Conversation
| 3. Try hitting the test endpoint on the server, by navigating to `http://0.0.0.0:8443/hello` in your browser. | ||
| 4. Try running a packing on the server, by hitting the `http://0.0.0.0:80/pack?recipe=firebase:recipes/one_sphere_v_1.0.0` in your browser. | ||
| 3. Try hitting the test endpoint on the server, by navigating to `http://0.0.0.0:80/hello` in your browser. | ||
| 4. Try running a packing on the server, by hitting the `http://0.0.0.0:80/start-packing?recipe=firebase:recipes/one_sphere_v_1.0.0` in your browser. |
There was a problem hiding this comment.
These instructions were just slightly incorrect, this has nothing to do with the other code changes, I just ran into it when testing my code and I wanted to fix it
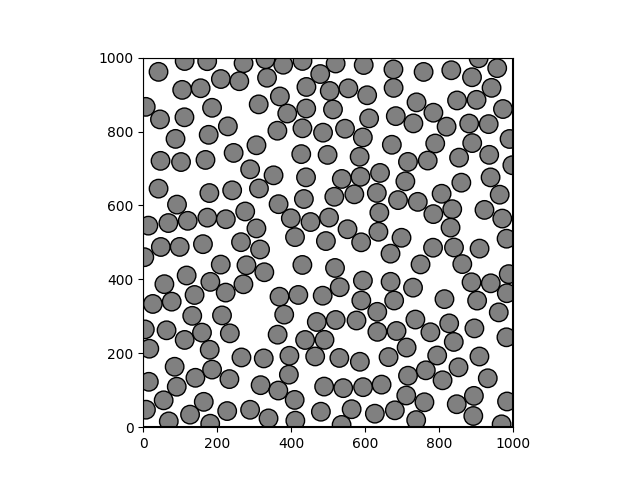
Packing analysis reportAnalysis for packing results located at cellpack/tests/outputs/test_spheres/spheresSST
Packing imageDistance analysisExpected minimum distance: 50.00
|

63ca5ae to
bd8ec42
Compare
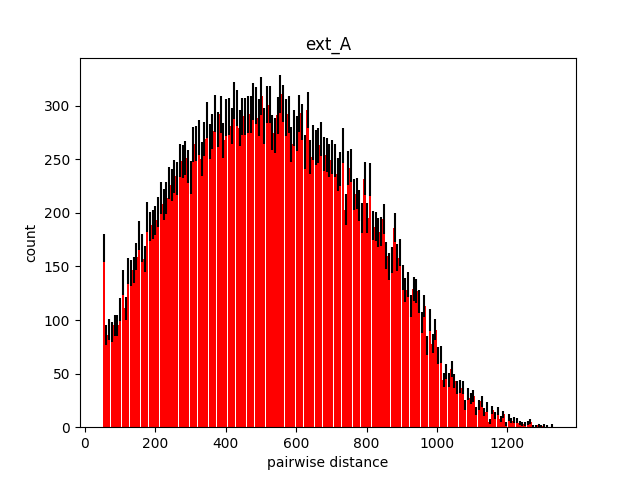
Packing analysis reportAnalysis for packing results located at cellpack/tests/outputs/test_spheres/spheresSST
Packing imageDistance analysisExpected minimum distance: 50.00
|
* remove os fetch for job_id * use dedup_hash instead of job id * proposal: get hash from recipe loader * renaming and add TODOs * format * rename param to hash * remove unused validate param and doc strings in pack * simplify get_ dedup_hash * refactor job_status update * cleanup * fix upload_job_status to handle awshandler * pass dedup_pash to env for fetching across files * add tests * format1 * format test
* remove os fetch for job_id * use dedup_hash instead of job id * proposal: get hash from recipe loader * renaming and add TODOs * format * rename param to hash * remove unused validate param and doc strings in pack * simplify get_ dedup_hash * refactor job_status update * cleanup * fix upload_job_status to handle awshandler * pass dedup_pash to env for fetching across files * add tests * format1 * format test
* proposal: get hash from recipe loader * simplify get_ dedup_hash * only post simularium results file once for server job runs * update code for rebase * code cleanup --------- Co-authored-by: Ruge Li <rugeli0605@gmail.com>
* remove local metadata writes for auto-pop feature * remove cleanup firebase workflow * remove cleanup firebase code * 1. make doc url a constant 2.remove unused param
c1d5718 to
c2259af
Compare
cellpack/bin/pack.py
Outdated
| recipe_loader = RecipeLoader( | ||
| recipe, packing_config_data["save_converted_recipe"], docker | ||
| ) | ||
| if isinstance(recipe, dict): |
There was a problem hiding this comment.
Try moving this to recipe_loader, it might be cleaner
 mogres
left a comment
mogres
left a comment
There was a problem hiding this comment.
Read through the changes and left some clarifying comments. I might do some testing later just to verify none of the other workflows are breaking.
Really awesome work putting this together! Excited to see the speedup in cellPACK studio.
There was a problem hiding this comment.
One suggestion to handle multiple input streams:
- Update the
RecipeLoaderinit to accept a singleinput_dataargument which can be a path to a file or a dictionary. This should avoid potetntial bugs from conflicting inputs passed throughinput_file_pathandjson_recipesince there is only one input now. - Handle resolving the path or dict inside the
read()method. This might require getting rid of the file path and file extension attributes which are not really used I think
| if file_name and url: | ||
| simulariumHelper.store_metadata( | ||
| file_name, url, db="firebase", job_id=job_id | ||
| if dedup_hash is None: |
There was a problem hiding this comment.
Can you clarify what happens here if dedup_hash is not None? Is the result not opened in browser if this is run locally?
There was a problem hiding this comment.
