العربية • বাংলা • Deutsch • English • Español • فارسی • Français • हिन्दी • Bahasa Indonesia • Italiano • 日本語 • 한국어 • Polski • Português • Română • Русский • Slovenščina • ไทย • Türkçe • Українська • Tiếng Việt • 简体中文 • 繁體中文


Apache Doris एक उपयोग में आसान, उच्च-प्रदर्शन और वास्तविक-समय विश्लेषणात्मक डेटाबेस है जो MPP आर्किटेक्चर पर आधारित है, जो अपनी चरम गति और उपयोग में आसानी के लिए जाना जाता है। इसे बड़े पैमाने पर डेटा के तहत क्वेरी परिणाम लौटाने के लिए केवल एक सेकंड से कम प्रतिक्रिया समय की आवश्यकता होती है और यह न केवल उच्च-समवर्ती बिंदु क्वेरी परिदृश्यों का समर्थन कर सकता है बल्कि उच्च-थ्रूपुट जटिल विश्लेषण परिदृश्यों का भी समर्थन कर सकता है।
यह सब Apache Doris को रिपोर्ट विश्लेषण, ad-hoc क्वेरी, एकीकृत डेटा वेयरहाउस, और डेटा लेक क्वेरी त्वरण सहित परिदृश्यों के लिए एक आदर्श उपकरण बनाता है। Apache Doris पर, उपयोगकर्ता विभिन्न अनुप्रयोग बना सकते हैं, जैसे कि उपयोगकर्ता व्यवहार विश्लेषण, AB परीक्षण प्लेटफॉर्म, लॉग पुनर्प्राप्ति विश्लेषण, उपयोगकर्ता प्रोफ़ाइल विश्लेषण, और ऑर्डर विश्लेषण।
🎉 🔗सभी रिलीज़ देखें, जहाँ आपको पिछले वर्ष में जारी किए गए Apache Doris संस्करणों का कालानुक्रमिक सारांश मिलेगा।
👀 Apache Doris की मुख्य विशेषताओं, ब्लॉगों और उपयोगकर्ता मामलों को विस्तार से खोजने के लिए 🔗आधिकारिक वेबसाइट का अन्वेषण करें।
नीचे दिए गए चित्र में दिखाए गए अनुसार, विभिन्न डेटा एकीकरण और प्रसंस्करण के बाद, डेटा स्रोत आमतौर पर वास्तविक-समय डेटा वेयरहाउस Apache Doris और ऑफ़लाइन डेटा लेक या डेटा वेयरहाउस (Apache Hive, Apache Iceberg या Apache Hudi में) में संग्रहीत होते हैं।
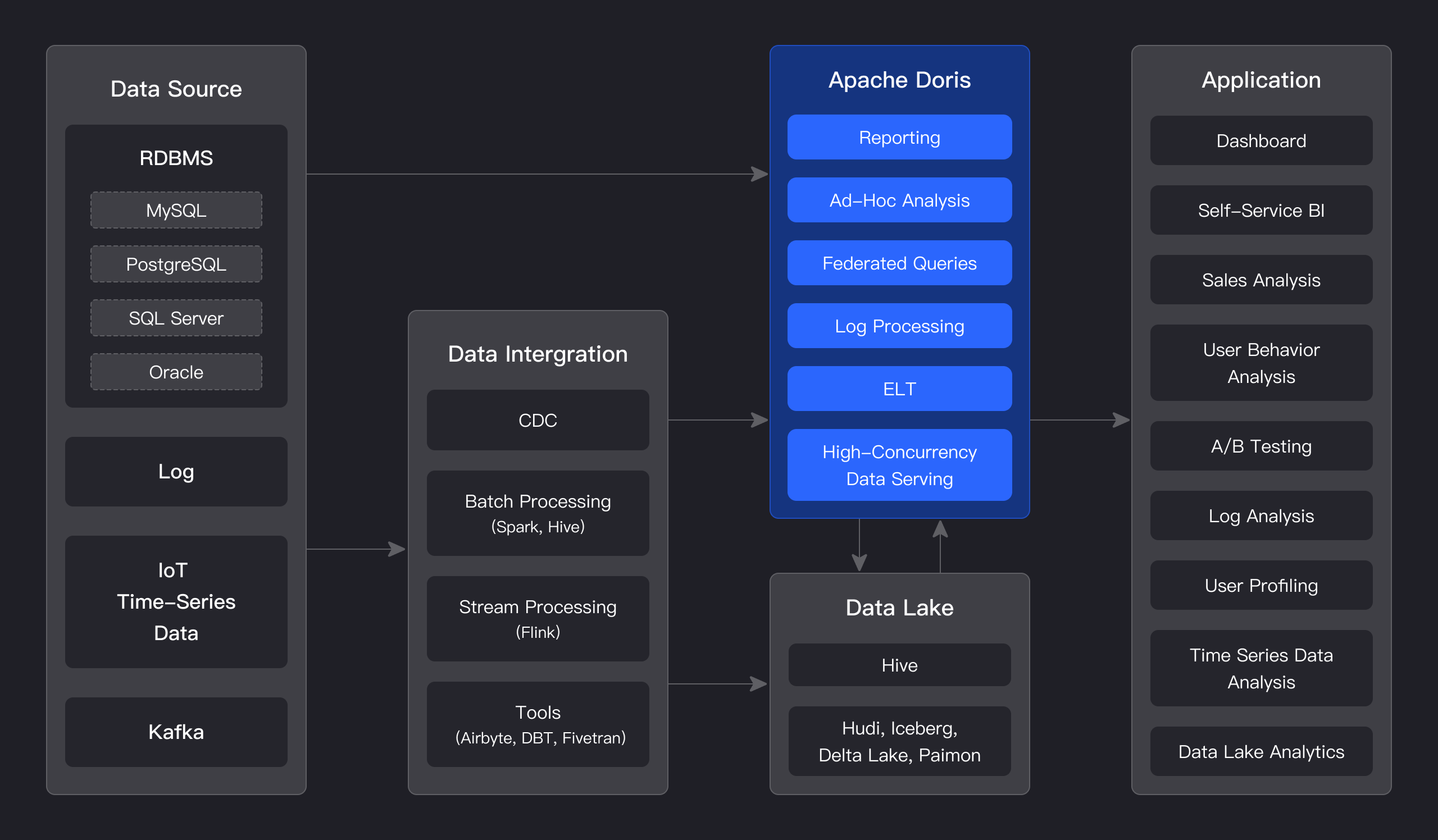
Apache Doris का व्यापक रूप से निम्नलिखित परिदृश्यों में उपयोग किया जाता है:
-
वास्तविक-समय डेटा विश्लेषण:
-
वास्तविक-समय रिपोर्टिंग और निर्णय लेना: Doris आंतरिक और बाहरी उद्यम उपयोग दोनों के लिए वास्तविक-समय अद्यतन रिपोर्ट और डैशबोर्ड प्रदान करता है, स्वचालित प्रक्रियाओं में वास्तविक-समय निर्णय लेने का समर्थन करता है।
-
Ad Hoc विश्लेषण: Doris बहुआयामी डेटा विश्लेषण क्षमताएं प्रदान करता है, जटिल डेटा से जल्दी से अंतर्दृष्टि खोजने में मदद करने के लिए त्वरित बिज़नेस इंटेलिजेंस विश्लेषण और ad hoc क्वेरी सक्षम करता है।
