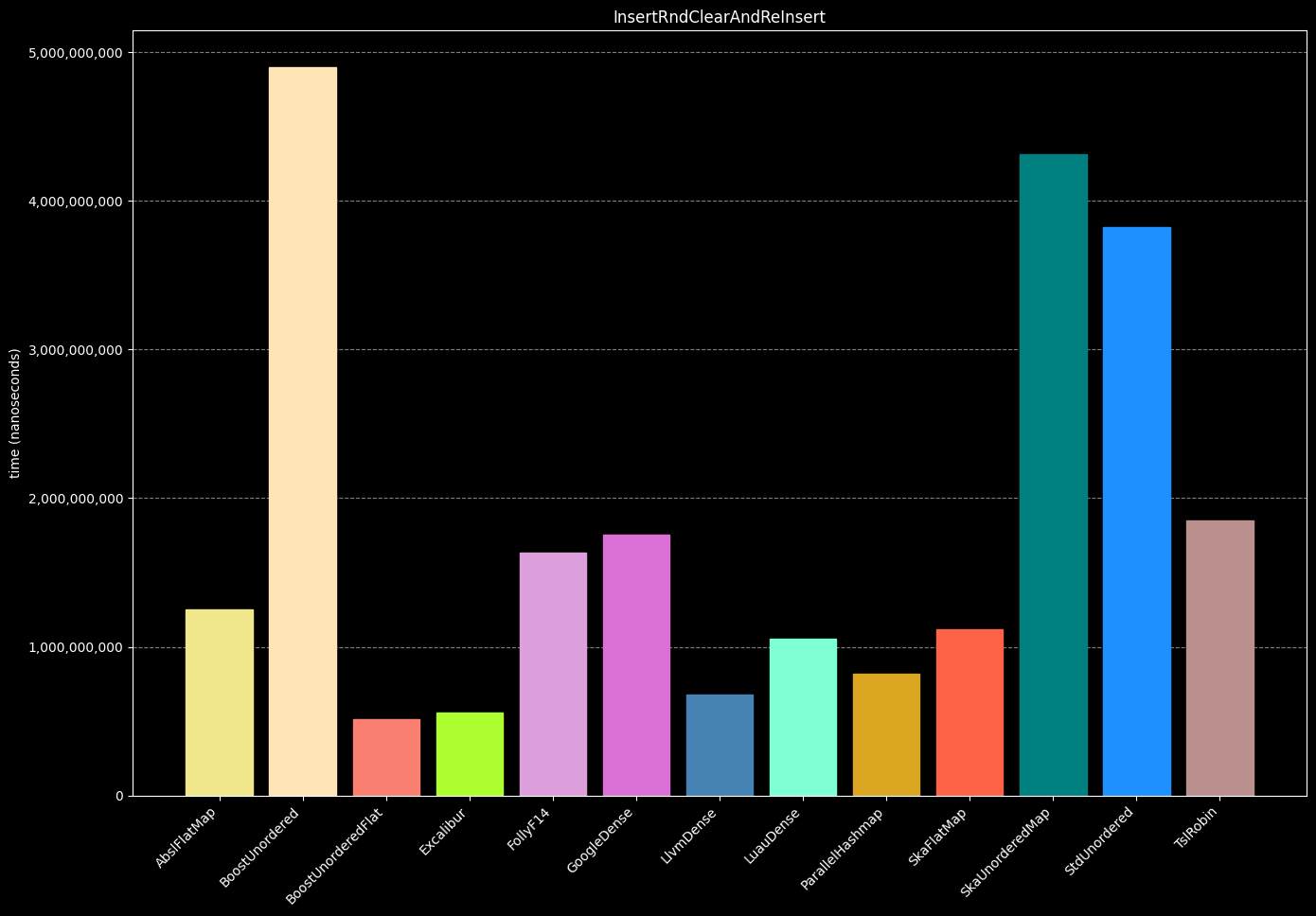
- Create a hash table
- Insert 1,000,000 unique random int numbers
- Clear the hash table
- Reinsert 1,000,000 unique random int numbers into the same cleared map.
