SC18
- Overview of machine learning / deep learning
- Success stories of deep learning for scientific applications
- How to train deep learning models with Keras
- How to scale training to multiple nodes on HPCs
- How to utilize HPC for hyper-parameter optimization
- Data management for deep learning at scale
- Data management and I/O at scale is still an open issue
- Extreme-scale applications regularly have I/O issues on HPC
- See Gordon Bell finalist on Deep Learning for Climate
- See CosmoFlow
- Some things which have worked
- Burst-buffer filesystems
- Pre-staging input files to RAM
- Per-node input file chunking (no global shuffling)
- General solutions don’t yet exist
- Presented classical machine learning algorithms
- We shouldn't be afraid of non-convex functions if we have large enough data
- Machine Learning (ML) workflow:
- What is the problem
- Data exploration
- Evaluation metrics
- Deploy
- Large scale
- Monitoring
- Department Of Energy HPC exascale project to try out
- History of Deep Learning and why it got so much attention in recent years? Computing power & big data
- Discussed overfitting and how to optimize a Neural Network (NN)
- Bias - Variance
- NERSC Big data stack
- NERSC ML/DL webpage
- Deep Learning for Science blog
- Summary:
- ML has had tremendous impact in commercial world
- Analogs in scientific domains
- Flavors of ML:
- Supervised Tasks: Regression, Classification
- Unsupervised Task: Clustering
- ML Algorithms:
- k-nn, k-means, Linear Regression, SVM, kernel-SVM, Deep Learning,…
- ML workflow
- ML software is available at DOE HPC facilities, please try it out!
- Real example of where they use Deep Learning models and very large data.
- Building ML models and scaling are 2 different problems
- Classification and Regression are most popular ML problems
- Why DL as sclae for science?
- Scientific data is typically large and complex
- Harder to find optimal hyperparameters
- Need lots of prototyping and model evaluation
- Key metric: time to scientific insight
- Don’t want to wait for days to train a single model
- Fast turnaround of ideas and exploration
- ML/DL for climate science used as an example of an aplication of DL to science
- Application of cutting-edge methods from machine learning, statistics, topology and applied math to:
- Predict extreme weather change in the future
- Improve mechanistic understanding of extreme events
- Classification and object detection of various types of weather patterns
- Segmentation (pixel-wise) of extreme weather patterns
- Tracking of spatio-temporal extreme events, such as hurricanes
- Generative Learning of complex systems using physics-based constraints
- Most bottlenecks occur in I/O whe scale
