- 1. Introduction - Joint
- 2. Motivation - 5
- 3. Method plan - 26
- 4. Netnography -25
- 5. Network analysis - 25
- 6. Content analysis - 25
- 7. ASDS II - LDA Topic Model - 3
- 8. Quali-quantitative integration across methods - Joint
- 9. Conclusion - Joint
- Literature
Over the course of the last years, youth and climate have become closely associated concepts in the public and political conversation on climate change. School Strikes for Climate in over 150 countries has scrutinised the discourse of climate as a generational issue, where the society "owes" the young generation a socially just approach to climate change (Thew et al., 2020).
In Denmark, this discourse of climate- and sustainability issues (hereafter CSI) as a generational issue manifested itself as Prime Minister, Mette Frederiksen, upon winning the election in June 2019, thanked the young generation for making this election the first ever climate-election (Frederiksen, 2020). This generational framing primes us to investigate how political youth- and mother parties engage in the conversation on CSI on social media.
Guided by Kozinets' (2019) writings on netnographically founded research, we formulate the scope of our study as follows: We are investigating how youth- and mother parties engage in the conversation on CSI on Twitter through posts and retweets to explore how they communicate their agendas on these issues in comparison. We do so by using both qualitative quantitative methods to explore patterns in a larger dataset of tweets posted by a defined list of youth- and mother parties, retrieved through the Twitter API.
Specifically, we explore how the framing of CSI as a political issue of particular significance to the younger generation(s) is reflected in how youth- and mother parties engage in the conversation on CSI on Twitter. Formally, we ask the question:
How do political parties engage in the conversation on climate- and sustainability related issues on Twitter and can we observe differences across the political spectrum and between mother- and youth parties?
The conversations on and engagements with CSI are not only politically prevalent, but also a focus of contemporary research on social media using quali-quantitative methods. By combining quantitative computational methods and qualitative netnographic observations, Blok et al. (n.d.) investigate how green NGOs in three Scandinavian countries interrelate on social media platforms during the covid-19 pandemic, a period in which media coverage and the Danish government's actions concerning climate declined. Blok et. al (2021) employ a combination of principal component analysis and netnography to analyse how climate-active NGOs in three Scandinavian countries react to the covid-19 pandemic by examining their climate and corona-related tweets.
To fathom the contemporary public and political debate, one cannot overlook the massive impact of social media networks and -platforms (Decuypere, 2020). The discussion of political issues has extended to a format that allows for direct communication between and with politicians, and while the digital infrastructure is largely owned by private companies and institutions, it offers the opportunity to repurpose the generated data for research purposes (Venturini et al., 2018; Edwards et al., 2013).
A large-scaled international study by Reuters Institute and the University of Oxford from 2020 found significant differences in how people across age groups as well as the political spectrum use social media both generally and specifically related to climate (Newman et al., 2020). Generally, Generation Z (born 1996-2002) consume more news on Instagram, compared to any other platform. They further supersede all other generations in their use of the platform when consuming news about climate as they find value in getting the news directly from climate activists (Andini, 2020). The study further suggests that political affiliation factors into how individuals perceive climate change, with people on the left side of the spectrum being more anxious (Ibid.).
Informed by the discrepancy in the use of platforms between generations, an aspect of our netnographic work is accordingly to examine how the youth parties present themselves on other platforms in comparison to their mother parties.
In this paper, we conduct our research with the internet, by immersing ourselves into the digital field to ground the computational aspects of the study (Kozinets, 2019). We combine netnographic field work to ask the right questions, explore the greater depths of the field through the creation of networks, before we use computational approaches to explore the content of the tweets related to CSI. By continuously extending our study though supplementary methods, we further the understanding of, if and where the different mother- and youth parties participate in the conversation on CSI (netnography), who they engage with and endorse on the topic (networks), how they communicate about CSI (content analysis) and finally how salient the topics are to each of the parties, and what tendencies we can observe (topic model).
By taking these steps and allowing the methods to inform and supplement each other, we conduct a comprehensive examination of how political parties tweet about CSI, as well as uncover potential differences between parties and generational segmentation as proxied by the comparison of youth- and mother parties. We identify differences in how parties engage in the conversation on CSI on Twitter, which will be unfolded throughout this paper.
Netnography is an ethnographic approach that seeks to acquire a deep understanding of complex cultures and interactions, with the aim of explaining online phenomena (Kozinets, 2019). This requires immersion into the field(s), or data site(s), where the phenomenon of interest takes place (Ibid.).
The investigative data collection of our netnography can be seen in the light of Kozinets’ (2019) double-funnel process, where the topic is repeatedly inspected broadly and concretised until we reach a narrow and specific topic of interest. We are guided by the five operations specified by Kozinets (2019): First, we simplify in an iterative process where our initial interest in youth parties and the CSI conversation is narrowed down to specific terms, which are then used in our search through data sites. We scout a broad range of social media sites as well as the parties’ websites and use this process to select what data sites to focus on as well as evaluate the collected data. These steps are taken repeatedly as we narrow the scope of the study while continuously saving the collected data in an immersion journal.
For the first time in Danish politics, climate became a central theme during the campaigns prior to the 2019 election and cemented the role of climate as a political topic of utmost importance (Sørensen, 2019) We focus the scope of our study to the time between the beginning of the election year 2019 until the time of collecting our Twitter data on June 3, 2021.
Through our double-funnel process, we define criteria for parties to be included in the scope of the study. We define a list of Danish youth parties associated with the parties either represented or eligible to be represented in parliament. For a pair of youth- and mother parties to be included, the mother party must hold a seat in parliament, and both must be active on Twitter with at least one tweet during the temporal scope of this study. Socialistisk Ungdomsfront (SUF) and Rød-Grøn Ungdom do not have a directly associated mother party, but nevertheless declare their support to Enhedslisten, so we include all three in our study (Rød-Grøn Ungdom, n.d.; Socialistisk Ungdomsfront, n.d.). We end up with a list consisting of 10 official parties and 11 youth parties.
Our simplifying steps include investigating how to create meaningful groupings between parties to contextualise the results of our analysis. Firstly, we treat the parties as single entities. Secondly, we view a grouping between youth- and mother parties as a proxy for examining a generational divide. Finally, to consider political similarities and differences between parties, we delimit an analytical grouping to be the bloc supporting the sitting government as one and the opposition as another. This distinction is made based on the mother parties dividing based on the principle of negative parliamentarism and is extended to the youth parties based on the position of their mother party (Table 1).
Table 1
| Party | English Translation | Twitter handle | Link |
|---|---|---|---|
| Alternativet | The Alternative | @alternativet_ | https://twitter.com/alternativet_ |
| Alternativets Unge | Alternative Youth | @AlternativeUnge | https://twitter.com/AlternativeUnge |
| Dansk Folkeparti (DF) | Danish People’s Party | @DanskDf1995 | https://twitter.com/DanskDf1995 |
| Dansk Folkepartis Ungdom (DFU) | Danish People's Party's Youth | @DFUngdom | https://twitter.com/DFUngdom |
| Enhedslisten | The Danish Red-Green Alliance | @Enhedslisten | https://twitter.com/Enhedslisten |
| Rød-Grøn Ungdom | Red-Green Youth | @rgungdom | https://twitter.com/rgungdom |
| Socialistisk Ungdomsfront (SUF) | Socialist Youth Front | @sufnet | https://twitter.com/sufnet |
| Det Konservative Folkeparti (Konservative) | The Conservatives | @KonservativeDK | https://twitter.com/KonservativeDK |
| Konservativ Ungdom (KU) | Conservative Youth | @KU_DK | https://twitter.com/KU_DK |
| Liberal Alliance (LA) | Liberal Alliance | @LiberalAlliance | https://twitter.com/LiberalAlliance |
| Liberal Alliances Ungdom (LAU) | Liberal Youth | @LiberalUngdomDK | https://twitter.com/LiberalUngdomDK |
| Nye Borgerlige | The New Right | @NyeBorgerlige | https://twitter.com/NyeBorgerlige |
| Unge Nye Borgerlige | Young The New Right | @UngeNB | https://twitter.com/ungenb |
| Radikale Venstre | Danish Social-Liberal Party | @radikale | https://twitter.com/radikale |
| Radikal Ungdom | The Danish Social Liberal Youth | @radikanungdom | https://twitter.com/radikalungdom |
| Socialistisk Folkeparti (SF) | Socialist People’s Party | @SFpolitik | https://twitter.com/SFpolitik |
| Socialistisk Folkepartis Ungdom (SFU) | Popular Socialist Youth of Denmark | @SF_Ungdom | https://twitter.com/SF_Ungdom |
| Socialdemokratiet | Social Democrats | @Spolitik | https://twitter.com/Spolitik |
| Dansk Socialdemokratisk Ungdom (DSU) | Social Democratic Youth | DSU_1920 | https://twitter.com/DSU_1920 |
| Venstre | The Liberal Party of Denmark | @venstredk | https://twitter.com/venstredk |
| Venstres Ungdom | Liberal Youth | @VUngdom | https://twitter.com/VUngdom |
We produce a shared immersion journal in online Excel where we collectively record and produce the data as we become immersed in the social mediascapes of our data sites (Kozinets, 2019). As described by Kozinets (2019) we continuously reconnoitre the data sites as we assess where to find the richness of the data. We then record such data findings in our immersion journal. Furthermore, we leave room to research and employ theoretical understandings and analytical concepts to our data, while also reflecting on the interpretations, assumptions and emotions through which we approach the data. The following sections provide examples of the findings learned through our netnographic immersion.