- Destroy the hash table
- Repeat steps 1-5 (10 times)
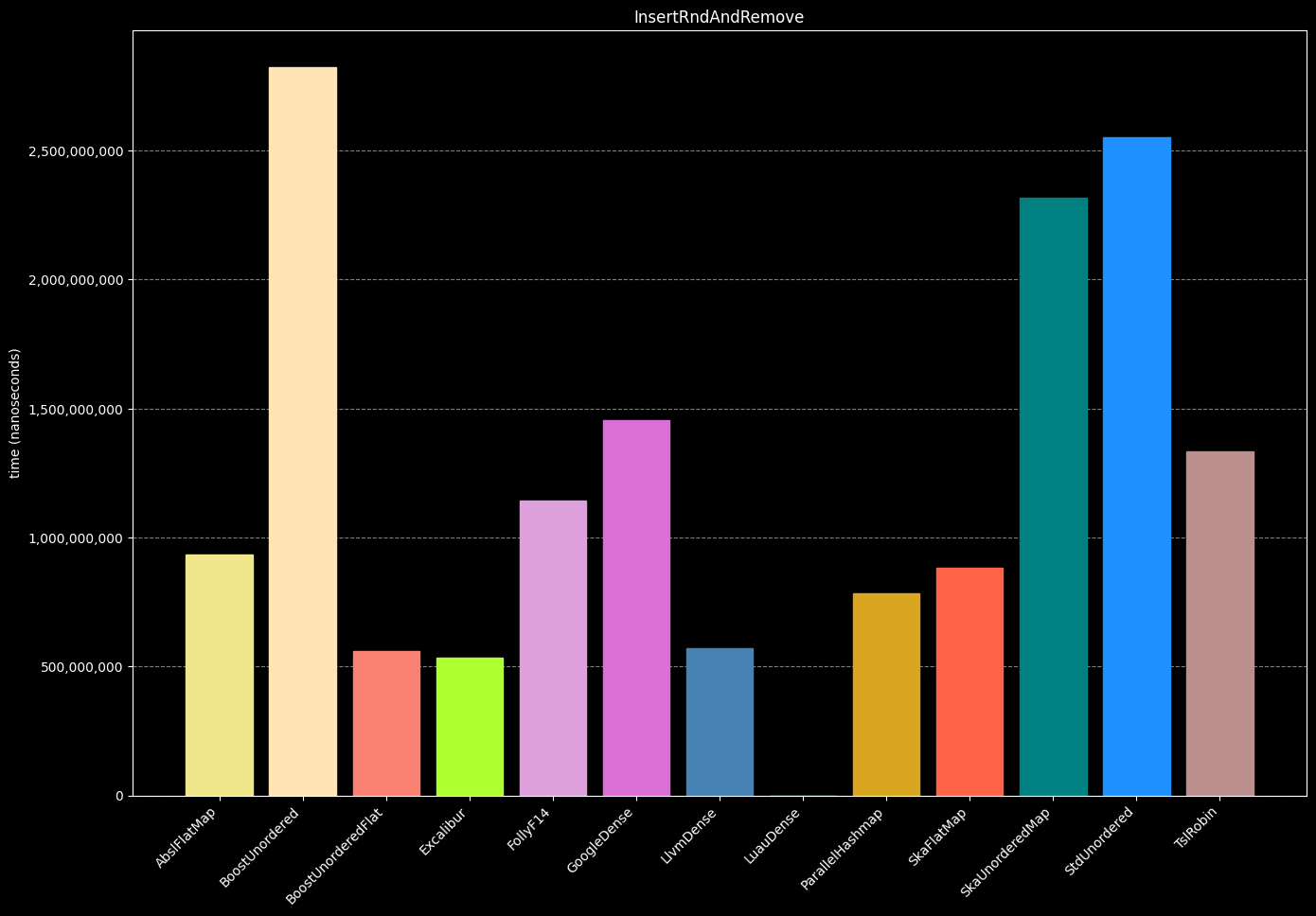
- Create a hash table
- Insert 1,000,000 unique random int numbers
- Remove all of the inserted entries one by one until the map is empty again.
- Destroy the hash table
- Repeat steps 1-4 (10 times)
- Create a hash table
- Insert a single key/value int the hash table
