An efficient audio-visual bimodal recognition system which uses Deep Convolution Neural Networks (CNNs) as a primary model architecture. First, two separate Deep CNN models are trained with the help of audio and facial features, respectively. The outputs of these CNN models are then combined/fused to predict the identity of the subject.
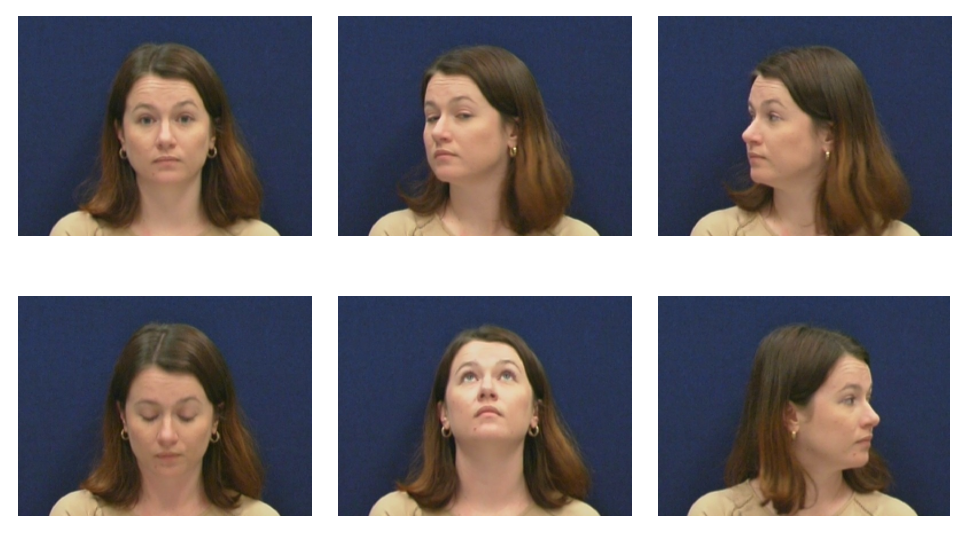
We normalized the images by dividing it with 255. The initial size of an image was 512 × 384, so we converted that to 224 × 224 pixels and kept RGB channel. The figure shows the sample images of VidTIMIT dataset.
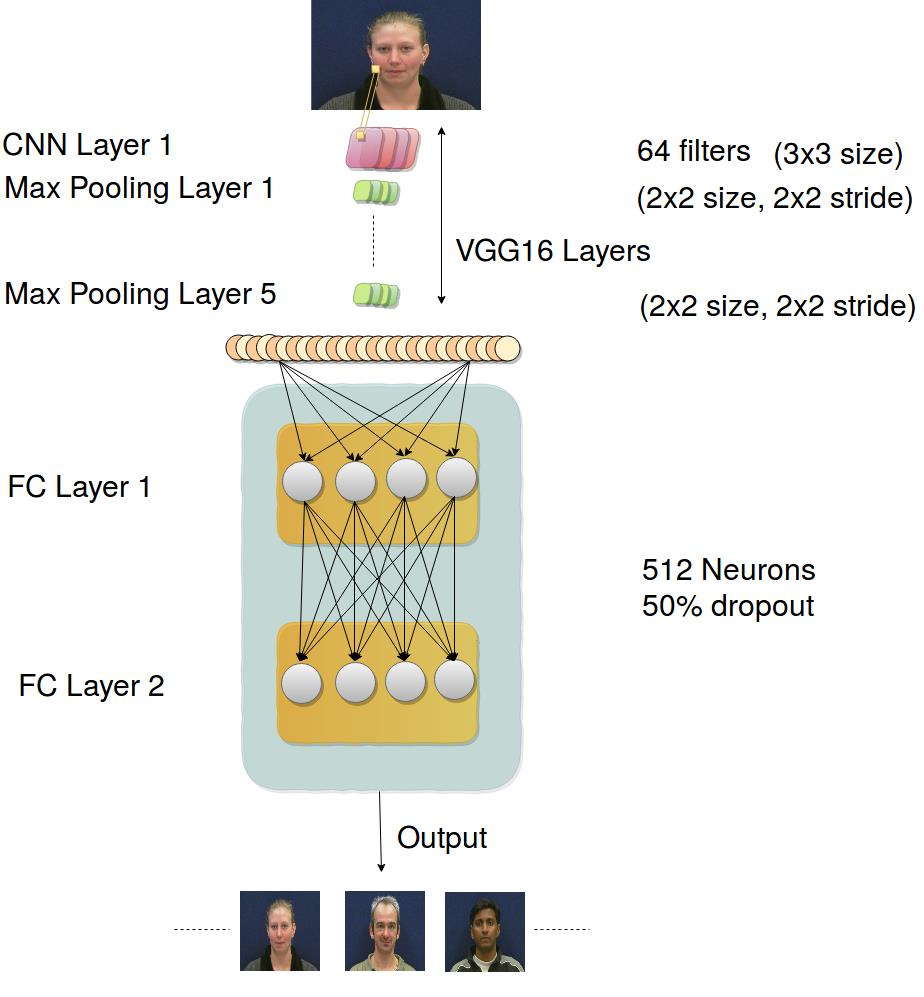
We passed these images to a CNN for feature extraction and then to fully connected hidden layers which gave the probabilities of each class as the output. We used VGG16 model with weights pre-trained on ImageNet. We extracted features of the images from the top 18 VGG16 layers and then passed that to the two dense layers and one output layer to compute the probabilities of each class. The below figure shows an overview of our model. We kept the same parameters for the first 18 layers of VGG16 architecture and for the rest of the layers. We kept 512 filters with 50% probability dropout for the next two fully connected hidden layers with relu activation function. We kept learning rate 0.0005 with 0.9 momentum, 1e-6 decay and used SGD optimizer.
Will add the person recognition using audio signals and the fusion of both of these models soon!!