-
उपयोगकर्ता प्रोफाइलिंग और व्यवहार विश्लेषण: Doris भागीदारी, प्रतिधारण और रूपांतरण जैसे उपयोगकर्ता व्यवहारों का विश्लेषण कर सकता है, जबकि व्यवहार विश्लेषण के लिए जनसंख्या अंतर्दृष्टि और भीड़ चयन जैसे परिदृश्यों का भी समर्थन करता है।
-
-
लेकहाउस एनालिटिक्स:
-
लेकहाउस क्वेरी त्वरण: Doris अपने कुशल क्वेरी इंजन के साथ लेकहाउस डेटा क्वेरी को तेज करता है।
-
संघीय एनालिटिक्स: Doris कई डेटा स्रोतों में संघीय क्वेरी का समर्थन करता है, आर्किटेक्चर को सरल बनाता है और डेटा साइलो को समाप्त करता है。
-
वास्तविक-समय डेटा प्रसंस्करण: Doris उच्च समवर्तनता और कम विलंबता जटिल व्यावसायिक आवश्यकताओं की आवश्यकताओं को पूरा करने के लिए वास्तविक-समय डेटा स्ट्रीम और बैच डेटा प्रसंस्करण क्षमताओं को जोड़ता है।
-
-
SQL-आधारित अवलोकनशीलता:
- लॉग और इवेंट विश्लेषण: Doris वितरित सिस्टम में लॉग और इवेंट के वास्तविक-समय या बैच विश्लेषण को सक्षम करता है, समस्याओं की पहचान करने और प्रदर्शन को अनुकूलित करने में मदद करता है।
Apache Doris MySQL प्रोटोकॉल का उपयोग करता है, MySQL सिंटैक्स के साथ अत्यधिक संगत है, और मानक SQL का समर्थन करता है। उपयोगकर्ता विभिन्न क्लाइंट उपकरणों के माध्यम से Apache Doris तक पहुंच सकते हैं, और यह BI उपकरणों के साथ निर्बाध रूप से एकीकृत होता है।
Apache Doris का स्टोरेज-कम्प्यूट एकीकृत आर्किटेक्चर सुव्यवस्थित और बनाए रखने में आसान है। जैसा कि नीचे दिए गए चित्र में दिखाया गया है, इसमें केवल दो प्रकार की प्रक्रियाएं शामिल हैं:
-
Frontend (FE): मुख्य रूप से उपयोगकर्ता अनुरोधों को संभालने, क्वेरी पार्सिंग और योजना, मेटाडेटा प्रबंधन, और नोड प्रबंधन कार्यों के लिए जिम्मेदार।
-
Backend (BE): मुख्य रूप से डेटा स्टोरेज और क्वेरी निष्पादन के लिए जिम्मेदार। डेटा को शार्ड में विभाजित किया जाता है और BE नोड्स में कई प्रतियों के साथ संग्रहीत किया जाता है।
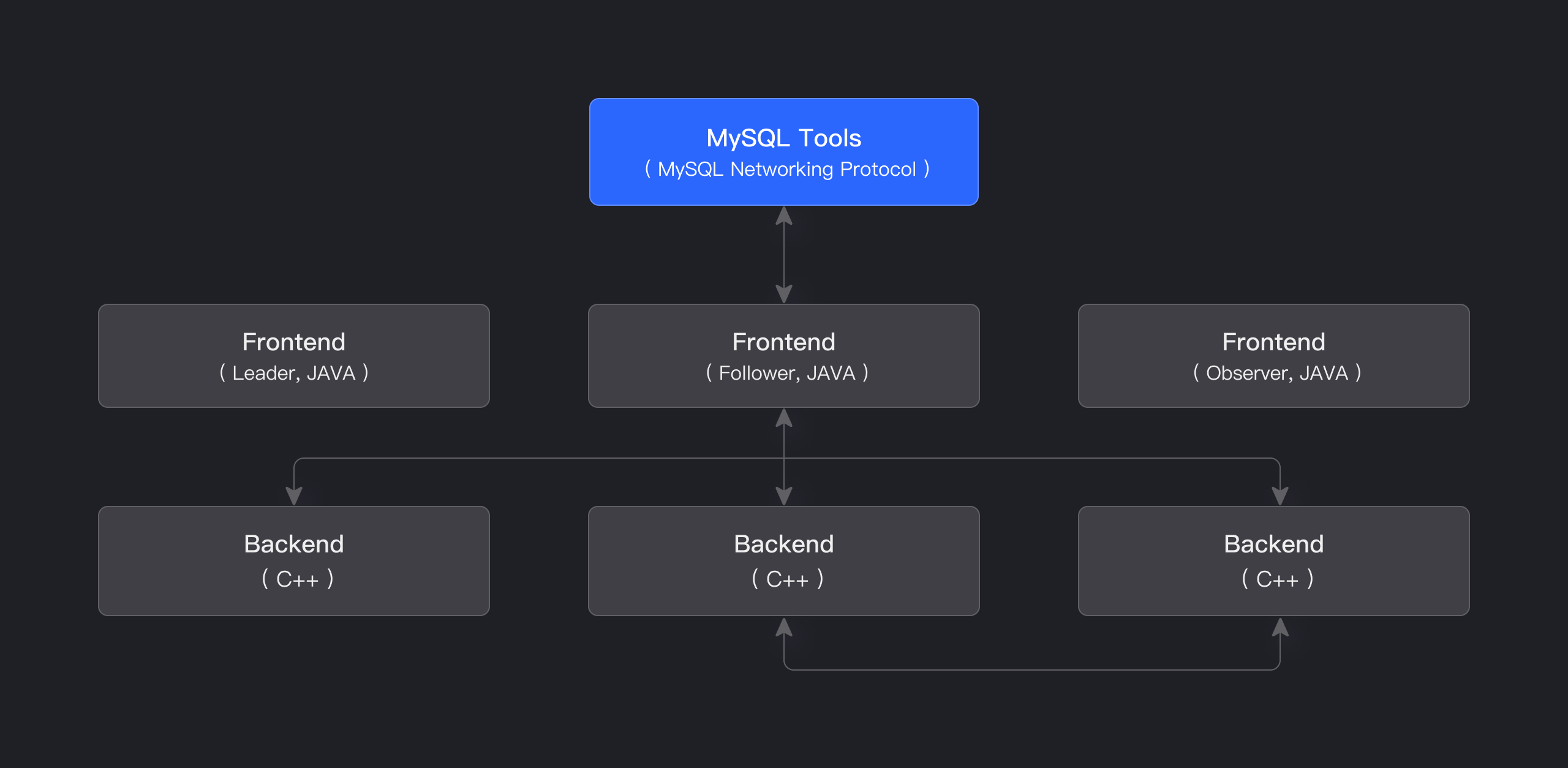
एक उत्पादन वातावरण में, आपदा वसूली के लिए कई FE नोड्स तैनात किए जा सकते हैं। प्रत्येक FE नोड मेटाडेटा की एक पूर्ण प्रति बनाए रखता है। FE नोड्स को तीन भूमिकाओं में विभाजित किया गया है:
| भूमिका | कार्य |
|---|---|