To attain an overview of how salient CSI are to each of the parties, we examine their program of political principals (PPP). We find that parties such as SF and SFU largely mention the “climate crisis” and communicate the need for sustainable transitions to avoid further escalation. Meanwhile the opposition parties KU and Venstre, as well as Socialdemokratiet, primarily present their climate policies in relation to economic policies, highlighting the importance of balancing economic growth and climate initiatives (Appendix IJ).
When exploring the parties' profiles on Twitter, the same tendency is apparent in the bio descriptions, where Alternativets Unge describes itself as “Youth party of the climate loonies.”, while Alternativet states that it is “[…] for people wanting a serious green, economic and social transition.”, while LAU identifies as being a party “[…] fighting for free people and a free market.” (own translations, Appendix 2). We discover a vast variation on how much the parties tweet, with mother parties generally posting far more to Twitter than their corresponding youth parties.
When reconnoitring the parties’ public Facebook pages, we observe that Socialdemokratiet and Nye Borgerlige are more active here than on Twitter. We also see tendencies similar to those inferred from the PPPs and Twitter. The youth parties from the supporting bloc are generally more focused on CSI and criticise the mother parties for not being committed to policies aimed at mitigating climate change. On their Facebook page, SFU directly criticises the climate minister for being an “[…] unambitious boomer climate minister.”, while Radikal Ungdom declares that they will hold their mother party responsible for their promise to make 2021 the “[…] year of climate”. LAU takes a different approach in their campaign “Communal climate, private money” in which it outlines its plan for reducing CO2 emissions by 70% of the 1990 levels through tax reductions, nuclear power and funding of innovation (own translations, Appendix IJ).
Lastly, we examine Instagram and find that the youth parties post more to the image-based platform than their mother parties do. Further, the youth parties generally post more to Instagram than to Twitter. Here too, there are ideological groupings in how salient CSI are and how much they are articulated. Across the political spectrum and amongst youth- as well as mother parties, CSI are widely referred to as generational with SFU and other youth parties from the supporting bloc calling on the mother parties to act on the climate crisis, as it is the young people’s future that is at stake (Figure 1). On the other hand, mother parties such as Radikale present themselves as listening to the youth when they promote their climate agendas by stating “The youth says it straightforward: climate action must happen.” (own translations, Appendix IJ).
 |
|---|
| Figure 1: Instagram post by Radikal Ungdom illustrating CSI as a generational issue |
Our netnographic observations provide insights into if and how the different parties dedicate space on their social media accounts for CSI. We observe differences in how parties use social media platforms as well as how they communicate about CSI. While most youth parties are more active on Instagram than Twitter, some mother parties, e.g. Socialdemokratiet and Nye Borgerlige, are far more active on Facebook than on Twitter. This might explain some of the disparity in posting activities on the parties’ Twitter profiles. Furthermore, we detect differences in how the parties communicate CSI with the youth parties of the supporting bloc framing the issue as a crisis, and opposition mother parties rather communicate CSI in relation to economy and industry. The youth parties of the opposition do generally not communicate CSI on social media platforms, with LAU being a notable exception to that finding.
A challenge to netnography is the impossibility of exploring all data sites in the infinite pool of social media sites, articles and other digital sources. When integrating qualitative and quantitative work, limiting the data sites is a non-trivial task, as a larger amount of information increases the granularity of our knowledge of the actors and how they use social media platforms differently to communicate their political agendas.
The netnographic observations situate our analysis, qualify our investigation of the quantitative computational methods and thus enables us to answer our research question. In the following section, we investigate two modes of visualising the parties' relations on social media. First, we manually map their interrelational follower patterns on Instagram and Twitter, then we employ an automated network to display who the parties retweet, when retweeting about CSI.
