Critical clauses are sections of a contract that are of great significance. These clauses if ignored may cause financial/legal damages to the party. Extracting these clauses in an agreement will protect your business from miscommunication and lawsuits, providing legal safeguards that your business may not otherwise receive.
We are going to be reading a contract and extracting the critical clauses from the contract thereby safeguarding the party from potential financial/legal ruin. This can be achieved as follows :
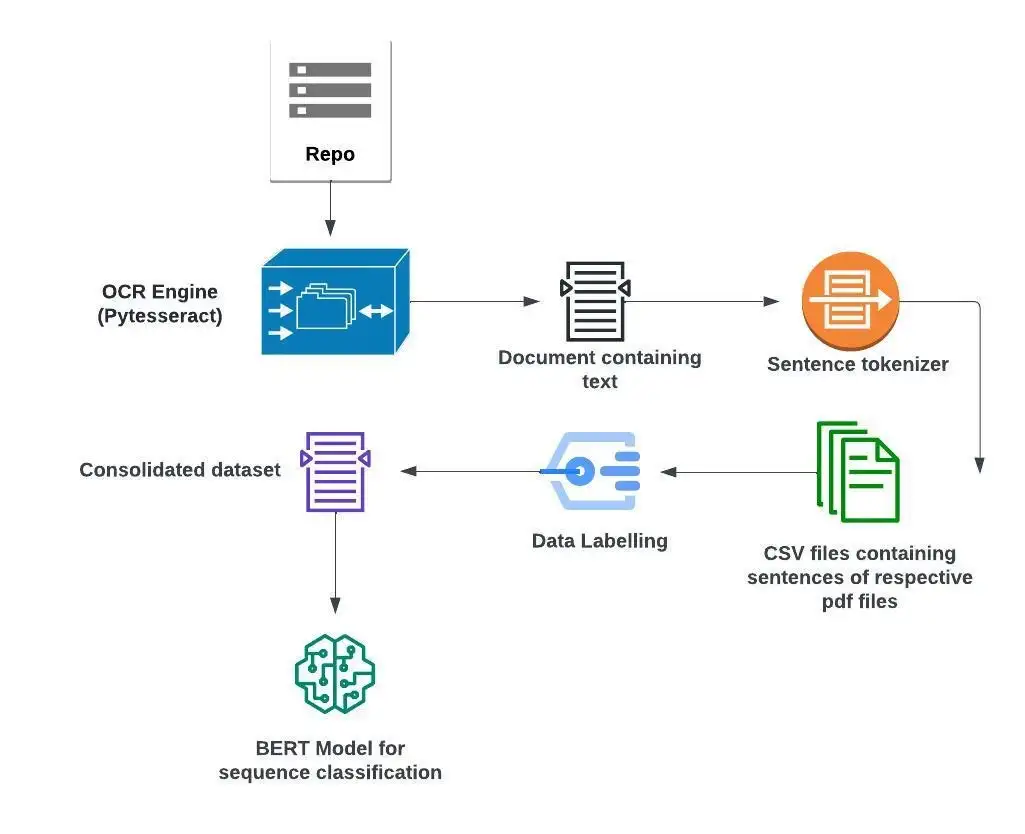
Pytesseract or Python-tesseract is an OCR tool for python that also serves as a wrapper for the Tesseract-OCR Engine. It can read and recognize text embedded in images.
We use Pytesseract as our OCR engine to read the contents of the PDF file.
The PDF files are taken from the repository and passed through the OCR engine. The OCR engine first converts the given PDF files into images using the convert_from_path() function of Pytesseract.
images = convert_from_path(path, 500, poppler_path= r'C:\\Program Files\\poppler-0.68.0\\bin')
These images of each page of the PDF file are then converted to text using the image_to_string() function.
def convert_img_to_text(file):
text = image_to_string(file)
return text
The text is then stored in a string that contains the entire text of the PDF file. The text from the PDF file is then split into sentences using the split() function. We obtain a list of all the sentences in the file.
sentence = re.split("\\. |\\.\n|\\.\n\n|\\:\n|\\: \n|\\:\n\n",text_from_pytesseract)
These sentences are filtered removing the unnecessary parts of the PDF file. The sentences are then finally written into a CSV file. We get a CSV file containing all the clauses of the contract.
