Author: Dre Dyson Advisor: Dr. Cohen Published: Apr 24, 2025
- Introduction
- Project Goal
- Computational Resources
- Methodology
- Analysis and Results
- Conclusion
- Acknowledgements
Large Language Models (LLMs) like ChatGPT and Llama 3 have demonstrated remarkable capabilities in understanding and processing complex information. However, these general-purpose models often lack the specialized knowledge required for niche topics, such as the intricacies of a specific vehicle like the Chrysler Crossfire (Ling, et al., 2024).
Online communities dedicated to vehicles like the Chrysler Crossfire are invaluable repositories of owner-generated knowledge, including troubleshooting tips, repair procedures, and common issues. This information, however, is often fragmented across forums and difficult to navigate. Furthermore, these communities develop unique jargon and an understanding of common problems that general LLMs cannot grasp.
This project explores fine-tuning an LLM using community-generated content specific to the Chrysler Crossfire. The aim is to create a model that understands the unique challenges, solutions, jargon, OEM part numbers, and recurring problems associated with this vehicle.
The primary goal of this project is to develop a specialized LLM that can:
- Understand and respond to Chrysler Crossfire-specific queries.
- Learn common jargon, OEM part numbers, and recurring vehicle issues.
- Facilitate troubleshooting, diagnostics, and repair procedures for Chrysler Crossfire owners, even those with limited automotive expertise.
- Bridge the knowledge gap and empower owners to better understand and maintain their vehicles.
- GPU Cluster: 4 x NVIDIA V100 GPUs for fine-tuning Meta's Llama Model.
- APIs:
- Deepseek API: Utilized with AugmentToolKit for synthetic data generation.
- OpenRouter API: Used for prompting and judging Meta's Llama 3.1 models during evaluation.
This project developed a Chrysler Crossfire-specific LLM through several key stages: data collection and preparation, conversational dataset generation using AugmentToolKit, selecting from Meta's Llama 3 Herd of Models, and fine-tuning the chosen model using Unsloth.
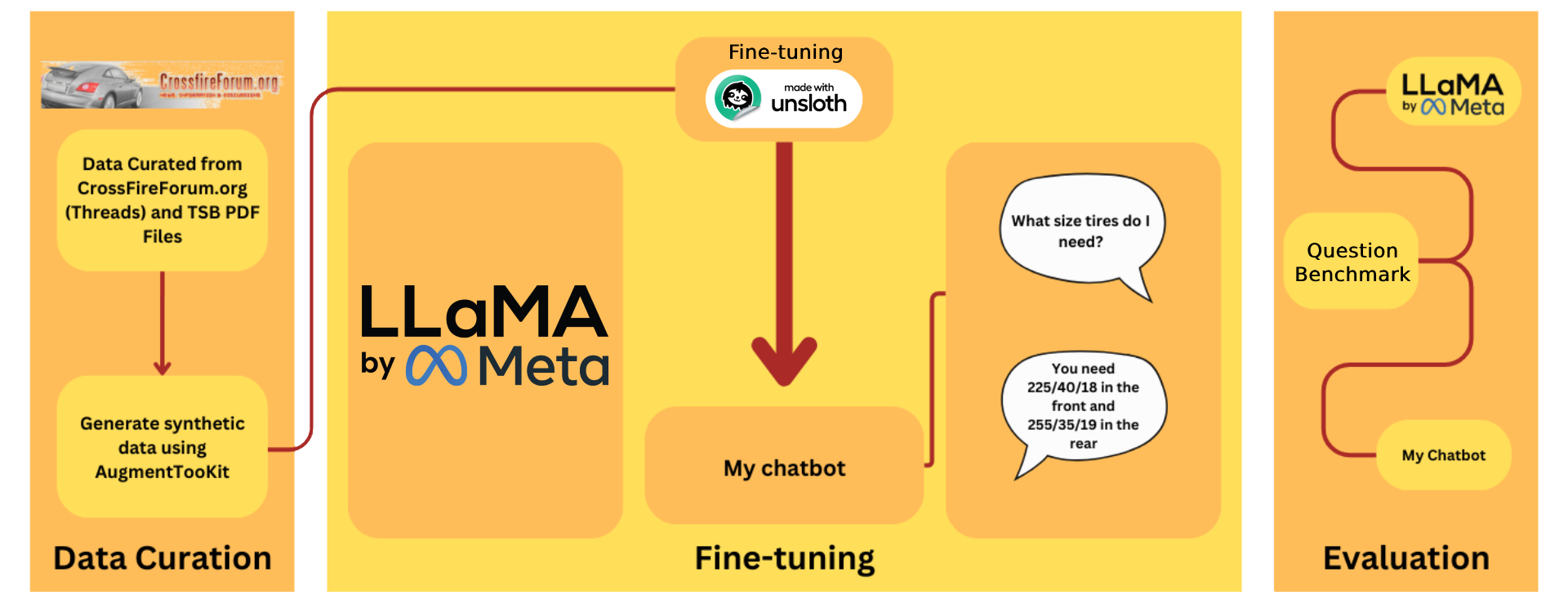
- Forum Scraping: A
bashscript usingwgetwas executed to scrape the popular Chrysler Crossfire forumhttp://crossfireforum.org. This created a local mirror of the forum's structure.- Subdirectories Scraped:
all-crossfires,crossfire-coupe,crossfire-roadster,crossfire-srt6,troubleshooting-technical-questions-modifications,tsbs-how-articles, andwheels-brakes-tires-suspension. - View Scraper Code (Placeholder)
- Subdirectories Scraped:
- Data Parsing: An
Rscript was used to parse the scraped HTML forum posts into a single dataframe, yielding approximately 60,000 Chrysler Crossfire-related text corpuses. - Sampling: A convenience sampling approach was applied to select ~26,447 forum posts covering diverse topics like ownership experiences, expectations, and common issues.