Networks are a popular way to visualise social connections and can be used to analyse structural properties of these (Decuypere, 2020). We use networks to inspect the structural properties of youth- and mother parties and their tweet activity related to CSI. The specific modality of our network is first focused on a how the parties connect with one another on Twitter and Instagram, while the second one depicts CSI retweet connections.
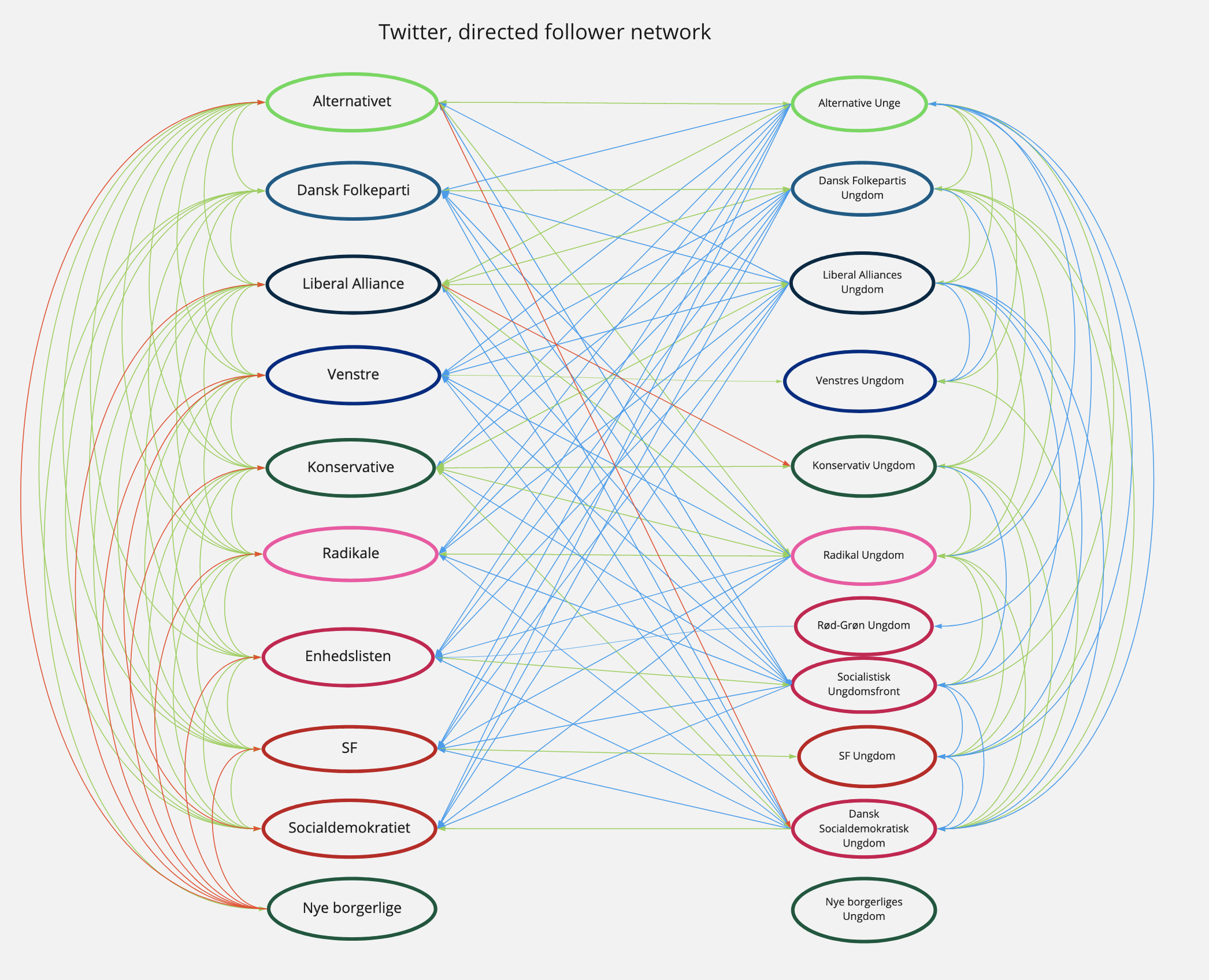
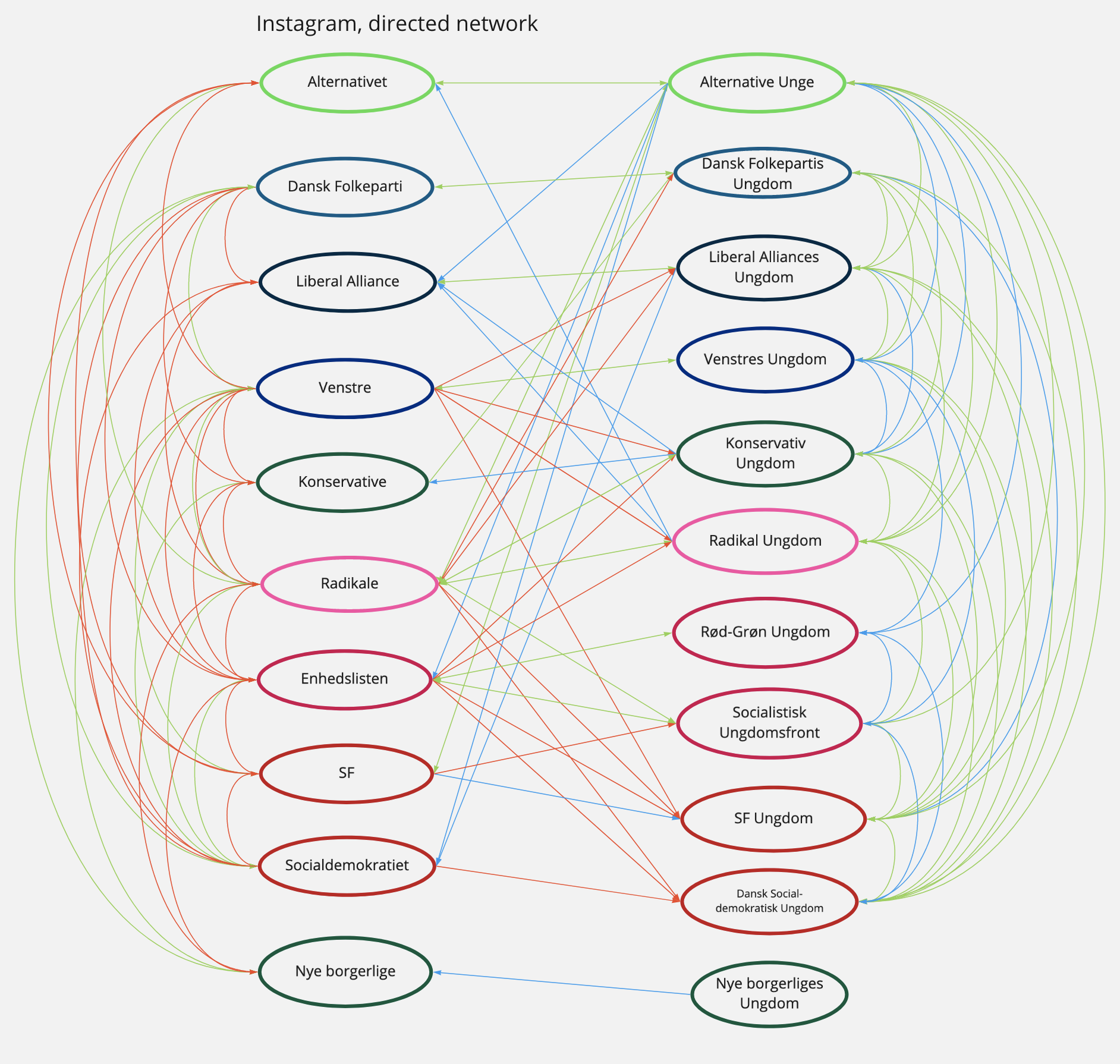
Like Twitter, Instagram is a connected network allowing users to select accounts they wish to follow. We find that all parties living up to our inclusion criteria are represented on Instagram, although not equally active. Thus, to see who each party opt to see content from, we create a manual follower network on Twitter (Figure 2) and Instagram (Figure 3).
In both networks, orange edges indicate a mother party following another party and blue a youth party following another party. If the follow is reciprocal, the edge between the nodes is green.
 |
|---|
| Figure 2: Directed follower network, Twitter |
 |
|---|
| Figure 3: Directed follower network, Instagram |
This visualises a divide in following behaviour along the generational axis on the platforms. With few exceptions, youth parties follow each other on Instagram, while mother parties do on Twitter. The follower network mapping Twitter shows that mother-parties do often not follow the youth parties back, apart from their own youth party. This tendency is reversed on Instagram where the mother-parties follow the youth parties, which is not reciprocated. Especially Venstre, Radikale and Enhedslisten orientate themselves towards the youth parties. The youth parties are more interconnected on Instagram than on Twitter supporting our assumption that they are more connected on Instagram. A possible explanation for this tendency is that their target audience, namely young people, are generally more represented on Instagram than on Twitter (Newman, 2020).
Research has found retweeting to be the best proxy for measuring endorsement on Twitter, motivating us to create an automated network visualising who the parties retweet on CSI (Kim & Yoo, 2012; Hong & Davidson, 2010; Boyd et al., 2010). Using the Twitter API, we retrieve tweets from the timelines of each of the youth- and mother parties. We find that Nye Borgerliges Ungdom has not posted a single tweet since January 1st, 2019, and since this study is largely founded on a generational comparison proxied by youth- and mother parties we ultimately exclude Nye Borgerlige from the Twitter dataset.
We qualitatively read a random sample of 600 tweets from our dataset. Drawing on the coding process described by MacQueen (1998), we first perform structural coding by finding all tweets related to CSI, and then develop a list of keywords on CSI through text segmentation.
We create a subset of all retweets in our dataset, we identify retweets containing the stem of the words in our keyword list: green, grøn (green), bæredygtighed (sustainable), CO2, miljø (environment), natur (nature) and the hashtag #dkgreen. We then create an automated retweet network that allows us to explore who the individual parties refer to when they retweet about CSI.
The network is created with Networkx, exported to Gephi and nodes colour-coded into relevant clusters: Parties (pink), politicians from mother parties (purple) and youth parties (orange) respectively, media outlets (turquoise), climate activists, organisations, stakeholders, and other legal entities (green) and governmental institutions or offices (red). Actors not fitting into these pre-defined categories remain blue. The network is visualised using the Force Atlas 2 algorithm and nodes are scaled after their in-degree centrality (see Appendix).
The retweet network visualises the disparity in Twitter activity between youth- and mother parties. The youth party Venstres Ungdom, is not represented in the network, meaning that it did not post a single retweet on CSI since January 1, 2019. Alternativets Unge and Radikal Ungdom retweet actors that we categorise as climate actors (green), while the remaining youth parties only retweet few actors, who are often politicians. Based on our netnography, we argue that the lack of retweets amongst youth parties might be caused by their generally low activity on Twitter as opposed to Facebook and Instagram.
