gsoc final report
SPDX YALM authored by @m1kit
Detecting the contents of license documents is a major task for software that automatically analyzes software metadata, such as package managers. OSS licenses can be detected automatically by comparing the license document with templates of major OSS licenses managed by SPDX using a string algorithm. However, typical string comparison algorithms are vulnerable to small additions of malicious wording.
For this reason, SPDX has provided the guideline for matching license documents. In addition, several license detection algorithms have been implemented. Among them, spdx_python_licensematching aims to faithfully reproduce the guidelines.
I have been working on two major tasks: to improve the existing implementation, and to release it as a library YALM to the world.
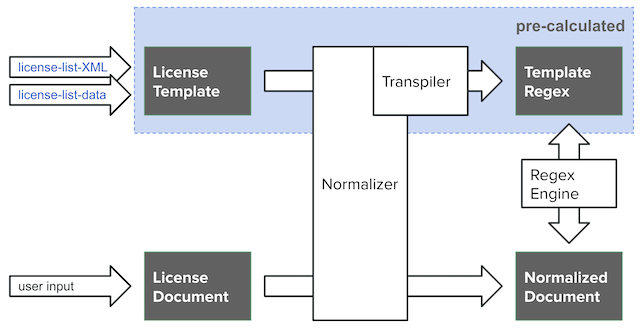
I implemented a license detection library, YALM, that follows the SPDX License Matching Guideline as much as possible. YALM determines the SPDX License Identifier that matches a given license document(example) based on the guideline and SPDX license templates.
To achieve this, YALM first normalizes small shifts in notation in the document. Then, it transpiles the license templates maintained by SPDX into regular expressions and checks if they match the normalized document by using an existing regular expression engine. Given a document, license detection can be achieved by comparing it with a large number of license templates to see if they match.
First of all, you need to install YALM.
pip install yalm
Then, you can detect the license of your file like:
import yalm.licenses
with open('path/to/file') as f:
result = yalm.licenses.detect_license(f.read())
print(result.template.name)(Note that the API above may be subject to change.)
terregex is a library I developed to transform a regex pattern. I developed it because YALM uses a regular expression engine as the backbone of its algorithms, and in some situation, we need to convert a pattern according to some rules.
For example, even if you want to convert all alphabets in a pattern to lowercase, you need to keep classes such as \W in uppercase. terregex can take such semantic differences into account.
Repo: m1kit/terregex
In order to prevent false positives due to small notational shifts, YALM normalizes documents and templates according to specific rules. SPDX license template (like this) has expressions to show which part of the license template is replacable and which part is omitable. In the past, all those expressions were converted to regular expressions and then normalized. However, those expressions should be subjected to a different normalization process. So YALM normalizes them first and then converts them into regular expressions.
PR: #18
Regular expression testing is accurate but slow. To reduce inference time, I introduced word-based testing. By using license templates, we can extract essential words and we can quickly determine a document contains these words or not.

PR: #18
SPDX manages hundreds of different licenses, and the number is growing daily. Since it is difficult to manually set up test cases for all of these licenses, I generated random license documents from license templates as test cases.
PR: #22
YALM uses a variety of resources, including license templates. These resources are updated from time to time, so they need to be regenerated. However, regenerating them at runtime leads to unnecessary overhead. In order to solve this problem, I have developed a framework for managing various resources.
We have resources listed below at m1kit/yalm-resources and they are updated periodically.
- License List
- Templates
- Real Samples for Testing
- Generated Samples for Testing
- Pre-transplied Regex
- Pre-extracted Word-set
equivalentwords.txtexpected-duplicates.json
By keeping these resources separated, we can use them when we port this library to another language.

Repo: m1kit/yalm-resources
I released an alpha version of this library on PyPI. Now we can install this library like this:
pip install yalm
Due to catastrophic backtracking, sometimes regex engine hung up. To prevent ReDoS I introduced timeout mechanism. Additionally, I added support for multiprocessing.
PR: #28
I was not able to implement all of the proposed features. However, I'd like to continue to develop these after the program.
The APIs are an important part of the library, and I would like to finalize it after discussion with the community. Also, the APIs should be documented well and published on readthedocs.
According to the integration tests, some test cases are failing. These are due to multiple factors, and the following causes have been identified (but not fixed yet).
Currently, when an unexpected mismatch occurs, it is not possible to indicate which part of the document caused the mismatch. There are many existing implementations, such as difflib, that show the differences between documents. However, in YALM's normalized documents, all newlines are removed, and in many cases the differences are meaningless.
We need de-normalizer, which restores newlines from normalized documents, to make differences clear.
At this time, only the coupling tests for the license classification API have been performed. In the future, we need to add some unit tests.
Existing tools in SPDX do not perform regular expression-based license detection like YALM. It would be nice to be able to replace the existing tools with YALM in the future.
The package management system, one of the expected use cases of this library, has been implemented in a number of languages. In the future, I hope to provide SPDX YALM in languages such as Java and Ruby.
First of all, I would like to thank @anshuldutt21 san for creating the first code base. The idea of transpiling the templates into regular expressions to follow the guidelines was his, and his implementation was very well thought out. This project won't be like this without his efforts.
Also, this project would not have been possible without the mentoring of @goneall san. The SPDX community has been working on the problem of license matching for many years, and they have knowledge about issues and solutions that I did not know. They were kind enough to provide me with relevant knowledge as the situation required.
Finally, I would like to thank members of the community for discussing with me and the GSoC for giving me this great opportunity.