Evaluation of Text Classification using Support Vector Machine compare with Naive Bayes, Random Forest Decision Tree and K-NN
The Data set was about BBC News provided by kaggle

Python programming language in the Jupyter Notebook environment was used in this paper to find standard deviation, mean, mean of standard error, and mean difference. The following algorithms were applied to the dataset to find the best model: The k-nearest neighbours algorithm, called KNN and k-NN, is a supervised classifier, which uses proximity to make classifications about the data point[12]. As it is shown in Figure 2 the K-NN with n_neighbors equal 5 as a parameter reached 94.76% accuracy.
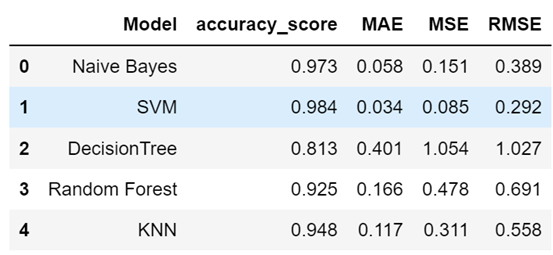
The data table of accuracy for all five Machine learning model has shown in Table 2