{kind=link}
{kind=link}
Semantic grep powered by Jina embeddings, running locally on Apple Silicon via MLX.
Four modes: pipe grep output for semantic reranking, search files directly with natural language, zero-shot classification, or code search.
| Model | Params | Dims | Max Seq | Matryoshka | Tasks |
|---|---|---|---|---|---|
| jina-embeddings-v5-small | 677M | 1024 | 32768 | 32-1024 | retrieval, text-matching, clustering, classification |
| jina-embeddings-v5-nano | 239M | 768 | 8192 | 32-768 | retrieval, text-matching, clustering, classification |
| jina-code-embeddings-1.5b | 1.54B | 1536 | 32768 | 128-1536 | nl2code, code2code, code2nl, code2completion, qa |
| jina-code-embeddings-0.5b | 0.49B | 896 | 32768 | 64-896 | nl2code, code2code, code2nl, code2completion, qa |
Unified MLX checkpoints with dynamic LoRA adapter switching (v5) or single checkpoint with instruction prefixes (code). One base model in memory for all tasks, adapter switching in 20ms. No PyTorch, no transformers - pure MLX on Metal GPU.
git clone https://github.com/jina-ai/jina-grep-cli.git && cd jina-grep-cli
uv venv .venv && source .venv/bin/activate
uv pip install -e .Requirements: Python 3.10+, Apple Silicon Mac.
Two modes:
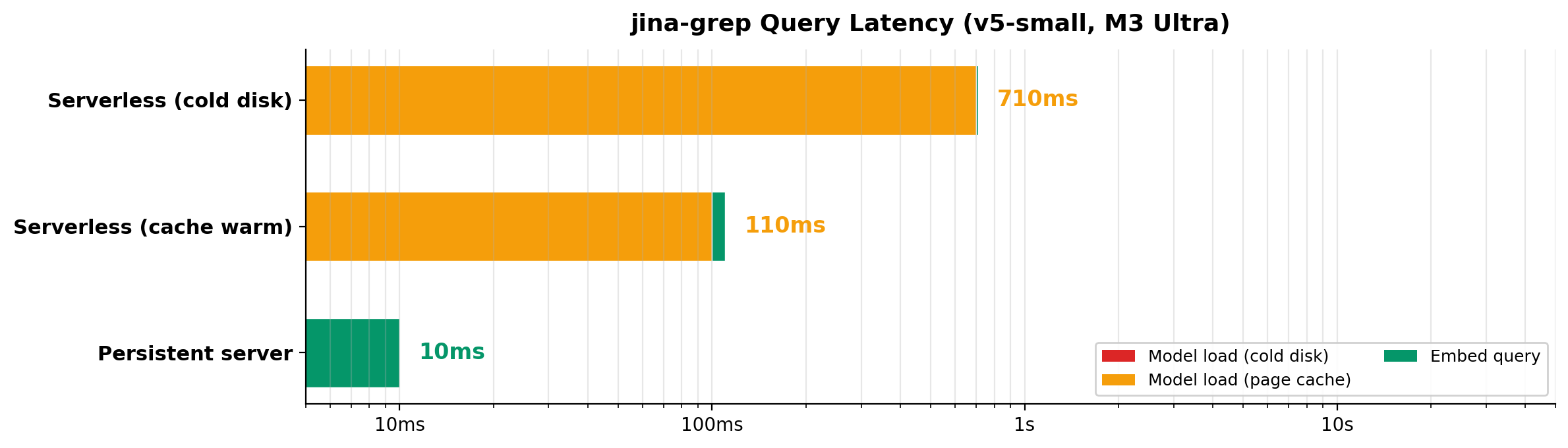
Serverless (default): Model loads in-process, runs the query, exits. No server, no background processes. Uses a unified MLX checkpoint with dynamic LoRA adapter switching (one base model for all tasks). MLX loads weights via mmap, so macOS keeps them in page cache after exit. Best for: occasional use, scripts, CI.
Persistent server: Keep a server running across invocations. Model stays in GPU memory, every query is ~10ms. Best for: interactive sessions, batch workloads.
jina-grep serve start # keep running in background
# ... run as many queries as you want, each takes ~10ms ...
jina-grep serve stop # stop when doneServerless mode auto-detects a running persistent server and uses it via HTTP (without stopping it afterwards).
grep -rn "error" src/ | jina-grep "error handling logic"
grep -rn "def.*test" . | jina-grep "unit tests for authentication"
grep -rn "TODO" . | jina-grep "performance optimization"jina-grep "memory leak" src/
jina-grep -r --threshold 0.3 "database connection pooling" .
jina-grep --top-k 5 "retry with exponential backoff" *.pyUse --model to switch to code embeddings and --task for code-specific tasks:
# Natural language to code: find code that matches a description
jina-grep --model jina-code-embeddings-1.5b --task nl2code "sort a list in descending order" src/
# Code to code: find similar code snippets
jina-grep --model jina-code-embeddings-0.5b --task code2code "for i in range(len(arr))" src/
# Code to natural language: find comments/docs matching code
jina-grep --model jina-code-embeddings-1.5b --task code2nl "def binary_search(arr, target):" src/
# Pipe mode works too
grep -rn "def " src/ | jina-grep --model jina-code-embeddings-1.5b --task nl2code "HTTP retry with backoff"Code tasks:
nl2code- natural language query to code (default for code models)code2code- find similar code snippetscode2nl- find comments/docs for codecode2completion- find completions for partial codeqa- question answering over code
Use -e to specify labels. Each line gets classified to the best matching label.
