Streamlining recruitment through intelligent resume analysis
- Overview
- Key Features
- Technology Stack
- Architecture
- Installation
- Usage
- Screenshots
- Future Roadmap
- Contributing
- License
- Acknowledgments
Smart Resume Analyzer is an intelligent web application that leverages Natural Language Processing (NLP) to automate the resume screening process. By analyzing resumes against job descriptions, the system provides objective, data-driven insights to help recruiters identify the most suitable candidates efficiently.
- Extracts and categorizes information from PDF resumes
- Identifies education, experience, and skills automatically
- Processes multiple resumes simultaneously
- Matches resumes against job requirements using weighted criteria
- Distinguishes between required and preferred skills
- Employs semantic similarity for context-aware matching
- Skill category radar charts
- Color-coded skill gap analysis
- Progress indicators for match scores
- Adjustable weights for different matching criteria
- Interactive sliders for personalized assessment
- Downloadable PDF reports
- Detailed candidate information and match scores
- Visual representations of strengths and skill gaps
| Frontend |
• HTML5, CSS3, JavaScript • Responsive design with custom styling • Interactive elements for file uploads and parameter adjustment |
| Backend |
• Python 3.8+ • Flask web framework • RESTful API endpoints |
| NLP & Data Processing |
• NLTK for tokenization and lemmatization • spaCy for entity recognition and semantic analysis • PyPDF2 for document parsing |
| Data Visualization |
• Matplotlib for chart generation • Base64 encoding for web display |
| Reporting | • FPDF for PDF generation |
Smart Resume Analyzer implements a modular architecture:
+---------------------+
| User Interface |
| (Web Frontend) |
+----------+----------+
|
v
+----------+----------+
| Web Application |
| (Flask Server) |
+----------+----------+
|
+-------+-------+
| | |
v v v
+-----+ +-----+ +-----+
|File | |NLP | |Match|
|Proc.| |Proc.| |Eng. |
+-----+ +-----+ +-----+
| | |
+-------+-------+
|
v
+----------+----------+
| Visualization & |
| Reporting Engine |
+----------+----------+
- Python 3.8 or higher
- pip package manager
- Virtual environment (recommended)
-
Clone the repository:
git clone https://github.com/hassanrrraza/resume_analyzer cd resume_analyzer -
Create and activate a virtual environment:
python -m venv .venv # On Windows .venv\Scripts\activate # On macOS/Linux source .venv/bin/activate
-
Install dependencies:
pip install -r requirements.txt
-
Download required NLP models:
python -m spacy download en_core_web_md python -m nltk.downloader punkt stopwords wordnet averaged_perceptron_tagger
-
Run the application:
python main.py
-
Access the application at
http://localhost:5000
-
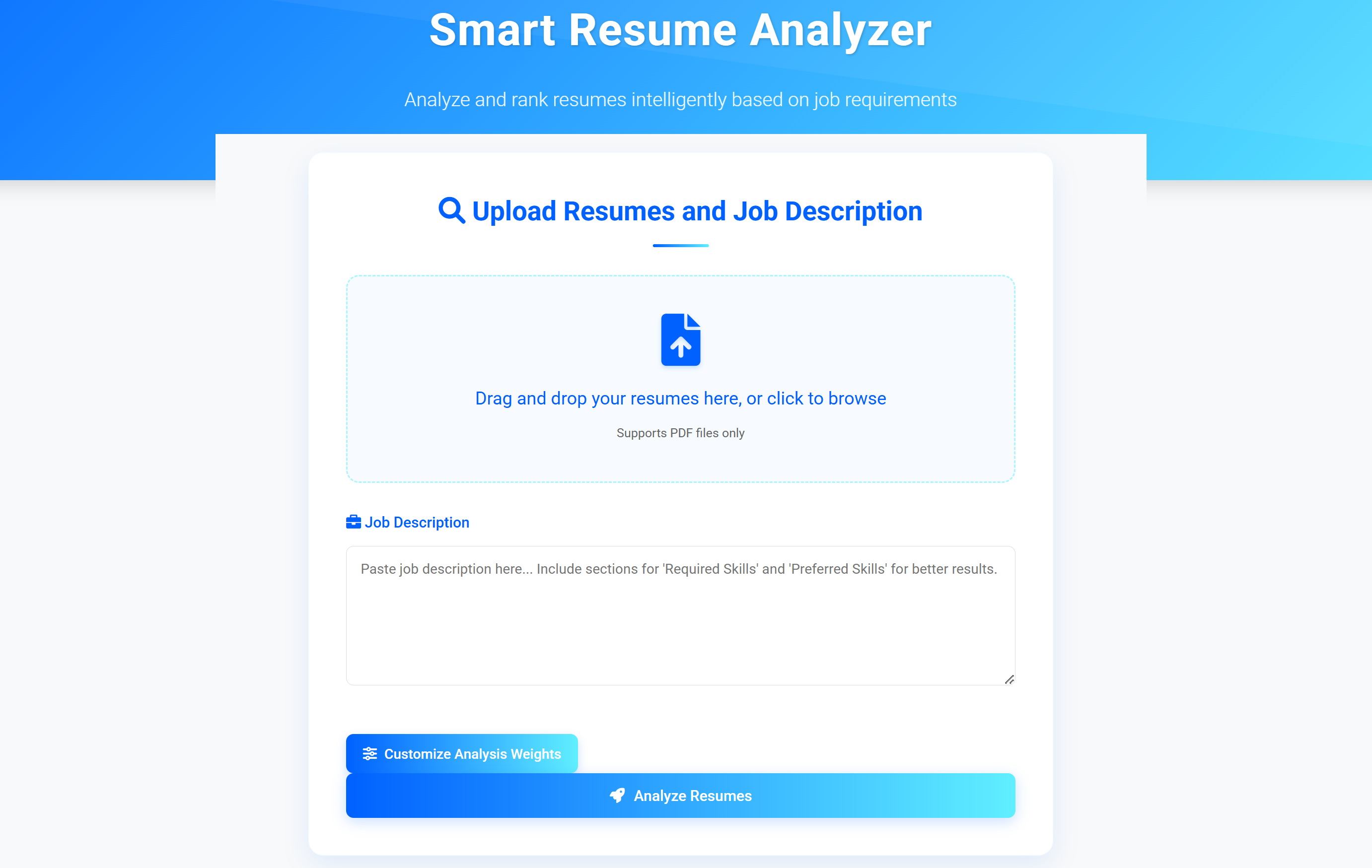
Upload Resumes
- Drag and drop PDF files
- Or click to browse and select files
- Multiple files can be uploaded simultaneously
-
Enter Job Description
- Paste job posting text
- Include required and preferred skills sections for best results
-
Customize Weights (Optional)
- Adjust importance of required skills (default: 60%)
- Adjust importance of preferred skills (default: 20%)
- Adjust importance of semantic similarity (default: 20%)
-
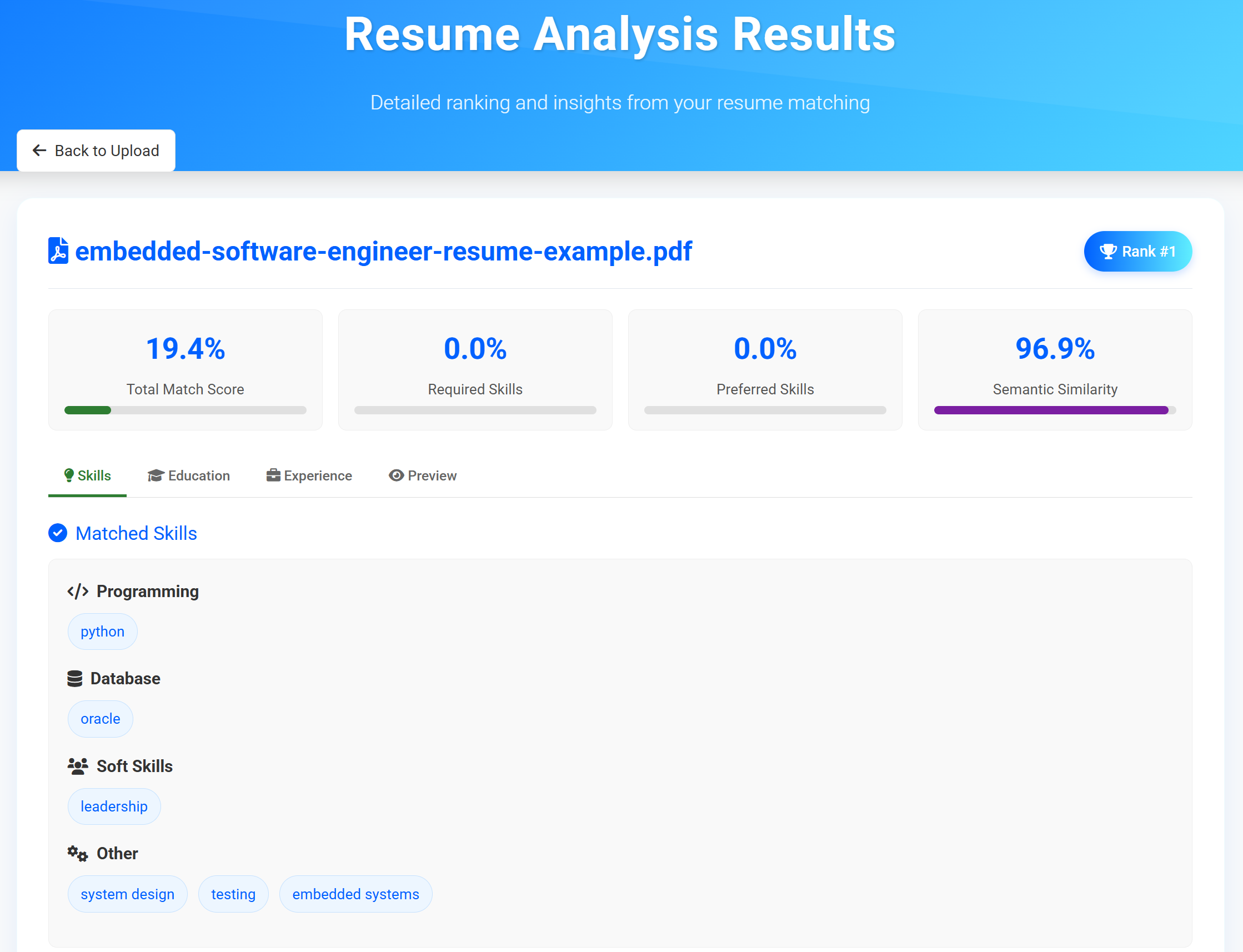
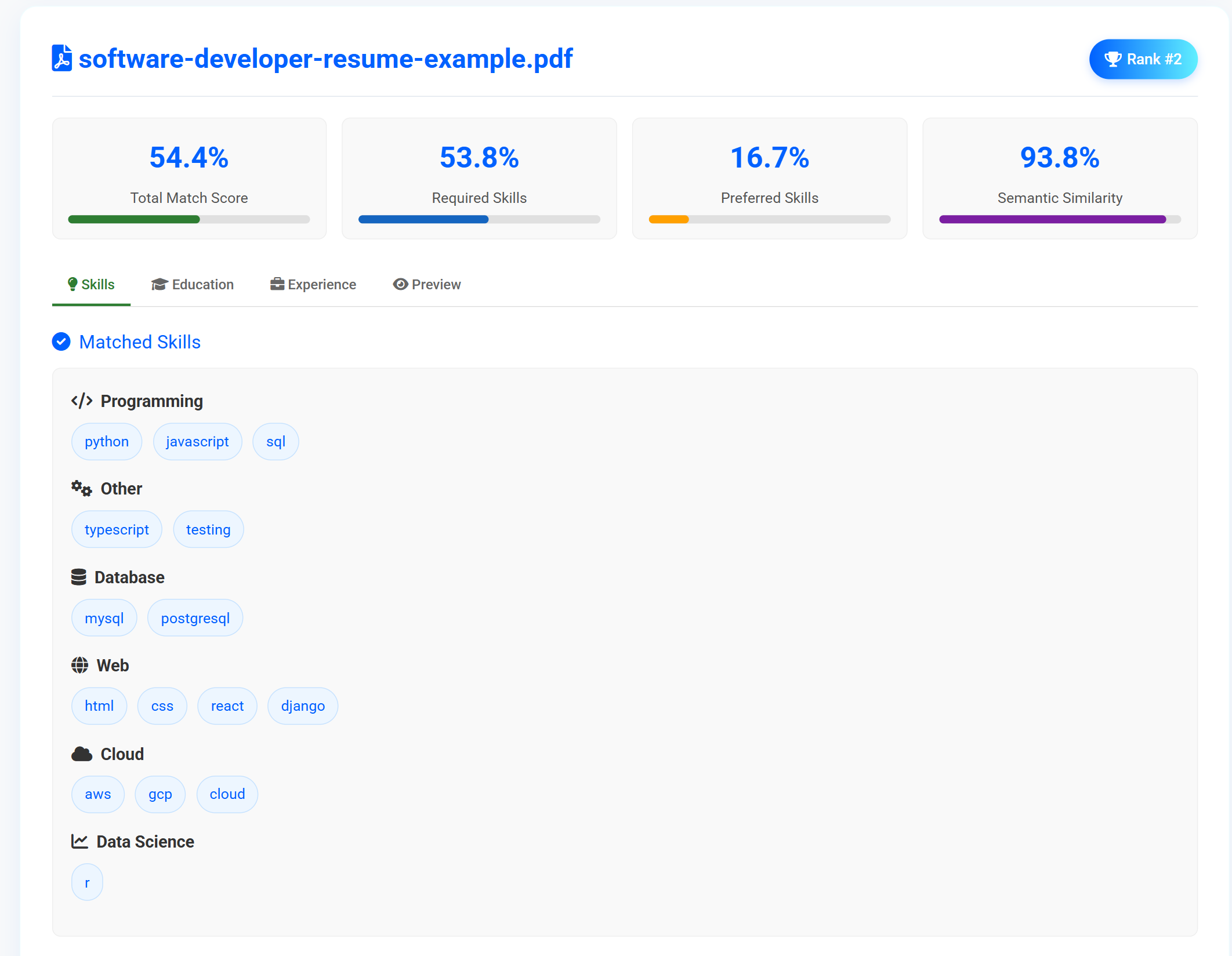
View Results
- Overall match scores
- Skills breakdown by category
- Education and experience details
- Skill gap analysis
-
Download Reports
- Generate comprehensive PDF summary
- Share with team members or stakeholders
Resume Upload Interface

Results Dashboard
Skill Analysis Visualization
- Support for DOCX and other resume formats
- Enhanced semantic analysis with BERT/GPT-based embeddings
- Expanded skills database with industry-specific terms
- Integration with Applicant Tracking Systems (ATS)
- Machine learning components for improved matching accuracy
- Mobile application development
- Multi-language support
Contributions are welcome! Please follow these steps:
- Fork the repository
- Create a feature branch:
git checkout -b feature/amazing-feature - Commit your changes:
git commit -m 'Add some amazing feature' - Push to the branch:
git push origin feature/amazing-feature - Open a Pull Request
Please ensure your code follows the project's style guidelines and includes appropriate tests.
This project is licensed under the MIT License - see the LICENSE file for details.
- NLTK team for natural language processing tools
- spaCy for advanced NLP capabilities
- Flask team for the web framework
- All contributors who have helped shape this project