——package com.google.common.base
"函数式编程"是一种"编程范式",主要思想是把运算过程尽量写成一系列嵌套的函数调用。
特点:
- 函数是"第一等公民"
指的是函数与其他数据类型一样,可以作为参数传递,也可以作为返回值 - 只用"表达式",不用"语句"
"表达式"(expression)是一个单纯的运算过程,总是有返回值;"语句"(statement)是执行某种操作,没有返回值。 - 没有"副作用"
函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。 - 不修改状态
不修改变量,意味着状态不能保存在变量中。函数式编程使用参数保存状态,最好的例子就是递归。 - 引用透明
任何时候只要参数相同,引用函数所得到的返回值总是相同的。
JDK8之前并不支持函数式编程,所以Guava提供了一套函数式编程的工具,包括:
- Predicate<T> 断言接口(Facade模式)
- Function<F, T> 函数接口
- Supplier
- Functions 函数工具类,通过内部类提供了很多实用函数(结尾带s的都是工厂模式)
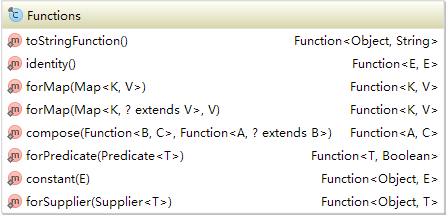

- forMap(Map):返回一个搜索Map的函数,apply(key),map中存在key则返回value,否则抛出异常
- forMap(Map, V):带默认值的搜索Map函数,key不存在是返回默认值,可以是null
- compose(Function a, Function b):将两个函数进行组合,相当于a.apply(b.apply)(桥接模式)
- constant(E):不管输入是什么,都会返回一个常量
- forPredicate(Predicate):将一个断言转换成返回值为Boolean的函数(适配器模式)
- forSupplier(Supplier):将一个Supplier转换成函数,不管传入参数是什么,都返回supplier.get()
- forMap(Map):返回一个搜索Map的函数,apply(key),map中存在key则返回value,否则抛出异常
- Predicates 断言工具类,有一些断言的实现
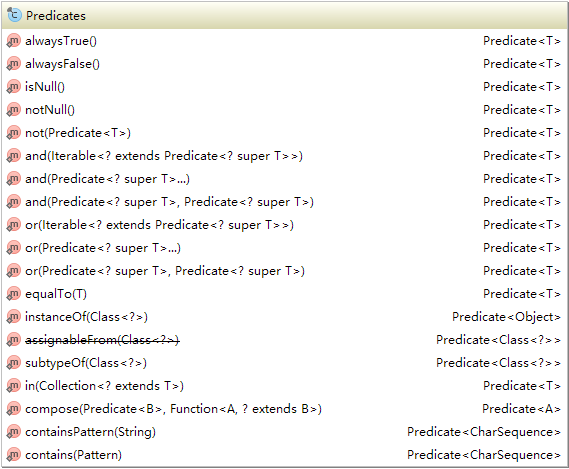
-compose(Predicate p, Function f):p.apply(f.apply()) - Suppliers
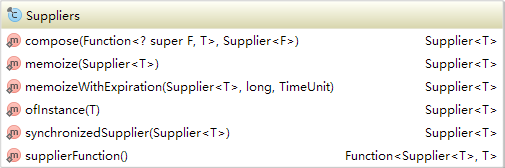
- compose(Function f, Supplier s):f.apply(s.get())
- memoize(Supplier):带缓存的Supplier
疑问:Function和Predicate中为什么要定义equals()?
- FinalizableReference
- FinalizableSoftReference
- FinalizableWeakReference
- FinalizablePhantomReference
- FinalizableReferenceQueue
在java体系中,并没有在reference对象中定义相应的回调方法,因此guava为jdk的reference增加了新的定义接口,称之为FinalizableReference。
增加了finalizeReferent()方法来实现gc后的回调。
- Strings
Strings 提供了空指针、空字符串的判断和互换方法。
Strings.isNullOrEmpty("");//true
Strings.nullToEmpty(null);//""
Strings.nullToEmpty("a");//"a"
Strings.emptyToNull("");//null
Strings.emptyToNull("a");//"a"
拿到字符串入参之后,调用一下 nullToEmpty 将可能的空指针变成空字符串,然后也就不用担心字符串引发的 NPE,或者字符串拼接时候出现的 “null” 了。
Strings 还提供了常见的字符串前后拼接同一个字符直到达到某个长度,或者重复拼接自身 n 次。
Strings.padStart("7", 3, '0');//"007"
Strings.padStart("2016", 3, '0');//"2016"
Strings.padEnd("4.", 5, '0');//"4.000"
Strings.padEnd("2016", 3, '!');//"2016"
Strings.repeat("hey", 3);//"heyheyhey"
public static String repeat(String string, int count) {
checkNotNull(string); // eager for GWT.
if (count <= 1) {
checkArgument(count >= 0, "invalid count: %s", count);
return (count == 0) ? "" : string;
}
// IF YOU MODIFY THE CODE HERE, you must update StringsRepeatBenchmark
final int len = string.length();
final long longSize = (long) len * (long) count;
final int size = (int) longSize;
if (size != longSize) {
throw new ArrayIndexOutOfBoundsException("Required array size too large: " + longSize);
}
final char[] array = new char[size];
string.getChars(0, len, array, 0);
int n;
for (n = len; n < size - n; n <<= 1) {
System.arraycopy(array, 0, array, n, n);
}
System.arraycopy(array, 0, array, n, size - n);
return new String(array);
}
int 升级 long 然后降级 int,是为了确保字符串 repeat 之后没有超过 String 的长度限制,
而先强制提升然后截断的方法,能够高效的判断溢出
Strings 的最后一组功能是查找两个字符串的公共前缀、后缀。
Strings.commonPrefix("aaab", "aac");//"aa"
Strings.commonSuffix("aaac", "aac");//"aac"
-
CharMatcher
CharMatcher提供了多种对字符串处理的方法, 它的主要意图有:- 找到匹配的字符
- 处理匹配的字符
CharMatcher内部主要实现包括两部分:
- 实现了大量公用内部类, 用来方便用户对字符串做匹配: 例如 JAVA_DIGIT 匹配数字, JAVA_LETTER 匹配字母等等.