The most retweeting parties within our network are Radikale, Alternativet and Alternativets Unge. While Radikale primarily retweets politicians on CSI, Alternativet and Alternativets Unge retweet a multitude of climate actors. We infer that the supporting bloc, except Socialdemokratiet, retweets more posts related to CSI, than the opposition bloc. While associated youth- and mother parties are mostly connected through a retweet, the parties do not retweet each other across neither generational nor party divides, the only exception being LA who retweets Alternativet.
While parties are not directly connected to each other, we do find them being connected through experts on CSI and media when retweeting on CSI. Central in the network, we find Greenpeace Denmark and the prominent climate actor John Nordbo from CARE. Greenpeace Danmark and John Nordbo are only retweeted by the mother parties in the supporting bloc (except Socialdemokratiet) and Alternativets Unge. The opposition parties Venstre, Konservative and LA retweet Spisekammeret, which is the official Twitter profile of the Danish Agriculture & Food Council (Landbrug & Fødevarer).
While the Council's Twitter page contains many posts somewhat related to CSI, a closer reading of these tweets reveals a greater emphasis on how the industry can further nature conservation, benefitting the environment as well as the economy. This finding is consistent with the economic focus of the opposition parties’ PPPs and social media posts.
Across the supporting- and opposition blocs, we find the largest green association in Denmark, the Danish society for Nature Conservation (Danmarks Naturfredningsforening). Danmarks Naturfredningsforening is retweeted by a broader range of parties (Enhedslisten, SF, Radikale, Konservative and Venstre). Through our netnographic work, we find that both supporting mother parties and opposition mother parties focus on some aspect of Danish nature, varying from expressing a wish for more wild nature and protecting biodiversity (SF) to preservation of the beautiful Danish landscape (Konservative). Danmarks Naturfredningsforening thus seems to encompass the political agendas across the political spectrum.
In the bottom of the network, we find Socialdemokratiet in a relatively isolated cluster. Socialdemokratiet only retweets its own politicians, the government’s Twitter profile and the sector organisation for windmills, Winddenmark. Only one actor, the social democratic MP Jesper Petersen (Jesper_Pet) connects Socialdemokratiet the rest of the network through Alternativet. This could be due to Socialdemokratiet’s low Twitter activity, however, the isolated position of Socialdemokratiet is supported by the netnographic findings.
Based on this automated network depicting who parties retweet and thus by proxy endorse, we can identify differences along the generational axis as well as on the political spectrum. These findings are consistent with the netnographic findings, although imperfect, due to the modest amount of CSI retweets by youth parties (except Alternativets Unge) as well as the opposition parties.
A potential shortcoming in the application of this method can be found in our Twitter dataset. With the API search, we exclusively get retweets in Danish, and therefore risk that important actors tweeting about CSI are not included. When examining the network, we are surprised that climate activists such as Greta Thunberg are not retweeted more, especially by youth parties, which might be due to the language restriction. A further investigation of retweet structures could thus be to include retweets in more languages to capture how youth- and mother parties are connected to actors in the international conversation on CSI.
To explore the patterns of shared word usage on CSI in the tweets by the youth- and mother parties, we employ the quantitative text analysis metods Principal Component Analysis (PCA) and qualify the findings through our netnographic observations.
The aim of PCA is to identify important information from a matrix of word frequencies. We draw on Fuhse et al. (2020) and understand socio-symbolic constellations as the ways in which actors relate to one another through symbolic practices as well as how these practices are connected through the actors. In this study, we use socio-symbolic constellations to describe how the parties use different words when communicating about CSI to position themselves in relation to one another. When using socio-symbolic constellations as a proxy for describing actors’ social relationships, Fuhse et al. (2020) underline the importance of having a field of mutual observation, where actors have explicit knowledge of each other's practices, to mitigate the risk of finding spurious connections between symbols (Ibid.). While our manual network shows that not all youth- and mother parties follow each other on Twitter, our netnographic observations and the fact that political parties position themselves in relation to each other, show that the parties are aware of each other’s practices and thereby exist in a field of mutual observation.
We find commonalities and differences in the parties’ word usage via an actor-term matrix where we count word frequencies and standardise these to identify the words most associated with each party. To narrow the vocabulary, we define green, grøn (green), klima (climate), natur (nature), bæredygtighed (sustainability) and CO2 as indicating that a tweet is about CSI and identify the most important words used by each party in relation to these. Using similar words brings the parties closer together in the PCA plot. To supplement this quantitative measure of shared word usage on CSI, we draw on Blok et al.’s (2021) methodological use of online ethnographic research on Twitter, Facebook and Instagram to ground and qualify our interpretation of the clusters emerging in the PCA plot (Figure 4).
 |
|---|
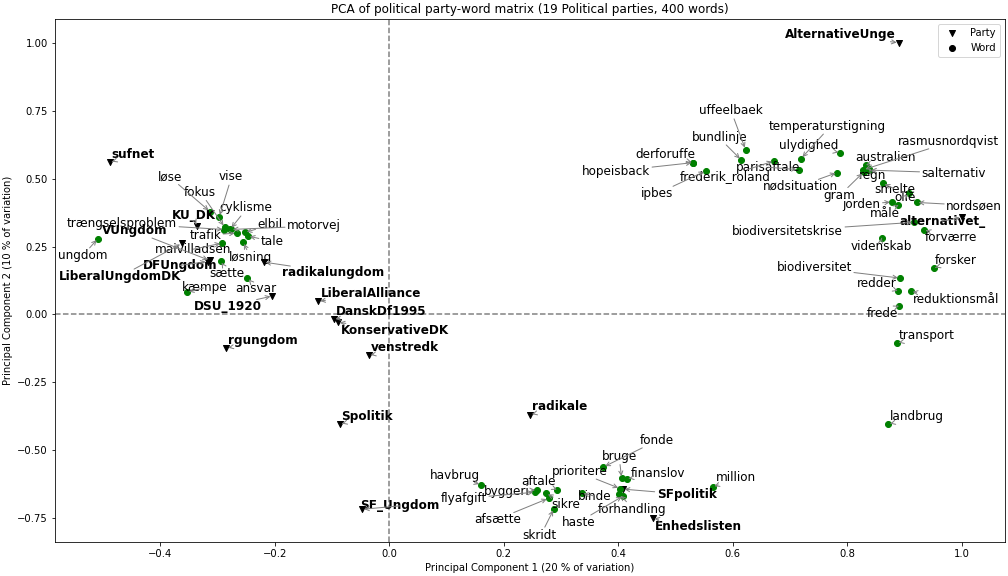
| Figure 4: PCA plot |
The x-axis accounts for the most variation in the data, as the first principal component (PC1) is found by finding the two datapoints with the largest possible distance between them. This is termed the eigenvalue and explains the largest part of the inertia of the data table (Brunton & Kutz, 2019; Abdi, 2010). The second principal component (PC2) is firstly restricted to being orthogonal to PC1 and then having the largest possible inertia (Adbi, 2010). In our PCA plot, PC1 captures 20% of the variance, while PC2 captures 10%.
When inspecting the plot, we see three clusters. In the north-eastern corner of our plot, Alternativet and Alternativets Unge form their own cluster. This fits well with our qualitative assessments of the tweets by Alternativet and Alternativets Unge, as both parties use a vast amount of climate words, form climate words of their own, such as klimaskuffet (climate-disappointed), and explicitly promote themselves as climate parties (Appendix IJ).
In the Southern part of our plot, we see a cluster consisting of the mother parties of the supporting bloc as well as SFU, which is also supported by our netnographic observations as these parties communicate about CSI in a similar fashion. In the third cluster positioned in the Western part of the plot, we find the opposition parties, who we find tweet less about climate than the supporting parties. Notably, the third cluster also contains the youth parties from the opposition bloc as well as Radikal Ungdom, DSU, SUF and Rød-Grøn Ungdom. Thus, these youth parties from the supporting bloc use more of the same words as each other and the opposition than words used by their respective mother parties.
