


Table of Contents (click to expand)
Pretrained simulator and datasets are available here.
Documentation is available here (debugging is in progress).
Stable versions are available at PyPI.
Slides are available here.
日本語はこちら。
Personalizing sentence generation is crucial in interactive platforms including recommender systems, online ads, and educational apps. For example, consider a situation where we recommend the movie "Wall-E (2008)" with some short descriptions or slogans of the movie, as shown in the following figure. If the user is a sci-fi lover, the description focusing on the "sci-fi" aspect of the movie would gain more attention than that focusing on the "romance" aspect, and vice versa. Such personalization is crucial for maximizing some business metrics and users' welfare.

Motivative example of for generating personalized sentence in movie recommendation.
This package, called OfflinePrompt, aims to provide tools for the above personalization focusing on the prompt-policy learning from logged bandit data. Specifically, we consider the following workflow -- (i) For each coming user, a policy chooses which prompt to use to generate sentences with a frozen LLM. (ii) Each user observes only the sentence generated by the chosen prompt and provides the reward for the corresponding sentence. -- The following figure illustrates the interaction process. Through daily operations in the platform, a (logging) policy naturally collects user responses to the sentence generated by the logging policy. Our goal is to use such informative logged data to learn or evaluate a new policy (Off-policy evaluation and learning; OPE/OPL) for better personalization in the future.

Prompt-guided sentence personalization as a off-policy learning of contextual bandits.
To facilitate the research and practical applications of OPL of prompt policies, OfflinePrompts contributes to the followings;
- To implement representative OPL methods for prompt optimization.
- To provide two benchmark environments, including synthetic and full-LLM.
- To streamline the workflow to connect OPL and sentence generation modules for smooth experimentation.
In particular, the provided full-LLM benchmark models realistic users' responses to the presented sentence in the movie recommendation settings, by training a semi-synthetic reward simulator with the sentence-augmented MovieLens dataset. The benchmark design is a remarkable contribution to the research community, as we currently lack a realistic simulator on personalized sentence generation tasks that satisfies the following four key qualifications:
- LLMs have knowledge about items (e.g., movies) so that they can generate descriptions.
- Items have more than two aspects (e.g., sci-fi and romance) so that choosing a prompt makes the difference in expected rewards.
- The above \textit{prompt effects} can be different among individual contexts (i.e., users).
- The prompt effects are learnable from datasets, so we can learn a realistic simulator (e.g., MovieLens enables us to learn affinity between user preference and movie features).
We hope this work will be an important cornerstone to the real-world applications of OPL for prompt-guided language personalization.
Click here to show the implementation details
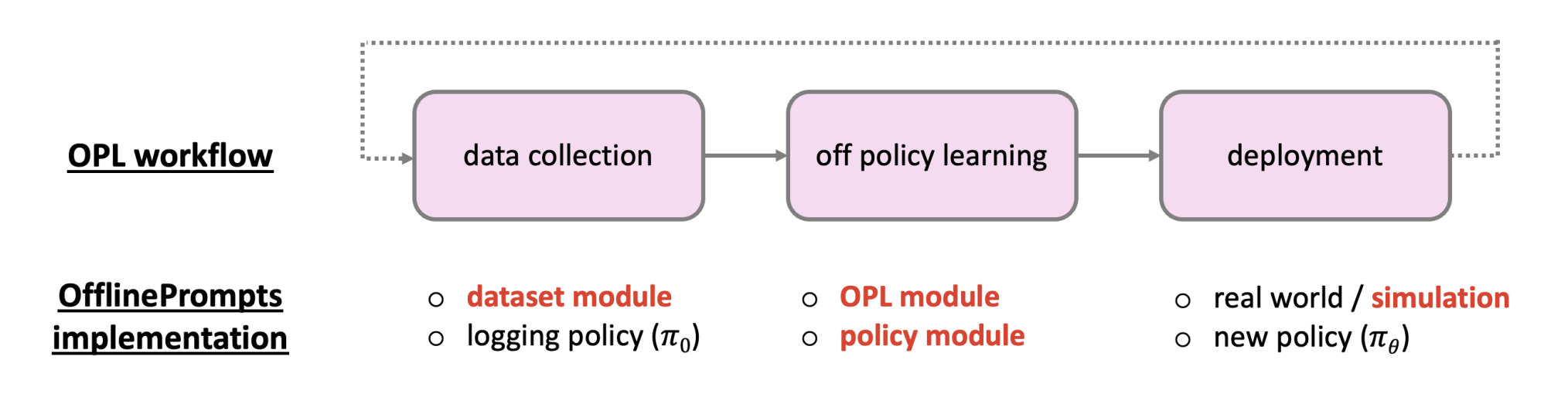
Off-policy learning (OPL) workflow and OfflinePrompts modules.
