Add Elasticsearch semantic search quickstart #1922
There are no files selected for viewing
{kind=link}
{kind=link}
{kind=link}
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,25 @@ | ||
| --- | ||
| applies_to: | ||
| serverless: ga | ||
| products: | ||
| - id: elasticsearch | ||
| --- | ||
|
|
||
| # {{es}} quickstarts | ||
|
|
||
| Our quickstarts reduce your time-to-value by offering a fast path to learn about search strategies. | ||
| Each quickstart provides: | ||
|
|
||
| - A highly opinionated, fast path to a specific use case | ||
| - Sensible configuration defaults with minimal configuration required | ||
|
|
||
| Follow the steps in these guides to get started quickly: | ||
|
|
||
| - [](/solutions/search/get-started/semantic-search.md) | ||
|
|
||
| For more advanced API examples, check out [](/solutions/search/api-quickstarts.md). | ||
|
|
||
| ## Related resources | ||
|
|
||
| - [](/get-started/index.md): an introduction to Elastic | ||
| - [](/manage-data/ingest.md): an overview of data ingestion methods |
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,211 @@ | ||
| --- | ||
| navigation_title: Semantic search | ||
| description: An introduction to semantic search in Elasticsearch. | ||
| applies_to: | ||
| serverless: all | ||
| stack: all | ||
| products: | ||
| - id: elasticsearch | ||
| --- | ||
| # Get started with semantic search | ||
|
|
||
| _Semantic search_ is a type of AI-powered search that enables you to use natural language in your queries. | ||
| It returns results that match the meaning of a query, as opposed to literal keyword matches. | ||
| For example, if you want to search for workplace guidelines on a second income, you could search for "side hustle", which is not a term you're likely to see in a formal HR document. | ||
|
|
||
| Semantic search uses {{es}} [vector database](https://www.elastic.co/what-is/vector-database) and [vector search](https://www.elastic.co/what-is/vector-search) technology. | ||
| Each _vector_ (or _vector embedding_) is an array of numbers that represent different characteristics of the text, such as sentiment, context, and syntactics. | ||
| These numeric representations make vector comparisons very efficient. | ||
|
|
||
| In this quickstart guide, you'll create vectors for a small set of sample data, store them in {{es}}, then run a semantic query. | ||
| By playing with a simple use case, you'll take the first steps toward understanding whether it's applicable to your own data. | ||
|
|
||
| ## Prerequisites | ||
|
|
||
| - If you're using [{{es-serverless}}](/solutions/search/serverless-elasticsearch-get-started.md), create a project that is optimized for vectors. To add the sample data, you must have a `developer` or `admin` predefined role or an equivalent custom role. | ||
| - If you're [running {{es}} locally](/solutions/search/run-elasticsearch-locally.md), start {{es}} and {{kib}}. To add the sample data, log in with a user that has the `superuser` built-in role, such as `elastic`. | ||
|
|
||
| To learn about role-based access control, check out [](/deploy-manage/users-roles/cluster-or-deployment-auth/user-roles.md). | ||
|
|
||
| <!-- | ||
| TBD: What is the impact of this "optimized for vectors" option? | ||
| --> | ||
|
|
||
| ## Create a vector database | ||
|
|
||
| When you create vectors (or _vectorize_ your data), you convert complex and nuanced documents into multidimensional numerical representations. | ||
| You can choose from many different vector embedding models. Some are extremely hardware efficient and can be run with less computational power. Others have a greater understanding of the context, can answer questions, and lead a threaded conversation. | ||
| The examples in this guide use the default Learned Sparse Encoder ([ELSER](/explore-analyze/machine-learning/nlp/ml-nlp-elser.md)) model, which provides great relevance across domains without the need for additional fine tuning. | ||
|
|
||
| The way that you store vectors has a significant impact on the performance and accuracy of search results. | ||
| They must be stored in specialized data structures designed to ensure efficient similarity search and speedy vector distance calculations. | ||
| This guide uses the [semantic text field type](elasticsearch://reference/elasticsearch/mapping-reference/semantic-text.md), which provides sensible defaults and automation. | ||
|
|
||
| :::::{stepper} | ||
| ::::{step} Create an index | ||
| An index is a collection of documents uniquely identified by a name or an alias. | ||
| You can follow the guided index workflow: | ||
|
|
||
| - If you're using {{es-serverless}}, go to **{{es}} > Home**, select the semantic search workflow, and click **Create a semantic optimized index**. | ||
lcawl marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| - If you're running {{es}} locally, go to **{{es}} > Home** and click **Create API index**. Select the semantic search workflow. | ||
|
|
||
| When you complete the workflow, you will have sample data and can skip to the steps related to exploring and searching it. | ||
| Alternatively, run the following API request in the [Console](/explore-analyze/query-filter/tools/console.md): | ||
lcawl marked this conversation as resolved.