- For large scale we need HPC
- KNL nodes on NERC Cori
-
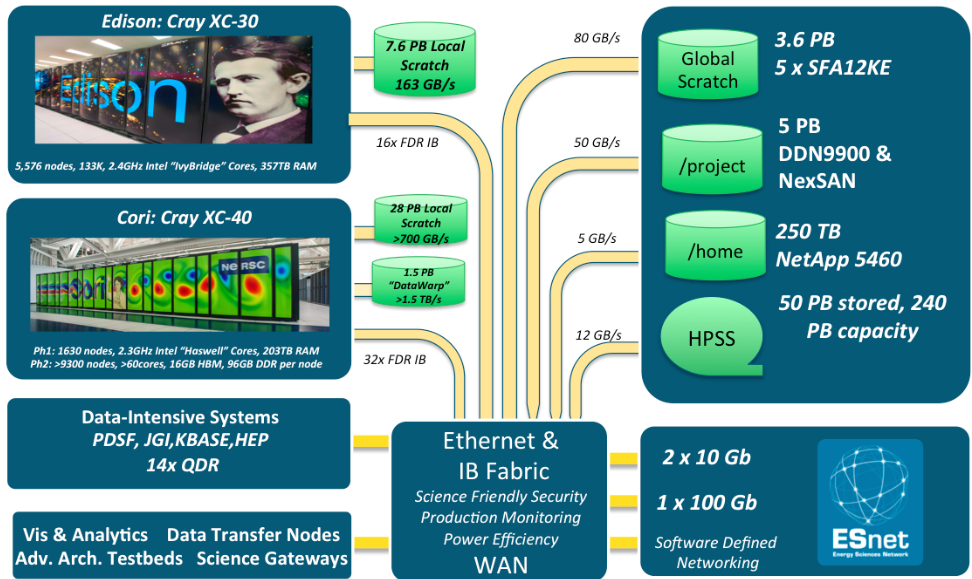
NERSC overview:
- National Energy Research Scientific Computing Center, established in 1974 as the first unclassified supercomputer center
- Now the Mission HPC facility for the DOE Office of Science
- 7000 users, 800 projects, 700 codes, 48 states, 40 countries, universities, and national labs

- 7000 users, 800 projects, 700 codes, 48 states, 40 countries, universities, and national labs
-
The Cori supercomputer:
- 2,388 Intel Xeon ("Haswell") nodes
- 9,688 Intel Xeon Phi ("KNL") nodes
- 1.8 PB "burst buffer" (1,700 GB/s I/O bandwidth)
- 30 PB Lustre (700 GB/s I/O bandwidth)
- Entered Top500 list at #5 in Nov 2016, now #10
-
Perlmutter: next-gen system optimized for science
- Cray Shasta system with 3-4x capability of Cori
- GPU-accelerated (4x NVIDIA) nodes and CPU-only (AMD) nodes
- Cray Slingshot high performance network
- Single-tier All-Flash Lustre based file system
-
Deep Learning at NERSC:
- Optimized DL software stack
- Frameworks: TensorFlow, Keras, PyTorch, Caffe, …Backed by Intel MKL-DNN
- Multi-node libraries: Cray PE DL plugin, Horovod, PyTorch distributed, …
- Big Data Center collaborations
- Intel optimizing TensorFlow and PyTorch for CPU with MKL-DNN
- Cray optimizing DL workflows, distributed training with Distributed Training Framework, data management issues.
- Optimized DL software stack
-
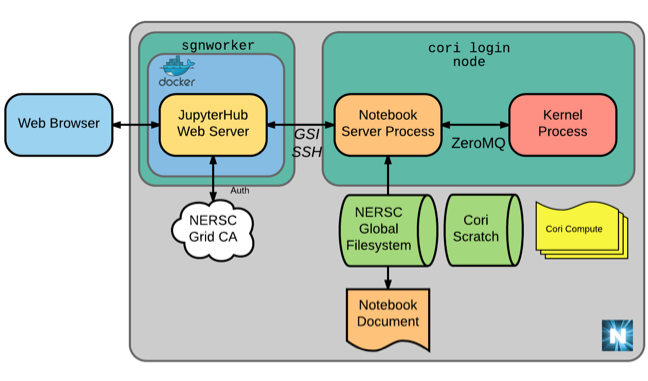
Jupyter at NERSC:
- JupyterHub deployed at NERSC to provide rich, interactive, notebook ecosystem on Cori
- Jupyter servers run on a dedicated login node and can access the system to offload work.
- Expansion of the service in progress.
- Today you can optionally utilize Jupyter as an in-browser GUI for browsing files on Cori and for submitting jobs (via terminal)
- TensorFlow - Best for production
- Most popular framework by several metrics
- Backed by Google and a strong community
- Moving towards more dynamic (“eager”) workflows
- Keras - Best for prototyping
- Usability first; “an API designed for human beings, not machines.”
- Now included in TF; recommended high-level API
- PyTorch - Best for prototyping | Best for production
- Rapidly growing in popularity, particularly in academic circles
- Pythonic experience; easy to use and debug
- Merging with Caffe2 for easier production deployment
- Tutorial
-
Goals of this Session
- Introduce the concept of Hyperparameter Optimization (HPO)
- What are hyperparameters?
- Why are they important?
- Introduce automatic distributed hyperparameter optimization
- Using the Cray HPO library as an example
- Introduce the concept of Hyperparameter Optimization (HPO)
-
What are Hyperparameters?
