Welcome to the AlwaysSaved Extractor Service — the user-facing web app that powers your private, searchable knowledge base for long-form media. Built to deliver fast, intelligent, and intuitive experiences, this interface lets users upload, explore, and query their personal content with ease.
This is the repository for the Extractor Service - Step 3 of the App Flow and the real start of the AlwaysSaved ML/AI Pipeline.
For more information about What is AlwaysSaved and its Key Features, refer to the AlwaysSaved Frontend README.
- 3rd Party Services Needed
- Environment and AWS Systems Manager Parameter Store Variables
- Starting the App
- File Structure and Service Flow
- AlwaysSaved System Design / App Flow
As a friendly reminder from the AlwaysSaved Frontend, the following AWS Resources should have already been setup for this Extractor Service to work properly:
- An s3 Bucket with the right permissions for storing media files.
- Parameters stored in the AWS Systems Manager Parameter Store.
An Amazon Simple Queue Service Extractor Queue was already created when you spun up the Frontend. You will now need to:
- Create a second SQS queue we call the
Embedding Queuethat theExtractor Serviceuses to send payloads to theEmbedding Serviceto continue the next part of the ML/AI Pipeline (see Steps 4-5 of System Design Diagram).
Your newly created Embedding Queue URL will be saved in the AWS Parmeter Store (see next section).
You'll need to create a .env file at the root of this repo. There's only one variable that you have to prefill, which is the Region where all your AWS s3 Bucket and SQS Queues are located.
AWS_REGION=
For both development and production, there are a lot of variables that we couldn't store in the .env file, so we had to resort to using the AWS Systems Manager Parameter Store ahead of time in order to get the app functioning.
The following variable keys have their values stored in the Parameter store as follows:
/alwayssaved/AWS_BUCKET
/alwayssaved/AWS_BUCKET_BASE_URL
/alwayssaved/EXTRACTOR_PUSH_QUEUE_URL
/alwayssaved/EMBEDDING_PUSH_QUEUE_URL
/alwayssaved/MONGO_DB_USER
/alwayssaved/MONGO_DB_PASSWORD
/alwayssaved/MONGO_DB_BASE_URI
/alwayssaved/MONGO_DB_NAME
/alwayssaved/MONGO_DB_CLUSTER_NAME
If you already setup your MongoDB Cluster and s3 Bucket by setting up the AlwaysSaved Frontend, adding those values in the AWS Parameter Store should be easy.
Make sure that the Extractor Service SQS URL gets saved in the paramter store under /alwayssaved/EXTRACTOR_PUSH_QUEUE_URL and the newly created Embedding Queue URL gets saved under /alwayssaved/EMBEDDING_PUSH_QUEUE_URL.
For clarification, your AWS_BUCKET_BASE_URL really means the URL that points to your Bucket in AWS like so:
https://<AWS_BUCKET_NAME>.s3.amazonaws.com
We need to use a virtual environment (we use the Pipenv virtualenv management tool) to run the app.
Navigate to the root of the project folder in your computer. Open 2 separate terminal windows that both point to the root of the project. In one of those terminal windows run the following commands:
Create and enter the virtual environment:
$ pipenv --python 3.11
Enter the virtual environment:
$ pipenv shell
Install the dependencies in the Pipfile:
$ pipenv install
Start the Extractor Service at the root service.py file:
$ python3 service.py
/
|
|___/services
| |
| |__/audio_extractor
| |
| |__/audio_transcription
| |
| |__/aws
| | |
| | |__s3.py
| | |
| | |__sqs.py
| | |
| | |__ssm.py
| |
| |
| |
| |__/utils
| |
| |__/mongodb
| |
| |__/types
|
|
|
|__service.py
So basically the AlwaysSaved ML/AI Pipeline starts here in the Extractor Service in concert with the Extractor Queue (see Steps 2-3 of System Design Diagram).
But first, a little explanation on the Data Entities of AlwaysSaved and how incoming requests to the Extractor Service arrive from the Frontend.
On the Frontend for v1, Users can upload a single or multiple .mp4 Video or .mp3 Audio File(s) to s3. When a single or multiple Files are uploaded to s3, the Frontend creates File MongoDB documents for each File upload.
Those newly created media File upload(s) are organized in a newly created MongoDB "Note" document.
