ENH: improved precision of darshan job start/end times #830
Conversation
|
Here's what the new output looks like for darshan-parser on an example log: We still just display integer start/end times (and corresponding time string), but runtime is now floating point (4 decimal points shown). |
|
Note that we currently use the following definition in the Darshan job header for these new values: Where a timespec is defined as follows: I think we probably want to change from the
Given that, I guess we should update to a fixed-width definition like: Make sense? |
|
That makes sense to me @shanedsnyder , and the code looks good so far (I know it's not done but I went ahead and looked over what's there). I'd probably be inclined to just make the nsec fields 64 bit too in the log format for simplicity, but I doubt it matters much. |
|
Okay, I have added code for more portable representation of time seconds/nanoseconds in the new job structure, and have also added the backwards compatibility code to up-convert logs with old job description formats. One of the main outstanding issues is how to best calculate the application runtime in Darshan utilities (and PyDarshan) consistently across logs with different versions. The new method for calculating runtime will always produce a non-zero runtime value for newer log versions. However, this method does not properly handle old log versions, which traditionally had their runtime rounded up (i.e., To avoid having version-specific handling in each Darshan utility, I'd be inclined to add a new logutils function for calculating a floating point runtime value. For new versions of logs, it uses the new method introduced in this PR. For old versions, it uses the old method that produces a rounded up integer value (converted to float when returning). Any objections or alternatives to that approach that I should consider? |
I implemented this in 19fe161, seems to work as expected for new logs and old logs from the darshan-logs repo. |
* add struct timespec start/end times to job struct * add custom MPI reduction ops for max/min values of struct timespecs * add logutils code for extracting start/end timespecs * update some analysis utilities to use new timespec values
method for calculating this depends on log format version, so a helper routine seems useful for utilities
* new logutils function (`darshan_log_get_job_runtime`) to
calculate job runtime as a floating point value
* for pre 3.41 logs, this is end-start+1 (i.e., runtime
rounded up to nearest integer)
* for 3.41+ logs, this is exact runtime to nsec precision
* CFFI definition updates of job types, type sizes
* CFFI bindings updates to extract new job timers and runtime
* updates to summary and report interfaces to use new job timers
and runtime values
* updates to plotting code to use new job timers and runtime
values
* `plot_dxt_heatmap.py` in particular had some code removed
that tried to correct for a calculated runtime of 0
* updates to tests to accommodate new changes to various
interfaces and record formats
* `test_plot_dxt_heatmap.py` has changes to avoid need for
rounding up calculated runtime
* new ior-PNETCF/ior-HDF5 log files are included as previous
ones are no longer valid due to log format changes
19fe161 to
d5a7843
Compare
|
Just rebased onto main and added a big commit to get pytest passing for me locally. We'll see how it works with CI more generally. |
|
Not sure what's going on now, but just the ubuntu-latest, 3.10 tests now are hanging. I tried re-running them specifically, and have a closer look but they are hanging essentially immediately upon starting the "test with pytest" step... |
There was a problem hiding this comment.
One concern I have is with the log file turnover here--if we don't add the new log files to the logs repo first, they aren't getting flushed by pytest for report generation in the CI here? And why remove the old ones? They're not being used by any tests or?
create_dxttimeline.py may not really be under test/in active usage?
I suppose I might feel more comfortable if the new log files were in the logs repo so that summary report generation was automatically tested for them.
As for the CI hanging, it may be a memory issue (?)--I believe the MacOS runners have more physical memory available than the Ubuntu runners: https://docs.github.com/en/actions/using-github-hosted-runners/about-github-hosted-runners#supported-runners-and-hardware-resources
Beyond any specific comments I made, the Python changes seem sensible enough and looks like Phil has reviewed the C.
| char mnt_type[3031]; | ||
| char mnt_path[3031]; | ||
| char mnt_type[3015]; | ||
| char mnt_path[3015]; |
There was a problem hiding this comment.