- Neural network model parameters – weights (connection, bias)
- Neural network hyperparameters – any other settings, e.g.:
- Topology:
- Number of neurons in fully connected layers
- Filters, kernel sizes, strides of convolutional / pooling layers
- Activation function: logistic, ReLU, tanh
- Training:
- Learning rate, batch size, momentum
- Dropout probability, batch normalization
- Optimizers (SGD, Adam, RMSProp, AdaGrad, etc)
- Significant impact on convergence
- Accuracy and time-to-accuracy
- Good choices especially important at scale
-
Search the space of possible hyperparameter sets:
- Brute-force of entire search space intractable
- More sets than atoms in the observable universe
- Only evaluate a subspace (prune):
- Grid or Random Search
- Bayesian Optimization based
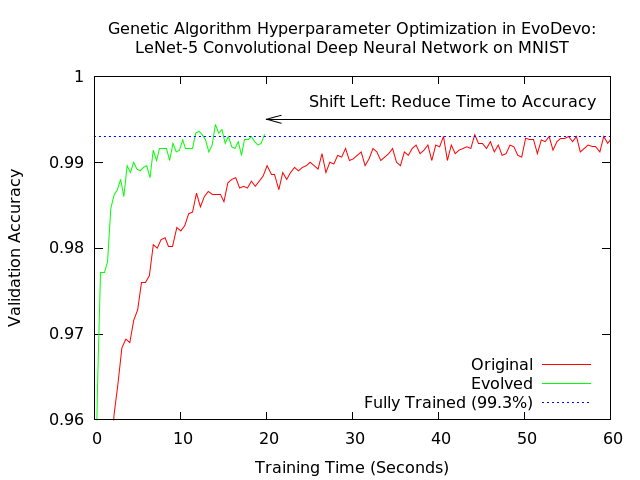
- Genetic / Evolutionary Algorithms (“population-based training”)
-
Population Based Training
- Optimize hyperparameters and parameters
- Hyperparameters optimized as usual with GA / EA
- Parameters optimized with checkpoint / restore:
- At the end of each epoch, population copies best parameters
- Creates a “training schedule” with customized epochs
-
Cray Hyperparameter Optimization
- Cray integrated Hyperparameter Optimization (HPO) support with Python interface and Chapel backend
- Supported distributed optimization as well as distributed training
- E.g., 20 nodes, 5 HPO instances each training on 4 nodes
- Simple steps to use:
- Create a python wrapper script
- Define optimizer and configuration
- Provide parameters, search range and executable command
- Run wrapper script to optimize
from crayai import hpo
eval = hpo.evaluator(‘python …’)
params = ([[“--learning_rate”, 0.01, (1e-6, 0.1)],
[“--dropout_rate”, 0.5, (0.3, 0.7)],
...]
Optimizer = hpo.{genetic,grid,random}.Optimizer(
params, eval, launcher=“urika”,
generations=5)
- The Cray HPO package comes with Urika integration
- Leverages deep learning and analytics resources of the Urika image
- Allows seamless distribution with workload managers
- Supports three techniques for HPO
- Genetic optimization
- Grid sweep
- Random search
- Supports Population Based Training
- Learn a custom training parameter schedule while training
- Trains a better model in less time
- Examples: Grid
# Grid search example
from crayai import hpo
# HPs with bounds discretized at linear intervals
params = hpo.params([["-a", 1.0, (-1.0e3, 1.0e3)],
["-b", -1.0, (-1.0e3, 1.0e3)]])
# Evaluator specifies how to evaluate a set of HPs
evaluator = hpo.evaluator('python ./model.py')
# Create a random search optimizer
optimizer = hpo.grid_search.optimizer(evaluator,num_iters = 1000)
optimizer.optimize(params)
- Examples: Random
# Random search example
from crayai import hpo
# HPs with bounds discretized at linear intervals
params = hpo.params([["-a", 1.0, (-1.0e3, 1.0e3)],
["-b", -1.0, (-1.0e3, 1.0e3)]])