- Destroy the hash table
- Repeat steps 1-3 (300,000 times)
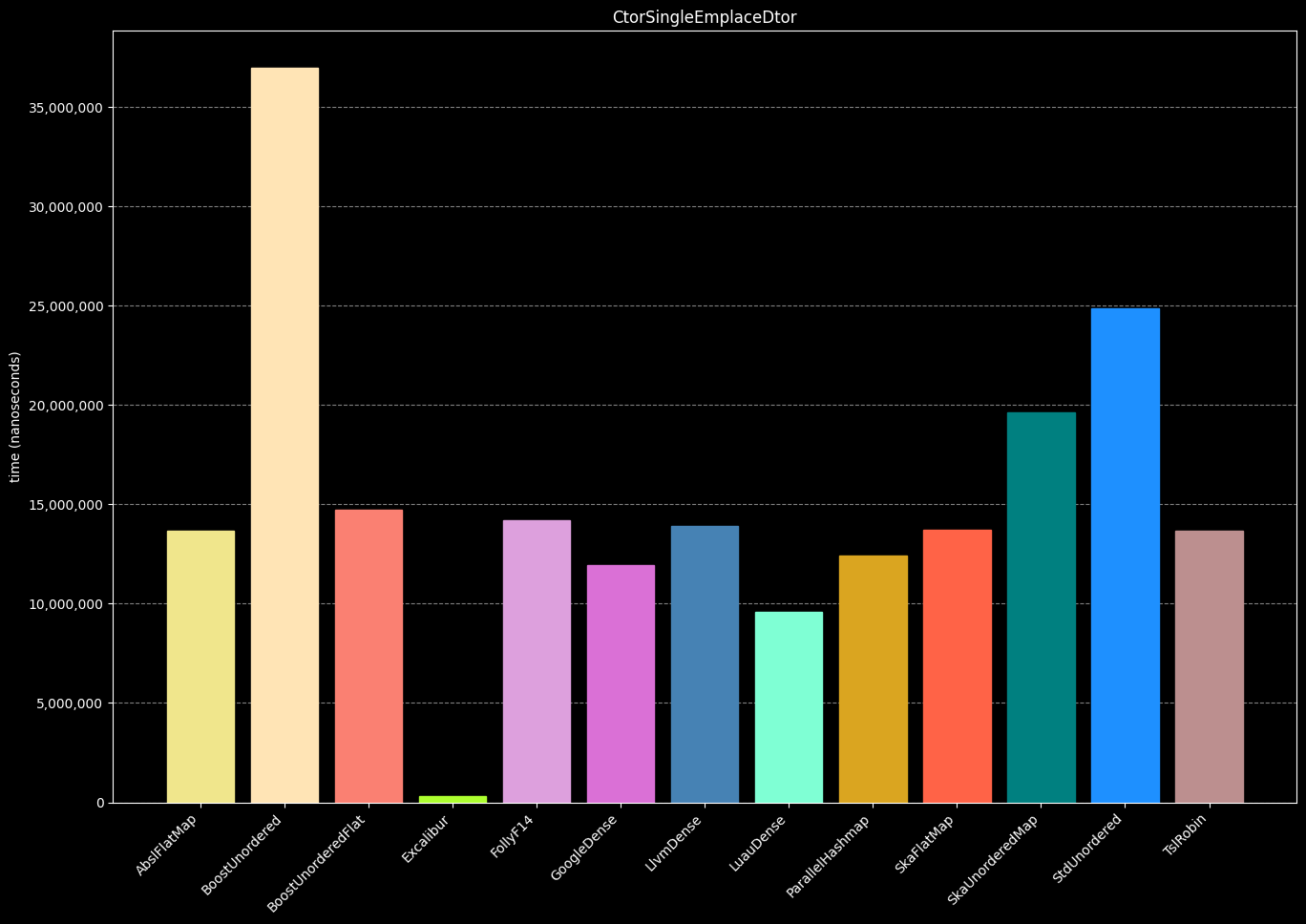
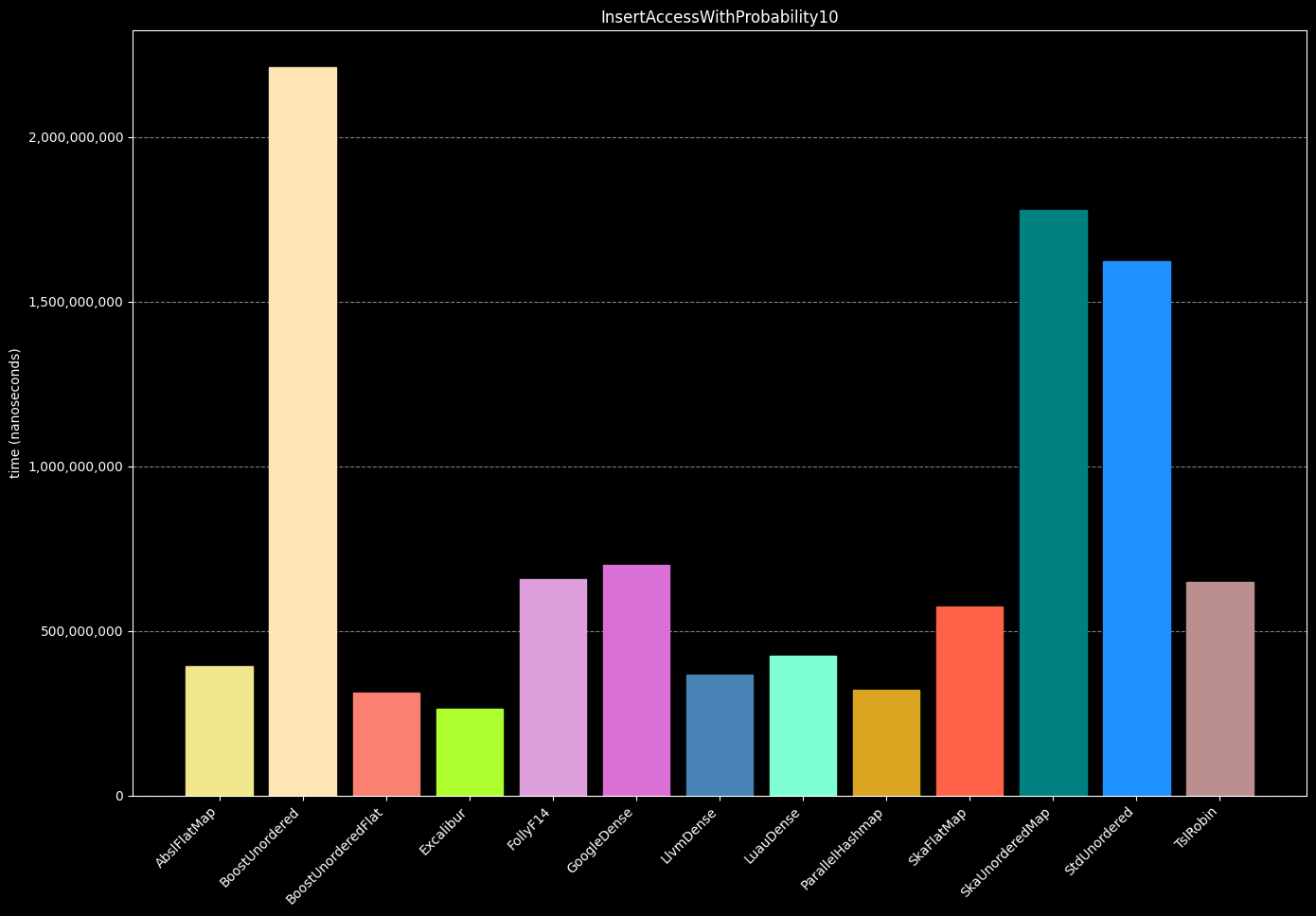
- Create a hash table
- Insert or increment 1,000,000 values where 10% of keys are duplicates (10% of operations will be modifications and 90% will be insertions)
- Destroy the hash table