Outdated
Show resolved
Hide resolved
|
||
|
|
||
| ```console | ||
| PUT /semantic-index | ||
| ``` | ||
|
|
||
| For an introduction to the concept of indices, check out [](/manage-data/data-store/index-basics.md). | ||
lcawl marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| :::: | ||
| ::::{step} Create a semantic_text field mapping | ||
| Each index has mappings that define how data is stored and indexed, like a schema in a relational database. | ||
| The following example creates a mapping for a single field ("content"): | ||
|
|
||
| ```console | ||
| PUT /semantic-index/_mapping | ||
| { | ||
| "properties": { | ||
| "content": { | ||
| "type": "semantic_text" | ||
| } | ||
| } | ||
| } | ||
| ``` | ||
|
|
||
| When you use `semantic_text` fields, the type of vector is determined by the vector embedding model. | ||
| In this case, the default ELSER model will be used to create sparse vectors. | ||
|
|
||
| For a deeper dive, check out [Mapping embeddings to Elasticsearch field types: semantic_text, dense_vector, sparse_vector](https://www.elastic.co/search-labs/blog/mapping-embeddings-to-elasticsearch-field-types). | ||
lcawl marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| :::: | ||
|
|
||
| ::::{step} Add documents | ||
|
|
||
| You can use the Elasticsearch bulk API to ingest an array of documents: | ||
|
|
||
| ```console | ||
| POST /_bulk?pretty | ||
| { "index": { "_index": "semantic-index" } } | ||
| {"content":"Yellowstone National Park is one of the largest national parks in the United States. It ranges from the Wyoming to Montana and Idaho, and contains an area of 2,219,791 acress across three different states. Its most famous for hosting the geyser Old Faithful and is centered on the Yellowstone Caldera, the largest super volcano on the American