- Manual Collection: 32 PDF files containing manufacturer technical documentation and user-submitted how-to guides were manually collected.
- Input for Augmentation: The raw text corpus and PDF files were provided to AugmentToolKit for synthetic data generation.
AugmentToolKit (ATK) is an open-source toolkit designed to automatically convert raw text into high-quality, custom datasets for training LLMs (Armstrong et al., 2024).
- Workflow: ATK processes an input folder (containing forum posts and PDFs), converts all files into a single text file, and then uses a user-specified LLM (Deepseek API in this project) to generate questions for each line of text. This is followed by data integrity checks.

- Pipeline Used: Multi-turn conversational question and answer pipeline.
- LLM for Generation: Deepseek’s API (chosen for its lack of rate limits and low token pricing).
- Output: 8,385 conversational question and answer pairs for fine-tuning.
In mid-2024, Meta introduced the Llama 3 family of LLMs. These models, built on transformer architecture, range from 8B to 405B parameters and are available as Base or Instruct versions.
- Base Model: Trained on unlabeled data for general language understanding and generation. Ideal for open-ended tasks but requires fine-tuning for specialization.
- Instruct Model: A fine-tuned version of the Base model, optimized for following user instructions using Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
For this project, we selected Meta’s Llama 3.1 8B Instruct Model for fine-tuning.
Unsloth is a framework that streamlines LLM training, handling data preparation, model loading/quantization, training, evaluation, and exporting.
- Model Loading: Unsloth loads a quantized model (Llama 3.1 8B 4-bit) and its tokenizer.
- Dataset Formatting: The raw dataset was converted into a standardized 'Alpaca' conversational style, natively supported by HuggingFace's Supervised Fine-tuning Trainer (SFT) (von Werra et al., 2020).
- SFTTrainer Configuration:
per_device_train_batch_size: 2gradient_accumulation_steps: 4 (Effective batch size: 8)num_train_epochs: 3learning_rate: 1e-4lr_scheduler_type:cosinewarmup_steps: 50fp16orbf16mixed-precision trainingadamw_8bitoptimizer
- Training: The Llama 3.1 8B model was fine-tuned for approximately 3,000 steps.
The collected data from Chrysler Crossfire online forums provided rich insights into common issues, DIY repairs, technical documentation, and general owner discussions. After processing with AugmentToolKit, we obtained a conversational dataset for fine-tuning.
Table 1: Fine-tuning Dataset Characteristics
| Metric | Value |
|---|---|
| No. of dialogues | 8385 |
| Total no. of turns | 79663 |
| Avg. turns per dialogue | 9.5 |
| Avg. tokens per turn | 41.62 |
| Total unique tokens | 70165 |
Table 1: Summarizes the characteristics of the conversational dataset (from all.jsonl). |
Topic modeling was performed on the fine-tuning dataset to understand prevalent themes, as recommended by Meta (2024).