# Evaluator specifies how to evaluate a set of HPs
evaluator = hpo.evaluator('python ./model.py')
# Create a random search optimizer
optimizer = hpo.random_search.optimizer(evaluator,num_iters = 1000)
optimizer.optimize(params)
- Examples: Genetic
from crayai import hpo
# HPs with bounds discretized at linear intervals
params = hpo.params([["-a", 1.0, (-1.0e3, 1.0e3)],
["-b", -1.0, (-1.0e3, 1.0e3)]])
# Evaluator specifies how to evaluate a set of HPs
evaluator = hpo.evaluator('python ./model.py')
# Create a random search optimizer
optimizer = hpo.genetic.optimizer(evaluator,
generations = 10,
num_demes = 4,
pop_size = 64,
mutation_rate = 0.005,
crossover_rate = 0.33)
optimizer.optimize(params)
- Each epoch will select the best
-
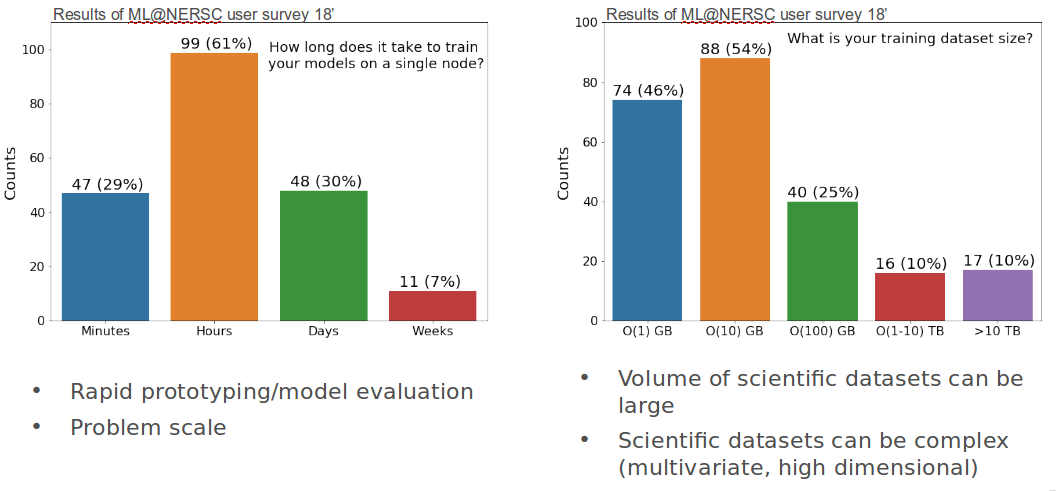
Motivation:
-
Data-parallel Training
- applies to Stochastic Gradient Descent-type algorithms
- each node takes a data batch and computes model updates independently
- these updates are then collectively summed and applied to the local model
- applies to Stochastic Gradient Descent-type algorithms
-
Synchronous Update
- all nodes compute gradients locally
- gradients are summed across nodes
- updates propagated to all nodes
- pros:
- stable convergence
- cons:
- scaling is not optimal because all nodes have to wait for reduction to complete (stragglers slow everyone down)
- global (effective) batch size grows with number of nodes
-
Asynchronous Update
- all nodes compute gradient update locally
- gradient is sent to parameters server
- parameters servers incorporates gradients into model as they arrive and sends back the updated model to the corresponding node
- pros
- no node waits for anybody (perfect scaling)
- resilient
- cons
- use of stale gradients can have impact on convergence rate (depending on #workers)
- parameter server can be bottleneck
-
Hybrid update
-
synchronous groups exchange information through parameters server asynchronously
-
gradient is sent to parameters server
-
parameters servers incorporates gradients into model as they arrive and sends back the updated model to the corresponding node
-
pros
- impact of stragglers reduced compared to fully synchronous mode
- negative impact on stochastic convergence controlled
- finer control on total batch size
-
cons
- group size needs to be tuned
-
other methods: stale-synchronous/pipelining
-
-
Large batch training and scaling learning rate
- In data parallelism with fully synchronous SGD one uses N workers to processes N batches of data
- Need to scale the learning rate accordingly to accelerate the convergence
-
Challenges with Large Batch Training: not stable and generalization gap
-
Avoiding initial training instabilities using larning rate warm-up (variable learning rate)
-
Large batch training takeaway
-
Training with large batch-size requires learning rate scaling. Anywhere between sub-sqrt to linear scaling have been used in practice.