OfflinePrompts streamlines the implementation with three modules: dataset, OPL, and policy, as shown in the above figure. All implementations are based on PyTorch. Roughly, the dataset module provides the benchmarks, the policy module provides the base implementations of the prompt-policy, and the OPL module provide learner classes for training the prompt-policy using logged dataset.
Both synthetic and full-LLM benchmarks provide a standardized setting and configurable submodules to control the data generation process. Specifically, as illustrated in the following figure, each benchmark consists of four submodules:
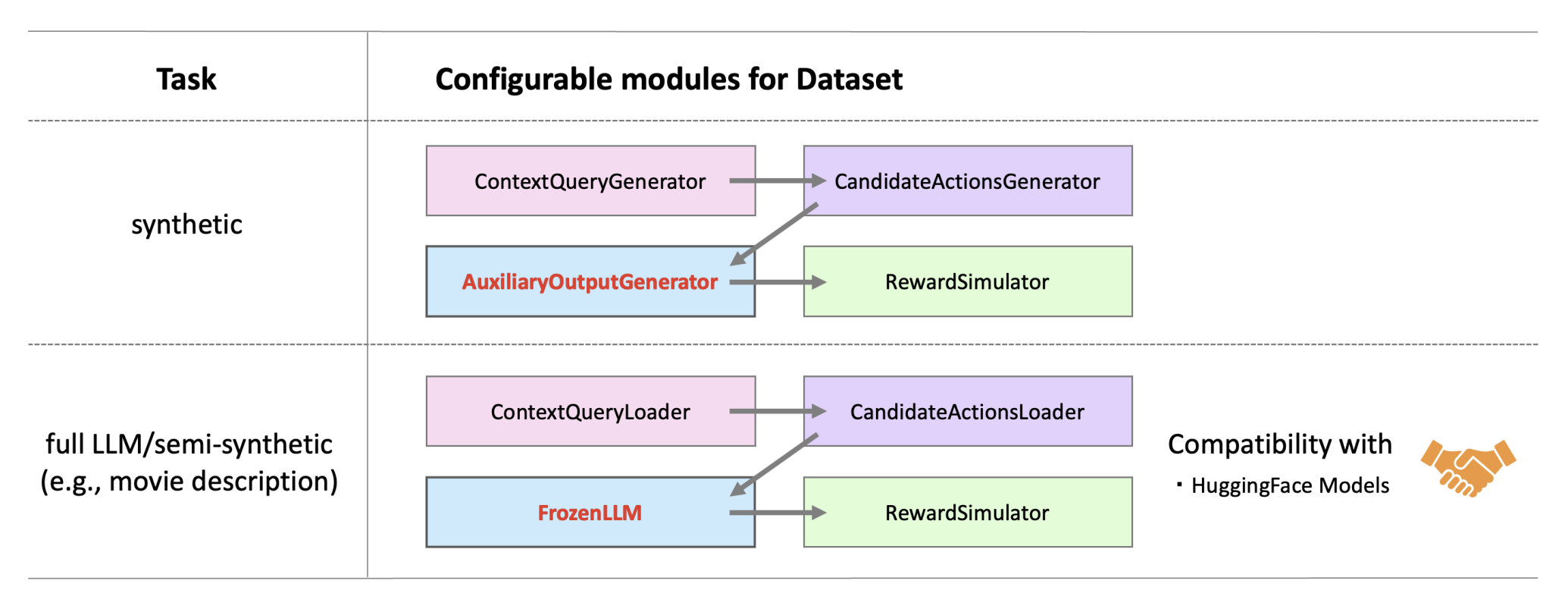
Two benchmarks (*synthetic* and *full-LLM*) with four configurable submodules.
ContextQueryModule: Loading the original dataset and user and item features.CandidateActionsModule: Loading and handling candidate prompts.AuxiliaryOutputGenerator/FrozenLLM: Handling sentence generation process given prompts as inputs.RewardSimulator: Simuating user responses given sentence generated by frozen LLMs.
Compared to the existing OPE/OPL benchmarks such as obp and scope-rl, our benchmark is distinctive in modeling AuxiliaryOutputGenerator/FrozenLLM, which enable us to simulate language generation tasks as contextual bandits with auxiliary outputs.
Moreover, since our FrozenLLM and RewardSimulator modules are compatible with Huggingface, users can easily employ various language models in the full-LLM experiments. The full-LLM (semi-synthetic) dataset module can also load custom dataset in a manner similar to the movie description benchmark. Please also refer to this page for the detailed procedure for using a custom dataset or environment.
Further details are available in the preprint.