- Repeat steps 1-3 (8 times)
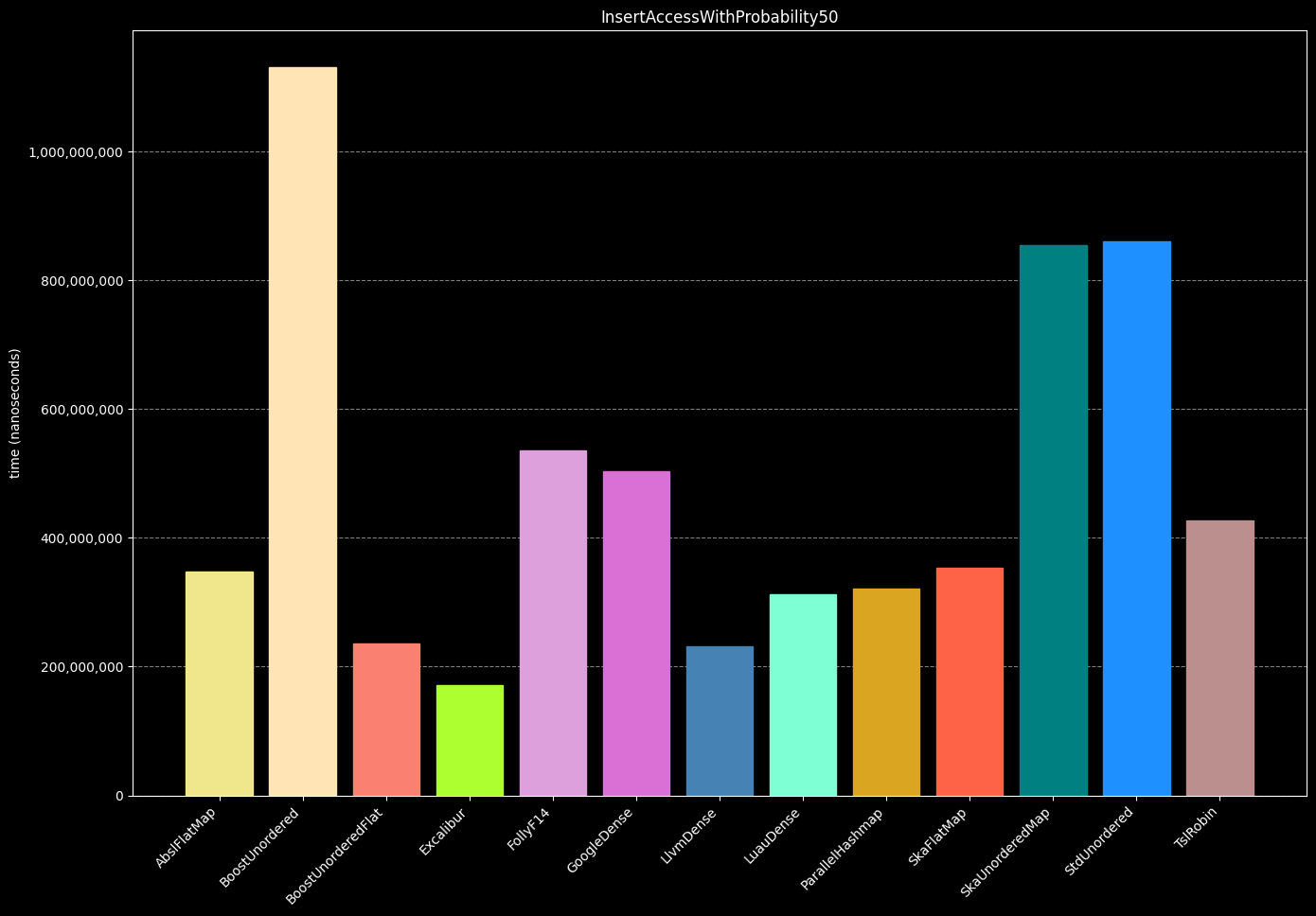
- Create a hash table
- Insert or increment 1,000,000 values where 50% of keys are duplicates (50% of operations will be modifications and 50% will be insertions)
- Destroy the hash table
- Repeat steps 1-3 (8 times)
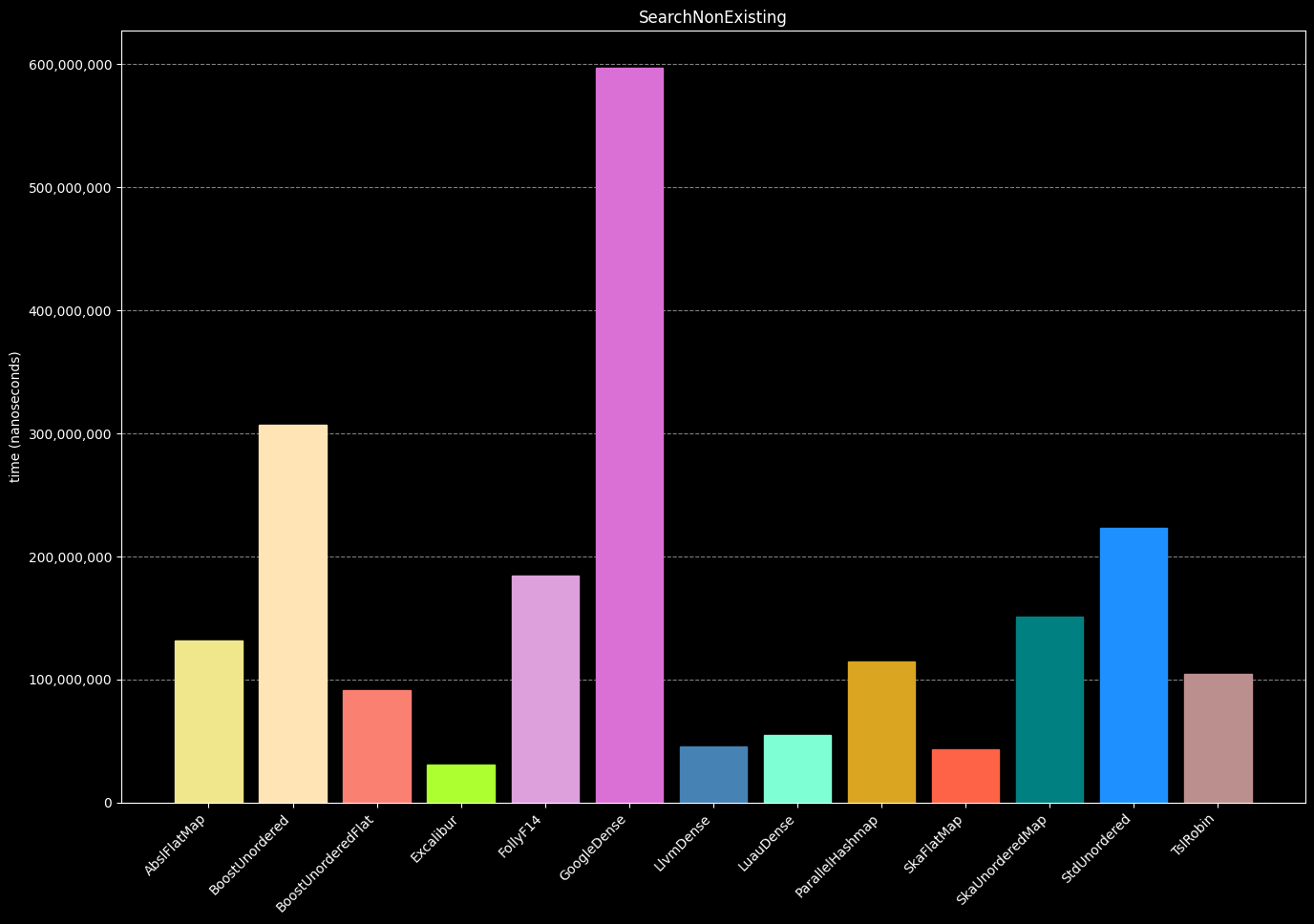
- Create a hash table
