本文档可以给分布式系统及想利用zk进行服务协同管理的开发者提供指引。包含了一些概念性的描述和实用信息。
本指南最开始的四个部分从比较高的层面对zk的概念进行了论述,这对理解zk原理及熟练实用是非常必要的。本指南不包含源码,读者需要对分布式计算有一定的了解。本节内容包括:
第二节提供了一些编程方面的实用信息,包括:
- Building Blocks: A Guide to ZooKeeper Operations
- Bindings
- Program Structure, with Simple Example [tbd]
- Gotchas: Common Problems and Troubleshooting
本文附录包含了一些其他与zk相关的实用信息。
本文大部分内容可以独立阅读。但是,在编写你的第一个zk应用之前,你至少需要阅读 ZooKeeper Data Model 和 ZooKeeper Basic Operations这两个章节。并且我们提供了一个demo来帮助你更快的理解zk应用的基本架构。
zk有一个类似于分布式文件系统层级机构的命名空间。唯一的不同是每一个节点都可以存放数据并且可以拥有子节点。就好比一个即是文件又是目录的文件系统。每一个节点都表现为 / 分隔的绝对路径;并不支持相对路径。路径中可以使用所有unicode字符,但是有如下限制:
- 空字符(\u0000)不能用于路径名(这会导致C语言绑定问题)。
- \u0001 - \u0019 and \u007F - \u009F 这些字符会导致显示问题,所以不应该在路径中使用。
- 如下字符不允许在路径中使用:\ud800 -uF8FFF, \uFFF0-uFFFF, \uXFFFE - \uXFFFF (X代表十六进制的1-E), \uF0000 - \uFFFFF.
- "." 可以用作路径的一部分,但不能单独用 "." 或 "..",因为zk不能使用相对路径。比如这些路径是不合法的:"/a/b/./c" or "/a/b/../c".
- "zookeeper" 是一个关键词,不能被使用,zk预建了zookeeper节点。
zk树状结构的每个节点被称之为 znode 。znode包含一个描述其状态的数据结构,包括数据和 ACL 变更的版本号,以及时间戳。版本号和时间戳一起就可以让zk验证缓存并协调更新。每当znode的数据有变化,版本号都会加1。例如,每次客户端取数据的时候版本号都会一同被拿到。当客户端执行更新或删除的时候必须提供数据版本号。如果提供的版本号与实际的数据版本号不一致,更新会失败。(这个动作可以被重写,参见...[tbd...])
在分布式应用中,一个字符节点可以代表主机、服务器、集群的成员或者一个客户端进程等。在zk文档中,znode代表一个数据节点。
servers 是指组成ZooKeeper服务的机器;quorum peers指的是构成一个集群的服务器;client指的是使用zk的任何一台主机或进程。
开发者最常使用的就是 znode 。通常扮演如下几种角色:
客户端会监控 znode 。节点的改变会触发监控并清除当前监控,也就是说监控是一次性的。当一个监控被触发,zk会通知客户端。更详细的描述在 ZooKeeper Watches 章节。
每一个节点存储的数据都可以被原子性的读写。读操作会读取znode下所有的数据,反过来,写操作会替换所有数据。每个节点都通过访问控制列表来进行权限限制。
zk设计之初就不是用来存储大型数据的, 它是用来进行数据协调的。这些数据的表现形式一般是配置信息、状态信息或者 rendezvous 等。他们的共同点是数据量相对较小,以KB为单位。zk客户端和服务端都会进行一些 check 来保证znode的数据量在1M以下,但平均来说,远达不到这个数据量。数据量较大的话,由于通过网络传输数据到存储介质会花费额外的时间,所以影响有些操作的延时。如果必须要存贮大型数据,一般采取的方式是将数据存放在大容量存储系统上例如 NFS 或 HDFS,然后将位点信息存放在zk上。
zk还有临时节点的概念。临时节点就是当创建它的会话不活动的时候就会被删除。由于这个特性,临时节点不可以有子节点。
在创建节点的时候你可以让zk在节点路径的末尾附加一个单调递增的计数器。这个计数器相对于父节点来说是唯一的。计数器的格式是 %010d,即左侧补0的十位数字(用来简化排序)。例如:"0000000001" 。参照队列说明的例子来使用此特性。PS:父节点会为第一级子节点维护一个有符号整型(4bytes)计数器,当计数器超过2147483647时会溢出(最终的节点名会是"-2147483647")。
zk跟踪时间有多种方式:
- Zxid 每次zk状态变更都会受到一个 zxid(ZooKeeper Transaction Id)形式的时间戳。它能表现出 zk 变更的顺序。每次变更都有一个唯一的 zxid,如果 zxid1 比 zxid2 小那么就能知道 zxid1发生在 zxid2 之前。
- Version numbers 节点每次变更都会使其版本号自增。有三个版本号:version(znode数据版本号),cversion(znode子节点版本号),averson(ACL版本号)。
- Ticks 当zk集群部署时,zk服务器使用ticks来定义状态上传,会话超时,连接超时等事件的时间。tick time 只能通过最小会话超时(2*tick time)来间接暴露,如果一个客户端请求的会话超时小于最小超时,服务器会高速客户端实际的超时时间是最小超时。
- Real time 除了 znode stat 结构体中的创建时间和修改时间,zk 不使用真实的时间或时钟。
znode stat 结构体说明:
- czxid znode创建的zxid
- mzxid znode修改的zxid
- ctime znode创建时间,距1970-1-1号的毫秒数
- mtime znode修改时间,距1970-1-1号的毫秒数
- version 数据版本号
- cversion 子节点版本号
- aversion ACL版本号
- ephemeralOwner 临时节点保存着创建它的会话 id。非临时节点始终为0
- dataLength znode数据长度
- numChildren znode子节点个数
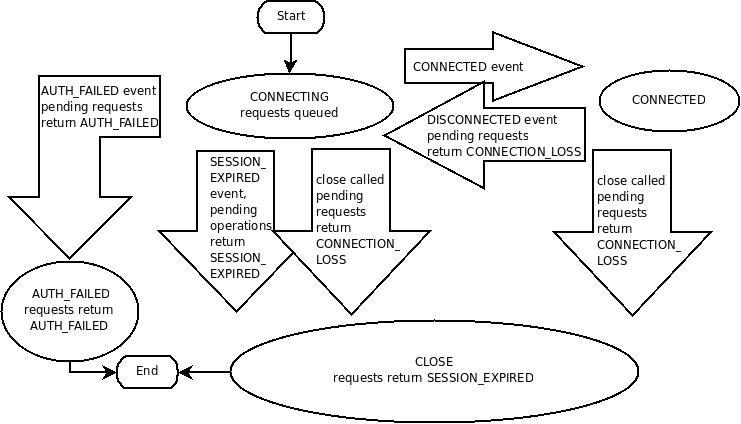
During normal operation will be in one of these two states. If an unrecoverable error occurs, such as session expiration or authentication failure, or if the application explicitly closes the handle, the handle will move to the CLOSED state. The following figure shows the possible state transitions of a ZooKeeper client:
zk客户端通过使用语言绑定创建一个到zk服务的句柄来与服务端建立会话。一旦句柄建立,它的初始态为 CONNECTING,客户端尝试连接zk集群中的某个服务器,连接成功后状态将变为 CONNECTED 。通常的操作将会是这两种状态。当有不可恢复的错误出现时,比如会话过期、授权失败或者客户端断开连接,客户端句柄将会切换为 CLOSED 状态。下图为zk客户端的状态迁移图:
To create a client session the application code must provide a connection string containing a comma separated list of host:port pairs, each corresponding to a ZooKeeper server (e.g. "127.0.0.1:4545" or "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002"). The ZooKeeper client library will pick an arbitrary server and try to connect to it. If this connection fails, or if the client becomes disconnected from the server for any reason, the client will automatically try the next server in the list, until a connection is (re-)established.
Added in 3.2.0: An optional "chroot" suffix may also be appended to the connection string. This will run the client commands while interpreting all paths relative to this root (similar to the unix chroot command). If used the example would look like: "127.0.0.1:4545/app/a" or "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/app/a" where the client would be rooted at "/app/a" and all paths would be relative to this root - ie getting/setting/etc... "/foo/bar" would result in operations being run on "/app/a/foo/bar" (from the server perspective). This feature is particularly useful in multi-tenant environments where each user of a particular ZooKeeper service could be rooted differently. This makes re-use much simpler as each user can code his/her application as if it were rooted at "/", while actual location (say /app/a) could be determined at deployment time.
When a client gets a handle to the ZooKeeper service, ZooKeeper creates a ZooKeeper session, represented as a 64-bit number, that it assigns to the client. If the client connects to a different ZooKeeper server, it will send the session id as a part of the connection handshake. As a security measure, the server creates a password for the session id that any ZooKeeper server can validate.The password is sent to the client with the session id when the client establishes the session. The client sends this password with the session id whenever it reestablishes the session with a new server.
One of the parameters to the ZooKeeper client library call to create a ZooKeeper session is the session timeout in milliseconds. The client sends a requested timeout, the server responds with the timeout that it can give the client. The current implementation requires that the timeout be a minimum of 2 times the tickTime (as set in the server configuration) and a maximum of 20 times the tickTime. The ZooKeeper client API allows access to the negotiated timeout.
When a client (session) becomes partitioned from the ZK serving cluster it will begin searching the list of servers that were specified during session creation. Eventually, when connectivity between the client and at least one of the servers is re-established, the session will either again transition to the "connected" state (if reconnected within the session timeout value) or it will transition to the "expired" state (if reconnected after the session timeout). It is not advisable to create a new session object (a new ZooKeeper.class or zookeeper handle in the c binding) for disconnection. The ZK client library will handle reconnect for you. In particular we have heuristics built into the client library to handle things like "herd effect", etc... Only create a new session when you are notified of session expiration (mandatory).