You can install OfflinePrompts using Python's package manager pip.
pip install offline-prompts
You can also install OfflinePrompts from the source.
git clone https://github.com/aiueola/offline-prompts
cd offline-prompts
python setup.py installOfflinePrompts supports Python 3.9 or newer. See requirements.txt for other requirements.
Please refer to the quickstart examples in the doc.
If you use this simulator in your project or find this resource useful, please cite the following papers.
(benchmarking experiment)
Haruka Kiyohara, Daniel Yiming Cao, Yuta Saito, Thorsten Joachims.
An Off-Policy Learning Approach for Steering Sentence Generation towards Personalization
link
@inproceedings{kiyohara2025off,
title = {An Off-Policy Learning Approach for Steering Sentence Generation towards Personalization},
author = {Kiyohara, Haruka and Cao, Daniel Yiming and Saito, Yuta and Joachims, Thorsten},
booktitle = {Proceedings of the 19th ACM Conference on Recommender Systems},
pages = {41--50},
year = {2025},
}
(package and documentation)
Haruka Kiyohara, Daniel Yiming Cao, Yuta Saito, Thorsten Joachims.
OfflinePrompts: Benchmark Suites for Prompt-guided Text Personalization from Logged Data
link
@article{kiyohara2025offline,
title = {OfflinePrompts: Benchmark Suites for Prompt-guided Text Personalization from Logged Data},
author = {Kiyohara, Haruka and Cao, Daniel Yiming and Saito, Yuta and Joachims, Thorsten},
journal = {arXiv preprint arXiv:},
year = {2025},
}
- Haruka Kiyohara (Main Contributor; Cornell University)
- Daniel Yiming Cao (Cornell University)
- Yuta Saito (Cornell University)
- Thorsten Joachims (Cornell University)
This research was supported in part by NSF Awards IIS-2312865 and OAC-2311521. Haruka Kiyohara and Yuta Saito are supported by Funai Overseas Scholarship.
This project is licensed under Apache 2.0 license - see LICENSE file for details.
If you have any questions, please contact hk844 [at] cornell.edu.
Implemented papers (click to expand)
-
Ronald J. Whilliams. "Simple Statistical Gradient-following Algorithms for Connectionist Reinforcement Learning." 1992.
-
Vijay Konda and John Tsitsiklis. "Actor-critic algorithms." 1999.
-
Alina Beygelzimer and John Langford. "The offset tree for learning with partial labels." 2009.
-
Alex Strehl, John Langford, Lihong Li, and Sham M Kakade. "Learning from logged implicit exploration data." 2010.
-
Miroslav Dudík, John Langford, and Lihong Li. "Doubly robust policy evaluation and learning." 2011.
-
Yuta Saito, Qingyang Ren, and Thorsten Joachims. "Off-policy evaluation for large action spaces via conjunct effect modeling." 2023.
-
Adith Swaminathan and Thorsten Joachims. "Batch learning from logged bandit feedback through counterfactual risk minimization." 2015.
-
Miroslav Dudík, John Langford, and Lihong Li. "Doubly robust policy evaluation and learning." 2011.
-
Yuta Saito, Jihan Yao, and Thorsten Joachims. "POTEC: Off-policy learning for large action spaces via two-stage policy decomposition." 2024.
-
Haruka Kiyohara, Daniel Yiming Cao, Yuta Saito, and Thorsten Joachims. "An Off-Policy Learning Approach for Steering Sentence Generation towards Personalization". 2025.
Other reference papers (click to expand)
-
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric Xing, and Zhiting Hu. "RLPrompt: Optimizing discrete text prompts with reinforcement learning." 2022.
-
Yuta Saito and Thorsten Joachims. "Off-policy evaluation for large action spaces via embedding." 2022.
-
Noveen Sachdeva, Yi Su, and Thorsten Joachims. "Off-Policy Bandits with Deficient Support." 2020.
-
Maxwell F. Harper and Joseph A. Konstan. "The MovieLens Datasets: History and Context." 2015.
-
Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita. "Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation." 2021.
-
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito. "SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation." 2023.
-
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. "Huggingface's Transformers: State-of-the-art Natural Language Processing." 2019.
-
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. "Language Models are Few-Shot Learners." 2020.
-
Albert Q. Jiang, Alexandre Sablayrolles, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothee Lacroix, William El Sayed. "Mistral-7B." 2023.
Relevant projects (click to expand)
- Open Bandit Pipeline -- a pipeline implementation of OPE in contextual bandits: [github] [documentation] [paper]
- scope-rl -- a pipeline implementation of OPE in reinforcement learning: [github] [documentation] [paper]
- MovieLens -- a dataset that collects large-scale user-item rating data in movie recommendation: [documentation] [paper]