- Insert 1,000,000 unique random int numbers
- Search for non existent keys (10,000,000 times)
- Destroy the hash table
- Create a hash table
- Insert 1,000,000 unique random int numbers
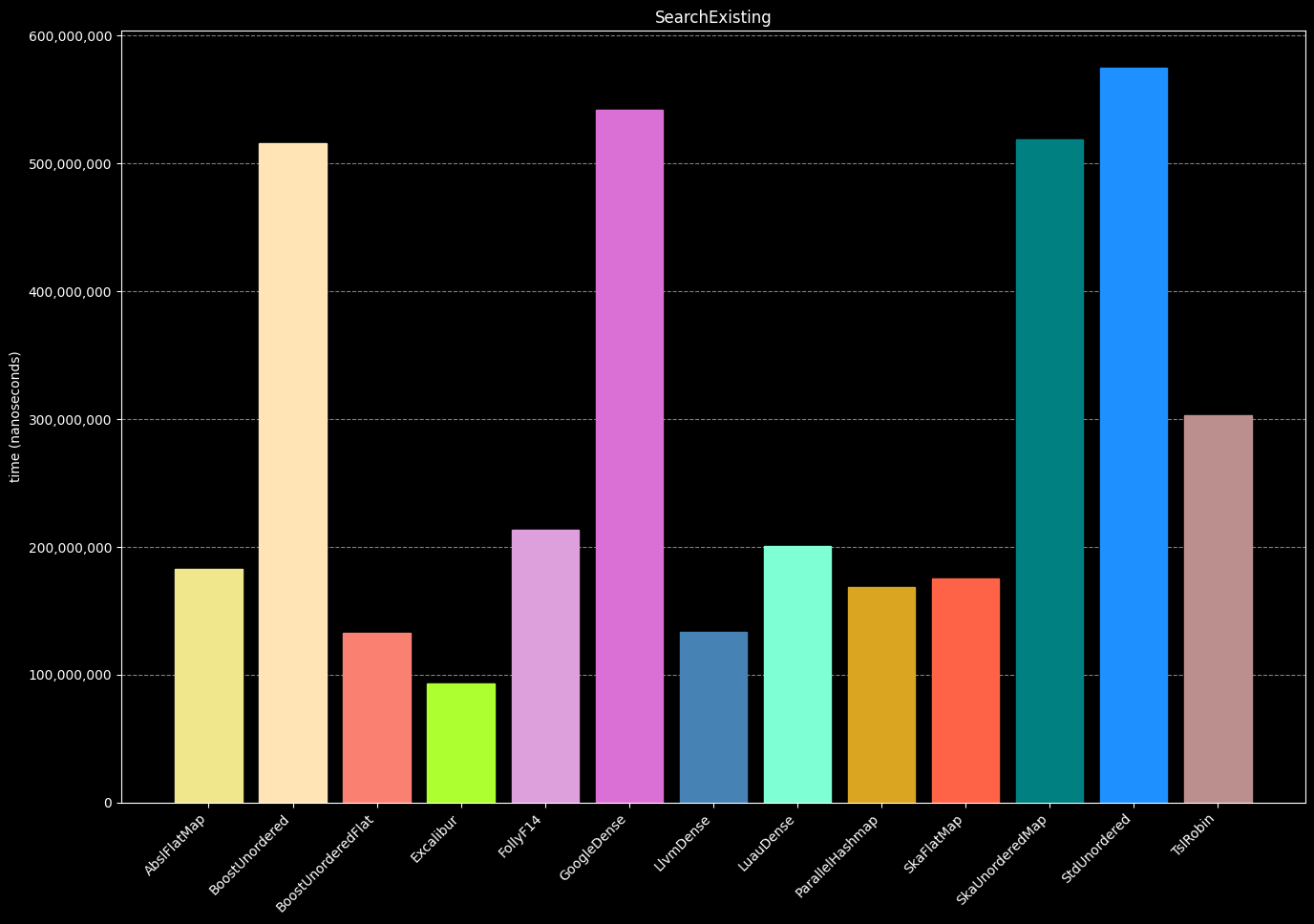
- Search for existent keys (10,000,000 times)
- Destroy the hash table
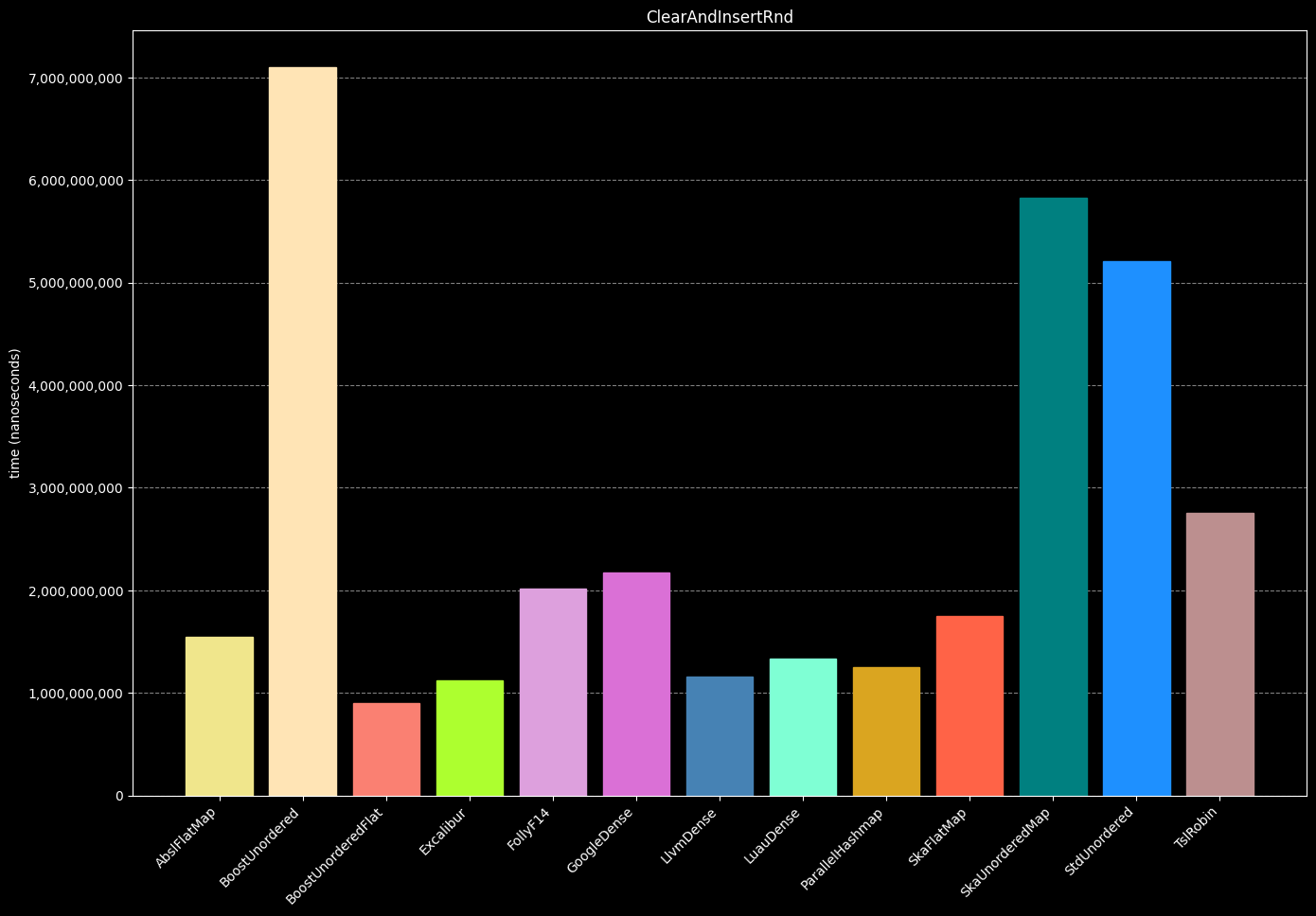
- Create a hash table
