Problem statement Given :
Sub Dub [Subtitle and Dubbing]: Build a software using deep learning to dub a given audio into other languages with the same emotion and pitch. It can be useful as we don’t need a person with knowledge of multiple languages if we could build voice translation. It will be appreciated if one can build near real time voice translation.
We Develop Our Solution using : Tacotron 2 : A neural network architecture for speech synthesis directly from text.
It consists of two components:
- a recurrent sequence-to-sequence feature prediction network with attention which predicts a sequence of mel spectrogram frames from an input character sequence
- a modified version of WaveNet which generates time-domain waveform samples conditioned on the predicted mel spectrogram frames
Link to understand more on Tacotron : https://github.com/Tomiinek/Multilingual_Text_to_Speech
Our Project Inspiration link : https://github.com/deterministic-algorithms-lab/Cross-Lingual-Voice-Cloning
Reason to Choose Tacotron 2 :
- Initially we were planning to use MFCC feature of input audio but then I was difficult to find resource for generate audio to the same audio input language with changing language and as time was a due to planned to go ahead with pretrained model.
- Single Model suppport multilingual text to speech with voice cloning
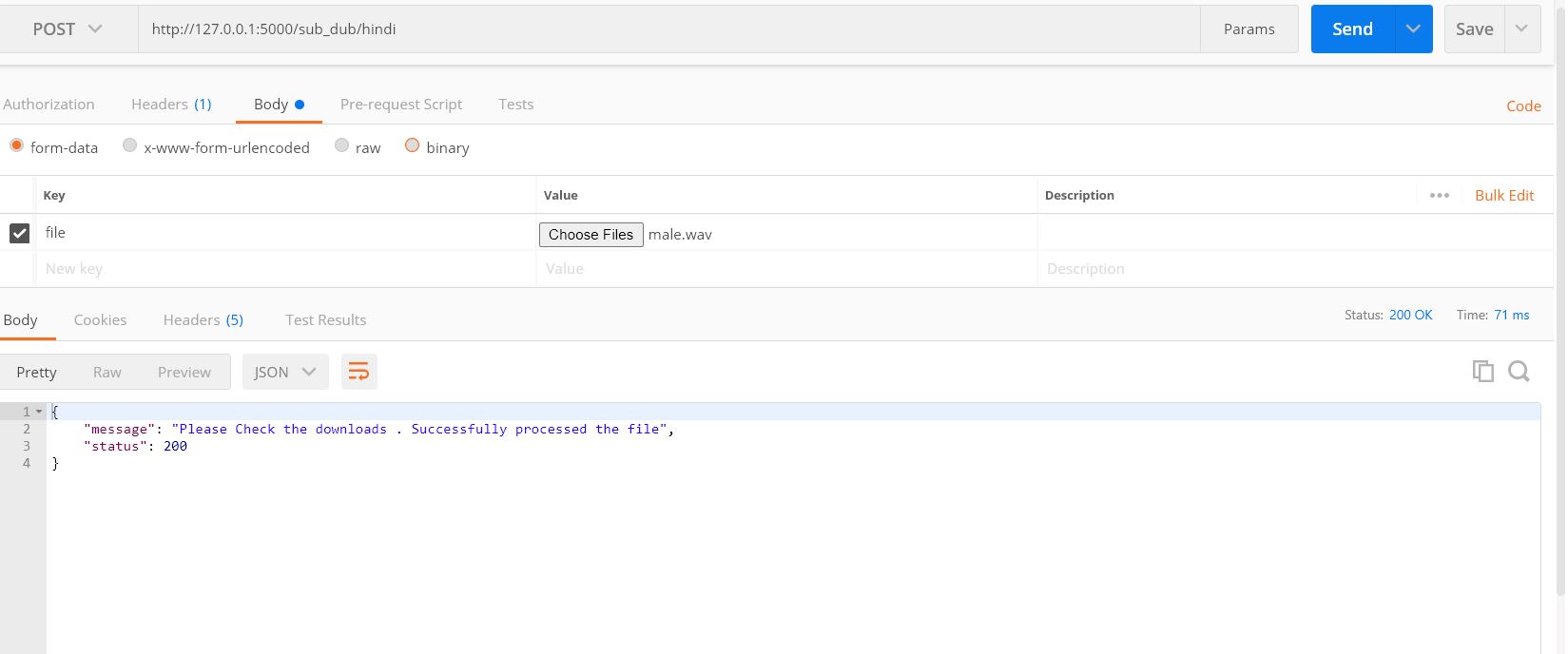
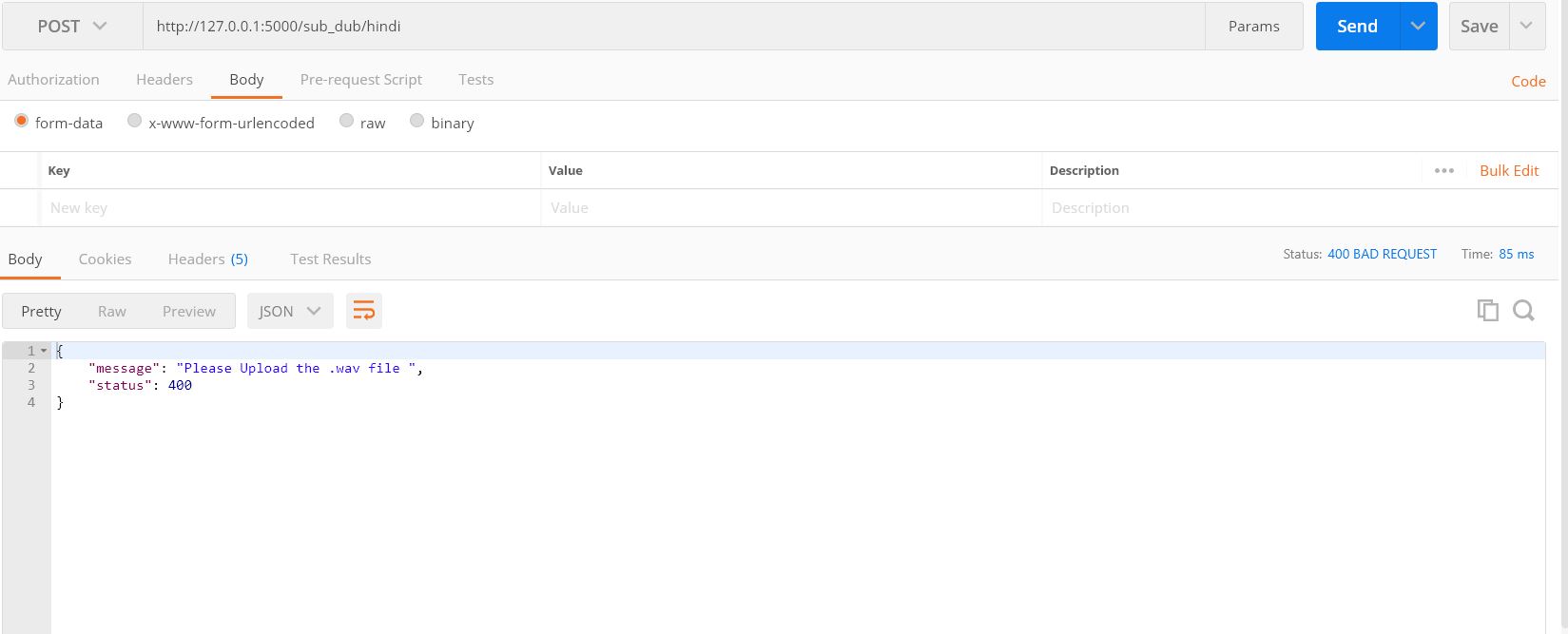
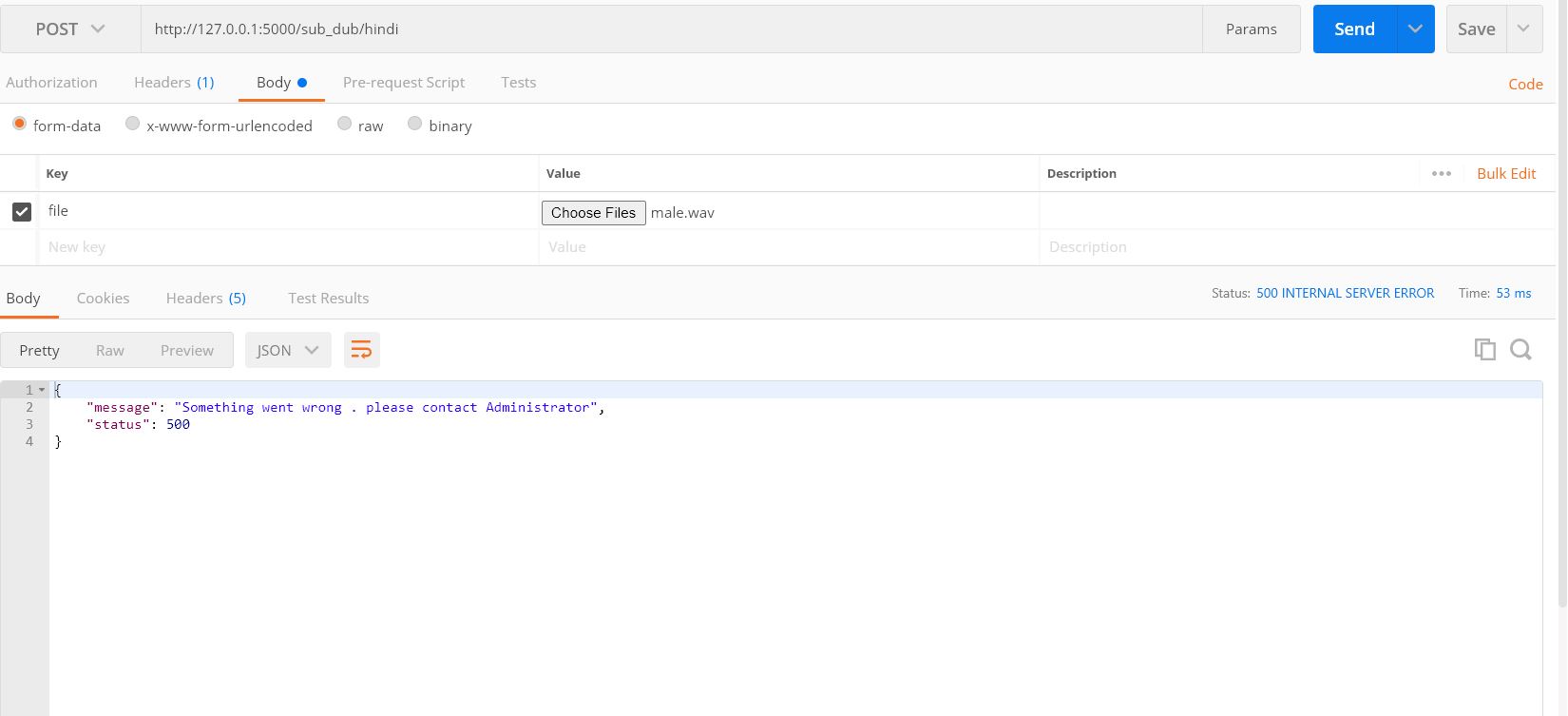
Our Constructed API : takes .wav format audio file and language in the request body and in response it downloades a zip file of processed audio file as requested with language mentioned . API try to Handles status code such as 200 , 400 , 403 , 500 .
Sample Out for status : 400
Sample Out for status : 500
Sample Out for status : 200