When the File upload(s) to s3 finish, the Frontend sends an SQS Message Payload to the Extractor Queue that gets processed by the Extractor Service. The incoming SQS Message to the Extractor Service has the following shape:
[
{
user_id: string;
media_uploads: [
{
note_id: ObjectID;
user_id: ObjectID;
s3_key: string;
}
]
}
]
Then for each SQS Message, for each media_upload in the Message Payload, the Extractor Service will:
- Download the media
Filefrom s3;- If the media download is an
.mp4file, extract the.mp3audio file from the video;
- If the media download is an
- Use the Whisper Model to transcribe the audio and create a
.txtfile of the transcript; - Upload the
.txttranscript to s3; and - Send an outgoing SQS Message to the
Embedding QueueStep 4 of System Design Diagram with the following shape:
{
note_id: string;
file_id: string;
user_id: string;
transcript_s3_key: string;
}
The next part of the ML/AI Pipeline then moves on to the Embedding Queue and Embedding Service (see Steps 4-5 of System Design Diagram).
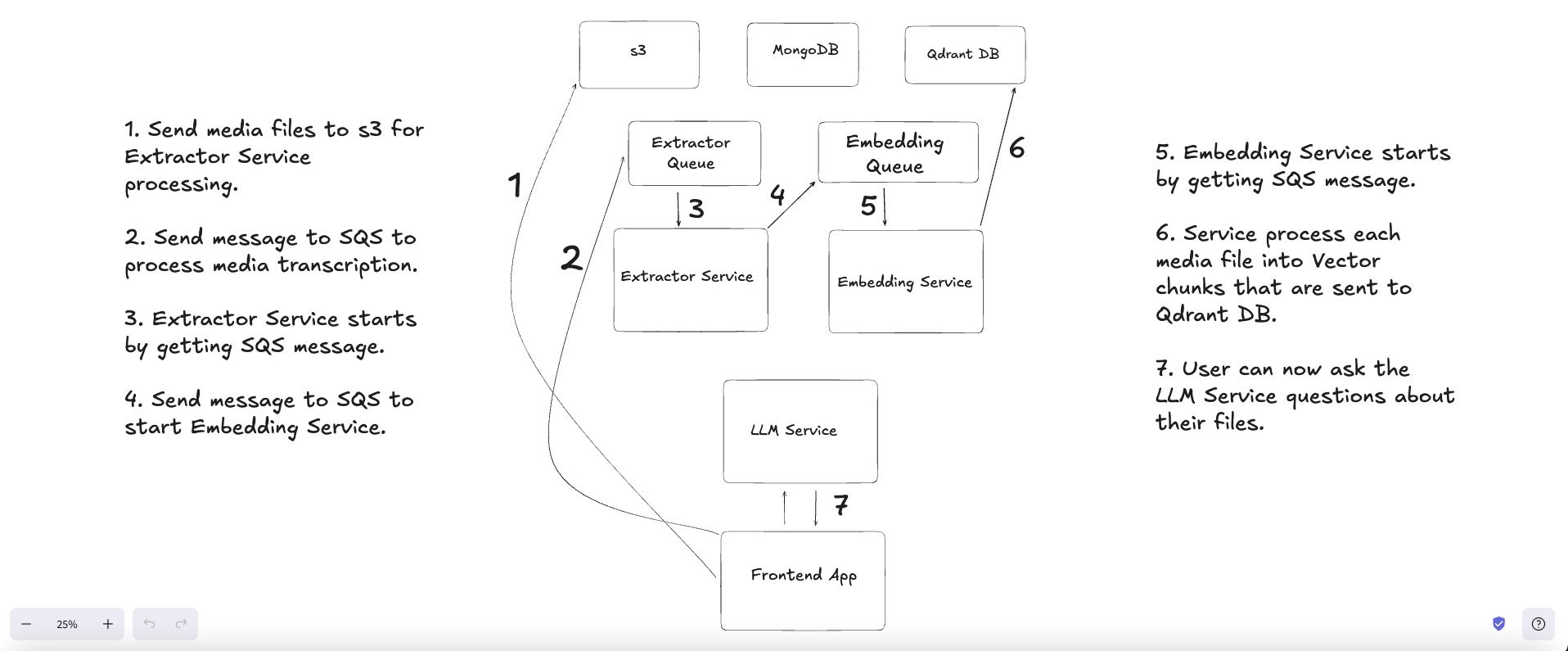
Above 👆🏽you will see the entire System Design and App Flow for Always Saved.
If you need a better view of the entire screenshot, feel free to download the Excalidraw File and view the System Design document in Excalidraw.
Jaime Mendoza https://github.com/jaimemendozadev