continent. Yellowstone is host to hundreds of species of animal, many of which are endangered or threatened. Most notably, it contains free-ranging herds of bison and elk, alongside bears, cougars and wolves. The national park receives over 4.5 million visitors annually and is a UNESCO World Heritage Site."} | ||
| { "index": { "_index": "semantic-index" } } | ||
| {"content":"Yosemite National Park is a United States National Park, covering over 750,000 acres of land in California. A UNESCO World Heritage Site, the park is best known for its granite cliffs, waterfalls and giant sequoia trees. Yosemite hosts over four million visitors in most years, with a peak of five million visitors in 2016. The park is home to a diverse range of wildlife, including mule deer, black bears, and the endangered Sierra Nevada bighorn sheep. The park has 1,200 square miles of wilderness, and is a popular destination for rock climbers, with over 3,000 feet of vertical granite to climb. Its most famous and cliff is the El Capitan, a 3,000 feet monolith along its tallest face."} | ||
| { "index": { "_index": "semantic-index" } } | ||
| {"content":"Rocky Mountain National Park is one of the most popular national parks in the United States. It receives over 4.5 million visitors annually, and is known for its mountainous terrain, including Longs Peak, which is the highest peak in the park. The park is home to a variety of wildlife, including elk, mule deer, moose, and bighorn sheep. The park is also home to a variety of ecosystems, including montane, subalpine, and alpine tundra. The park is a popular destination for hiking, camping, and wildlife viewing, and is a UNESCO World Heritage Site."} | ||
| ``` | ||
|
|
||
| The bulk ingestion might take longer than the default request timeout. | ||