Session expiration is managed by the ZooKeeper cluster itself, not by the client. When the ZK client establishes a session with the cluster it provides a "timeout" value detailed above. This value is used by the cluster to determine when the client's session expires. Expirations happens when the cluster does not hear from the client within the specified session timeout period (i.e. no heartbeat). At session expiration the cluster will delete any/all ephemeral nodes owned by that session and immediately notify any/all connected clients of the change (anyone watching those znodes). At this point the client of the expired session is still disconnected from the cluster, it will not be notified of the session expiration until/unless it is able to re-establish a connection to the cluster. The client will stay in disconnected state until the TCP connection is re-established with the cluster, at which point the watcher of the expired session will receive the "session expired" notification.
Example state transitions for an expired session as seen by the expired session's watcher:
'connected' : session is established and client is communicating with cluster (client/server communication is operating properly) .... client is partitioned from the cluster 'disconnected' : client has lost connectivity with the cluster .... time elapses, after 'timeout' period the cluster expires the session, nothing is seen by client as it is disconnected from cluster .... time elapses, the client regains network level connectivity with the cluster 'expired' : eventually the client reconnects to the cluster, it is then notified of the expiration Another parameter to the ZooKeeper session establishment call is the default watcher. Watchers are notified when any state change occurs in the client. For example if the client loses connectivity to the server the client will be notified, or if the client's session expires, etc... This watcher should consider the initial state to be disconnected (i.e. before any state changes events are sent to the watcher by the client lib). In the case of a new connection, the first event sent to the watcher is typically the session connection event.
The session is kept alive by requests sent by the client. If the session is idle for a period of time that would timeout the session, the client will send a PING request to keep the session alive. This PING request not only allows the ZooKeeper server to know that the client is still active, but it also allows the client to verify that its connection to the ZooKeeper server is still active. The timing of the PING is conservative enough to ensure reasonable time to detect a dead connection and reconnect to a new server.
Once a connection to the server is successfully established (connected) there are basically two cases where the client lib generates connectionloss (the result code in c binding, exception in Java -- see the API documentation for binding specific details) when either a synchronous or asynchronous operation is performed and one of the following holds:
The application calls an operation on a session that is no longer alive/valid The ZooKeeper client disconnects from a server when there are pending operations to that server, i.e., there is a pending asynchronous call. Added in 3.2.0 -- SessionMovedException. There is an internal exception that is generally not seen by clients called the SessionMovedException. This exception occurs because a request was received on a connection for a session which has been reestablished on a different server. The normal cause of this error is a client that sends a request to a server, but the network packet gets delayed, so the client times out and connects to a new server. When the delayed packet arrives at the first server, the old server detects that the session has moved, and closes the client connection. Clients normally do not see this error since they do not read from those old connections. (Old connections are usually closed.) One situation in which this condition can be seen is when two clients try to reestablish the same connection using a saved session id and password. One of the clients will reestablish the connection and the second client will be disconnected (causing the pair to attempt to re-establish its connection/session indefinitely).
zk中所有的读操作 —— getDate(), getChildren(), exists() 都有一个设置监控的选项。zk对watch的定义:一个监控事件就是一个一次性触发器,当监控的节点数据发生变化时会给客户端发送这个事件。对于监控的定义有如下三个关键点:
当数据发生变化时会给客户端发送一个监控事件。例如,客户端调用了 getDate("/znode1", true),然后 /znode1 变化或者删除了,客户端会收到一个 /znode1 的监控事件。假如 /znode1 再次发生变化,在客户端再次进行带监控的读操作之前不会再次发送监控事件。
这意味着有一个事件被发往客户端,但这个事件不一定比更新成功的返回码更快到达客户端。监控事件是异步发往监控者的。zk可以保证顺序:在监控事件到达之前客户端不会感知到数据的变化。网络延迟或其他原因可能导致不同的客户端在不同的时间感知到监控事件及数据变化。关键点在于不同客户端感知到变化将会有严格的顺序。
This refers to the different ways a node can change. It helps to think of ZooKeeper as maintaining two lists of watches: data watches and child watches. getData() and exists() set data watches. getChildren() sets child watches. Alternatively, it may help to think of watches being set according to the kind of data returned. getData() and exists() return information about the data of the node, whereas getChildren() returns a list of children. Thus, setData() will trigger data watches for the znode being set (assuming the set is successful). A successful create() will trigger a data watch for the znode being created and a child watch for the parent znode. A successful delete() will trigger both a data watch and a child watch (since there can be no more children) for a znode being deleted as well as a child watch for the parent znode. Watches are maintained locally at the ZooKeeper server to which the client is connected. This allows watches to be lightweight to set, maintain, and dispatch. When a client connects to a new server, the watch will be triggered for any session events. Watches will not be received while disconnected from a server. When a client reconnects, any previously registered watches will be reregistered and triggered if needed. In general this all occurs transparently. There is one case where a watch may be missed: a watch for the existence of a znode not yet created will be missed if the znode is created and deleted while disconnected.