- Insert 1,000,000 unique random int numbers
- Destroy the hash table
- Repeat steps 1-3 (25 times)
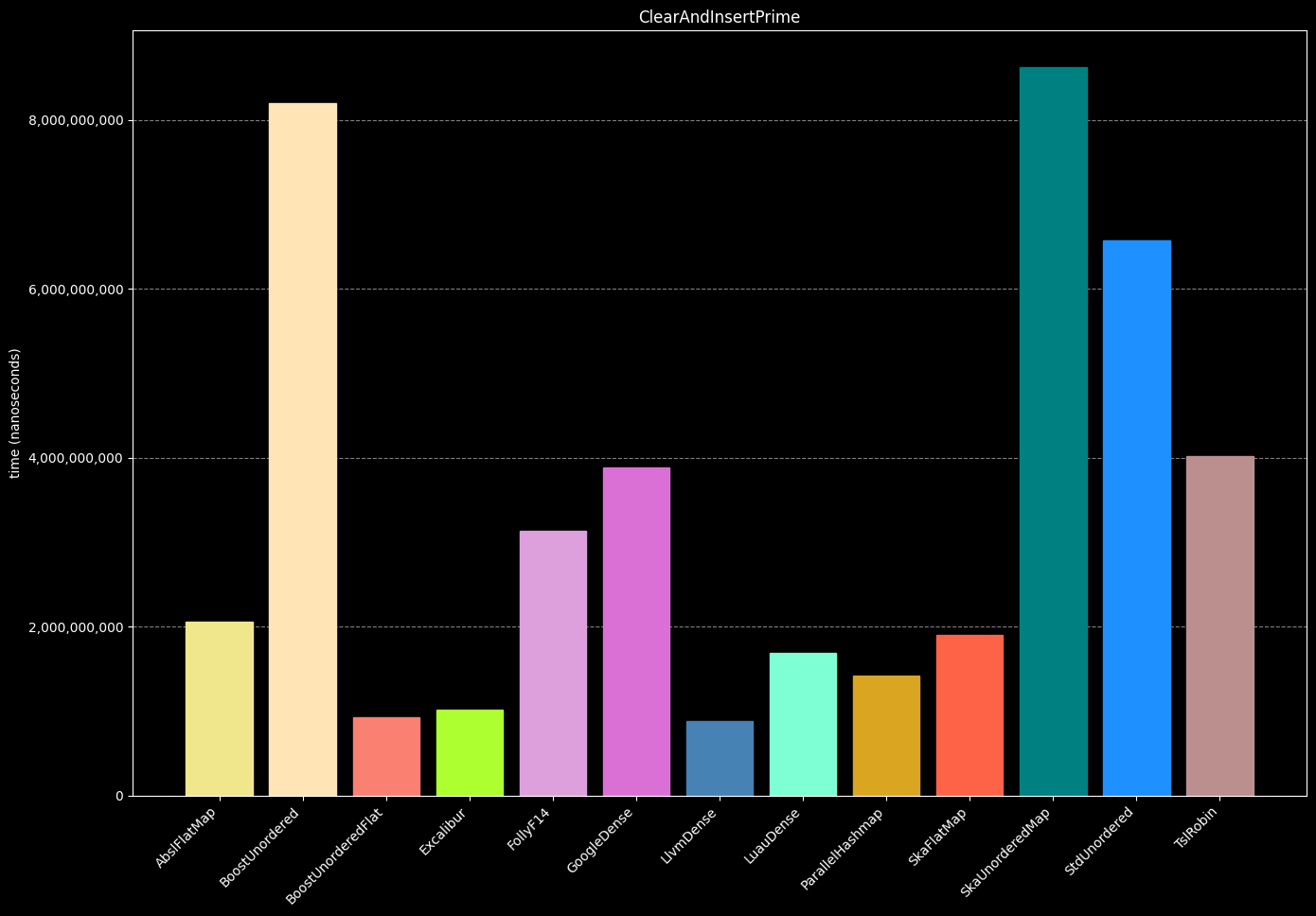
- Create a hash table.
- Insert 100 unique random numbers 32,767 times (shuffled), totaling 3,276,700 insertions.
- Destroy the hash table.
- Repeat steps 1-3 (10 times)
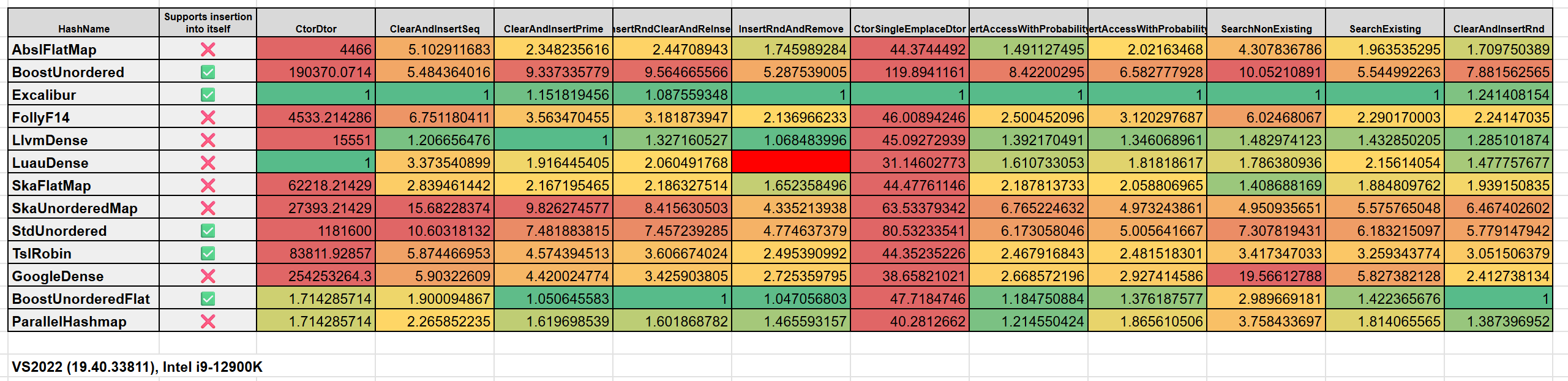
Below, you can find all the tests combined into a single table using normalized timings where 1.0 is the fastest implementation, 2.0 is twice as slow as the fastest configuration, and so on.
OS: Windows 11 Pro (22621.4317)
CPU: Intel i9-12900K
RAM: 128Gb
ExcaliburHash is a header-only library. Simply include the headers in your project.
