nidmap reverse prefix patch #4748
Conversation
 jjhursey
left a comment
jjhursey
left a comment
There was a problem hiding this comment.
My only concern with this PR is of my own making. The tryreverse mechanism in the nidmap is only activated when we detect the multiple digit set case. I would like to keep that mechanism in this bug fix as it both fixes the bug and provides efficient packing for that case.
I'm interested in what @ggouaillardet thinks on that part of this PR.
|
let's KISS :-) if I understand correctly, we search the digits forward, and if we detect a second set, we go reverse. if yes, then since
iirc, @rhc54 suggested backporting the new if not, and given the fact that a regex is expanded the same way regardless digits were searched forward or reverse, |
 ggouaillardet
left a comment
ggouaillardet
left a comment
There was a problem hiding this comment.
- reference to commit ids from the
masterbranch are missing (git cherry-pick -xcan do that automatically) - i do not think these should be signed-off-by once again (unless backported)
'-' is not an alpha character nor a digit, but it is a valid hostname character and should be handled as an alpha character, otherwise, nodes such as node-001 do not get "compressed" in the regex. Refs open-mpi#4621 Signed-off-by: Gilles Gouaillardet <[email protected]> (cherry picked from commit f3e2a31)
If we detect that someone has given us an incorrect node name, provide a helpful message telling them as it is almost certainly a typo. Signed-off-by: Ralph Castain <[email protected]> (cherry picked from commit 3269f2d)
e1dbdcb to
4897df8
Compare
|
@ggouaillardet I thought we couldn't backport the The reverse method should handle all of the cases we need it to (obviously we will want to test this out to confirm). But @rhc54 's concern was that it's hard to prove that we won't break other, currently support hostname formats. That's why you all went down the road of creating a framework on For simple hostnames (e.g., For the v3.0.x series we want the bug to be fixed (so we can launch >64 nodes with rsh launcher), and have an option for the user to get a better compression of the more complex hostname format (for master we recommend that users set |
|
here are the words of @rhc54 i misinterpreted
At first, let's agree we should fix the bug in the To me, the rationale for a I do not have a strong opinion on how to move forward for the
As far as i am concerned, i like 4) best, and feels less comfortable with 3). But once again, this is not a strong opinion. |
so any tree spawn operation properly gets the number of children underneath us. This commit is a tiny subset of open-mpi/ompi@347ca41 that should have been back-ported into the v3.0.x branch Fixes open-mpi#4578 Thanks to Carlos Eduardo de Andrade for reporting. Signed-off-by: Gilles Gouaillardet <[email protected]> (cherry picked from commit e445d47)
|
Yeah, this is a tough one. I remain concerned about the change to the nidmap algorithm - as we pointed out on the original PR, it is easy to come up with patterns that would have worked for the "forward" approach but don't work for the "reverse" one. This makes me nervous that some portion of the community will see new problems emerge. I therefore agree that it would be better to separate out ced40df from the other three commits as they are clear bug fixes and involve no debate. Going with the regx framework has its own issues. I fear it can get confusing to users if 3.1 requires an MCA param to resolve the nidmap problem, but 3.0 doesn't - it breaks the compatibility promise we made. Likewise, introducing a change in 3.0.1 does the same thing, but could be considered a "bug fix" requirement. I think a discussion with the RMs and general community is therefore required for the other commit, and probably for the commit of the new regx framework into v3.1 in #4747 as well due to the compatibility promise question. |
|
If we take out ced40df then we will need a custom patch to fix the original bug - hostnames with multiple sets of digits produce an invalid regex pattern preventing tree based launching with the In master the bug was fixed at the same time the I suggest that we remove ced40df from this PR, can then port over the minimal fix from the This means that it produces a correct, but suboptimal pattern for hostnames with multiple sets of digits. We can do that backport. As an aside: |
|
@jjhursey let's do that ! For Or I can do that a la
The latter approach is more generic, but i'd rather do it asap so it lands the @rhc54 any advice ? |
|
What may save us here is that ORTE uses the PMIx regex function to generate the regex given to the application procs. This means that the clients don't see the regex built by mpirun - only other daemons do, and we already require that they be of the same version. So we should be okay from that perspective regardless of the option you use since the daemons are not allowed to mix libopen-rte versions, and the ORTE-generated regex doesn't crossover between daemons and application procs. However, since the PMIx regex generator is the same as the ORTE "forward" algorithm, it means that this regex will also get the "wrong" answer in the IBM case...which means that clients are going to compute incorrect host locations for their peers - not good. Guess that means we need to port the regx framework to PMIx as well, and it raises questions about the embedded PMIx code in the 3.0 and 3.1 releases. |
|
@sam6258 Can you remove commit ced40df and backport 31ae3ea (then retest of course)? @rhc54 Yeah we need to fix the PMIx regex as well. We at least need to fix the bug in the |
|
FWIW: PMIx already has a regx framework, so all that should be required there is to create a suitable component. |
Refs. open-mpi/ompi#4689 Refs. open-mpi/ompi#4748 Signed-off-by: Gilles Gouaillardet <[email protected]>
|
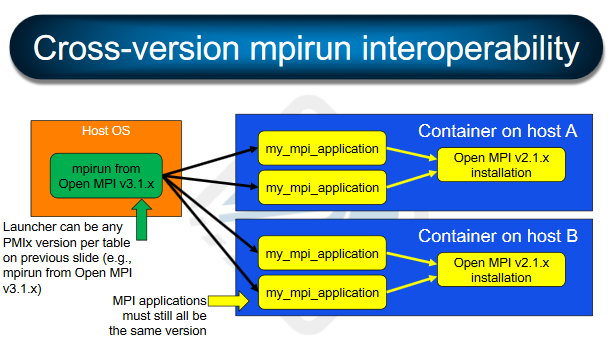
@rhc54 can you please help me correctly interpret slide 74 (Cross-version mpirun interoperability) that was presented at SC'17 Open MPI BoF ?
