OpeLa Internal Design
OpeLa コンパイラは、セルフホストを達成するまでは C++ で記述します。 C++ の素晴らしい機能、ライブラリを活用して作りたいところですが、最終的に OpeLa 言語に移植することを考えるとバランスが大切です。 移植をスムーズにするためには、OpeLa コンパイラを実装するのに利用した C++ の言語機能やライブラリを、OpeLa 言語でも実現する必要があるからです。
OpeLa 言語には、MikanOS を実装するために欲しい言語機能とライブラリを用意したいと考えています。 したがって、OpeLa コンパイラもその範囲で実装するのが良いだろうと思います。 OpeLa コンパイラ V1 は、何も制約を考えずに実装していましたが、V2 はこれらの制約を踏まえて実装します。
OpeLa コンパイラ V2 を実装するのに利用する C++ の機能を考えるために、MikanOS の実装に活用している機能、ライブラリを洗い出しました。
- int や char 等の整数型、静的配列
- ビット指定の整数型(uint8_t、uint64_t など)
- グローバル変数、ローカル変数
- 関数
- ポインタ演算、関数ポインタ経由の関数呼び出し
- 可変長引数
... - 構造体、クラス、継承
- ビットフィールド
- 関数のオーバーロード
- 演算子のオーバーロード
- 配置new、普通のnew
- alignas
- インラインアセンブラ
- 無名関数、クロージャ
- sprintf
- string, vector, map, deque
- テンプレート
基本的には、上記の機能は MikanOS の実装に必要と考えられますので OpeLa 言語に搭載する方針です。一部機能は、バランスを考えて代替の機能とすることもあります。
C++ のテンプレートは複雑な機能なので、ちょっと違う形で実現しようと思っていましたが、考えを改めて実装することにしました。 →OpeLa のジェネリクスに登場する演算子の考察
したがって、これは古い記事です:C++ のテンプレートの使い方と OpeLa での代替手段の検討
MikanOS の実装で使っている C++ の機能の洗い出し結果を踏まえ、Ver.2 の言語仕様をまとめます。 言語仕様は内部設計ではないので OpeLa 言語仕様 で扱います。
Ver.2 はレジスタマシンとして構成するため、どの値をどのレジスタに割り当てるかを決める「レジスタ割り当て」が重要です。 ナイーブなアルゴリズムではすぐにレジスタが足りなくなる可能性があります。 OpeLa Register Assignment で設計します。
整数のキャストとは uint8 や int64 などの整数型の間の型変換のことです。
OpeLa Type Cast で説明します。
構文木のデータ構造 では、OpeLa コンパイラが内部で用いる各種のデータ構造を詳しく説明します。
AST ノードを表す Node や型を表す Type などについて知りたい方はご覧ください。
2021/09/07 時点では、ドット演算子(構造体のフィールドアクセス)に対応するコードは次の通りに生成されます。(x を構造体型の変数、a をフィールド名とする)
-
x.aの左辺xを、lval=true でコード生成する。→レジスタにxのアドレスを設定するコードが生成される。 - フィールド
aのオフセットを計算し、xのアドレスからそのオフセットだけ離れたメモリを読むコードを生成する。
具体的には、x struct{a int; b int;} というローカル変数のフィールド b を読むコードは次のようになります。
lea rdi, [rbp-16]
mov rdi, qword ptr [rdi+8]
1 行目で x のアドレス(ローカル変数なので RBP レジスタが基準となる)を RDI に設定します。2 行目で、RDI を基準としてオフセット 8(b のオフセットに対応)の領域を読みます。
構造体は一般に 8 バイトより大きく、レジスタに格納しきれないのでこのような実装にしています。しかし、左辺を値として扱いたいケースがいくつかあります。
- 構造体が 8 バイトに収まる場合
- 最適化のために、アドレスではなく値をレジスタに格納したい
- 構造体が 16 バイトに収まり、かつ関数の戻り値とする場合
- System V AMD64 ABI では、16 バイトに収まる値を返す際は RDX:RAX に格納することになっている(RAX が下位 8 バイト)
前者は最適化なのでやらなくても動きはしますが、後者は構造体を返す外部の関数を呼び出す際には対応が必須です。以降でその実現方法を検討します。
このケースへの対応は比較的簡単だろうと思います。なぜなら、GenerateAsm は式の評価結果を 1 つのレジスタに格納する、という前提を変えずに済みそうだからです。必要な箇所で構造体のサイズを求め、8 バイト以下ならレジスタにアドレスではなく値を設定する、という条件分岐を書けば実現できる気がします。
このケースはちょっと難しいです。なぜなら、今のところ GenerateAsm は式の値が複数のレジスタにまたがる可能性を全く考慮していないからです。関数の戻り値というのは「関数呼び出し式(kCall)」の値のことですから、れっきとした「式の値」なわけですね。
ぱっと思いつくのは 関数(...).a というように、ドット演算子の左辺が関数呼び出し式のときだけ特別扱いする方法です。関数の戻り値が 16 バイト以下の構造体であり、かつドット演算子を直接適用するときだけ、左辺の値が RDX:RAX に格納されているという前提でコード生成を行います。
構造体を引数に取るような関数を定義したくなったときのことを少し考えてみます。例えば func AddPair(x Pair) int のような関数を定義するとします。Pair は struct {a int64; b int64;} という型です。構造体を戻す関数を func f() Pair とします。AddPair(f()) はどのような機械語にするべきでしょうか?