Is this correcting an error unrelated to the primary thrust of this PR or?
There was a problem hiding this comment.
kind of convoluted, but these array sizes are ultimately based on a macro calculation that is based on the size of the Darshan job structure. (job structure grew by 16 bytes in this PR, and you can see above this reduces these array sizes by 16 bytes).
another argument to somehow automate this, as the only reason i realized this needed to be fixed was by observing weird failures in testing
| cols = ["length", "start_time", "end_time", "rank"] | ||
| agg_df = pd.DataFrame(data=data, columns=cols) | ||
| runtime = 1 | ||
| runtime = 2 |
There was a problem hiding this comment.
what's going on here? changing the behavior for the synthetic data set because you always round up under the hood now or?
There was a problem hiding this comment.
that's exactly right
we are always rounding up under the covers for older logs, so calculated runtime in those cases should always be greater than any of the DXT timestamp values. since the DXT timestamps in the synthetic data above reference timestamps greater than 1, the runtime needs to be at least 2 (or more accurately, it needs to be greater than the largest DXT timestamp value, but whole numbers for simplicity).
| ), | ||
| ( | ||
| "shane_ior-PNETCDF_id864223-864223_10-27-46849-11258636277699483231_1.darshan", | ||
| "shane_ior-PNETCDF_id438100-438100_11-9-41525-10280033558448664385_1.darshan", |
There was a problem hiding this comment.
is there much benefit to the turnover of log files here and elsewhere vs. adding to logs repo and flushing through the new logs that way?
There was a problem hiding this comment.
the only reason i switched log files again is that the old ones were generated by a previous development branch (pnetcdf) that we will no longer be able to parse correctly on this branch. essentially, the old logs have the same embedded format versions as the logs in this PR (we only really bump them on release), but the logs do have slightly different underlying formats. this means logutils code can't properly parse the old versions unfortunately.
this is one of the drawbacks on testing logs that were not generated by stable darshan releases (as opposed to dev branches), as we can't reliably guarantee backwards compatibility between releases (well, i guess we could, but we won't).
The new logs should be under test by pytest, they are found in the same locations that various other test logs are found locally in Darshan. Maybe I'm missing the point. I mentioned this above, but I'm not sure there's an easy answer here. Pushing development logs into darshan-logs can cause other issues, particularly if subsequent feature branches further modify log format between releases, breaking ability to parse prior development logs -- in this case, the logs will need to be regenerated. Also, if outside folks wanted to mine through our logs, it might be confusing if they would need specific Darshan branches to parse them. It might be cleaner just to keep test logs locally in Darshan as needed, then flush them all out to darshan-logs at release time once we are sure they have a stable format. I didn't say anything about it in this PR or elsewhere, but that's basically what I was planning to do with these 2 logs. I'm open to other suggestions though.
Ah yeah, looks like it isn't. I just fixed things I noticed when grepping around for job field keys that are no longer around (i.e.