which
I never really thought about it, and my first impression was the second option. |
|
I think you'll find this discussed a bit here. Bottom line: all three scenarios exist in the wild and need to be supported. The guarantee given by OMPI is that any combination of v3.x will work. So the point here is that we have a problem - changing the nidmap mid-series means that containers (and static builds) using older v3.0 releases will fail when presented with a regex generated by the "reverse" (or your modified solution) algorithm. This breaks our compatibility promise. However, in the case of the framework approach, one could also argue that the only time the "reverse" component is activated is when the user explicitly requests it. In such cases, one would expect they have done so because they know the default mechanism will generate an error. Thus, we could argue that compatibility is preserved as the containerized older version of OMPI wouldn't have worked anyway on that system. I'm not sure what would happen if a regex from your alternative approach is given to an older version of nidmap for processing. I suspect it will fail - yes? If so, I don't believe we can use it in the v3.x release series. |
|
Thanks for the explanation ! currently, the Generally speaking, then yes, I agree there is a problem. A quite different approach is to have only one callback in the An intermediate approach would be to add a makes sense ? |
|
In PMIx, we do indeed prefix the regx with the name of the module that generated it, as you say, and we should do that going forward in OMPI. Since the regx framework isn't in prior versions, and there is no compatibility guarantee between major releases of OMPI, there is no problem in going that route. The issue really is just with the OMPI v3.1 vs v3.0 release series. I don't believe we can make any changes to the regex code in those two without violating the promise. |
4897df8 to
2c6431b
Compare
 rhc54
left a comment
rhc54
left a comment
There was a problem hiding this comment.
Should be okay, and won't affect backward compatibility
Refs. open-mpi/ompi#4689 Refs. open-mpi/ompi#4748 Signed-off-by: Gilles Gouaillardet <[email protected]> (cherry picked from commit 98073d7) Signed-off-by: Joshua Hursey <[email protected]>
|
@rhc54 back to the previously mentionned SC'17 slide, do we plan to support
we cannot prefix the regex in the middle of the series by default (otherwise we would break interoperability). That being said, we can have future components prefix it, and it will be up to the user |
|
@sam6258 the commit you backported is still titled |
|
We need to separate out the PMIx promise vs that of OMPI itself. I don't recall the precise slide, but the official OMPI promise is what was given on the wiki page - we only support "cross-version" support within a major release series (e.g., OMPI v3.1 with OMPI v3.0). We specifically exclude operations across major release series (e.g., between OMPI v3.x and OMPI v2.x). PMIx goes further as we have to support cross-subsystem integration - but that is purely a PMIx promise and doesn't impose anything on OMPI. |
|
That is the infamous slide. From your previous reply, I now understand it was incorrect.
|
|
Yeah, it's a little complicated. Even though PMIx might interoperate, the problem is that there is no guarantee that the information being communicated is the same. IIRC, what we say is that we guarantee interoperation if the major is the same, and it might work if the major is different - but we cannot guarantee it. I could be confused myself, so maybe @bwbarrett or @jsquyres should chime in. All I can say for certain is that the PMIx communication channel will work in that slide - I just can't guarantee the contents of that communication will meet all expectations/requirements. |
|
yep, we need to define what we want to achieve and where this should be discussed Starting at
last but not least, i think we should have MTT and/or CI test for interoperability, since it is so easy to break. |
|
Up to the community as to where to discuss it - we had a long discussion about this not so long ago, and I thought it had been captured (but I don't recall exactly where). As for the oob: only daemon-to-daemon communication uses the OOB, and we require the daemons to all be the same OMPI version. So I'm not sure why you feel the OOB is an issue? I do see that the apps open the oob/rml frameworks in master - IIRC, that was left solely so that @anandhis could test her rml/ofi code. Probably should be removed now. |
|
OK, let me see if I finally get it straight ... in https://github.com/open-mpi/ompi/wiki/Container-Versioning
what does orte exactly means here ?
|
|
You probably need to move this off of this PR - the discussion is way beyond this poor old PR. I honestly think you are over-thinking this. The promise was solely about the compatibility of the app to the launch infrastructure (mpirun + daemons). If you put an orted inside the container and try to use it with an mpirun outside the container, then we only guarantee compatibility if the two are within the same OMPI major release series. Period. And yes - that means the executable and any dynamically linked libraries - we don't distinguish between them. IMO, anybody invoking more than one OMPI version in a container is doing something very, very wrong. |
Refs. open-mpi#4689 Signed-off-by: Gilles Gouaillardet <[email protected]> (back-ported from commit a056fde) Signed-off-by: Scott Miller <[email protected]>
2c6431b to
28d49dc
Compare
|
Yeah this PR is ready to go now. If there is a question of if we should move the regx framework into the v3.1.x series then we should move the discussion to PR #4747. I would like to get PR #4747 merged soon (or some version with the bug fix in it) so I can do some scale testing with the Open MPI v3.1.x HEAD. |
|
@bwbarrett @hppritcha This PR is good to go. |
No description provided.