- 实现了大量处理字符串的方法, 使用特定的CharMatcher可以对匹配到的字符串做出多种处理, 例如 remove(), replace(), trim(), retain()等等
CharMatcher本身是一个抽象类, 其中一些操作方法是抽象方法, 他主要依靠内部继承CharMatcher的内部子类来实现抽象方法和重写一些操作方法, 因为不同的匹配规则的这些操作方法具有不同的实现要求(模板方法模式)
- 找到匹配的字符
CharMatcher negate(): 返回以当前Matcher判断规则相反的Matcher CharMatcher and(CharMatcher other): 返回与other匹配条件组合做与来判断的Matcher CharMatcher or(CharMatcher other): 返回与other匹配条件组合做或来判断的Matcher
CharMatcher.javaUpperCase().matches('A'); //true
CharMatcher.javaUpperCase().negate().matches('A'); //false
CharMatcher.javaUpperCase().matches('a'); //false
CharMatcher.javaUpperCase().negate().matches('a'); //true
CharMatcher.is('c').indexIn("abcdc"); //2
CharMatcher.is('c').indexIn("abcdc", 3); //3
CharMatcher.is('c').and(CharMatcher.noneOf("abd")).matches('c') //true
CharMatcher.is('c').and(CharMatcher.noneOf("abc")).matches('c') //false
疑问:setBits()干嘛用的? 附:BitSet讲解
- Ascii
提供了一组操作Ascii(0x00~0x7F)字符的方法,如下:
- CaseFormat
不同命名方式转换的工具类,不支持Ascii以外的字符
通过枚举定义了各种格式:
- LOWER_HYPHEN 中折线命名,如test-test
- LOWER_UNDERSCORE 小写下划线命名,如test_test
- UPPER_UNDERSCORE 大写下划线命名,如TEST_TEST
- LOWER_CAMEL 小写驼峰命名,如testTest
- UPPER_CAMEL 大写驼峰命名,如TestTest
两个模板方法: - to(CaseFormat, String)
- convert(CaseFormat, String)
两个方法很类似,只有一点不同,如果两种格式相同to不会做转换,直接返回原字符串,而conver依然会做一次转换
- LOWER_HYPHEN 中折线命名,如test-test
UPPER_CAMEL.convert(UPPER_CAMEL, "testTest") //TestTest
UPPER_CAMEL.to(UPPER_CAMEL, "testTest") //testTest
UPPER_CAMEL.to(LOWER_UNDERSCORE, "testTest") //test_test
通过枚举实现单例工厂
- Spliter
提供各种字符串分割方法
跟上面的一样,返回类型为Spliter的为工厂方法,返回一个特定的Spliter,调用其splite方法进行分割
Spliter与apache commons的StringUtils对比: 1.Spliter面向对象,StringUtils面向过程
// Apache StringUtils...
String[] tokens1= StringUtils.split("one,two,three",',');
// Google Guava splitter...
Iteratable<String> tokens2 = Splitter.on(','),split("one,two,three");
2.Spliter分割结果是迭代器(写快读慢),StringUtils是数组(读快写慢) 附:Spliter与apache commons的StringUtils对比
- Joiner
还是一样,是个工厂,调用join来连接字符串
-
PreConditions
防御式编程工具类,参数检查异常提前抛出,大家都懂的...
表达式正确性检查:
checkArgument(expression) expression=false抛出IllegalArgumentException
非空检查:
checkNotNull(T), 被检查对象为空抛出NullPointerException,否则返回原对象
边界检查:
checkElementIndex(index, size) index不合法抛出IndexOutOfBoundsException,size不合法IllegalArgumentException -
Verify
跟PreConditions差不多,只不过只能检查表达式是否为true,false的时候PreConditions抛出jdk定义的异常,而Verify抛出guava自己的VerifyException -
Defaults
返回各种类型的默认值 -
Enums
枚举类型常用方法的工具类,不知道有什么用。
-
Equivalence
这个类实现的功能都可以通过重写equals方法,但是通过Equivalence可以更加优雅的实现。
public final boolean equivalent(@Nullable T a, @Nullable T b) {
if (a == b) {
return true;
}
if (a == null || b == null) {
return false;
}
return doEquivalent(a, b);
}
protected abstract boolean doEquivalent(T a, T b);
- Objects
可以比较两个可能为null的对象,避免 NPE - StopWatch
用来计时的 - Throwables
异常处理工具类 我们在日常的开发中遇到异常的时候,往往需要做下面的几件事情中的一些:- 将异常信息存入数据库、日志文件、或者邮件等。
- 将checkedException转换为UncheckedException
- 在代码中得到引发异常的最低层异常
- 得到异常链
- 过滤异常,只抛出感兴趣的异常
Throwables给我们提供了这些常用的方法