Not sure, I don't really see any output at all from |
|
The advantage of the logs repo is that The backwards compatibility business is pretty confusing, too bad, I think backwards compatibility in general (log files, semi-public struct member ordering) is one of the pain points on the development side at least. Note also that some log files in the logs repo were generated from development hashes/"latest main" type thing I think--it should even say in their README.. so may need to check that. We've seen the CI flush through perfectly today in gh-849, so maybe try again tomorrow if you genuinely think it is a fluke here. On the other hand, I suspect we've been scraping close to the limit for some time, so it may not take much to push us over. GitHub Universe conference is running today and tomorrow, maybe some extra stress from that on the resources. I guess you could open a dummy/test PR that basically changes something innocuous to see if that also fails CI for same reason. |
Maybe make a top-level subdir for unstable version logs in the darshan-logs repo? They could be available for specific CI tests as things land, but omitted from "let's try this on all the example logs" CI cases, and deleted once their immediate purpose is served? Or maybe they shouldn't be in darshan-logs at all, just pull from box or ftp or whatever during dev if we need unstable version logs to test features as they are developed? Just throwing ideas out for discussion. I agree that dev logs in darshan-logs are bad news, at least unless they are clearly categorized differently. |
Yeah, I'm convinced it's something specific to this PR, as #850 passes tests fine now -- ubuntu-latest, python 3.10 is passing in 11 minutes there, and it's just hung for over 20 minutes on this PR. The changeset here isn't trivial, obviously, but I really don't get what specifically could cause a hiccup in the tests (particularly on only one of the CI environments). I didn't add any new tests, just updated expected values for old ones and added a couple of new logs. I'd be a little more comfortable if the tests were clearly failing or at least making progress until some test with larger memory requirements and then stalling, but I'm not seeing any initial clues about what's going on. Any ideas on how to test whether we're close to memory limits or something? Not really sure what else to try here. |
|