| If it times out, wait for the ELSER model to load (typically 1-5 minutes) then retry it. | ||
| If you're using {{es-serverless}}, you can check the model state in **{{project-settings}} > {{models-app}}**. | ||
| <!-- | ||
| TBD: Stack app location | ||
| --> | ||
|
|
||
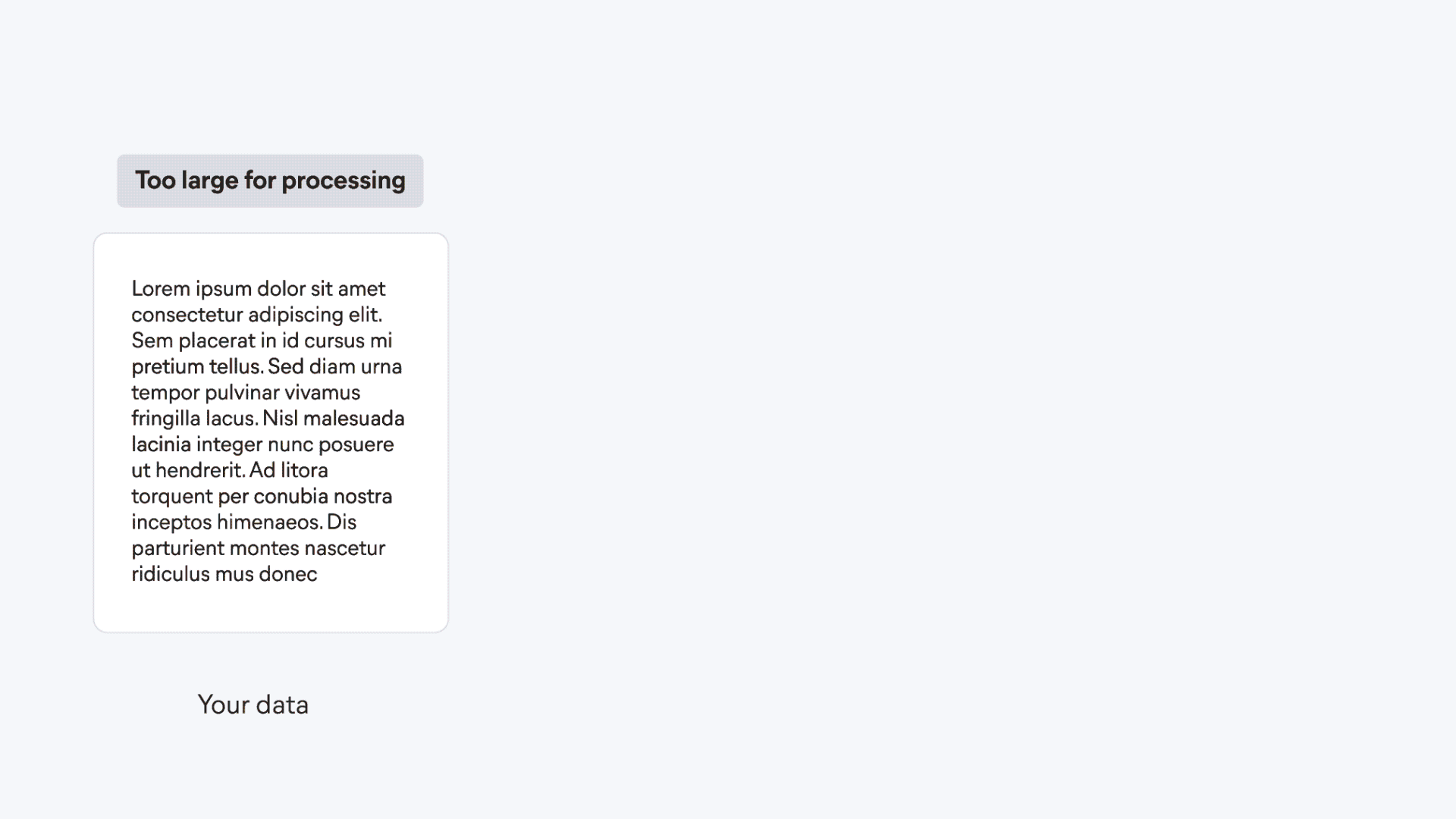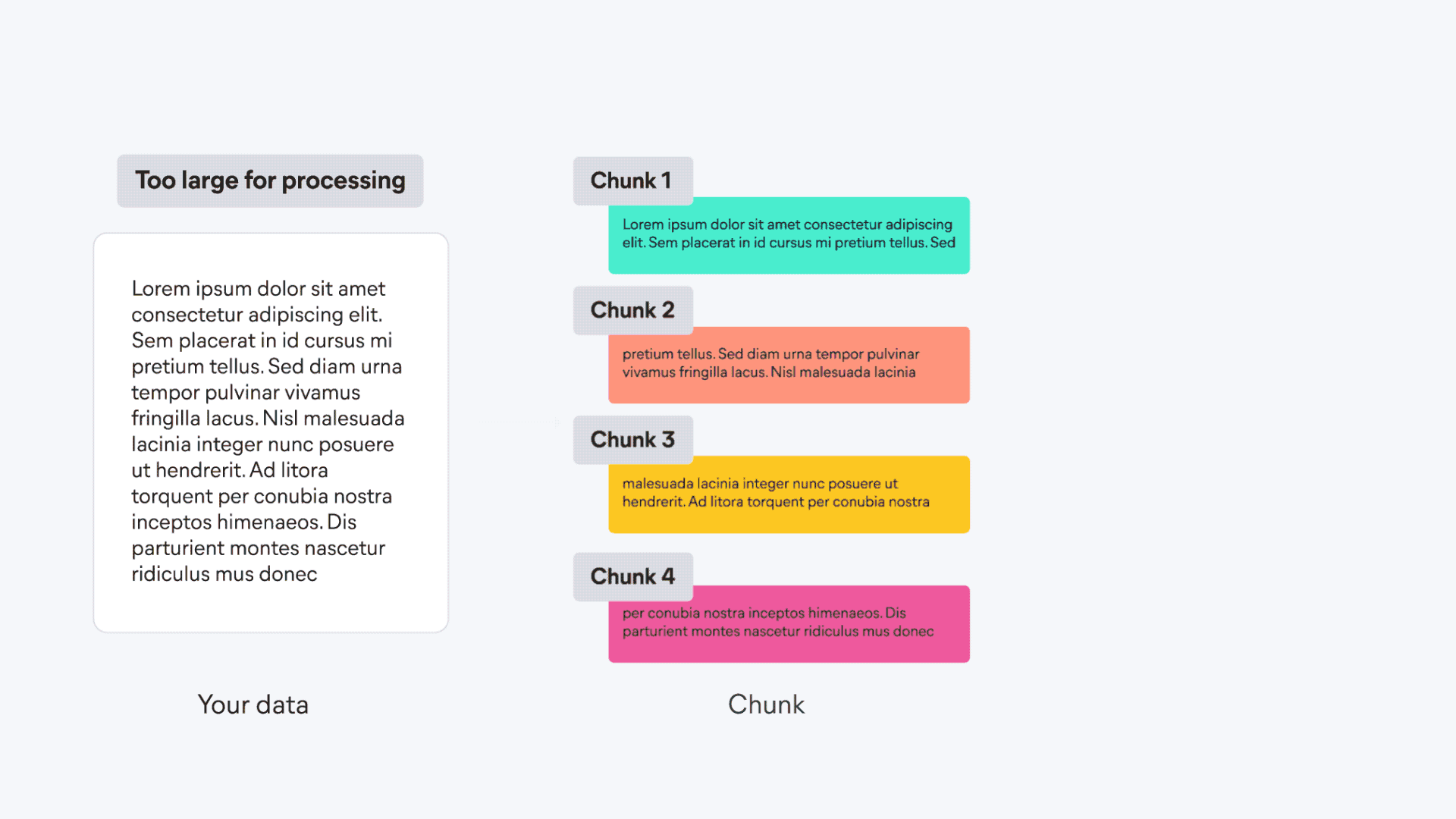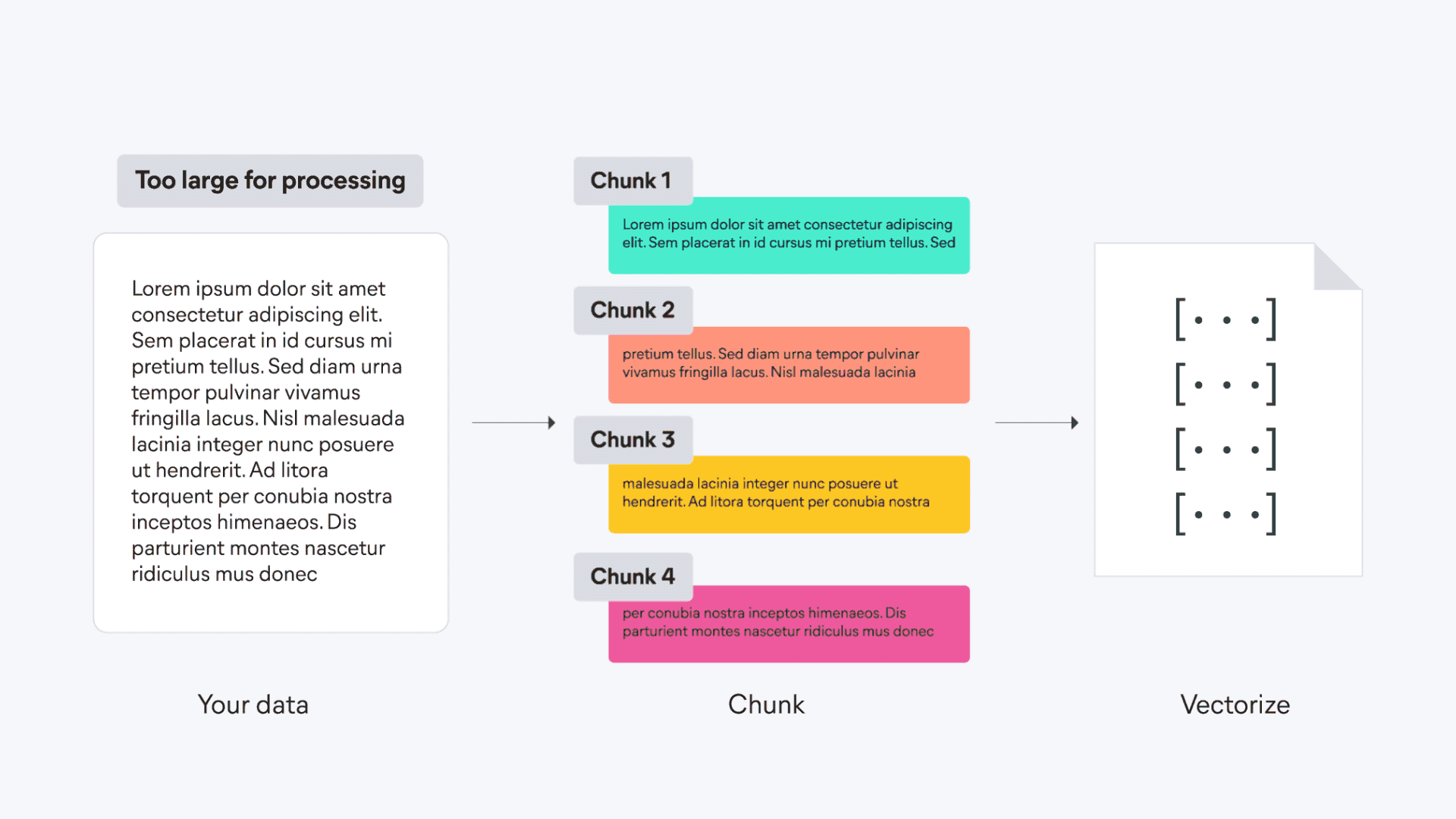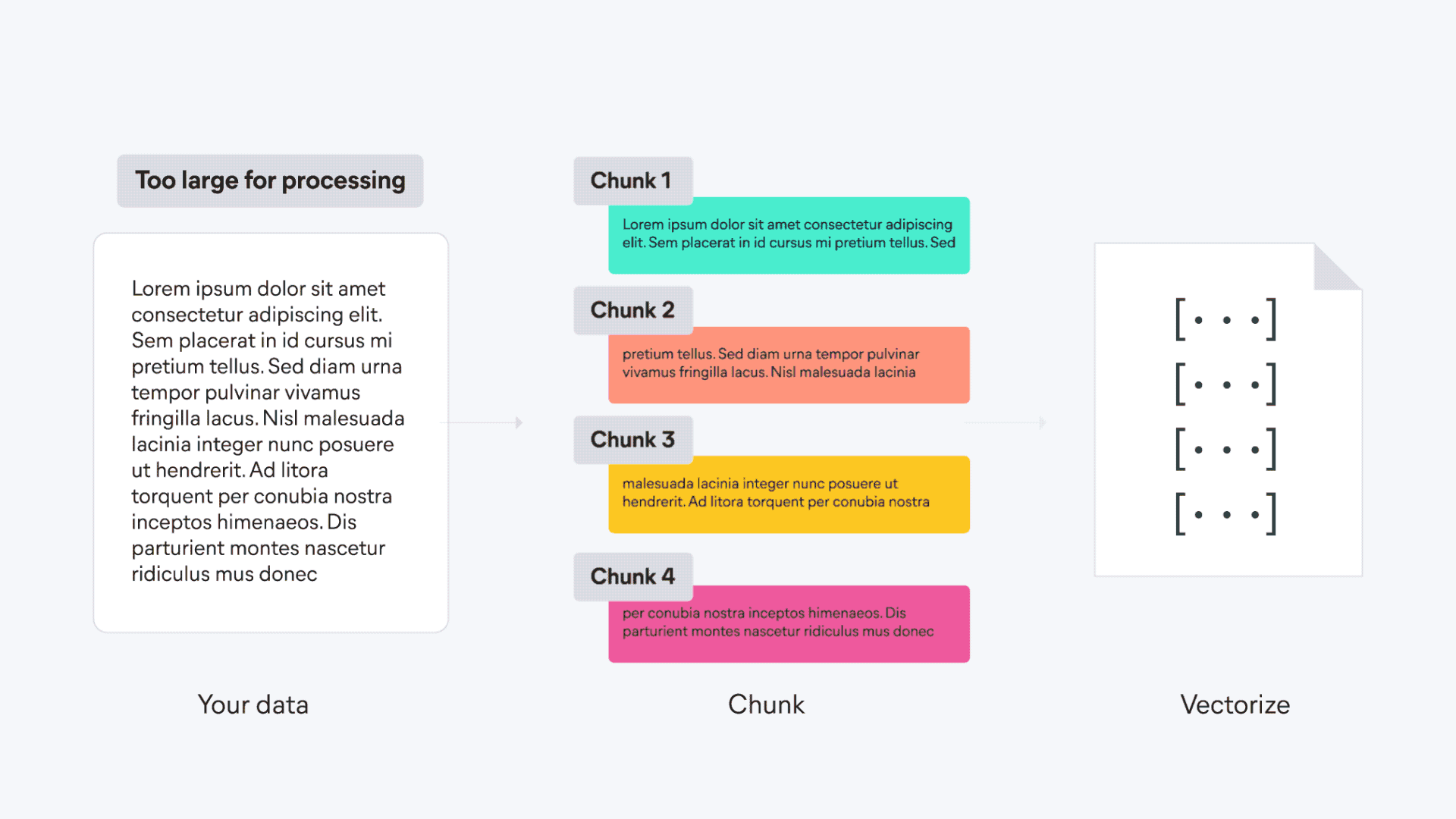
| First, the content is divided into smaller, manageable chunks to ensure that meaningful segments can be more effectively processed and searched. | ||
| Each chunk of text is then transformed into a sparse vector by using the ELSER model's text expansion techniques. | ||
|
|
||
|  | ||
|
There was a problem hiding this comment. Not sure if this is helpful here, but would definitely be nice in the main chunking explanations page(s) There was a problem hiding this comment. Do you have a particular page in mind? I thought maybe the tokenizer reference but the callout at the top of that page makes it clear that the ML tokenization and vectorization are not covered there, so it seems like that would have to be somewhere in the https://www.elastic.co/docs/solutions/search/ai-search/ai-search branch. There was a problem hiding this comment. I don't really unfortunately most of our chunking information is sitting in Elasticsearch Labs blogs 😞
Yup chunking is pertinent to vector/semantic search. We do have this page in E&A: https://www.elastic.co/docs/explore-analyze/elastic-inference/inference-api#infer-chunking-config |
||
|
|
||
| The vectors are stored in {{es}} and are ready to be used for semantic search. | ||
| :::: | ||
| ::::{step} Explore the data | ||
|
|
||
| To familiarize yourself with this data set, open [Discover](/explore-analyze/discover.md) from the navigation menu or by using the [global search field](/explore-analyze/find-and-organize/find-apps-and-objects.md). | ||