| Master | FE Master नोड मेटाडेटा पढ़ने और लिखने के संचालन के लिए जिम्मेदार है। जब Master में मेटाडेटा परिवर्तन होते हैं, तो वे BDB JE प्रोटोकॉल के माध्यम से Follower या Observer नोड्स को सिंक्रनाइज़ किए जाते हैं। |
| Follower | Follower नोड मेटाडेटा पढ़ने के लिए जिम्मेदार है। यदि Master नोड विफल हो जाता है, तो एक Follower नोड को नए Master के रूप में चुना जा सकता है। |
| Observer | Observer नोड मेटाडेटा पढ़ने के लिए जिम्मेदार है और मुख्य रूप से क्वेरी समवर्तनता बढ़ाने के लिए उपयोग किया जाता है। यह क्लस्टर नेतृत्व चुनावों में भाग नहीं लेता है। |
FE और BE दोनों प्रक्रियाएं क्षैतिज रूप से स्केलेबल हैं, जिससे एक एकल क्लस्टर सैकड़ों मशीनों और दसियों पेटाबाइट्स स्टोरेज क्षमता का समर्थन कर सकता है। FE और BE प्रक्रियाएं सेवाओं की उच्च उपलब्धता और डेटा की उच्च विश्वसनीयता सुनिश्चित करने के लिए एक स्थिरता प्रोटोकॉल का उपयोग करती हैं। स्टोरेज-कम्प्यूट एकीकृत आर्किटेक्चर अत्यधिक एकीकृत है, वितरित सिस्टम की परिचालन जटिलता को काफी कम करता है।
-
उच्च उपलब्धता: Apache Doris में, मेटाडेटा और डेटा दोनों कई प्रतियों के साथ संग्रहीत होते हैं, quorum प्रोटोकॉल के माध्यम से डेटा लॉग सिंक्रनाइज़ करते हैं। डेटा लेखन तब सफल माना जाता है जब अधिकांश प्रतियां लेखन पूरा कर लेती हैं, यह सुनिश्चित करते हुए कि कुछ नोड्स विफल होने पर भी क्लस्टर उपलब्ध रहता है। Apache Doris समान-शहर और क्रॉस-क्षेत्र आपदा वसूली दोनों का समर्थन करता है, दोहरे-क्लस्टर मास्टर-स्लेव मोड सक्षम करता है। जब कुछ नोड्स विफलताओं का अनुभव करते हैं, तो क्लस्टर स्वचालित रूप से दोषपूर्ण नोड्स को अलग कर सकता है, समग्र क्लस्टर उपलब्धता को प्रभावित होने से रोकता है।
-
उच्च संगतता: Apache Doris MySQL प्रोटोकॉल के साथ अत्यधिक संगत है और मानक SQL सिंटैक्स का समर्थन करता है, अधिकांश MySQL और Hive फ़ंक्शन को कवर करता है। यह उच्च संगतता उपयोगकर्ताओं को मौजूदा अनुप्रयोगों और उपकरणों को निर्बाध रूप से माइग्रेट और एकीकृत करने की अनुमति देती है। Apache Doris MySQL इकोसिस्टम का समर्थन करता है, उपयोगकर्ताओं को अधिक सुविधाजनक संचालन और रखरखाव के लिए MySQL क्लाइंट उपकरणों का उपयोग करके Doris से कनेक्ट करने में सक्षम बनाता है। यह BI रिपोर्टिंग उपकरणों और डेटा ट्रांसमिशन उपकरणों के लिए MySQL प्रोटोकॉल संगतता का भी समर्थन करता है, डेटा विश्लेषण और डेटा ट्रांसमिशन प्रक्रियाओं में दक्षता और स्थिरता सुनिश्चित करता है।