One thing to try might be https://pypi.org/project/pytest-monitor/ -- then we could get the per-test memory usage into a sql database->pandas and sort by memory footprint. If nothing else, we could then try disabling ( One thing that we've known for some time is stuff like gh-784 where even an average laptop can't handle some of our DXT stuff until we get those data structure adjustments decided upon, so something tiny might have just pushed it over the edge when things run at the same time perhaps. I'm on vacation til Sunday night, but use your discretion I guess if you need to move forward (maybe open an issue if you temporarily skip/disable some problem tests). |
|
I tried xfailing (with execution blocked) one of the more expensive test cases (just one case, not entire test) when comparing memory footprints against I wasn't entirely convinced of the effect, since
here:
Even if the measured changes above are largely stochastic, we may still see some benefit from suppressing one of the most expensive test cases in the suite (note that we don't suppress the entire test, just that case with large data file). If this still gets us nowhere, we can try adding the verbose ( |
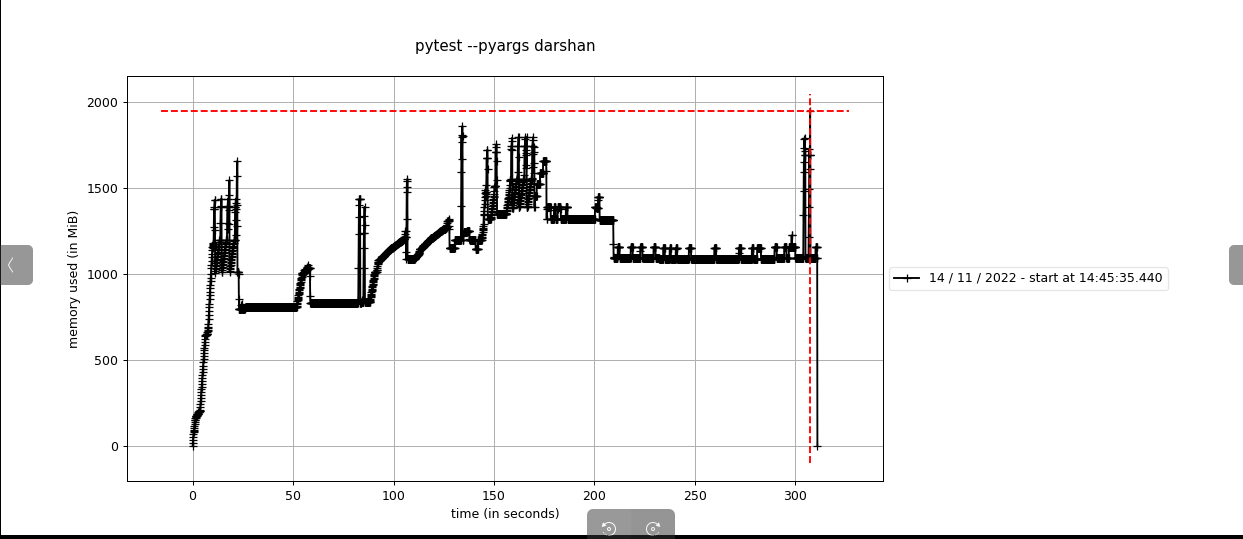
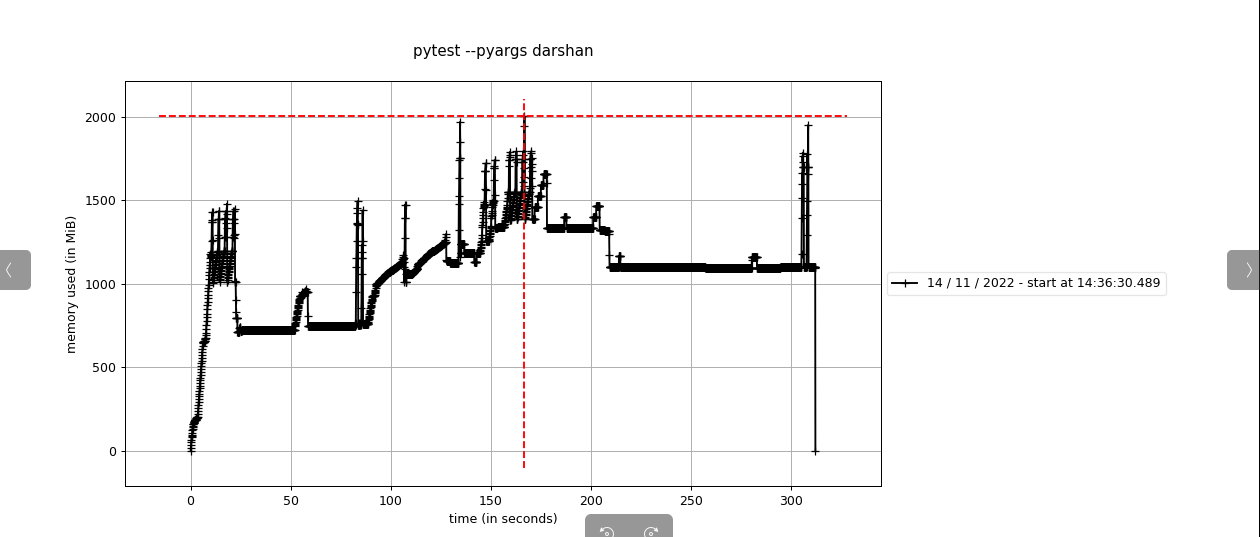
|
|
|
Even with debug mode and verbose
It should be reporting the first several completed tests by then.. I'll try a few more things. It works fine in |

|
argh, let's see if I can use the ssh debug approach to get right on the problem virtual machine per https://github.com/marketplace/actions/debugging-with-ssh |
|
Ok, now we can log right into the affected runner/job using output from the actions log: I'll see if I can reproduce the problem |

|
I confirmed that in the ubuntu-latest Next steps will probably be:
|
* use Ubuntu 22.04 LTS for Python 3.10 testing to avoid mysterious issues described in gh-851
0ce81a4 to
5410a73
Compare
|
Ok, let's see if the approach described in gh-851 works to get CI passing then. It looks like using Ubuntu 22.04 LTS for the Python 3.10 CI job may do the trick, but we'll see. |
|
Ok, the CI is finally passing here. I'd suggest the next steps are:
|
|
All looks good to me, I'll go ahead and merge. FWIW, I agree this is a pretty bizarre bug...it clearly is only triggered by changes introduced on this branch (or other side effects), as other recent PRs (as well as my dummy PR I tried last week) run without issue. The fact that none of the tests ever seem to start is very odd, and given we can only trigger this via CI workflows, debugging it sounds like a nightmare. I agree it's probably not worth us sinking more time in. |
The existing changes already included in the PR:
struct timespecstart/end times to job structTODO items:
start_time/end_timein job header, and rely solely onstart_ts/end_ts