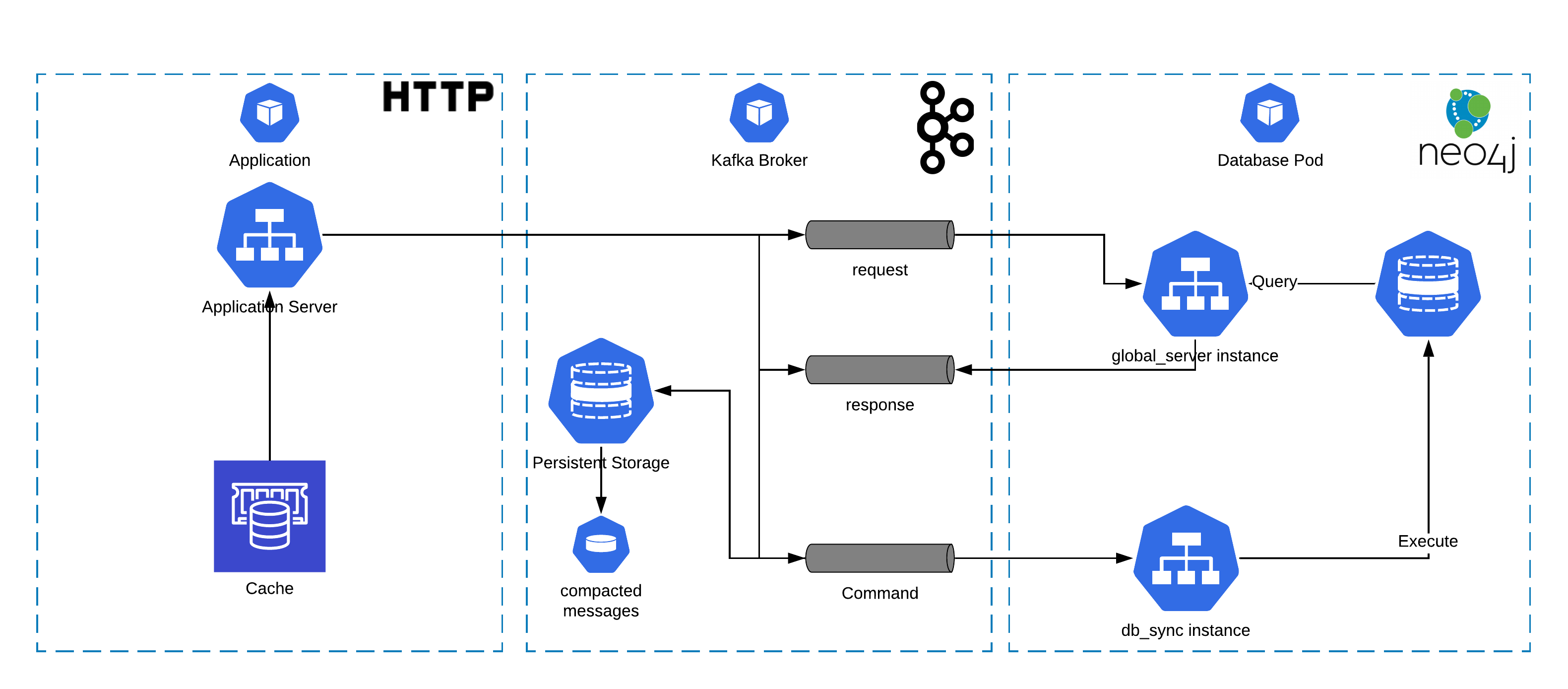
##Motivation
In some cases, replication and cluster serving is an paid or absent feature for some databases. Here I show how to use Apache Kafka to serve and replicate the neo4j that have replication as paid feature. So, here I use the community server to show that is possible to replicate data across databases and serve data from "replicaset" with an reactive perspective.