The CSV files from all the contracts are then combined into one CSV file. This file consists of sentences(clauses) from all the contracts. This file is further filtered and we then proceed to the classification process. The various clauses are manually classified as critical or non-critical depending on their contents. Since the number of critical clauses is much less compared to the number of non-critical clauses in contracts, naturally there is an imbalance in the dataset. This problem is solved by adding several critical clauses from various legal contracts available on Kaggle.

Total number of clauses in dataset: 1216
Critical Clauses: 644
Non-critical Clauses: 572
The CSV file is then read and stored as a data frame using pandas. All the critical clauses are mapped as 1 and the non-critical clauses are mapped as 0.
BERT is a powerful Transformer-based machine learning model. BERT is a very good pre-trained language model and has been wildly successful on a variety of tasks in NLP (natural language processing).
We are going to be using BERT for binary text classification. We will be able to classify the various clauses of the contract as critical and non-critical respectively.
We use small_bert/bert_en_uncased_L-4_H-256_A-4 model for our binary text classification problem. It implements the encoder API for text embeddings with transformer encoders. We use the bert_en_uncased_preprocess Saved Model to preprocess plain text inputs into the input format expected by BERT. This model uses a vocabulary for English extracted from the Wikipedia and BooksCorpus (same as in the models by the original BERT authors). Text inputs are normalized the “uncased” way, meaning that the text has been lower-cased before tokenization into word pieces, and any accent markers are stripped.
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string)
preprocessor = hub.KerasLayer(path_uncased_preprocess)
encoder_inputs = preprocessor(text_input)
encoder = hub.KerasLayer(path_bertmodel, trainable=True)
outputs = encoder(encoder_inputs)
We have two layers of neural networks in our model. The Dropout layer is used to ignore 10% of the neurons. The Dense layer acts as the classifier in the model. The sigmoid function is used as an activation function as we require a value between 0 and 1.
l = tf.keras.layers.Dropout(0.1, name="dropout")(outputs['pooled_output'])
l = tf.keras.layers.Dense(1, activation='sigmoid', name="output")(l)
model = tf.keras.Model(inputs=[text_input], outputs = [l])
METRICS = [ tf.keras.metrics.BinaryAccuracy(name='accuracy'), tf.keras.metrics.Precision(name='precision'), tf.keras.metrics.Recall(name='recall')]
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=METRICS)
The model is then created and trained using the training data of the dataset. First we take 75% of the dataset as training data which is fit into the model as follows:
model.fit(X_train, y_train, epochs=5)
The training data is passed forward and backward through the neural network 5 times.
Once the model is trained we evaluate the results on the remaining 25% of the dataset kept for testing. When 75% of the dataset is used as training data the accuracy metrics on the remaining 25% test data are as follows:
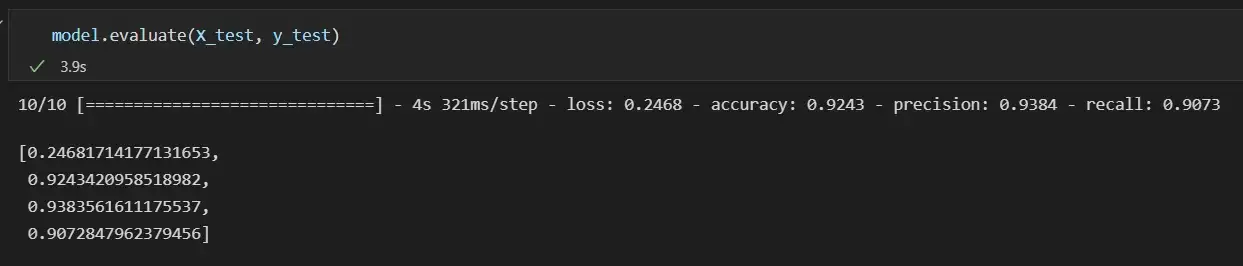
Despite the lack of data in the dataset, this model performs fairly accurately on unseen test data. This model can be further improved by enhancing the dataset with more clauses from legal contracts.