For server jobs, the result file is uploaded as part of the outputs directory via upload_outputs_to_s3, the frontend can then fetch the result_path and display simularium result in Studio, so we intentionally skip the separate upload when dedup_hash is not None here.
For local packings, dedup_hash is None, so the existing upload +open in browser is preserved.
| # If db is AWSHandler, switch to firebase handler for job status updates | ||
| if hasattr(self.db, "s3_client"): | ||
| handler = DATABASE_IDS.handlers().get(DATABASE_IDS.FIREBASE) | ||
| db_handler = handler(default_db="staging") |
There was a problem hiding this comment.
Would this overwrite the self.db attribute? Might be better to create a new handler object or use .copy() just in case
cellpack/autopack/DBRecipeHandler.py
Outdated
| ) | ||
| db_handler = self.db | ||
| # If db is AWSHandler, switch to firebase handler for job status updates | ||
| if hasattr(self.db, "s3_client"): |
There was a problem hiding this comment.
Is it possible to directly check if this is an AWSHandler using isinstance? Idk if it is possible for it to not have the s3_client attribute but just in case.
There was a problem hiding this comment.
to your question above: no, self.db is not overwritten. In this case, db_handler is reassigned to a local variable that points to the Firebase handler, self.db remains as s3_client.
And I agree, isinstance would be more explicit and robust here, thanks for calling that out!
There was a problem hiding this comment.
Might be good to have an integration test to check if the changes in this file don't break the local workflow: pack -r RECIPE_PATH -c CONFIG_PATH with a mock recipe and config. Not sure if we have this already
| autopack.helper = helper | ||
| env = Environment(config=packing_config_data, recipe=recipe_data) | ||
| env.helper = helper | ||
| env.dedup_hash = hash |
There was a problem hiding this comment.
You might have to update the environment __init__ to initialize the dedup_hash attribute as None
| config_data=packing_config_data, | ||
| recipe_data=recipe_loader.serializable_recipe_data, | ||
| ) | ||
| if docker and hash: |
There was a problem hiding this comment.
Can you add a short docstring saying that this branch runs if pack is called from cellPACK studio (i.e. docker and hash are both provided)?
There was a problem hiding this comment.
We check this dedup hash against those existing in the job_status firebase collection to see if this exact recipe has already been packed, and if we find a match, we return it rather than running the packing
Just to clarify, do we still run the packing even if the dedup hash exists in firebase? Or do we just pull the results?
…m/mesoscope/cellpack into feature/server-passed-recipe-json
Co-authored-by: Saurabh Mogre <saurabh.mogre@alleninstitute.org>
@mogres Yeah in that case, we skip the packing entirely and return the |
…m/mesoscope/cellpack into feature/server-passed-recipe-json
Problem
Currently, when a user packs an edited recipe via the cellpack client, we upload the edited recipe to firebase, pass that reference to the server, and then the server retrieves the recipe from firebase. To minimize firebase calls and improve efficiency of the client, we're changing that flow to instead send the edited recipe JSON as the body of the packing request to the server.
We also wanted a way to check if we have already packed a recipe and if we have, return that result file rather than running the whole packing again. To do this, we are calculating a hash for the recipe objects before they are packed. The hash for each recipe will be uploaded to firebase along with its result files, so we can query firebase for a given hash to see if that recipe has a packing result already.
Key Server Improvements
1. Deduplication & Caching
2. Input Flexibility & Backwards Compatibility
3. Smart Job Management
4. Firebase Request Reduction
5: Unified Results Upload
Technical Implementation
New Server Components:
DataDoc.generate_hash()- Creates deterministic hash from recipe JSONjob_exists()- Checks if job already completed in FirebaseRequest Flow Changes:
Benefits
CellPACK Server Job Workflow Changes
BEFORE: Original Server Workflow
graph TD A[Client Request] --> B[POST /start-packing] B --> C{Check for recipe URL param} C -->|Missing| D[Return 400 Error] C -->|Present| E[Generate UUID for job_id] E --> F[Create Background Task] F --> G[Return job_id immediately] F --> I[Initiate packing] I --> J[Load recipe from firebase<br>using file path from<br>URL param] J --> K[Execute packing] K --> L{Packing succeeds?} L -->|Success| M[S3: Upload outputs to S3<br>Firebase: Update job status to SUCCEEDED] L -->|Failure| N[Firebase: Update job status to FAILED] style A fill:#e1f5fe style G fill:#c8e6c9 style M fill:#fff3e0 style N fill:#ffcdd2AFTER: Enhanced Server Workflow with JSON Recipe Support
graph TD A[Client Request] --> B[POST /start-packing] B --> C{Check inputs} C -->|No recipe - no URL param<br>and no request body| D[Return 400 Error] C -->|Has recipe path URL param| E[Generate UUID for job_id] C -->|Has recipe JSON in request body| F[Generate hash from JSON] F --> G{Packing result exists<br>in firebase for this hash?} G -->|Yes| H[Return existing hash<br>as job_id] G -->|No| I[Use hash as job_id] E --> J[Create Background Task] I --> J J --> K[Return job_id immediately] J --> L[Initiate packing] L --> M{Input type?} M -->|Recipe path| N[Load recipe from firebase<br>using file path from<br>URL param] M -->|JSON body| O[Load recipe from JSON dict<br>from request body] N --> P[Execute packing] O --> P P --> Q{Packing succeeds?} Q -->|Success| R[S3: Upload outputs to S3<br>Firebase: Update job status to SUCCEEDED] Q -->|Failure| S[Firebase: Update job status to FAILED] style A fill:#e1f5fe style K fill:#c8e6c9 style R fill:#fff3e0 style S fill:#ffcdd2 style G fill:#ffeb3b style H fill:#c8e6c9