This repository contains an implementation of a Transformer model from scratch using PyTorch. The Transformer architecture is a cornerstone of modern natural language processing (NLP) tasks, enabling efficient and scalable attention mechanisms.
The Transformer model is a neural network architecture introduced in the paper "Attention is All You Need" by Vaswani et al. It has become the foundation for many state-of-the-art models in NLP, including BERT, GPT, and T5. This repository provides a clean and simple implementation of the Transformer model to help you understand its inner workings and experiment with its components.
This comprehensive and practical guide will take you through the process of setting up and using the Transformer model from this repository, helping you to grasp the intricacies of this powerful architecture. By following the tutorial, you'll be well-equipped to delve into the world of Transformers and leverage them for various NLP applications.
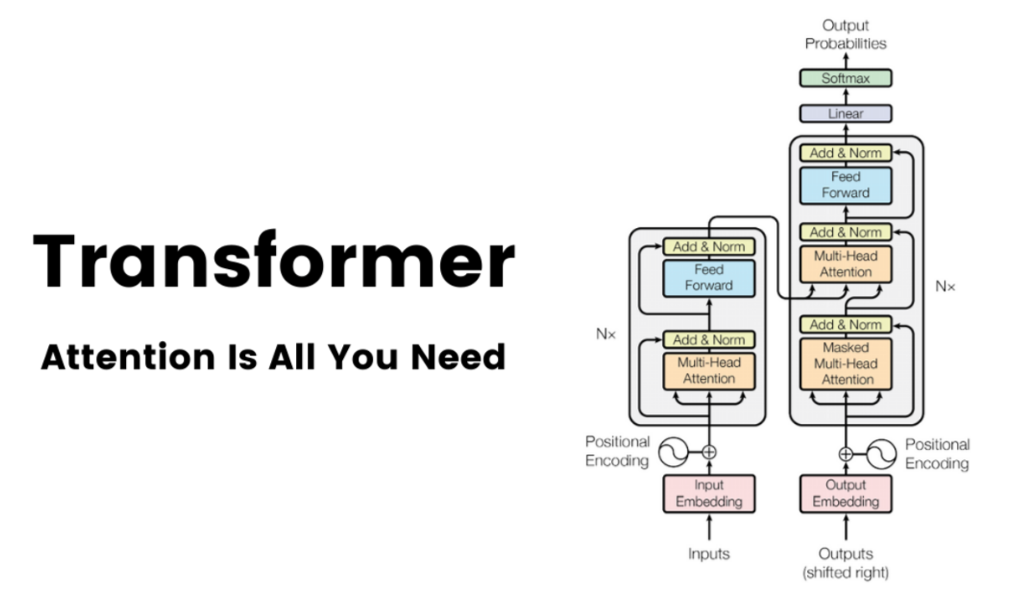
To get started, clone the repository and install the required dependencies. It is recommended to use a virtual environment to manage dependencies.
git clone https://github.com/atikul-islam-sajib/TransformerScratch.git
cd TransformerScratchpython -m venv env
source env/bin/activate # On Windows, use `env\Scripts\activate`
pip install -r requirements.txtThe repository provides scripts and notebooks to help you understand and experiment with the Transformer. Below is an example script that demonstrates how to initialize the Transformer, create random input tensors, and print the shapes of the embedding and output tensors.
.