Our PCA does not show clear generational differences. SFU and Alternativets Unge are the youth parties that we find to tweet the most and tweet the most about climate, and their word usage seems to align with the word usage of their mother parties. The placement of the remaining youth parties in proximity to each other but not always in proximity to their mother parties or others who we qualitatively assess to tweet similarly about CSI, might be due to our two PC’s only accounting for 30% of the variance, thus suggesting that there might be more to the similarities and differences of the socio-symbolic constellation than our plot portrays.
Socialdemokratiet is placed between the supporting bloc and the opposition/youth party bloc, however slightly closer to the latter. This suggests that while Socialdemokratiet shares some vocabulary with the bloc supporting them, their use of words is closer to that of the opposition. Socialdemokratiet’s isolated position in the plot aligns with our findings from inspecting the automated retweet network and from the netnographic observations on our data sites, where we find that Socialdemokratiet tweets less consistently about climate than its supporting bloc, which might explain its placement closer to the opposition.
We find that combining the inspection of the PCA plot with the netnographic observations and relational understandings from our network analysis allows us to analyse how different parties’ word usage on CSI are similar and differing.
PCA as a method has shortcomings that we take into consideration prior to diving into the qualitative assessment of the model. As PCA performs dimensionality reduction, a shortcoming of employing it is that it only explains some of the variance, and that we are only able to see a fraction of the words in our corpus (Abdi, 2019). Therefore, we must critically assess the output bearing our qualitative insights in mind (Blok et al., 2021). We thus experience challenges in interpreting the specific placements of the parties in its socio-symbolic space. These placements are especially ambiguous for the parties that do not post to Twitter about CSI very often, as these are not very represented in the data.
To uncover if and how youth- and mother parties tweet about climate- and sustainability issues (hereafter CSI), we employ a topic model to discover latent topics within our Twitter dataset. We pose two questions that we seek to answer exploratively through the applied method.
1) Can we identify a topic on CSI in the parties’ tweets? If yes, which parties tweet about this topic?
2) How do parties tweet about CSI over time, and are there differences across the generational divide?
We use a Latent Dirichlet Allocation (LDA) topic model, which is an unsupervised machine learning model that uses a bag of words approach to identify latent topic information in large corpora of text (Hong & Davidson, 2010).
LDA is a generative model, meaning that LDA assumes that a document is written by first deciding on a topic distribution and then randomly choose each word in the document based on its weight within the topic and the topics distribution within the document (Atteveldt et al., 2021). Furthermore, LDA works with the assumption that written documents are about several topics at the same time, meaning that a collection of documents will contain the same topics but in different proportions (Blei, 2012). Despite the generative assumptions about how documents are written, an LDA topic model can be used as an effective way to explore which topics are present and how present they are across specific documents. LDA is a probalistic topic model that takes the observed variables (words) and hidden variables (topic structures) and calculates a joint distribution of the two (Blei, 2012; Terman, 2017). When applying LDA on our documents of tweets, the model iterates through each document and identifies the probability distribution over a predefined number of topics. These topics are represented as a probability function over words (Hong & Davidson, 2010).
When performing a content analysis on Twitter, there are some challenges posed by the nature of the text, the most significant being text length. Since tweets are limited to 280 characters, each document is by default shorter than traditional documents such as newspaper articles (Hong & Davidson, 2010). A general point concerning LDA topic models is that the model searches for a predefined number of topics that is manually decided by the researcher. This means that the researcher is also qualitatively assessing when the model is successfully identifying distinguishable topics.
We follow the findings of Hong and Davidson (2010) who conducted an experiment to find the best approach to constructing a topic model on Twitter data. Their study compared the performance of topic models on distinctive designs. The most relevant to mention here are the message (or tweet) scheme and the user scheme, the first taking each tweet as an individual, short document, the latter taking tweets aggregated per each user as documents (Ibid.). The user scheme had fewer, but longer documents, resulting in fewer, but more accurate topic distributions. According to the experiment by Hong and Davidson (2010), this approach resulted in the best performing LDA topic model.
We employ an LDA topic model with the python library gensim. Our data consists of tweets from the timelines of the Twitter profiles of nine mother parties and 10 youth parties. The LDA is employed on two different version of our data. First, we treat all tweets as unique documents. Thereafter, we aggregate tweets on party and week level.
LDA is a text-based method that converts words into numbers and requires preprocessing to simplify the text data given to the model without severely diminishing the interpretability and possible conclusions (Denny & Spirling, 2018). We draw on the preprocessing by Terman (2017) while adapting the steps to our analysis. This resulted in the following preprocessing steps: lowercasing, replacing instances of ‘&’ with ‘og’ (and), removing punctuation, odd special characters, and additional whitespaces. We remove URLs, words with less than three characters, emojis and #dkpol, as our initial attempt to include emojis and all hashtags resulted in uninterpretable topics and poorly performing models despite alterations in number of topics, passes and iterations. We keep all other hashtags and mentions to be able to identify whether specific hashtags or Twitter users are prevalent within any topics. Numbers are kept as our netnographic inquiry showed that numbers such as 2030 are often used to discuss CSI.
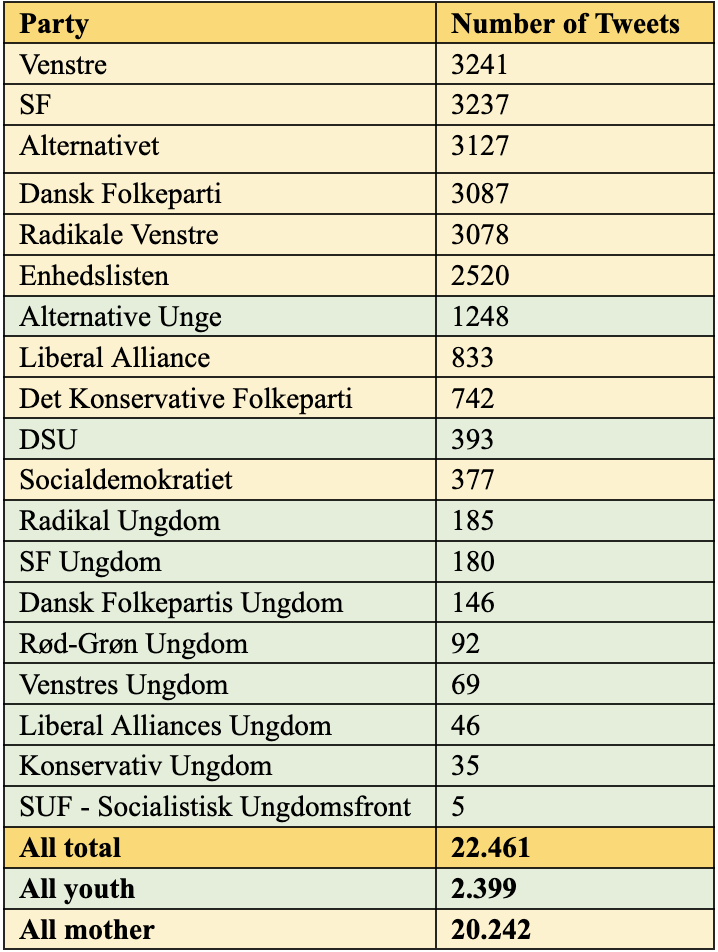
After tokenising all tweets and removing stop words on the nltk stop words list in Danish and English, we stem using the nltk Snowball stemmer in Danish. Tweets that lose their meaning after preprocessing, such as a tweet only consisting of an emoji or a URL, are removed. Our analysis focuses on the timeframe from the beginning of 2019 until the time of our API search (June 3, 2021), resulting in a dataset consisting of 22,641 tweets. The distribution of tweets between parties is illustrated in Table 2.
 |
|---|
| Table 2: Tweet distribution |
We create uni- and bigrams, tokenise and get an id2word dictionary of 250,630 words. We filter away frequently and infrequently used words, resulting in a list of 11,150 words and use doc2bow to create a corpus object consisting of all document tokens.