-
वास्तविक-समय डेटा वेयरहाउस: Apache Doris के आधार पर, एक वास्तविक-समय डेटा वेयरहाउस सेवा बनाई जा सकती है। Apache Doris सेकंड-स्तरीय डेटा अंतर्ग्रहण क्षमताएं प्रदान करता है, सेकंडों के भीतर अपस्ट्रीम ऑनलाइन लेनदेन डेटाबेस से वृद्धिशील परिवर्तनों को Doris में कैप्चर करता है। वेक्टराइज्ड इंजन, MPP आर्किटेक्चर, और Pipeline निष्पादन इंजन का लाभ उठाकर, Doris सब-सेकंड डेटा क्वेरी क्षमताएं प्रदान करता है, जिससे एक उच्च-प्रदर्शन, कम-विलंबता वास्तविक-समय डेटा वेयरहाउस प्लेटफॉर्म का निर्माण होता है।
-
एकीकृत लेकहाउस: Apache Doris डेटा लेक या रिलेशनल डेटाबेस जैसे बाहरी डेटा स्रोतों के आधार पर एक एकीकृत लेकहाउस आर्किटेक्चर बना सकता है। Doris एकीकृत लेकहाउस समाधान डेटा लेक और डेटा वेयरहाउस के बीच निर्बाध एकीकरण और मुक्त डेटा प्रवाह सक्षम करता है, उपयोगकर्ताओं को डेटा लेक में डेटा विश्लेषण समस्याओं को हल करने के लिए डेटा वेयरहाउस क्षमताओं का सीधे उपयोग करने में मदद करता है, जबकि डेटा मूल्य बढ़ाने के लिए डेटा लेक डेटा प्रबंधन क्षमताओं का पूरी तरह से लाभ उठाता है।
-
लचीला मॉडलिंग: Apache Doris विभिन्न मॉडलिंग दृष्टिकोण प्रदान करता है, जैसे कि व्यापक तालिका मॉडल, पूर्व-एग्रीगेशन मॉडल, स्टार/स्नोफ्लेक स्कीमा, आदि। डेटा आयात के दौरान, डेटा को व्यापक तालिकाओं में समतल किया जा सकता है और Flink या Spark जैसे कम्प्यूट इंजन के माध्यम से Doris में लिखा जा सकता है, या डेटा को सीधे Doris में आयात किया जा सकता है, दृश्यों, मटेरियलाइज़्ड दृश्यों, या वास्तविक-समय बहु-तालिका जोड़ों के माध्यम से डेटा मॉडलिंग संचालन करता है।
Doris एक कुशल SQL इंटरफ़ेस प्रदान करता है और MySQL प्रोटोकॉल के साथ पूरी तरह से संगत है। इसका क्वेरी इंजन MPP (मासिवली पैरेलल प्रोसेसिंग) आर्किटेक्चर पर आधारित है, जटिल विश्लेषणात्मक क्वेरी को कुशलता से निष्पादित करने और कम-विलंबता वास्तविक-समय क्वेरी प्राप्त करने में सक्षम है। डेटा एन्कोडिंग और संपीड़न के लिए कॉलम स्टोरेज तकनीक के माध्यम से, यह क्वेरी प्रदर्शन और स्टोरेज संपीड़न अनुपात को काफी हद तक अनुकूलित करता है।
