By Samuel Stevens, S M Rayeed, and Jenna Kline.
Code to reproduce our findings in Mind the Gap: Evaluating Vision Systems in Small Data Applications.
We looked a lot of recent AI methods papers (DINOv2, Gemini Flash 1.5, Claude Sonnet 3.7, V-JEPA, etc) and measured how many training samples were used in each reported evaluation task. We found that no papers use any tasks between 100 and 1K training samples.
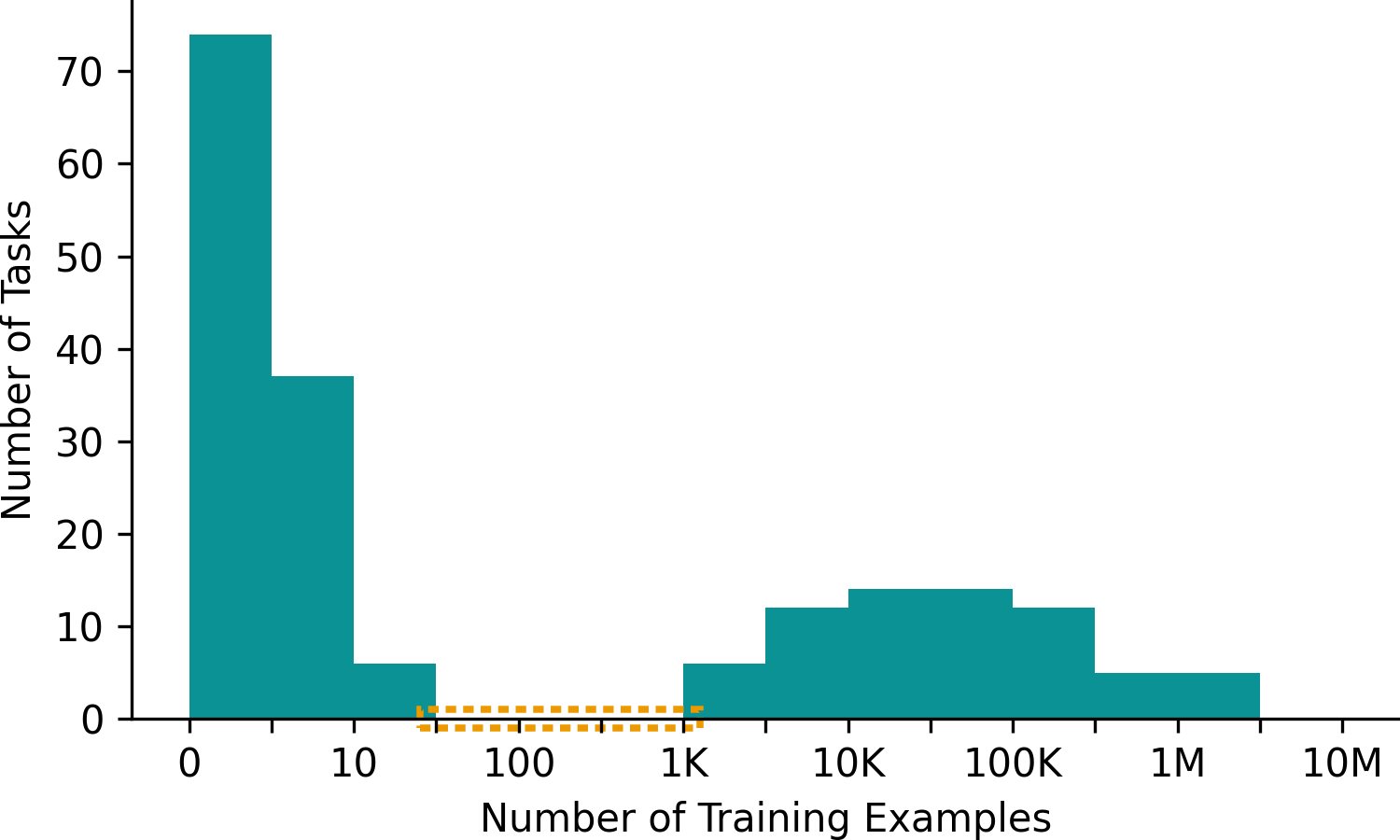 |
|---|
| Image Credit: arxiv.org/pdf/2504.06486 |
We decided to use NeWT to evaluate recent AI methods in this regime of 100-1K training samples and reported our findings.
If you want our raw data, you can download it: data/results.sqlite.gz (96 MB) and data/existing-work.csv (5 KB).
Unzip the sqlite3 file and move it to results/, then run the below scripts.
To reproduce our work, follow the instructions below:
With uv
uv run benchmark.py --helpThis will run the benchmark script, which will force a .venv to be created.
Set the $NFS and $USER variables or edit the configs in configs/*.toml to point towards your NeWt data.
You can download the data using:
uv run mindthegap/download.py --helpThen run
uv run benchmark.py --cfg configs/mllms.tomlThis will create the results database and check if you have any results (you probably don't). It will report what jobs it has to run.
To actually run the jobs, use:
uv run benchmark.py --cfg configs/mllms.toml --no-dry-runTo recreate our figures, run the notebookes/figures.py notebook with marimo.