learn GAN through self-taught
architecture:

更多细节查看 Blog

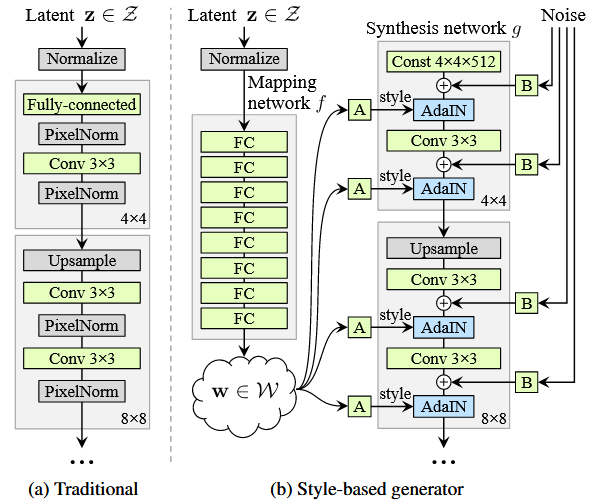
find the code at my kaggle and the trained model in examples/stylegan/trained_.
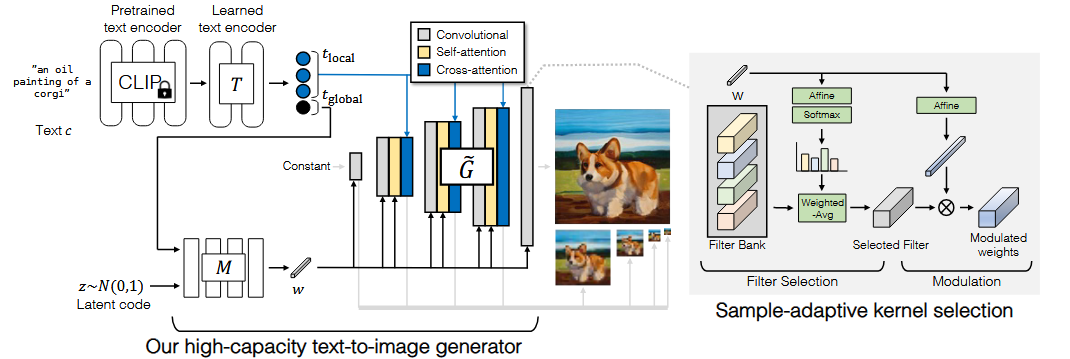
尽管最近在生成式图像建模方面取得了进展,但从ImageNet等复杂数据集中成功地生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,本文在目前尚未尝试的最大规模上训练生成对抗网络,并研究这种规模下的不稳定性。本文发现,将正交正则化应用到生成器中,可以使其成为一种简单的"截断技巧",通过减少生成器输入的方差,从而对样本保真度和多样性之间的权衡进行精细控制。本文的修改导致了模型,它在类条件图像合成中设定了新的技术状态。当在128 × 128分辨率的ImageNet上训练时,本文的模型( Big GANs )获得了166.5的Inception Score ( IS )和7.4的FID
广为流传的一种说法是GAN难以训练,文献中的GAN架构中充斥着经验主义的花招。本文提供了反对这一主张的证据,并以更有原则的方式建立了现代GAN基线。首先,本文推导了一个性能良好的正则化相对论GAN损失,解决了先前通过一揽子ad - hoc技巧解决的模式丢弃和不收敛问题。本文从数学上分析了损失,并证明了它与大多数现有的相对论损失不同,具有局部收敛保证。其次,这种损失允许本文抛弃所有的ad - hoc技巧,并使用现代架构替换普通GAN中使用的过时骨干。以StyleGAN2为例,本文提出了一个新的简化和现代化的路线图,由此产生了一个新的极简基线- - R3GAN ( '再GAN ')。尽管简单,本文方法在FFHQ,ImageNet,CIFAR和Stacked MNIST数据集上超过了StyleGAN2,并且与最先进的GAN和扩散模型进行了比较


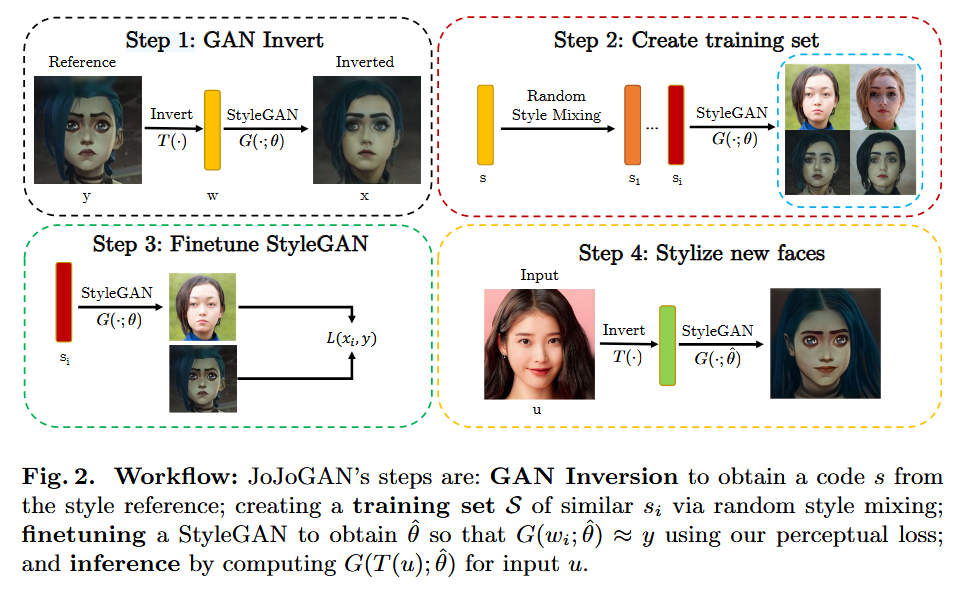
风格映射器对其输入图像(所以,例如,把人脸拿到卡通上)应用某种固定的风格。本文描述了一个简单的步骤- - JoJoGAN - -从风格的单个例子中学习一个风格映射器。JoJoGAN使用GAN的反转过程和StyleGAN的文体杂糅属性从单个示例样式中产生大量的成对数据集。然后使用配对数据集对StyleGAN进行微调。然后通过GAN - Inversion映射图像的风格,再通过微调的StyleGAN映射图像的风格。JoJoGAN只需要一个参考数据,训练时间仅需30秒。JoJoGAN可以成功地使用极端风格引用(比如动物的脸)。
-
GAN反演:将参考风格图像y进行GAN反演,得到一个风格编码w = T ( y ),并由此得到一组s参数s ( w )。
-
训练集:用s来寻找一组与s "接近"的风格编码S,对于si∈S,Pairs ( si , y)就是成对的训练集。
-
微调:对StyleGAN进行微调,得到使得G(si; θˆ) ≈ y
-
推理:对于输入u,得到的风格化人脸是G(s(T (u)); θˆ)