Error while training Spacy NER with Hindi dataset #11726
-
|
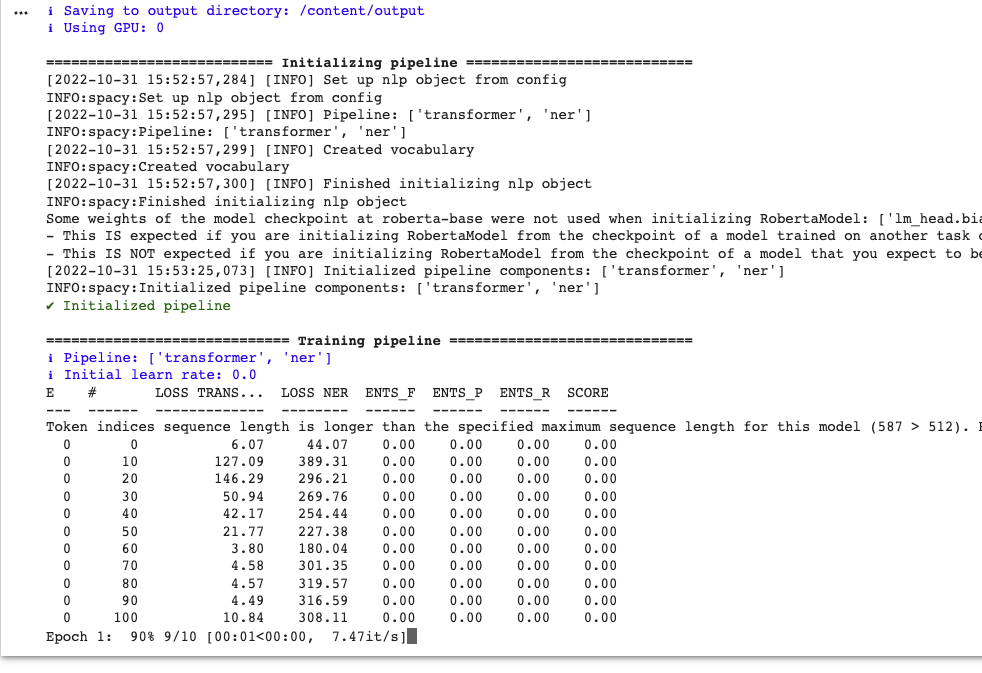
Hi, I'm trying to train the Spacy NER transformers model with Hindi language dataset. The issue is there are no F1, Precison and Recall scores changing at all as mentioned in the below training table (please look at the attached image). Steps to reproduce
Successfully converted .conll files to .spacy files using Training -
Final configuration file. I have modified default values of few parameters in the config file as I was getting CUDA out of memory exception.
Info about spaCy`- spaCy version: 3.4.2
|
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 3 replies
-
|
Sorry you're having trouble with this. To make it easier for us to help you, please do not post screenshots of terminal output, which are hard to read, and please read the Markdown guide on formatting code blocks. Only zero scores usually indicates a data problem. Did you try using Is your text data Romanized? If not then the base Transformer model of roberta-base won't work well, as none of your words will be in the vocabulary. You could try using a Hindi Transformer model (just change the name in the config) or use a non-Tranformer tok2vec (that's probably easiest). Let us know if those don't help. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for your reply. I have used the Output =============================== Training stats =============================== ============================== Vocab & Vectors ============================== ========================== Named Entity Recognition ========================== ================================== Summary ================================== Note: I haven't Romanized, as I'm not aware of what it does? Any links on how to Romanize Hindi text, please? Also, below is the sample of my Hindi dataset
I have tried with Hindi transformer model and non-transformer model (tok2vec), still only zeros coming up after every training step. Thanks. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for providing the output of debug data, that does look OK.
Romanizing means writing your text in the latin alphabet, rather than another alphabet like devanagari. I am not suggesting that you do this. However, the I would recommend you try changing |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @polm, Your suggestion helped me to build something. At first, I tried with Tok2Vec, it worked and got decent F-score 0.76, then tried with Hindi transformer Test results: Thanks again. |

Beta Was this translation helpful? Give feedback.
-
|
Glad you got it working, thanks for letting us know it worked OK! |
Beta Was this translation helpful? Give feedback.
Sorry you're having trouble with this. To make it easier for us to help you, please do not post screenshots of terminal output, which are hard to read, and please read the Markdown guide on formatting code blocks.
Only zero scores usually indicates a data problem. Did you try using
spacy debug datato check if there were problems with your data?Is your text data Romanized? If not then the base Transformer model of roberta-base won't work well, as none of your words will be in the vocabulary. You could try using a Hindi Transformer model (just change the name in the config) or use a non-Tranformer tok2vec (that's probably easiest).
Let us know if those don't help.