Apache Doris MySQL प्रोटोकॉल को अपनाता है, मानक SQL का समर्थन करता है, और MySQL सिंटैक्स के साथ अत्यधिक संगत है। उपयोगकर्ता विभिन्न क्लाइंट उपकरणों के माध्यम से Apache Doris तक पहुंच सकते हैं और इसे BI उपकरणों के साथ निर्बाध रूप से एकीकृत कर सकते हैं, जिसमें लेकिन Smartbi, DataEase, FineBI, Tableau, Power BI, और Apache Superset तक सीमित नहीं है। Apache Doris MySQL प्रोटोकॉल का समर्थन करने वाले किसी भी BI उपकरण के लिए डेटा स्रोत के रूप में काम कर सकता है।
Apache Doris में एक कॉलम स्टोरेज इंजन है, जो कॉलम द्वारा डेटा को एन्कोड, कंप्रेस और पढ़ता है। यह बहुत उच्च डेटा संपीड़न अनुपात सक्षम करता है और अनावश्यक डेटा स्कैनिंग को काफी कम करता है, इस प्रकार IO और CPU संसाधनों का अधिक कुशल उपयोग करता है।
Apache Doris डेटा स्कैन को कम करने के लिए विभिन्न इंडेक्स संरचनाओं का समर्थन करता है:
-
सॉर्टेड कंपाउंड की इंडेक्स: उपयोगकर्ता अधिकतम तीन कॉलम निर्दिष्ट कर सकते हैं ताकि एक कंपाउंड सॉर्ट की बना सकें। यह उच्च-समवर्ती रिपोर्टिंग परिदृश्यों का बेहतर समर्थन करने के लिए डेटा को प्रभावी ढंग से प्रून कर सकता है।
-
Min/Max इंडेक्स: यह संख्यात्मक प्रकारों की समानता और रेंज क्वेरी में प्रभावी डेटा फ़िल्टरिंग सक्षम करता है।
-
BloomFilter इंडेक्स: यह उच्च-कार्डिनैलिटी कॉलम की समानता फ़िल्टरिंग और प्रूनिंग में बहुत प्रभावी है।
-
इनवर्टेड इंडेक्स: यह किसी भी फ़ील्ड के लिए त्वरित खोज सक्षम करता है।
Apache Doris विभिन्न डेटा मॉडल का समर्थन करता है और उन्हें विभिन्न परिदृश्यों के लिए अनुकूलित किया है:
-
विवरण मॉडल (डुप्लिकेट की मॉडल): तथ्य तालिकाओं की विस्तृत स्टोरेज आवश्यकताओं को पूरा करने के लिए डिज़ाइन किया गया एक विवरण डेटा मॉडल।
-
प्राथमिक की मॉडल (अद्वितीय की मॉडल): अद्वितीय कुंजी सुनिश्चित करता है; समान कुंजी वाले डेटा को अधिलेखित किया जाता है, पंक्ति-स्तरीय डेटा अपडेट सक्षम करता है।
-
एग्रीगेट मॉडल (एग्रीगेट की मॉडल): समान कुंजी वाले मान कॉलम को मर्ज करता है, पूर्व-एग्रीगेशन के माध्यम से प्रदर्शन में काफी सुधार करता है।