-
Training with large learning rates introduces instabilities in the initial stages of training. Gradual warm-up to target learning rate works well.
-
Training with a large batch-size has a generalization gap w.r.t small batch-size
-
Linear warm-up + scaling LR works well for ~10x scaling of batch-size
-
Increasing the batch-size is an alternative approach to decaying the learning rate
-
Adaptive learning rate scaling methods like LARC is another alternative
-
These methods are constantly pushing the limits of the largest batch-size we can use for training but they still don’t eliminate the upper bound
-
There are works that try to understand the reasons behind the generalization gap which we didn’t review here
-
- Horovod for distributed training
- good to consider Cray PE ML Plugin for scalable training on HPC systems
- Horovod link
- Enables distributed synchronous data-parallel training with minimal changes to user code
- Uses ring all-reduce and MPI to collectively combine gradients across workers
- Such approaches shown to scale better than parameter-server approaches (e.g. distributed TensorFlow with gRPC)
- Initialize Horovod and MPI:

hvd.init()
- Wrap your optimizer in the Horovod distributed optimizer:
opt = keras.optimizers.SGD(lr=lr*hvd.size(), ...)
opt = hvd.DistributedOptimizer(opt)
- Construct the variables broadcast callback:
callbacks = [hvd.callbacks.BroadcastGlobalVariablesCallback(0)]
- Train model as usual; it should now synchronize at every mini-batch step:
model.fit(..., callbacks=callbacks)
- Launch your script with MPI
mpirun -n NUM_RANKS … python train.py …
- Notes:
- batch size increase, learning rate should decrease and opposite
- start small and scale up
- end of epoch we will always see small jumps
- SGD + momentum is most used
- LARC Optimizer link
- Standardize data, batch normalization
- GPUs are more efficient than multiple nodes model? (not sure)
- It might take longer to train because validation data is not distributed in chunks like training data
- General ML/DL training
- Andrew Ng’s famous ML course on Coursera: https://www.coursera.org/learn/machine-learning
- Deep learning specialization on Coursera: https://www.coursera.org/specializations/deep-learning
- Distributed training
- Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis: https://arxiv.org/abs/1802.09941
- Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates: https://arxiv.org/abs/1708.07120
- Training Imagenet in 3 hours for $25; and CIFAR10 for $0.26: https://www.fast.ai/2018/04/30/dawnbench-fastai/
- MLPerf Deep Learning Benchmarking (https://mlperf.org)
- Cray Urika-XC and Urika-CS AI and Analytics software suites
- DL Frameworks: TensorFlow, Keras, PyTorch with Cray ML Plugin and Horovod for distributed training
- Hyperparameter optimization library
- Also Spark, Dask Distributed, Anaconda Python, Jupyeter and pbdR
- Population Based Training of Neural Networks (DeepMind):
- Telescope data challenges
- where they were getting 15 TB data / night
- transfer to all 3 centers each night needed
- data available to anyone
- 60 Pb volumes
- Texas Advanced Computer Center (TAC)
- They use Singularity and Docker - Less optimized but easy to use
- High resolution 3D images
- Interest in more container based technology - life-cycle issues
- GPU interest in speed up processing
Matthew Grover - Walmart Inc
Alex Sutton - Microsoft Corporation
- Great challenges in creating Data Pipelines
- Continue model maintenance after model production to test model drift and re-training
- Look for Benchmarking - How fast the model runs on different platforms and resources
- Some key tools they mentioned:
- Recommended paper: TFX: A TensorFlow-Based Production-Scale Machine Learning Platform link