Environment used to run db_sync.py:
# Kafka
export BROKERS=server1:port1,server2:port2...
export GROUP_ID=group_id
export B_PASSWORD=password # Optional
export B_USERNAME=username # Optional
# Topics
export B_TOPIC_PREFIX=0436wmyx-
export COMMAND_TOPIC=command
# Neo4j
export NEO4J_USER=neo4j
export NEO4J_PASS=data1
export NEO4J_URI=bolt://localhost:7681Environment variables to use with global_server.py:
# KAFKA
export BROKERS=server1:port1,server2:port2...
export GROUP_ID=group_id
export B_PASSWORD=password # Optional
export B_USERNAME=username # Optional
# TOPICS
export B_TOPIC_PREFIX=0436wmyx-
export REQUEST_TOPIC=request
export RESPONSE_TOPIC=response
# NEO4J
export NEO4J_USER=neo4j
export NEO4J_PASS=data1
export NEO4J_URI=bolt://localhost:7681
# name: command, partitions: 1, replicas: 3
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic command
The command topic must have one (1) partition to ensure the order of commands be sync with the topic offset. You can make any replications as you want it will only increase the time of kafka to sync all received message with the other replicas. But by default lets put some replicas, it is important to guarantee no data loss in case of one of the kafka brokers is down or data corrupted.
# name: request, partitions: 3
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic request
# name response, partitions: 3
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic response
The request and response topic is used to query data from any databases. On the request topic you must set as many partitions as replicas of your database, because afterwards you will need instantiate an pseudo server to handle all requests and feed the response topic. In this tutorial we gonna use 3 databases, so, the request topic must have 3 or more partitions to serve each database server.
The response topic does not have specific number of partitions, but it is important to note that it depends on the number of parallel consumers. One consumer can handle 3 partitions but 3 consumers can't handle 1 partition.
To try out this tutorial first we need configure manually one or more instances of neo4j. For that I've used docker to instantiate 3 instances of neo4j on three different ports:
# FIRST DB
docker run \
--publish=7471:7474 --publish=7681:7687 \
--volume=$HOME/neo4j/data:/data \
neo4j
#SECCOND DB
docker run \
--publish=7472:7474 --publish=7682:7687 \
--volume=$HOME/neo4j/data:/data \
neo4j
# THIRD DB
docker run \
--publish=7473:7474 --publish=7683:7687 \
--volume=$HOME/neo4j/data:/data \
neo4j
And then I open my browser to configure neo4j user password on http://localhost:7471/browser/. Do not forget to access this url on three different ports (7471,7472,7473). I have used 3 different passwords for each database, but it is not mandatory.
Open 3 consoles and setup the environments for db_sync.py pointing to the 3 instances databases. This is mandatory to set only one group_id for each db instance to ensure that no data will be unsynchronized. Use Environment Variables Summary as guide to configure your environment variables for db_sync.py. The easiest way I found to do it is set up multiple run configurations on pycharm for each database. After database initialization and configuration, run 3 instances of db_sync.py
After previous step, you must run the global_server.py. Global server must act as one unique server, then all global server group_id should be the same, because each request must be handled one unique time. The neo4j variables must be pointing to the database that it is representing. You can have more than one instance of global server for database with the same configuration variables.
The only one thing you must have in mind is the number of partition of request topic, it always should be greater than global server instances.
For example: I have 3 databases I want to have 1 global server instance for each database, so, the number of partitions must be greater than 2, otherwise some instances of global server will wait for one of the other instances disconnect from kafka to start assume its place.
Visual Studio has a very usefull plugin to manage docker and docker compose files. It also manage running containers, networks and etc...
docker-compose -f "neo4j-kafka-interface\docker-compose.yml" up -d --builddocker-compose -f "neo4j-kafka-interface\docker-compose.yml" down
docker-compose -f "neo4j-kafka-interface\docker-compose.yml" up -d --build
Changes:
- File formatting
- Error treatment
- More effective logging
- Integrating with docker compose
- Direct network connection with compose-kafka_dataflow
- Neo4j network isolation
- Docker plugin image added for README
- Use of JSON object to query and modify database
{
"to": "kafka_query_response_topic",
"with_key":"query_key",
"command":"MATCH (u:User {name :\"user_1\"}) return u"
}{
"with_key":"command_key",
"command":"MERGE (u:User {name :\"user_1\"}) ON MATCH SET u.password = \"pass\" "
}