This repository is a minimal template for publishing small FAIR/Linked Data
datasets on the web using only static files (HTML + RDF).
No server configuration, no database, no triple store — just GitHub Pages, like
here: https://dataobservatory-eu.github.io/dataset-template#
data.csv— tabular form of the dataset (easy to inspect and edit)dataset.ttl— RDF in Turtle (human-friendly, hand-editable)dataset.nt— RDF in N-Triples (line-oriented, machine-friendly)index.html— human-readable landing page with links and metadataREADME.md— these instructions
The HTML page includes <link rel="alternate"> tags so RDF-aware clients
can automatically discover the Turtle, N-Triples, and JSON-LD files.
Click the green “Use this template” button on GitHub and create your own copy.
- Edit
data.csvwith your own tabular data. - Regenerate or replace
dataset.ttl,dataset.nt, anddataset.jsonld.
👉 If you use R, you can install the latest released version of
dataset from CRAN with:
install.packages("dataset")
To install the development version from GitHub with pak or remotes:
# install.packages("pak")
pak::pak("dataobservatory-eu/dataset")
# install.packages("remotes")
remotes::install_github("dataobservatory-eu/dataset")
The From R to RDF
vignette will show you how to convert an R data.frame or tibble into an RDF
dataset.
👉 If you don’t use R:
- Replace
dataset.ttlwith your own RDF. - You can hand-edit TTL safely; it’s designed to be human-friendly.
- Validate your file using the IDLab Turtle Validator.
Example of hand editing:
@base <https://dataobservatory-eu.github.io/dataset-template#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#> .
@prefix sdmx-attribute: <http://purl.org/linked-data/sdmx/2009/attribute#> .
@prefix sdmx-code: <http://purl.org/linked-data/sdmx/2009/code#> .
<obs1>
<http://data.europa.eu/83i/aa/GDP> "2354.8"^^xsd:decimal ;
sdmx-dimension:refArea <https://www.geonames.org/countries/AD/> ;
sdmx-dimension:refPeriod "2020"^^xsd:gYear ;
sdmx-dimension:freq sdmx-code:freq-A ;
sdmx-attribute:unitMeasure <https://dd.eionet.europa.eu/vocabularyconcept/eurostat/unit/CP_MEUR> ;
sdmx-attribute:obsStatus sdmx-code:obsStatus-A .
For hand-editing, some basic Turtle knowledge:
-
The prefix contains vocabulary definitions, for example, as country (geopolitical entity) names. If you want to change Andorra to Iceland, you need to change https://www.geonames.org/countries/AD/ to https://www.geonames.org/countries/IS/. Because sdmx-dimension is defined (as you see in the prefix) as the geographical reference area, this will read as
observation 1has the reference area ofAndorra(orIceland). -
For the correct import/export of numbers, dates, characters, the XML definitions is used, if you have a string saying
"music"^^<xsd:string>, you can replace it with another string like"lyrics"^^<xsd:string>.
This page is now available at https://dataobservatory-eu.github.io/dataset-template/. You would like to see your dataset on your GitHub Page, and you need to do the following.
- Go to Settings → Pages.
- Choose main branch, / (root) folder.
- Save
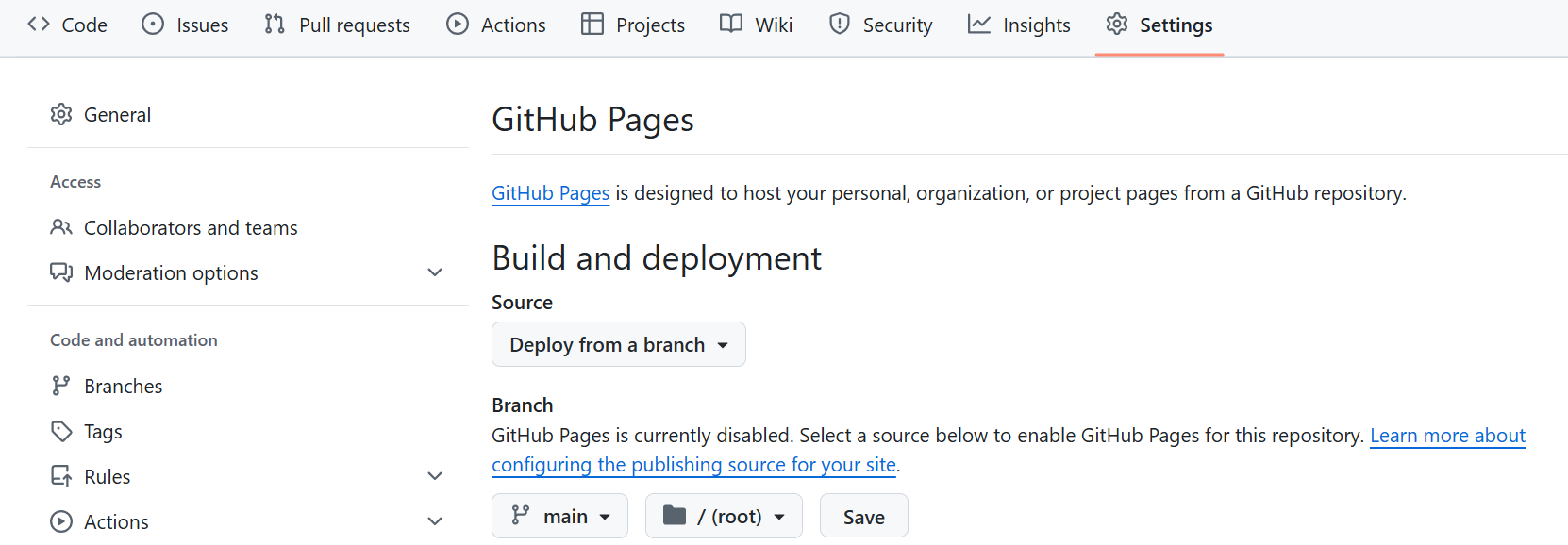
Your dataset will now be available at: https://USERNAME.github.io/REPO-NAME/
with a base namespace
https://USERNAME.github.io/REPO-NAME#
Do not forget to https://dataobservatory-eu.github.io/dataset-template# with your own
repo’s URL when adapting the template in the RDF files, like in the Turtle
example above.
You can edit a HTML file even with a word processor like Word or LibreOffice. If you want to use our template, and you do not want to create a new page, you can open the file
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Your Dataset Title</title>
<!-- Link to machine-readable RDF -->
<link rel="alternate" type="application/n-triples" href="dataset.nt">
<link rel="alternate" type="text/turtle" href="dataset.ttl">
<link rel="alternate" type="application/ld+json" href="dataset.jsonld">
</head>
<body>
<h1>Your Dataset Title</h1>
<p>
This page provides a human-readable landing page for the example dataset
used in the <code>dataset</code> R package.
</p>
<p>
Each observation has a persistent identifier such as:<br>
<a href="#obs1">https://dataobservatory-eu.github.io/dataset-template#obs1</a>
</p>
<p>
For example, <strong>obs1</strong> corresponds to the first row in
<a href="data.csv">data.csv</a> and is also available in RDF serialisations:
</p>
<ul>
<li><a href="dataset.nt">N-Triples</a></li>
<li><a href="dataset.ttl">Turtle</a></li>
<li><a href="dataset.jsonld">JSON-LD</a></li>
</ul>
</body>
</html>
Developed by Reprex as part of the dataobservatory
ecosystem.
We hope this lowers the barrier for researchers to publish semantically enriched, FAIR datasets — even without specialised infrastructure.