# Add ExcaliburHash as a subdirectory
add_subdirectory(ExcaliburHash)
# Link to your target
target_link_libraries(your_target ExcaliburHash)Copy the ExcaliburHash/ directory to your project and include:
#include "ExcaliburHash/ExcaliburHash.h"#include "ExcaliburHash.h"
int main()
{
// Hash map (key/value pairs) with convenient type alias
Excalibur::HashMap<int, std::string> hashMap;
hashMap.emplace(42, "hello");
hashMap[123] = "world";
// Hash set (keys only) with type alias
Excalibur::HashSet<int> hashSet;
hashSet.emplace(42);
// Raw HashTable template (more explicit)
Excalibur::HashTable<int, int> table;
table.emplace(13, 6);
return 0;
}Excalibur::HashMap<int, std::string> map;
// Insert/update
map.emplace(1, "one");
map[2] = "two";
// Search
if (map.has(1)) {
auto it = map.find(1);
if (it != map.iend()) {
std::cout << "Found: " << it.value() << std::endl;
}
}
// Removal
map.erase(1);
// Iteration
for (const auto& item : map.items()) {
std::cout << item.key() << " -> " << item.value() << std::endl;
}
// Keys and values separately
for (const auto& key : map.keys()) {
std::cout << "Key: " << key << std::endl;
}
for (const auto& value : map.values()) {
std::cout << "Value: " << value << std::endl;
}// Default: 1 inline item (no heap allocation for small maps)
Excalibur::HashMap<int, int> smallMap;
// Configure inline storage for better performance with known sizes
Excalibur::HashMap<int, int, 8> mediumMap; // 8 items inline storage
Excalibur::HashMap<int, int, 64> largeMap; // 64 items inline storageFor custom key types, specialize KeyInfo<T>:
struct MyKey {
int id;
// ... other members
};
namespace Excalibur {
template <> struct KeyInfo<MyKey> {
static inline bool isValid(const MyKey& key) noexcept {
return key.id != -1 && key.id != -2;
}
static inline MyKey getTombstone() noexcept { return {-1}; }
static inline MyKey getEmpty() noexcept { return {-2}; }
static inline size_t hash(const MyKey& key) noexcept {
return std::hash<int>{}(key.id);
}
static inline bool isEqual(const MyKey& lhs, const MyKey& rhs) noexcept {
return lhs.id == rhs.id;
}
};
}More detailed examples can be found in the unit tests folder.
// Hash map (key-value pairs)
template <typename TKey, typename TValue, unsigned kNumInlineItems = 1, typename TKeyInfo = KeyInfo<TKey>>
using HashMap = HashTable<TKey, TValue, kNumInlineItems, TKeyInfo>;
// Hash set (keys only)
template <typename TKey, unsigned kNumInlineItems = 1, typename TKeyInfo = KeyInfo<TKey>>
using HashSet = HashTable<TKey, std::nullptr_t, kNumInlineItems, TKeyInfo>;HashTable() noexcept; // Default constructor
HashTable(const HashTable& other); // Copy constructor
HashTable(HashTable&& other) noexcept; // Move constructor
HashTable& operator=(const HashTable& other); // Copy assignment
HashTable& operator=(HashTable&& other) noexcept; // Move assignment
~HashTable(); // Destructor// Find element by key (returns iterator)
IteratorKV find(const TKey& key) noexcept;
ConstIteratorKV find(const TKey& key) const noexcept;
// Check if key exists
bool has(const TKey& key) const noexcept;
// Access or insert element (hash maps only)
TValue& operator[](const TKey& key);// Insert element (returns pair<iterator, bool>)
template <typename TK, class... Args>
std::pair<IteratorKV, bool> emplace(TK&& key, Args&&... args);
// Remove element by iterator
IteratorKV erase(const IteratorKV& it);
ConstIteratorKV erase(const ConstIteratorKV& it);
// Remove element by key (returns true if removed)
bool erase(const TKey& key);
// Remove all elements
void clear();// Size information
uint32_t size() const noexcept; // Number of elements
uint32_t capacity() const noexcept; // Current bucket count
bool empty() const noexcept; // Check if empty
uint32_t getNumTombstones() const noexcept; // Number of tombstone entries
// Performance tuning
bool reserve(uint32_t numBuckets); // Reserve bucket capacity
void rehash(); // Rebuild hash table (removes tombstones)// Key-value iterators (most commonly used)
IteratorKV ibegin(); // Mutable iterator to first item
IteratorKV iend(); // Mutable iterator past last item
ConstIteratorKV ibegin() const; // Const iterator to first item
ConstIteratorKV iend() const; // Const iterator past last item
// Key-only iterators
IteratorK begin() const; // Iterator to first key
IteratorK end() const; // Iterator past last key
// Value-only iterators (hash maps only)
IteratorV vbegin(); // Mutable iterator to first value
IteratorV vend(); // Mutable iterator past last value
ConstIteratorV vbegin() const; // Const iterator to first value
ConstIteratorV vend() const; // Const iterator past last value// Convenient range objects for range-based for loops
auto keys() const; // Iterate over keys
auto values(); // Iterate over values (mutable)
auto values() const; // Iterate over values (const)
auto items(); // Iterate over key-value pairs (mutable)
auto items() const; // Iterate over key-value pairs (const)// Iterator methods (available on all iterator types)
iterator.key(); // Get key reference (IteratorKV, ConstIteratorKV)
iterator.value(); // Get value reference (IteratorKV, ConstIteratorKV)
*iterator; // Dereference to key (IteratorK) or value (IteratorV)
++iterator; // Pre-increment
iterator++; // Post-increment
iterator == other; // Equality comparison
iterator != other; // Inequality comparisontemplate <typename TKey, typename TValue, unsigned kNumInlineItems = 1, typename TKeyInfo = KeyInfo<TKey>>
class HashTable;TKey: Key typeTValue: Value type (usestd::nullptr_tfor sets)kNumInlineItems: Number of items stored inline (default: 1, must be power of 2)TKeyInfo: Key traits struct (auto-detected for built-in types)
ExcaliburHash provides built-in KeyInfo specializations for:
int32_t,uint32_tint64_t,uint64_tstd::string
For other types, you must specialize KeyInfo<T> (see Custom Key Types section above).