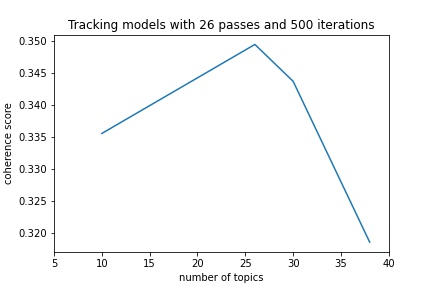
Choosing the number of topics for an LDA model is a non-trivial task that depends on the type of documents and the aim of the study (Roberts, 2014). To identify the optimal number of topics we focus on the coherence score as a measure of how well the model performs as done by Azad (2020). We compute the coherence score for different numbers of topics ranging from 2 up to 200 topics with steps of 6, as illustrated in Figure 5.
 |
|---|
| Figure 5: Number of topics for non-aggregated data |
Drawing on our qualitative readings of the Twitter timelines, we use the first local maximum of 38 topics as the maximum number of topics, since we argue that we will not be able to identify more meaningful topics within our relatively small corpus. We run models with 10, 26, 30 and 38 topics to find the best number topics. Guided by Azad (2020) and our own experimenting, we set the number of passes to 25 and iterations to 500 to balance training the model sufficiently while staying within the scope of what is computationally possible. We set the minimum probability to 0.0 to ensure that all topics are represented with a value in each tweet. We inspect the coherence scores (Figure 6), the top 10 words for the topics in each of the four models and their placement in a visualisation through pyLDAvis (Appendix HTML1). Here, we find that the model with 26 topics performs the best with a coherence score of 0.35.
 |
|---|
| Figure 6: Testing models |
We employ an LDA topic model to exploratively examine our Twitter dataset and get an understanding of the youth- and mother parties’ word usage related to CSI. When validating our model, we draw inspiration from Atteveldt et al. (2021), who recommend qualitatively examining the top words within each topic as well as top documents within each topic. From inspecting and labelling the 26 topics we identify topic 14 and topic 17 as being related to CSI (Appendix Topics).
We compute the gamma, meaning the proportion of each document that is made up of words from the assigned topics. Each document is given a gamma for each of the 26 topics, which sum to a total of 1.0. When qualitatively inspecting the 10 tweets with the highest gamma for topic 14 and 17 respectively, we find all of them to be climate and sustainability related, which suggests that we successfully identified topics on CSI through our LDA model. Tweets with a high coherence score on topic 14 seem to concern specific negotiations between parties, reaching well-defined goals and criticising specific private companies. Meanwhile, topic 17 tweets are about parties communicating their visions for green transition and a more sustainable future.
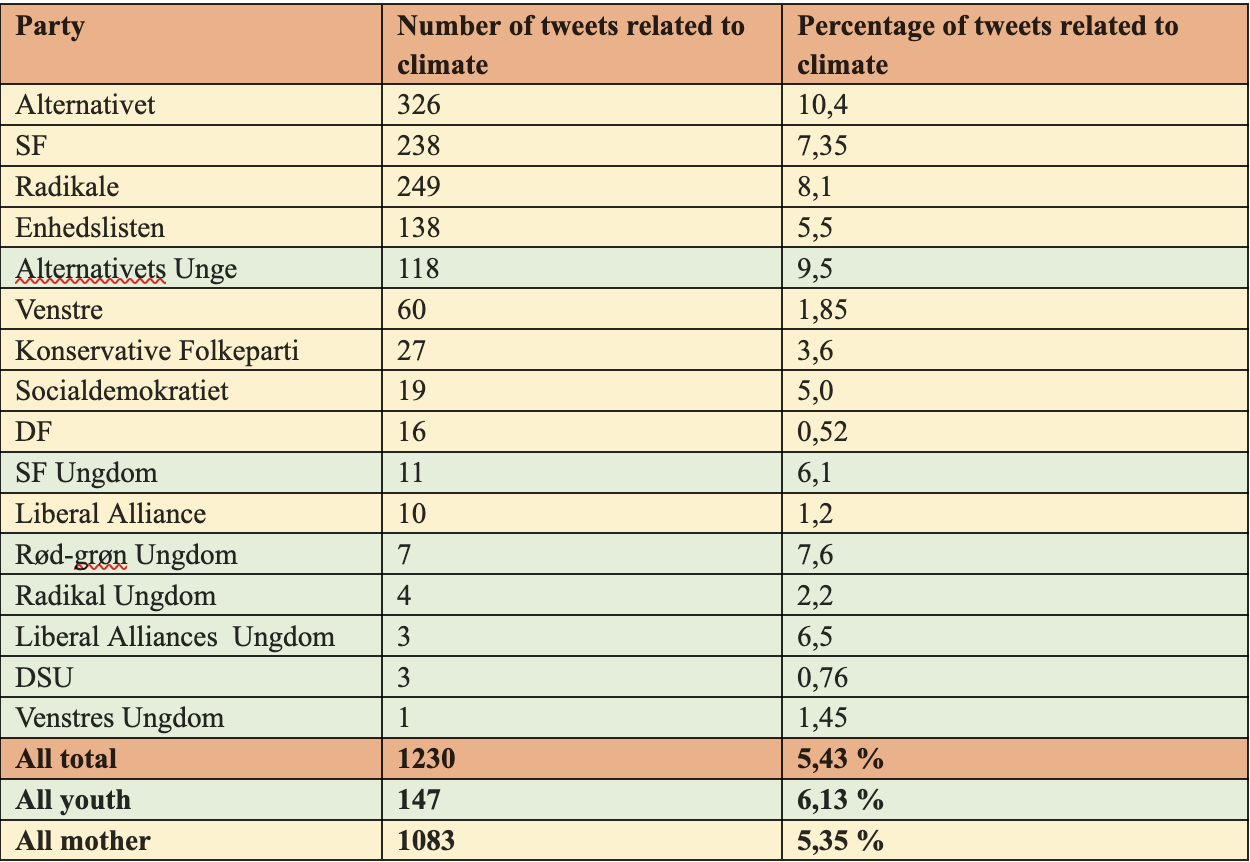
To further inspect whether topic 14 and 17 can be said to concern CSI, we create a subset for each topic including all tweets that have a gamma higher than 0.5 for topic 14 and topic 17 respectively. We inspect the tweets with the lowest gamma for each of these subsets and qualitatively assess that these tweets also (at least partially) concern CSI. We thus define all tweets with a gamma over 0.5 on either topic 14 or topic 17 to concern CSI, which enables us to infer how present CSI is in our Twitter dataset as well as which parties tweet the most about CSI.
 |
|---|
| Table 3: Total number of tweets with gamme >0.5 in topic 14 or 17 per party |
Table 3 shows large variation in how much parties tweet about CSI. For example, our inspection suggests that 10.4% of Alternativet’s tweets are primarily about CSI, while this is only the case for 0.5% of the tweets by DF. The bloc supporting the government tweets significantly more about climate than the opposition parties, where the highest percentage is Konservative (3,6%). Amongst the parties supporting the government, Radikale, SF as well as Enhedslisten, however, tweet more about climate than Socialdemokratiet. We find a similar divide amongst the youth parties, while LAU has a high percentage of climate tweets compared to its mother party.
When looking at the generational divide between youth- and mother parties, we see that the topics on CSI are slightly more prevalent amongst the youth parties. Importantly, there is great variance in the number of tweets posted by each party and our exploration shows a large gap in how much mother- and youth parties tweet, with the latter only having posted 10.7 % of the total number of tweets in our dataset. Consequently, we do not seek to draw any conclusions solely from these results but rather see them in combination with the other methods employed in this study.
While we find the LDA model to perform well on documents consisting of only single tweets, we want to explore if aggregating the tweets into larger documents will cause the model to perform better and produce more interpretable topic distributions, as suggested by Hong and Davidson (2010). Inspired by Barberá et al. (2019), we aggregate tweets on party and week level, meaning that one document consists of all tweets by a party during a certain week. Based on the function that computes the coherence scores for different numbers of topics, we decide on a model with 10 topics, 25 passes and 500 iterations, which achieves a coherence score of 0.74.