# Classify code by category
jina-grep -e "database" -e "error handling" -e "data processing" -e "configuration" src/
# Read labels from file
echo -e "bug\nfeature\nrefactor\ndocs" > labels.txt
jina-grep -f labels.txt src/
# Output only the label (pipe-friendly)
jina-grep -o -e "positive" -e "negative" -e "neutral" reviews.txt
# Count per label
jina-grep -c -e "bug" -e "feature" -e "docs" src/Output shows all label scores, best label highlighted:
src/main.py:10:def handle_error(error_code, message): [error handling:0.744 data processing:0.756 ...]
src/config.py:1:# Configuration settings [configuration:0.210 database:0.217 ...]
jina-grep serve start [--port 8089] [--host 127.0.0.1] [--foreground]
jina-grep serve stop
jina-grep serve statusGrep-compatible flags:
-r, -R Recursive search (standalone mode)
-l Print only filenames with matches
-L Print only filenames without matches
-c Print match count per file
-n Print line numbers (default: on)
-H / --no-filename Show / hide filename
-A/-B/-C NUM Context lines after/before/both
--include=GLOB Search only matching files
--exclude=GLOB Skip matching files
--exclude-dir Skip matching directories
--color=WHEN never/always/auto
-v Invert match (lowest similarity)
-m NUM Max matches per file
-q Quiet mode
Semantic flags:
--threshold Cosine similarity threshold (default: 0.5)
--top-k Max results (default: 10)
--model Model name (default: jina-embeddings-v5-nano)
--task v5: retrieval/text-matching/clustering/classification
code: nl2code/code2code/code2nl/code2completion/qa
--server Server URL (default: http://localhost:8089)
--granularity line/paragraph/sentence/token (default: token)
All models use mx.fast.scaled_dot_product_attention and mx.fast.rope for optimized inference.
Config Batch ~Tokens Avg ms P50 ms Tok/s
---------------------------------------------------------------------------
1x short 1 5 7.5 7.3 671
1x medium 1 56 9.8 9.7 5734
1x long (~520 tok) 1 161 15.4 15.4 10448
1x very long (~2.6K tok) 1 801 52.3 49.7 15320
8x short 8 40 10.3 10.2 3889
32x short 32 160 22.4 21.7 7138
128x short 128 640 56.9 53.5 11250
256x short 256 1280 106.3 106.6 12041
8x long 8 1288 66.8 66.7 19273
32x long 32 5152 238.5 239.2 21598
Single query: 7.5ms. Peak throughput: 21.6K tok/s.
Config Batch ~Tokens Avg ms P50 ms Tok/s
---------------------------------------------------------------------------
1x short 1 6 3.0 3.2 1971
1x medium 1 57 3.4 3.4 16787
1x long (~520 tok) 1 162 4.8 4.8 33634
1x very long (~2.6K tok) 1 802 13.2 13.1 60931
8x short 8 48 4.2 4.1 11563
32x short 32 192 7.4 7.3 25796
128x short 128 768 17.8 17.8 43027
256x short 256 1536 34.6 34.6 44450
8x long 8 1296 18.3 18.3 70734
32x long 32 5184 67.3 67.2 76984
Single query: 3ms. Peak throughput: 77K tok/s.
Config Batch ~Tokens Avg ms P50 ms Tok/s
---------------------------------------------------------------------------
1x short 1 5 14.6 11.2 343
1x medium 1 56 20.0 20.0 2797
1x long (~520 tok) 1 161 34.0 34.0 4739
1x very long (~2.6K tok) 1 801 117.1 113.5 6842
8x short 8 40 28.2 28.3 1418
32x short 32 160 72.6 71.4 2205
128x short 128 640 248.6 246.9 2574
256x short 256 1280 486.9 486.7 2629
8x long 8 1288 174.7 174.6 7374
32x long 32 5152 672.3 672.7 7664
Single query: 14.6ms. Peak throughput: 7.7K tok/s.
Config Batch ~Tokens Avg ms P50 ms Tok/s
---------------------------------------------------------------------------
1x short 1 5 6.0 5.8 828
1x medium 1 56 8.5 8.6 6558
1x long (~520 tok) 1 161 12.3 12.3 13126
1x very long (~2.6K tok) 1 801 40.1 38.1 19984
8x short 8 40 9.5 9.5 4192
32x short 32 160 25.3 25.2 6331
128x short 128 640 78.5 78.7 8152
256x short 256 1280 150.8 150.8 8487
8x long 8 1288 55.4 55.4 23248
32x long 32 5152 202.1 202.3 25491
Single query: 6ms. Peak throughput: 25.5K tok/s.
Apache-2.0