Apache Doris मजबूत सुसंगत एकल-तालिका मटेरियलाइज़्ड दृश्यों और अतुल्यकालिक रूप से रिफ्रेश किए गए बहु-तालिका मटेरियलाइज़्ड दृश्यों का भी समर्थन करता है। एकल-तालिका मटेरियलाइज़्ड दृश्य स्वचालित रूप से सिस्टम द्वारा रिफ्रेश और बनाए रखे जाते हैं, उपयोगकर्ताओं से मैनुअल हस्तक्षेप की आवश्यकता नहीं होती है। बहु-तालिका मटेरियलाइज़्ड दृश्यों को क्लस्टर-इन-शेड्यूलिंग या बाहरी शेड्यूलिंग उपकरणों का उपयोग करके समय-समय पर रिफ्रेश किया जा सकता है, डेटा मॉडलिंग की जटिलता को कम करता है।
Apache Doris में नोड्स के बीच और नोड्स के भीतर समानांतर निष्पादन के लिए MPP-आधारित क्वेरी इंजन है। यह जटिल क्वेरी को बेहतर ढंग से संभालने के लिए बड़ी तालिकाओं के लिए वितरित shuffle join का समर्थन करता है।
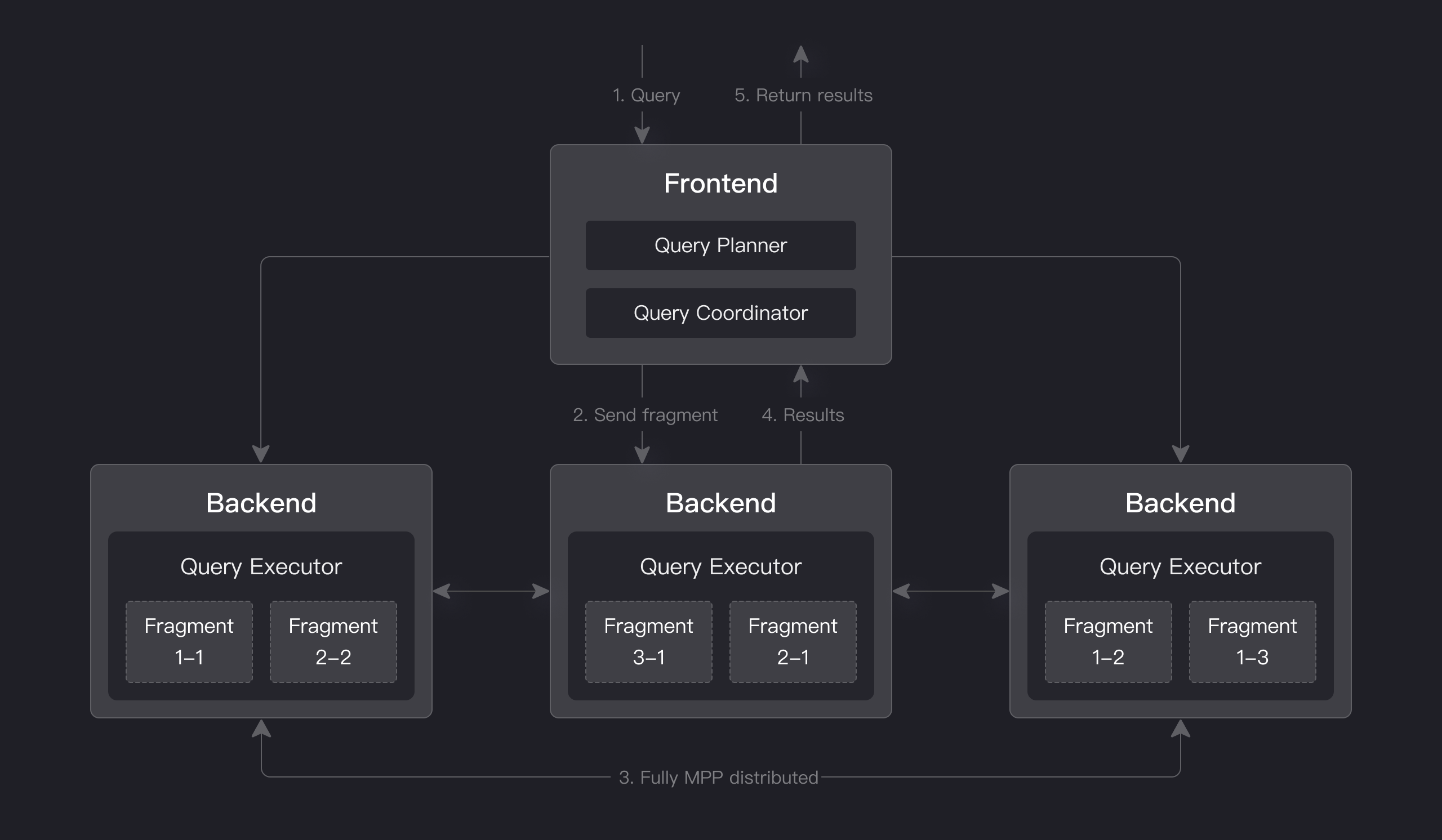
Apache Doris का क्वेरी इंजन पूरी तरह से वेक्टराइज्ड है, सभी मेमोरी संरचनाएं कॉलम प्रारूप में व्यवस्थित हैं। यह वर्चुअल फ़ंक्शन कॉल को काफी कम कर सकता है, कैश हिट दरों को बढ़ा सकता है, और SIMD निर्देशों का कुशल उपयोग कर सकता है। Apache Doris व्यापक तालिका एग्रीगेशन परिदृश्यों में गैर-वेक्टराइज्ड इंजन की तुलना में 5-10 गुना अधिक प्रदर्शन प्रदान करता है।

Apache Doris रनटाइम सांख्यिकी के आधार पर निष्पादन योजना को गतिशील रूप से समायोजित करने के लिए अनुकूली क्वेरी निष्पादन तकनीक का उपयोग करता है। उदाहरण के लिए, यह एक रनटाइम फ़िल्टर उत्पन्न कर सकता है और इसे प्रोब साइड पर पुश कर सकता है। विशेष रूप से, यह फ़िल्टर को प्रोब साइड पर सबसे निचले स्तर के स्कैन नोड पर पुश करता है, जो प्रसंस्करण के लिए डेटा की मात्रा को काफी कम करता है और join प्रदर्शन को बढ़ाता है। Apache Doris का रनटाइम फ़िल्टर In/Min/Max/Bloom Filter का समर्थन करता है।
Apache Doris एक Pipeline निष्पादन इंजन का उपयोग करता है जो क्वेरी को समानांतर निष्पादन के लिए कई उप-कार्यों में तोड़ता है, मल्टी-कोर CPU क्षमताओं का पूरी तरह से लाभ उठाता है। यह एक साथ क्वेरी थ्रेड्स की संख्या को सीमित करके थ्रेड विस्फोट समस्या को संबोधित करता है। Pipeline निष्पादन इंजन डेटा कॉपीिंग और शेयरिंग को कम करता है, सॉर्टिंग और एग्रीगेशन ऑपरेशन को अनुकूलित करता है, जिससे क्वेरी दक्षता और थ्रूपुट में काफी सुधार होता है।