|
|
||
| In **Discover**, you can click the expand icon  to show details about documents in the table. | ||
|
|
||
| :::{image} /solutions/images/serverless-discover-semantic.png | ||
| :screenshot: | ||
| :alt: Discover table view with document expanded | ||
| ::: | ||
|
|
||
| For more tips, check out [](/explore-analyze/discover/discover-get-started.md). | ||
| :::: | ||
| ::::: | ||
|
|
||
| ## Test semantic search | ||
|
|
||
| When you run a semantic search, the text in your query must be turned into vectors that use the same embedding model as your vector database. | ||
| This step is performed automatically when you use `semantic_text` fields. | ||
| You therefore only need to pick a query language and a method for comparing the vectors. | ||
|
|
||
| :::::{stepper} | ||
| ::::{step} Choose a query language | ||
|
|
||
| {{es}} provides a variety of query languages for interacting with your data. | ||
| For an overview of their features and use cases, check out [](/explore-analyze/query-filter/languages.md). | ||
| The [Elasticsearch Query Language](/explore-analyze/query-filter/languages/esql.md) (ES|QL) is designed to be easy to read and write. | ||
| It enables you to query your data directly in **Discover**, so it's a good one to start with. | ||
|
|
||
| Go to **Discover** and select **Try ES|QL** from the application menu bar. | ||
| :::: | ||
| ::::{step} Choose a vector comparison method | ||
| You can search data that is stored in `semantic_text` fields by using a specific subset of queries, including `knn`, `match`, `semantic`, and `sparse_vector`. | ||
| For the definitive list of supported queries, refer to [](elasticsearch://reference/elasticsearch/mapping-reference/semantic-text.md). | ||