├── Dockerfile
├── LICENSE
├── README.md
├── artifacts
│ ├── checkpoints
│ │ ├── best_model
│ │ │ └── __init__.py
│ │ └── train_models
│ │ └── __init__.py
│ ├── files
│ │ ├── Transformer.png
│ │ ├── __init__.py
│ │ ├── decoderTransformer.png
│ │ ├── encoderTransformer.png
│ │ ├── feedforward_network.png
│ │ ├── one_decoder.png
│ │ └── one_encoder.png
├── config.yml
├── data
│ ├── processed
│ │ ├── __init__.py
│ │ └── dataloader.pkl
│ └── raw
│ └── __init__.py
├── mypy.ini
├── notebooks
│ ├── ModelProtype.ipynb
│ └── Model_Inference.ipynb
├── requirements.txt
├── setup.py
├── src
│ ├── __init__.py
│ ├── cli.py
│ ├── decoder.py
│ ├── decoder_block.py
│ ├── embedding_layer.py
│ ├── encoder.py
│ ├── encoder_block.py
│ ├── encoder_decoder_attention.py
│ ├── feedforward_network.py
│ ├── inference.py
│ ├── layer_normalization.py
│ ├── mask.py
│ ├── multihead_attention.py
│ ├── positional_encoding.py
│ ├── tokenizer.py
│ ├── transformer.py
│ ├── transformer_attention.py
│ └── utils.py
└── unittest
└── test.py
For detailed documentation on the implementation and usage, visit the -> Transformer Tutorial Notebook
Prepare your data:
english = [
"The sun is shining brightly today",
"I enjoy reading books on rainy afternoons",
"The cat sat on the windowsill watching the birds",
"She baked a delicious chocolate cake for dessert",
"We went for a long walk in the park yesterday",
]
german = [
"Die Sonne scheint heute hell",
"Ich lese gerne Bücher an regnerischen Nachmittagen",
"Die Katze saß auf der Fensterbank und beobachtete die Vögel",
"Sie hat einen leckeren Schokoladenkuchen zum Nachtisch gebacken",
"Wir sind gestern lange im Park spazieren gegangen",
]Define the parameters:
MAX_LENGTH = 200 # Maximum length of the input sequences
BATCH_SIZE = 2 # Number of samples per batch
EMBEDDING_DIMENSION = 512 # Dimensionality of the embedding vectors
NUM_ENCODER_LAYERS = 8 # Number of encoder layers in the Transformer
NUM_DECODER_LAYERS = 8 # Number of decoder layers in the Transformer
NUM_HEADS = 8 # Number of attention heads
DIM_FEEDFORWARD = 2048 # Dimensionality of the feedforward network
DROPOUT = 0.1 # Dropout rate
LAYER_NORM_EPS = 1e-5 # Epsilon for layer normalization
Use the transformers library for tokenization:
from transformers import AutoTokenizer
from torch.utils.data import DataLoader, TensorDataset
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# English Tokenization
english_tokenizer = tokenizer(
english, padding="max_length", truncation=True, return_tensors="pt", max_length=MAX_LENGTH
)
english_tokenizer_results = TensorDataset(english_tokenizer["input_ids"], english_tokenizer["attention_mask"])
english_tokenizer_dataloader = DataLoader(english_tokenizer_results, batch_size=BATCH_SIZE, shuffle=True)
# German Tokenization
german_tokenizer = tokenizer(
german, padding="max_length", truncation=True, return_tensors="pt", max_length=MAX_LENGTH
)
german_tokenizer_results = TensorDataset(german_tokenizer["input_ids"], german_tokenizer["attention_mask"])
german_tokenizer_dataloader = DataLoader(german_tokenizer_results, batch_size=BATCH_SIZE, shuffle=True)
english_vocab_size = german_vocab_size = tokenizer.vocab_sizeInitialize the embedding layer:
from src.embedding_layer import EmbeddingLayer
embedding = EmbeddingLayer(
vocabulary_size=english_vocab_size,
sequence_length=MAX_LENGTH,
dimension=EMBEDDING_DIMENSION,
)Initialize the Transformer model:
from src.transformer import Transformer
transformer_model = Transformer(
d_model=EMBEDDING_DIMENSION,
nhead=8,
num_encoder_layers=8,
num_decoder_layers=8,
dim_feedforward=2048,
dropout=0.1,
layer_norm_eps=1e-5,
)Test the Transformer model with the first batch:
for (english_batch, english_padding_mask), (german_batch, german_padding_mask) in zip(
english_tokenizer_dataloader, german_tokenizer_dataloader
):
english_embeddings = embedding(english_batch)
german_embeddings = embedding(german_batch)
transformer_output = transformer_model(
x=english_embeddings,
y=german_embeddings,
encoder_padding_mask=english_padding_mask,
decoder_padding_mask=german_padding_mask,
)
print(transformer_output.size())
break # Test with only the first batchYou can use a configuration file to manage the parameters for your Transformer Encoder setup. Below is an example of a configuration file named config.yaml.
path:
FILES_PATH: "./artifacts/files/"
PROCESSED_PATH: "./data/processed/"
transformers:
MAX_LENGTH = 200 # Maximum length of the input sequences
BATCH_SIZE = 2 # Number of samples per batch
EMBEDDING_DIMENSION = 512 # Dimensionality of the embedding vectors
NUM_ENCODER_LAYERS = 8 # Number of encoder layers in the Transformer
NUM_DECODER_LAYERS = 8 # Number of decoder layers in the Transformer
NUM_HEADS = 8 # Number of attention heads
DIM_FEEDFORWARD = 2048 # Dimensionality of the feedforward network
DROPOUT = 0.1 # Dropout rate
LAYER_NORM_EPS = 1e-5 # Epsilon for layer normalization
Contributions are welcome! If you have any ideas, suggestions, or bug reports, please open an issue or submit a pull request.
This project is licensed under the MIT License. See the LICENSE file for details.