Table 2: Topic Distribution in Fine-tuning Dataset
| Domain | No. dialogues |
|---|---|
| crankshaft position sensor, position sensor cps, got also heard | 148.0 |
| speed manual transmission, first step take, still bit confused | 134.0 |
| question car performance, question run issue, naturally aspirated car | 102.0 |
| check engine light, make also heard, affect car performance | 124.0 |
| question car modification, naturally aspirated engine, hear car trouble | 128.0 |
| question installation process, fan control module, control module located | 94.0 |
| cold air intake, air intake system, auto part store | 133.0 |
| question chrysler crossfire, uneven tire wear, second quartermile time | 131.0 |
| rear fog light, relay control module, throttle position sensor | 118.0 |
| car audio system, car electrical system, also heard something | 119.0 |
| question car maintenance, spark plug wire, connector guide bushing | 120.0 |
| Table 2: Key discussion areas and their frequency in the conversational dataset. The prominence of "crankshaft position sensor" aligns with its known failure rate in Chrysler Crossfires. |
Training Optimizations with Weights & Biases:
Training progress was monitored using Weights & Biases, tracking train/learning_rate and train/loss over ~3,000 steps (approx. 13 hours).
-
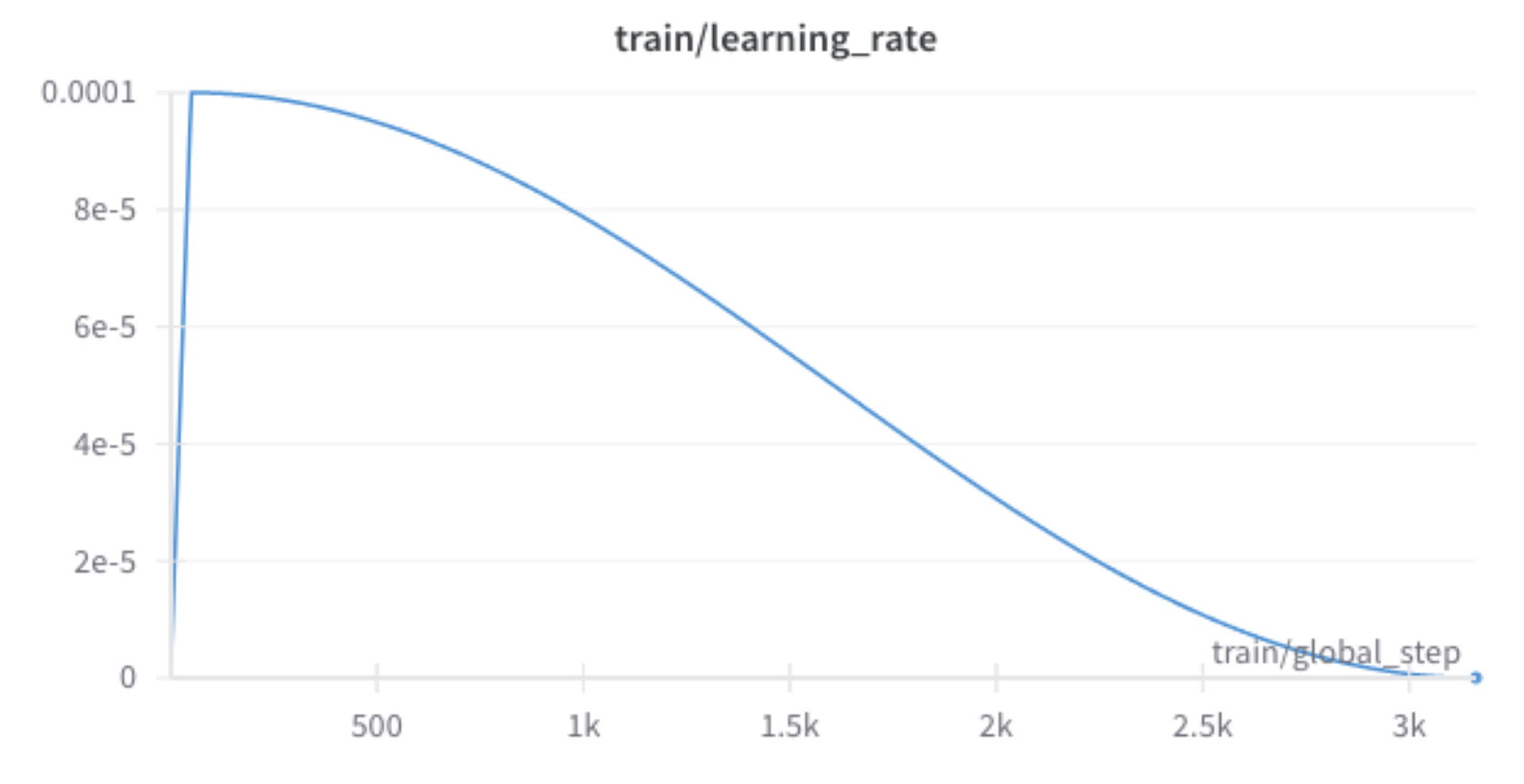
Learning Rate: The
train/learning_rateplot (Figure 3) shows the configured schedule: initial warmup to 1e-4, followed by a cosine decay.Figure 3: Weights and Biases's Learning Rate Plot.