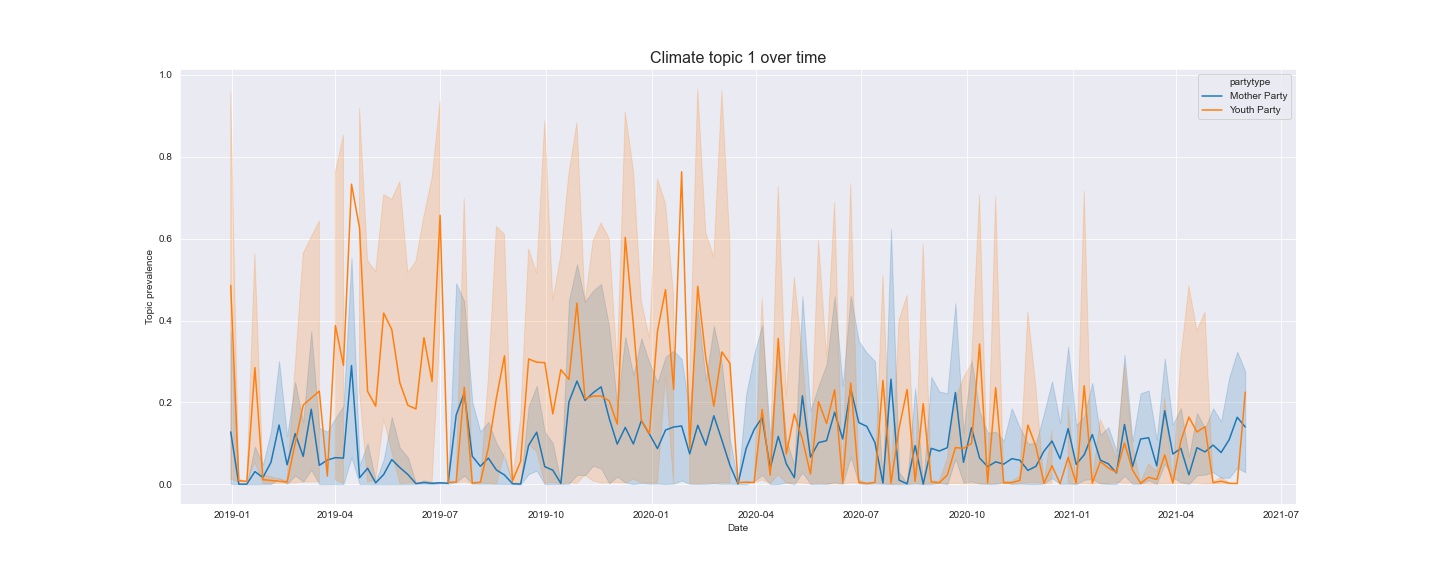
We label the topics by inspecting the top words and visualise the topics with pyLDAvis (Appendix HTML2). We interpret topic 0 and topic 1 to be CSI-related although discriminating between the themes of the topics is less straightforward compared to the topics identified with non-aggregated tweets even though this topic model gives a notably higher coherence score. When sorting the aggregated tweets based on their gammas, we find topic 0 to be highly dominated by Enhedslisten while topic 1 is highly dominated by Alternativet and Alternativets Unge. This could suggest that these parties are frequently and continuously tweeting about CSI. To achieve an understanding of the generational aspects of the temporal development in tweets belonging to either of these topics, we group mother- and youth parties separately. Then we plot the development of topic 0 (Figure 7) and topic 1 (Figure 8) over time.
 |
|---|
| Figure 7: topic 0 |
 |
|---|
| Figure 8: topic 1 |
Amongst the youth parties, topic 1 seems prevalent during election year 2019. Meanwhile, we observe an increase in youth parties’ tweets belonging to topic 0 posted since the summer of 2020. However, we experience sporadic posting-activity on Twitter by the youth parties, compared to their mother party counterparts as well as big differences in number of tweets from each grouping, which could explain some of the inconsistency.
We experience that LDA has shortcomings in relation to the interpretability of the topics as well as all the subjective choices needed regarding number of topics, iterations and passes and defining the meaning of each topic. This is especially prevalent in the aggregated data, which could be caused by the mere fact that we as researchers combine individual tweets that were never intended to be coherent documents. Nevertheless, LDA allows us to explore our data in new ways and identify latent patterns in how words appear in relation to each other.
An alternative approach to examining the parties’ engagement in CSI on Twitter would be employing a sentiment analysis, for example on a subset of tweets concerning CSI. Sentiment analysis is commonly used to analyse political content. For example, in a study by Young and Soroka (2012), they create a dictionary that prove to perform well on manually coded newspaper content from previous electoral campaigns in Canada. Additionally, Brie and Dufresne (2018) employ a sentiment analysis to analyse tweet sentiment in tweets from official campaign organisations during the 2014 Scottish independence referendum.
For our study, we could employ the module SENTIDA, which consists of just about 10.000 lemmas in the Danish language (Lauridsen et al., 2019). This would allow us to gauge if there are general differences in sentiment in the way each party tweet about CSI as well as determine if there are differences between youth- and mother parties in terms of positivity and negativity as well as in the intensity and polarisation of sentiment scores.
There are technical challenges to automated sentiment analyses in smaller languages such as Danish. Firstly, SENTIDA requires lemmatisation, which is not unproblematic in the Danish language, as words tend to change in the process. For instance, in our experience, nej, meaning no, was lemmatised to neje, meaning curtsy. Furthermore, the use of negations to encourage agreement or to pose a question is simply accepted as a negation, and thus changes the sentiment of the entire sentence (Lauridsen et al., 2019). Accordingly, we deem that the LDA topic model would provide us with more useful insights and be a better approach to answering our research question.
We combine qualitative and quantitative perspectives to explore if and how youth- and mother parties engage in the conversation on CSI on Twitter, and whether this reveals a generational divide. Tasked with using digital Twitter data, we tap into a data source from one of the platforms contributing to the increasing availability of digital data (Moats, 2021). We thus position our study in the evolving field of social science research using digital methods and digital data (Marres & Gerlitz, 2016; Munk, 2019).
As described by Marres and Gerlitz (2016), both the digital tools we employ and the social media platforms that serve as the arena for our study are instruments constructed to serve a multitude of purposes and push several agendas. Marres and Gerlitz argue that recognising the multi-valent purposes of both digital tools and social media platforms enables researchers to experiment with the different methods; a methodological process they coin interface methods (Ibid.). When employing methods from Digital Methods and ASDS 2 to data from Twitter and other social media platforms, we work within the scope of interface methods. Consequently, we must conform to and consider the structures of the social media platforms, for example the limits on text length of tweets.
Our study combines qualitative and quantitative methods in what Munk calls a complementary approach (Munk 2019). Complementarity describes allowing qualitative and quantitative methods to perform their separate tasks and play on their different strengths, and then bringing them together to support and enrich each other (Ibid.). This approach has shown useful for grasping how CSI are communicated by youth- and mother parties in our study. An example of this being the analysis of our PCA, where we visualise our actor-term matrix to show patterns of word usage by the parties on Twitter and interpret it informed by our netnography.
When working netnographically, the notion of exploring a field takes on new meaning as the data emerging from online platforms can be dispersed on multiple sites and is generally different from data obtained through the embodied participation characterising ethnography (Kozinets, 2019). Kozinets (2019) therefore renames it a data site in digital contexts. We see this as connected to what Munk (2019) calls the meaning problem. The meaning problem concerns how to extract meaning from data, when the data is not contextualised by the actors it regards, which stems from the digital dissolving materialised fields and thus detaching data from the people it concerns (Ibid.). This requires the researcher to situate the data, or as Munk argues; supply numbers with stories, which he deems essential for addressing the meaning problem (Ibid.).
The challenge of the meaning problem becomes prevalent in our network analysis. While our networks of the parties’ following- and retweet behaviour provide useful insights into how the parties are connected, we risk making claims about the parties being loosely or tightly linked to other actors without being able to check whether this aligns with their own perception (Munk 2019). With our netnographic insights at hand, we are however better suited to assess meaningful connections when interpreting the networks.