System V AMD64 ABI(最新版は x86 64 psABI で配布されています)で関数の引数をどのように渡すかを規定しています。仕様が複雑すぎて正確には理解できていませんが、普通の 16 バイト以下の構造体であればレジスタで渡すことができるようです。ということは、AddPair(f()) はまず f() を実行し、RAX→RDI、RDX→RSI にコピーしてから AddPair を呼べば良さそうです。このやり方がすべてのケースで通用する保証はありませんが、uchan が書くようなプログラムのほとんどをカバーできると思います。
System V AMD64 ABI の複雑な仕様を uchan なりに読んだ結果、おそらく 16 バイトを超える構造体はスタック渡しになります。レジスタでは渡せません。このルールは 16 バイト以下の構造体を RDX:RAX で返せる、というルールと整合しています。どういうことかというと、ある関数からレジスタにより返された構造体を他の関数に渡すときは、単にレジスタ間コピーをすれば良い、ということです。レジスタで返されたのにスタックにコピーする場合や、逆にスタックで返されたのにレジスタにコピーする場合を考えなくて良さそうです。
以下は V1 の設計です。V2 ではデータ構造が変わるかもしれません。
直感的に分かるように、具体例により仕様を記述します。
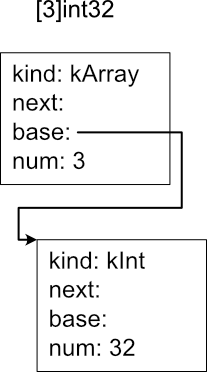
配列型(kind: kArray)は、base に要素の型、num に要素数が設定される。
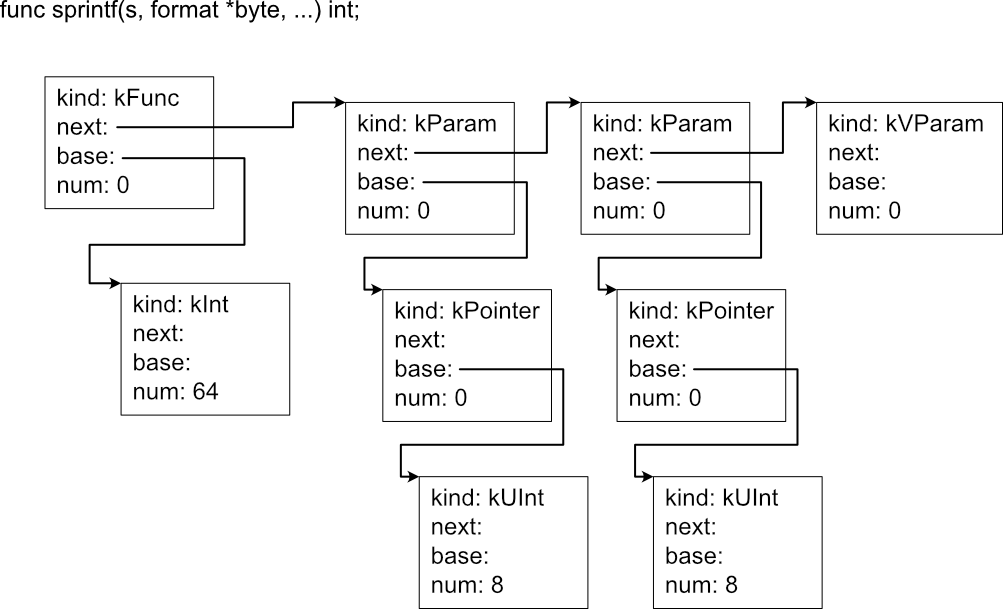
関数型(kind: kFunc)は、next に引数型のリストの先頭要素、base に戻り値型が設定される。 引数型リストの最後には可変長引数を表す kVParam が来得る。
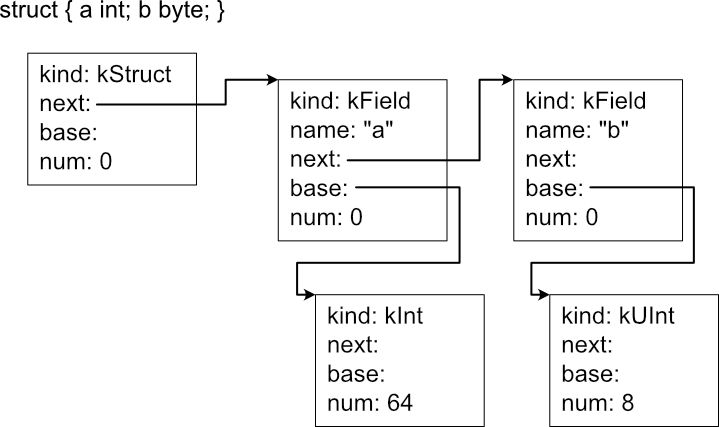
構造体型(kind: kStruct)は、next にフィールド型のリストの先頭要素が設定される。 フィールド型は name にフィールド名が設定される。