-
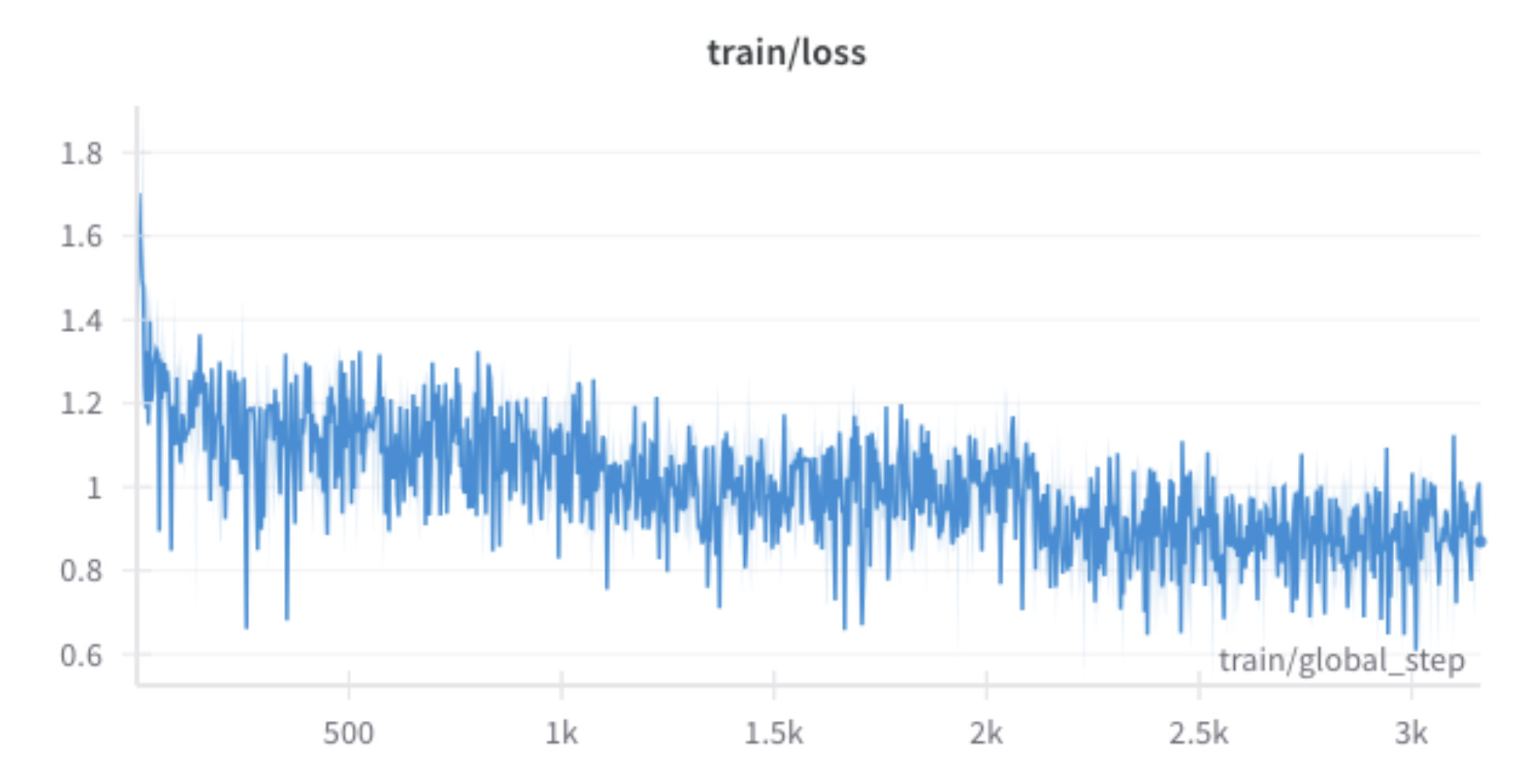
Training Loss: The
train/lossplot (Figure 4) demonstrates effective learning. Loss started around 1.4-1.6, dropped rapidly, and then gradually settled between 0.8 and 1.0 towards the end of training.Figure 4: Weights and Biases's Training Loss Plot.
