
Writing captions of images has always required the help of human’s knowledge in order to write catchy captions. Here in this project we have implemented the task of using a deep learning model, to automatically generate captions for images using visual attention mechanism. We have also shown visually how the model automatically learns to focus on specific parts of images, while predicting the corresponding words of the output sequence accurately. We have used two benchmark datasets – Flickr8k, MS COCO for our model
-
Flickr - 8k
- This dataset has around 8k images with 5 captions given for each image. Since it has very few images, we have used (Caption_1, Image), (Caption_2, Image) and so on... for all the 5 captions making the dataset comprise around 40k imagecaption pair. From this, 32000 images have been used for training and 8000 for validation, with the split ratio 0.2 MS-COCO This dataset has around 120k images with 5 captions for image Because of our GPU configuration, we kept our training images to be 25,600 and 6000 images for validation
-
MS-COCO
- This dataset has around 120k images with 5 captions for image. Because of our low GPU configuration, we kept our training images to be 25,600 and 6000 images for validation.
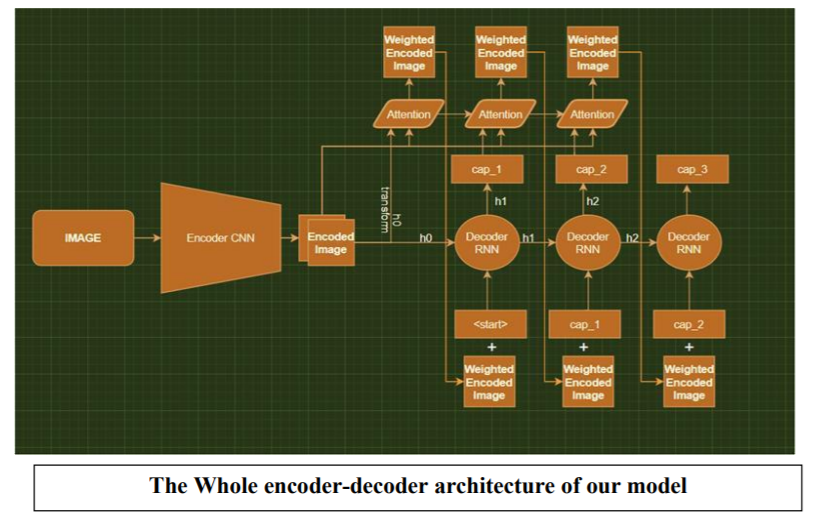
The model consists of 3 parts namely, the encoder, decoder and attention mechanism. For the purpose of encoder, we have used a Convolutional Neural Network, Inception v3, which is pre-trained on IMAGENET dataset for classification. For our purpose where we need to get the features encoded, we remove the last layer which is used for classification purpose. Using visual attention mechanism., we make the decoder be able to look at different parts of the image at every time step in the sequence.
Following are a few key hyperparameters that we retained across various models. These could be helpful for attempting to reproduce our results.
RNN Size 512
Batch size 64
Learning Rate 4e-4
RNN Sequence max
length 16
Epochs 30
Vocabulary size 5000
- It takes around 1 hour for training with Flickr8k dataset
- It took around 10 hours for training with COCO dataset.
Checking the accuracy of the model is tricky as the output is a sequence of words which could be correct even if the predicted caption is not exactly matching with the original caption. BLEU score can be used to measure the performance of the model.
Final bleu score: 0.008854
- Show and Tell: A Neural Image Caption Generator - Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan
- https://github.com/SubhamIO/ImageCaptioning-using-Attention-MechanismLocal-Attention-and-Global-Attention-
- https://www.tensorflow.org/tutorials/text/image_captioning