In ASDS 2, we use an LDA topic model to explore topical distributions within our Twitter dataset in combination with qualitatively guided interpretation of how the parties tweet about CSI. Topic modelling entails looking at words as single entities, while our qualitative reading facilitates drawing meaning from combinations of words. Thes two approaches to analysing text data contribute to our project in very different manners. One enables us to account for patterns based on a large amount of data, while the other enables us to look for meaning and qualitatively ground our analysis.
The multifaceted methodological approaches allow us to discover a generational divide despite vast differences in Twitter activity between the parties, partially due to the youth parties showing a general preference for using Instagram and to some extent Facebook. Thus, a potential further investigation would ideally entail bringing in text and image data from Facebook and Instagram.
Through netnographic observations, we discover that it is common for youth- as well as mother parties to present CSI as a topic that is more salient to the younger generation. This is supported by our automated retweet network, where youth parties generally retweet more climate actors than the mother-parties. We observe a skewed following behaviour, where youth parties orientate themselves more towards the mother parties on Twitter, while mother parties follow youth parties on Instagram. Furthermore, we find that mother parties’ word usage is reflected in the divide between the bloc supporting the government and the opposition. The supporting parties post more frequently about CSI to Twitter, notwithstanding Socialdemokratiet which post less about climate to the platform than the other parties in the bloc. This division between the supporting- and opposition blocs is generally reflected amongst the youth parties too, while youth parties post more about CSI to Instagram. Lastly, our LDA topic model shows that CSI is detectable as a prevalent topic within our corpus of tweets, while differences in prevalence follow the findings from the other applied methods. Ultimately, we find evidence of a generational divide, where CSI is broadly communicated as a generational issue more salient to the younger generation, as well as evidence that the youth- and mother parties belonging to the supporting bloc, except Socialdemokratiet, post the most about CSI to social media.
van Atteveldt, W., Trilling, D. & Arcila, C. (2021). Computational Analysis of Communication: A practical introduction to the analysis of texts, networks, and images with code examples in Python and R. cssbook.net
Azad, A. (2020, July 13). Twitter Topic Modeling - Towards Data Science. Towards Data Science. Retrieved June 16, 2021 https://towardsdatascience.com/twitter-topic-modeling-e0e3315b12e2
Barberá, P., Casas, A., Nagler, J., Egan, P. J., Bonneau, R., Jost, J. T., & Tucker, J. A. (2019). Who leads? Who follows? Measuring issue attention and agenda setting by legislators and the mass public using social media data. American Political Science Review, 113(4), 883-901.
Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM, 55(4), 77-84.
Brie, E., & Dufresne, Y. (2018). Tones from a Narrowing Race: Polling and Online Political Communication during the 2014 Scottish Referendum Campaign. British Journal of Political Science, 50(2), 497–509. https://doi.org/10.1017/s0007123417000606
Hong, L., & Davison, B. D. (2010, July). Empirical study of topic modeling in twitter. In Proceedings of the first workshop on social media analytics. 80-88.
Denny, M. J., & Spirling, A. (2018). Text preprocessing for unsupervised learning: Why it matters, when it misleads, and what to do about it. Political Analysis, 26(2), 168-189.
Lauridsen, G. A., Dalsgaard, J. A., & Svendsen, L. K. B. (2019). SENTIDA: A New Tool for Sentiment Analysis in Danish. Journal of Language Works-Sprogvidenskabeligt Studentertidsskrift, 4(1), 38-53
Roberts, M. E., Stewart, B. M., Tingley, D., Lucas, C., Leder-Luis, J., Gadarian, S. K., Albertson, B., & Rand, D. G. (2014). Structural Topic Models for Open-Ended Survey Responses. American Journal of Political Science, 58(4), 1064–1082. https://doi.org/10.1111/ajps.12103
Terman, R. (2017). Islamophobia and media portrayals of Muslim women: A computational text analysis of US news coverage. International Studies Quarterly, 61(3), 489-502.
Young, L., & Soroka, S. (2012). Affective news: The automated coding of sentiment in political texts. Political Communication, 29(2), 205-231.
Abdi, H., & Williams, L. J. (2010). Principal component analysis. Wiley interdisciplinary reviews: computational statistics, 2(4), 433-459.
Andini, S. (2020). How People Access News about Climate Change. In: E Newman, N., Fletcher, R., Schulz, A., Andi, S., & Nielsen, R. K. (2020). Reuters Institute Digital News Report 2020. Reuters Institute for Study of Journalism. 52 – 57.
Blok, A. et al. (2021). Inter-risk framing contests. Under review for American Journal of Cultural Sociology
Blok, A. (n.d.). Digital klima-aktivisme i en skandinavisk corona-tid. Coronakrisen.Github. Retrieved June 16, 2021, from https://coronakrisen.github.io/post6.html
Boyd, D., Golder, S., & Lotan, G. (2010, January). Tweet, tweet, retweet: Conversational aspects of retweeting on twitter. In 2010 43rd Hawaii international conference on system sciences. 1-10. IEEE.
Brunton, S. L., & Kutz, J. N. (2019). Data-driven science and engineering: Machine learning, dynamical systems, and control. Cambridge University Press.
Decuypere, M. (2020). Visual Network Analysis: a qualitative method for researching sociomaterial practice. Qualitative Research, 20(1), 73-90.
Edwards, A., Housley, W., Williams, M., Sloan, L., & Williams, M. (2013). Digital social research, social media and the sociological imagination: Surrogacy, augmentation and re-orientation. International Journal of Social Research Methodology, 16(3), 245-260.
Frederiksen. (2020, June 24). Mette Frederiksens tale på valgnatten 2019. Danske Taler. https://dansketaler.dk/tale/mette-frederiksens-tale-paa-valgnatten-2019/
Fuhse, J., Stuhler, O., Riebling, J., & Martin, J. L. (2020). Relating social and symbolic relations in quantitative text analysis. A study of parliamentary discourse in the Weimar Republic. Poetics, 78, 101363.
Hong, L., & Davison, B. D. (2010, July). Empirical study of topic modeling in twitter. In Proceedings of the first workshop on social media analytics. 80-88.
Kim, J., & Yoo, J. (2012, December). Role of sentiment in message propagation: Reply vs. retweet behavior in political communication. In 2012 International Conference on Social Informatics (pp. 131-136). IEEE.
Kozinets, R. V. (2019). Netnography: The essential guide to qualitative social media research. Sage.
MacQueen, K. M., McLellan, E., Kay, K., & Milstein, B. (1998). Codebook development for team-based qualitative analysis. Cam Journal, 10(2), 31-36.
Marres, N., & Gerlitz, C. (2016). Interface methods: Renegotiating relations between digital social research, STS and sociology. The Sociological Review, 64(1), 21-46.
Moats, D. (2021). Rethinking the ‘Great Divide’: Approaching Interdisciplinary Collaborations Around Digital Data with Humour and Irony. Big Data and Society, 34(1), 19-42.
Munk, A. K. (2019). Four styles of quali-quantitative analysis: Making sense of the new Nordic food movement on the web. Nordicom Review, 40(s1), 159-176.
Newman, N., Fletcher, R., Schulz, A., Andi, S., & Nielsen, R. K. (2020). Reuters Institute Digital News Report 2020. Reuters Institute for Study of Journalism. 2020-06.
Rød-Grøn Ungdom. (n.d.). Vedtægter. Retrieved June 16, 2021, from https://www.rgungdom.dk/vedtaegter
Socialistisk Ungdomsfront. (n.d.). Hvem er vi? Retrieved June 16, 2021, from https://ungdomsfront.dk/hvem-er-vi
Sørensen. (2019). Folketingsvalget 2019. Danmarkshistoriendk, Aarhus Universitet. Retrieved June 16, 2021, from https://danmarkshistorien.dk/vis/materiale/folketingsvalget-2019-1/
Thew, H., Middlemiss, L., & Paavola, J. (2020). “Youth is not a political position”: exploring justice claims-making in the UN climate change negotiations. Global Environmental Change, 61, 102036.
Venturini, T., Bounegru, L., Gray, J., & Rogers, R. (2018). A reality check (list) for digital methods. New media & society, 20(11), 4195-4217.