{kind=link}
These plots confirm that the training proceeded as configured and the model learned from the specialized dataset.
The fine-tuned Llama 3.1 8B model ("Chrysler Crossfire Model") was evaluated against baseline Llama 3.1 Instruct models (8B, 70B, and 405B) using five benchmark questions specific to the Chrysler Crossfire.
Benchmark Questions:
- What is the replacement battery type for my Chrysler Crossfire? (Ground Truth: H6)
- What is the stock wheel size for the front of my Chrysler Crossfire? (Ground Truth: 18 inches)
- What model of headlight should I use as a replacement for my Chrysler Crossfire? (Ground Truth: H7)
- What is the stock wheel size for the rear of my Chrysler Crossfire? (Ground Truth: 19 inches)
- How do I perform a throttle reset for my Chrysler Crossfire? (Ground Truth: Key to position 2, pedal down 5s, key off, pedal up)
A dashboard was developed to prompt these models via OpenRouter's API. Meta’s Llama 4 Maverick was used as a judge to label responses as 'Correct' or 'Incorrect' against the ground truth.
Table 3: Model Performance on Specific Questions
| Model | Battery Type | Front Wheel Size | Headlight Model | Rear Wheel Size | Throttle Reset Proc. |
|---|---|---|---|---|---|
| Llama 3.1 8B | Incorrect | Incorrect | Incorrect | Incorrect | Incorrect |
| Llama 3.1 70B | Incorrect | Incorrect | Incorrect | Incorrect | Incorrect |
| Llama 3.1 405B | Incorrect | Correct | Incorrect | Incorrect | Incorrect |
| Chrysler Crossfire Model | Correct | Correct | Correct | Correct | Correct |
| Table 3: Comparison of model performance. Our fine-tuned model demonstrates superior accuracy on specialized queries. |
Table 4: Overall Model Accuracy
| Model | Correct Answers | Total Questions | Accuracy (%) |
|---|---|---|---|
| Llama 3.1 8B | 0 | 5 | 0.0 |
| Llama 3.1 70B | 0 | 5 | 0.0 |
| Llama 3.1 405B | 1 | 5 | 20.0 |
| Chrysler Crossfire Model | 5 | 5 | 100.00 |
| Table 4: Overall correctness across all benchmark questions. |
(Note: Detailed model responses can be found in Table 5 of the original paper/report.)
The results highlight that general-purpose LLMs, even large ones, lack specific knowledge embedded in niche communities. Our fine-tuning approach successfully encoded this specialized information, creating a domain-specific expert model.
This project successfully demonstrated that fine-tuning an LLM on community-generated data can create a specialized expert model for a niche domain like the Chrysler Crossfire. Our "Chrysler Crossfire Model" significantly outperformed baseline Llama 3.1 models on vehicle-specific queries, achieving 100% accuracy on the benchmark questions.
However, the model may still hallucinate on more technical or obscure questions. Furthermore, the rapid evolution of LLMs means general-purpose models are continuously improving. For instance, initial tests with ChatGPT showed poor performance on Crossfire queries, but subsequent updates to ChatGPT led to dramatically improved accuracy.
This underscores that while domain-focused fine-tuning is a powerful strategy for specialized knowledge delivery, ongoing updates and refinements are crucial in the fast-moving AI landscape.
- Dr. Cohen, for advisory and guidance throughout this capstone project.
- Meta AI, for the Llama 3 models and their open-source contributions.
- The developers of Unsloth, for their efficient fine-tuning framework.
- The developers of AugmentToolKit, for their data generation tools.
- Deepseek AI and OpenRouter, for providing API access.
- The Chrysler Crossfire community at
crossfireforum.orgfor being the source of invaluable data.