|
|
||
| In ES|QL, you can perform semantic searches on `semantic_text` field types using the same match syntax as full-text search. | ||
| For example: | ||
|
|
||
| ```esql | ||
| FROM semantic-index <1> | ||
| | WHERE content: "what's the biggest park?" <2> | ||
| | LIMIT 10 <3> | ||
| ``` | ||
|
|
||
| 1. The FROM source command returns a table of data from the specified index. | ||
| 2. A simplified syntax for the MATCH search function, this command performs a semantic query on the specified field. Think of some queries that are relevant to the documents you explored, such as finding the biggest park or the best for rappelling. | ||
| 3. The LIMIT processing command defines the maximum number of rows to return. | ||
|
|
||
| When you click **▶Run**, the results appear in a table. | ||
| Each row in the table represents a document. | ||
| <!-- | ||
| TBD: Run the same query in Console | ||
| --> | ||
| To learn more about these commands, refer to [](elasticsearch://reference/query-languages/esql/esql-syntax-reference.md) and [](/solutions/search/esql-for-search.md). | ||
| :::: | ||
| ::::{step} Analyze the results | ||
|
|
||
| To have a better understanding of how well each document matches your query, add commands to include the relevance score and sort the results based on that value. | ||
| For example: | ||
|
|
||
| ```esql | ||
| FROM semantic-index METADATA _score <1> | ||
| | WHERE content: "best spot for rappelling" | ||
| | KEEP content, _score <2> | ||
| | SORT _score DESC <3> | ||
| | LIMIT 10 | ||
| ``` | ||
|
|
||
| 1. The `METADATA` clause provides access to the query relevance score, which is a [metadata field](elasticsearch://reference/query-languages/esql/esql-metadata-fields.md). | ||