ऑप्टिमाइज़र के संदर्भ में, Apache Doris CBO (कॉस्ट-बेस्ड ऑप्टिमाइज़र), RBO (रूल-बेस्ड ऑप्टिमाइज़र), और HBO (हिस्ट्री-बेस्ड ऑप्टिमाइज़र) की संयुक्त अनुकूलन रणनीति को नियोजित करता है। RBO निरंतर फोल्डिंग, सबक्वेरी रीराइटिंग, प्रेडिकेट पुशडाउन, और अधिक का समर्थन करता है। CBO join रीऑर्डरिंग और अन्य अनुकूलन का समर्थन करता है। HBO ऐतिहासिक क्वेरी जानकारी के आधार पर इष्टतम निष्पादन योजना की सिफारिश करता है। ये कई अनुकूलन उपाय सुनिश्चित करते हैं कि Doris विभिन्न प्रकार की क्वेरी के लिए उच्च-प्रदर्शन क्वेरी योजनाओं को गिन सकता है।
-
🎯 उपयोग में आसान: दो प्रक्रियाएं, कोई अन्य निर्भरता नहीं; ऑनलाइन क्लस्टर स्केलिंग, स्वचालित प्रतिकृति वसूली; MySQL प्रोटोकॉल के साथ संगत, और मानक SQL का उपयोग करता है।
-
🚀 उच्च प्रदर्शन: कॉलम स्टोरेज इंजन, आधुनिक MPP आर्किटेक्चर, वेक्टराइज्ड क्वेरी इंजन, पूर्व-एग्रीगेटेड मटेरियलाइज़्ड दृश्य और डेटा इंडेक्स के साथ कम-विलंबता और उच्च-थ्रूपुट क्वेरी के लिए अत्यंत तेज़ प्रदर्शन।
-
🖥️ एकल एकीकृत: एक एकल सिस्टम वास्तविक-समय डेटा सेवा, इंटरैक्टिव डेटा विश्लेषण और ऑफ़लाइन डेटा प्रसंस्करण परिदृश्यों का समर्थन कर सकता है।
-
⚛️ संघीय क्वेरी: Hive, Iceberg, Hudi जैसे डेटा लेक और MySQL और Elasticsearch जैसे डेटाबेस की संघीय क्वेरी का समर्थन करता है।
-
⏩ विभिन्न डेटा आयात विधियां: HDFS/S3 से बैच आयात और MySQL Binlog/Kafka से स्ट्रीम आयात का समर्थन करता है; HTTP इंटरफ़ेस के माध्यम से माइक्रो-बैच लेखन और JDBC में Insert का उपयोग करके वास्तविक-समय लेखन का समर्थन करता है।
-
🚙 समृद्ध पारिस्थितिकी: Spark Doris को पढ़ने और लिखने के लिए Spark-Doris-Connector का उपयोग करता है; Flink-Doris-Connector Flink CDC को Doris में exactly-once डेटा लेखन लागू करने में सक्षम बनाता है; DBT Doris Adapter DBT के साथ Doris में डेटा को रूपांतरित करने के लिए प्रदान किया जाता है।
Apache Doris Apache इनक्यूबेटर से सफलतापूर्वक स्नातक हो गया है और जून 2022 में एक टॉप-लेवल प्रोजेक्ट बन गया है।
हम Apache Doris में उनके योगदान के लिए 🔗सामुदायिक योगदानकर्ताओं की गहराई से सराहना करते हैं।
Apache Doris का अब चीन और दुनिया भर में व्यापक उपयोगकर्ता आधार है, और आज तक, Apache Doris का उपयोग दुनिया भर में हजारों कंपनियों में उत्पादन वातावरण में किया जा रहा है। बाजार पूंजीकरण या मूल्यांकन के मामले में चीन की शीर्ष 50 इंटरनेट कंपनियों में से 80% से अधिक लंबे समय से Apache Doris का उपयोग कर रही हैं, जिसमें Baidu, Meituan, Xiaomi, Jingdong, Bytedance, Tencent, NetEase, Kwai, Sina, 360, Mihoyo, और Ke Holdings शामिल हैं। यह वित्त, ऊर्जा, विनिर्माण, और दूरसंचार जैसे कुछ पारंपरिक उद्योगों में भी व्यापक रूप से उपयोग किया जाता है।