| 2. The KEEP processing command affects the columns and their order in the results table. | ||
| 3. The results are sorted in descending order based on the `_score`. | ||
|
|
||
| :::{tip} | ||
| Click the **ES|QL help** button to open the in-product reference documentation for all commands and functions or to get recommended queries that will help you get started. | ||
| ::: | ||
|
|
||
| :::{image} /solutions/images/serverless-discover-semantic-esql.png | ||
| :screenshot: | ||
| :alt: Run an ES|QL semantic query in Discover | ||
| ::: | ||
|
|
||
| In this example, the first row in the table is the document related to Rocky Mountain National Park, which had the highest relevance score for the query. | ||
|
|
||
| For more tips, check out [Using ES|QL in Discover](/explore-analyze/discover/try-esql.md). | ||
| :::: | ||
| ::::: | ||
|
|
||
| <!-- | ||
| TBD: Delete index and stop model? | ||
| --> | ||
|
|
||
| ## Next steps | ||
|
|
||
| Thanks for taking the time to try out semantic search in {{es-serverless}}. | ||
| For a deeper dive, go to [](/solutions/search/semantic-search.md). | ||
|
|
||
| If you want to extend this example, try an index with more fields. | ||
| For example, if you have both a `text` field and a `semantic_text` field, you can combine the strengths of traditional keyword search and advanced semantic search. | ||
| A [hybrid search](/solutions/search/hybrid-semantic-text.md) provides comprehensive search capabilities to find relevant information based on both the raw text and its underlying meaning. | ||
|
|
||
| To learn about more options, such as vector and keyword search, go to [](/solutions/search/search-approaches.md). | ||
| For a summary of the AI-powered search use cases, go to [](/solutions/search/ai-search/ai-search.md). | ||
Uh oh!
There was an error while loading. Please reload this page.