Apache Doris के उपयोगकर्ता: 🔗उपयोगकर्ता
Apache Doris वेबसाइट पर अपना कंपनी लोगो जोड़ें: 🔗अपनी कंपनी जोड़ें
सभी दस्तावेज़ 🔗दस्तावेज़
सभी रिलीज़ और बाइनरी संस्करण 🔗डाउनलोड
कैसे कंपाइल करें देखें 🔗कंपाइलेशन)
कैसे इंस्टॉल और तैनात करें देखें 🔗इंस्टॉलेशन और तैनाती
Doris Spark/Flink के लिए Connector के माध्यम से Doris में संग्रहीत डेटा पढ़ने के लिए समर्थन प्रदान करता है, और Connector के माध्यम से Doris में डेटा लिखने का भी समर्थन करता है।
मेल सूची Apache समुदाय में संचार का सबसे मान्यता प्राप्त रूप है। कैसे 🔗मेलिंग सूचियों की सदस्यता लें देखें
यदि आपके कोई प्रश्न हैं, तो 🔗GitHub Issue फाइल करने या इसे 🔗GitHub Discussion में पोस्ट करने और 🔗Pull Request सबमिट करके इसे ठीक करने के लिए स्वतंत्र महसूस करें
हम आपके सुझावों, टिप्पणियों (आलोचनाओं सहित), टिप्पणियों और योगदानों का स्वागत करते हैं। 🔗कैसे योगदान करें और 🔗कोड सबमिशन गाइड देखें
🔗Doris सुधार प्रस्ताव (DSIP) को सभी प्रमुख सुविधा अपडेट या सुधारों के लिए डिज़ाइन दस्तावेज़ों का संग्रह माना जा सकता है।
🔗 Backend C++ कोडिंग विनिर्देश का कड़ाई से पालन किया जाना चाहिए, जो हमें बेहतर कोड गुणवत्ता प्राप्त करने में मदद करेगा।
निम्नलिखित मेलिंग सूची के माध्यम से हमसे संपर्क करें।
| नाम | दायरा | |||
|---|---|---|---|---|
| dev@doris.apache.org | विकास-संबंधी चर्चाएं | सदस्यता लें | सदस्यता रद्द करें | अभिलेखागार |
- Apache Doris आधिकारिक वेबसाइट - साइट
- डेवलपर मेलिंग सूची - dev@doris.apache.org। मेलिंग सूची की सदस्यता लेने के लिए dev-subscribe@doris.apache.org को मेल करें, उत्तर का अनुसरण करें।
- Slack चैनल - Slack में शामिल हों
- Twitter - @doris_apache को फॉलो करें
नोट तृतीय-पक्ष निर्भरताओं के कुछ लाइसेंस Apache 2.0 लाइसेंस के साथ संगत नहीं हैं। इसलिए आपको Apache 2.0 लाइसेंस के अनुपालन के लिए कुछ Doris सुविधाओं को अक्षम करना होगा। विवरण के लिए,
thirdparty/LICENSE.txtफ़ाइल देखें